 夜雨聆风
夜雨聆风
我们是被AI追着跑的普通人,身处其中三分好奇、六分焦虑,还有一分无处安放的茫然。
作者|权个人
图片|ChatGPT被AI追着跑的人
我们可能是历史上第一批被一项技术(AI)追着跑的普通人。过去三年多我已经数不清自己听过多少个新词了——大模型、Agent、RAG、MCP、Token、Harness...它们像潮水一样涌过来,今天刚搞懂的概念,明天就被另一个更新的覆盖。
1.人工智能
人工智能(Artificial Intelligence,AI)是过去 70 年里人类不断尝试"让机器具备类似人的思考、感知与决策能力"的所有努力的统称。
可以说它不仅是一项具体技术,还是一个野心。这个野心随着2022年11月ChatGPT时刻的到来变得前所未有的清晰与现实。
回头看,这个野心在不同年代有完全不同的实现路径。符号主义时代靠人手写规则(给机器列出"猫有四条腿、毛茸茸、会喵喵叫"这样的规则)。机器学习时代靠统计与概率(让机器从数据中找规律)。
深度学习时代靠神经网络(让机器自己学会哪些特征值得关注)。今天的大模型时代,则靠 Transformer 与海量算力,让机器拥有了类似"通识"的能力。
每一波浪潮的内核都跟前一波几乎不同,被淘汰的不是"AI"这个目标,而是"上一种实现 AI 的方法"。
举个例子:人类教机器下棋的70年
符号主义阶段(1950-1980s):人类工程师把所有棋类规则、开局定式、残局技巧一条条写进程序。机器照着执行,赢了业余棋手,但靠的是"人脑借机器之手"。
机器学习阶段(1990s):机器开始自己分析人类棋谱,从几十万局对局中找规律。1997 年 IBM 深蓝击败国际象棋冠军卡斯帕罗夫,但它仍然依赖人类喂给它的棋谱与评估函数。
深度学习阶段(2010s):AlphaGo 不再靠人类棋谱,自己跟自己下了几千万局,走出了人类两千年都没想过的招法,这一刻,机器第一次"反过来教人类下棋"。
大模型阶段(2020s 至今):今天我们已经不再为"机器会下棋"震惊。人们关心的是,一个不为下棋而生的通用大模型,顺手就能讲解残局、点评棋手、撰写棋评。

有意思的是:"Artificial Intelligence,AI"这个词本身就是 1956 年达特茅斯会议上,为了拉到资金、特意起的"性感名字"。可见会讲故事一直是一项稀缺的能力。
AI也一直背负着"被高估—失望—重启"的行业周期律。但在今天我深刻感受到了不同,今天的AI让普通人拿到了一张改变工作与生活的船票。
2.机器学习
机器学习(Machine Learning,ML)就是不再靠人写规则、而是让机器从数据中自己找规律的方法。它是现代 AI 真正的起点。
在机器学习出现之前,程序员的工作是把规则一条一条写清楚,机器照着执行。比如想让程序识别一只猫,你得告诉它"猫有四条腿、有胡须、瞳孔是竖的、会喵喵叫"。然后你要尽可能的穷尽任何特殊情况。否则遇到一只断了腿的猫、或一只闭着嘴不叫的猫,程序就崩了。
机器学习颠覆了这个范式,你不再写规则,你只负责喂数据:告诉机器"这一万张图片是猫,这一万张图片不是",剩下的让它自己琢磨。
机器学习真正的革命,不是"机器变聪明了",而是程序员第一次可以用"喂数据"代替"敲代码"——从此凡是规则太复杂、写不完的任务(图像识别、语音转文字、推荐内容、机器翻译),通通可以"丢给数据自己学"。
早期的机器学习并不是真正"端到端"的全自动——你虽然不用写规则,但仍然得手动告诉机器"该看哪些特征"。
比如做信用卡反欺诈,工程师得先从原始交易记录里提取出"交易金额、地点、时间间隔、商户类型"这几列,做成一张特征表格,再喂给模型。这道工序叫特征工程,一个项目 80% 的时间都花在这上面。直到深度学习出现,这道隐形门槛才被彻底取消。
3.深度学习
深度学习(Deep Learning,DL)是机器学习的一个分支。它的特点是用层数很深的神经网络让机器找规律。"深"不是指"难",而是指层级抽象:一层处理一层的特征,从原始信号一直加工到最终判断。
承接我们之前提到的机器学习的概念:传统机器学习虽然不用人手写规则,但还得人手挑特征。这道叫"特征工程"的工序既费时,又依赖专家经验,还经常成为模型上限的瓶颈。
深度学习把这一步彻底干掉了:你只管把原始数据扔进去(整张图、整段录音、整篇文本),模型自己会一层层抽象出有用的特征。从此机器学习变成了真正"端到端"的过程——人类只管给数据,中间所有工序由机器自己长出来。
举个例子:图像识别的流水线
第1层(浅层):接到原始像素,只做最简单的事——识别边缘、颜色、亮暗。
第2-3层(中间层):把这些"零件"拼成更复杂的部件——这是眼睛、那是耳朵、这条是猫胡须。
第 4-5 层(中深层):部件组合成局部——这是猫脸、这是猫身。
最后一层:整合所有信息,给出判断——这是一只猫。
整条流水线没有一道工序是人手动设计的,每个工位都是模型在训练中自己长出来的。
这正是深度学习颠覆性的地方:它不只是"机器学习的升级版",它是特征工程时代的终结。从图像到语音,从文字到蛋白质结构,凡是过去要靠专家经验提炼特征的领域,深度学习一来几乎全线碾压。
行业里有句话:"过去十年 AI 的进步,本质上是'更深的网络 + 更多的数据 + 更强的算力'三件事在反复发酵。"换句话说,深度学习的胜利不是数学上的胜利,而是工程上的胜利。

4.神经网络
神经网络(Neural Network)是一种模仿"神经元相互连接、加权传递信号"这种结构而设计的数学模型——它是几乎所有现代 AI 系统的底层骨架。
它的基本单元叫神经元:接收一堆数字作为输入,按各自的"权重"加权求和,总和超过某个阈值就"激活"(把信号传给下一层),否则保持沉默。
一个神经网络,就是成千上万这样的神经元按层堆叠、互相连接组成的庞大计算结构。
所谓"训练",就是反复调整这些权重。一开始随机乱来、错得离谱,经过千万次纠错,最终形成一组"权重组合",能让整个网络做出正确判断。
举个例子:一场超大规模的接力投票
输入层(一线工人):每个神经元只看到原始信号的一小块——这个像素、那个字符,单独看毫无意义。
隐藏层(各级中层):每一层把前一层的"投票结果"再次加权综合,把零散信号逐步汇总成"有意义的判断"。
输出层(最终决策):整个组织投出最后一票——"这是一只猫"或"这不是"。
训练的过程,就是这家公司反复犯错、一点点学会"该多听谁的、该少听谁的"。
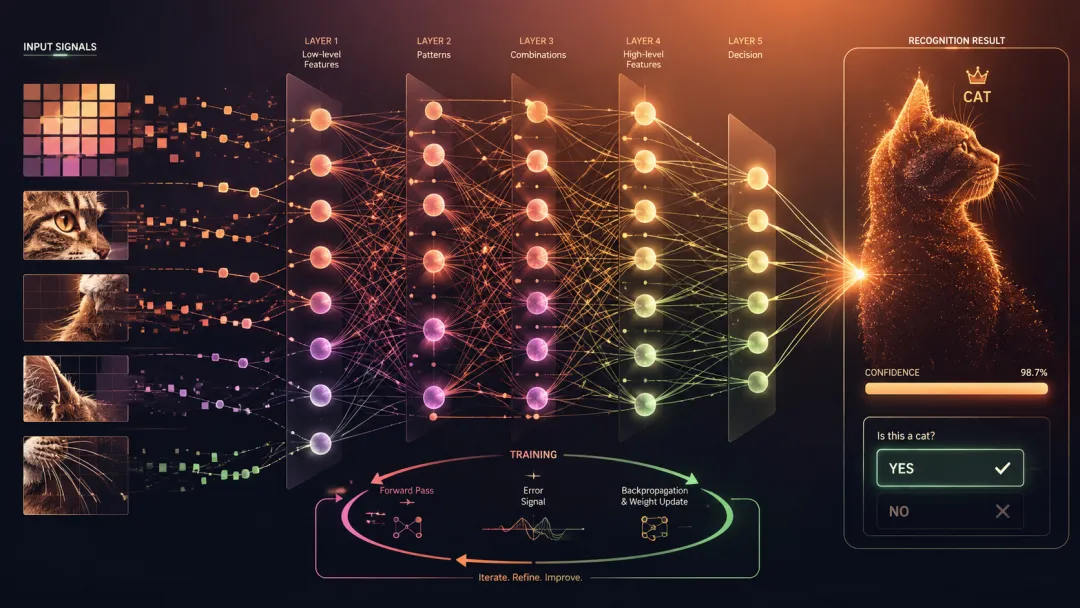
"神经网络"这个名字其实是个浪漫的误导。1950 年代的研究者起这个名字,是为了致敬大脑神经元的灵感,但今天我们用的神经网络,跟生物大脑的实际工作机制相差甚远。
它真正像的不是"大脑",而是一群拿着加权计算器的小学生在猜答案、猜错了就调整手里权重。这个名字带来了几十年的浪漫想象,也带来了几十年的过度承诺,直到今天,仍有不少人误以为"AI 学会的是大脑思考的方式"——其实并不是。
5.监督学习
监督学习(Supervised Learning)是一种让机器"照着标准答案学"的训练方式。你喂给它大量带有正确答案的数据,它通过反复对照练习,学会从输入推断出对应的输出。
在监督学习中,训练数据是核心。每条数据都包含两部分:输入(比如一张照片)和标签(比如"这是一只猫")。模型的任务就是找到输入和标签之间的规律,下次遇到没见过的新数据,也能给出正确判断。
举个例子:刷题备考的学生
老师(标注好的数据):准备一摞带标准答案的练习题。
学生(模型):一开始错得多,但每做一题就对照答案纠正思路,慢慢摸清出题套路。
考试(实际应用):上考场遇到新题,也能凭刷题积累的规律答得八九不离十。
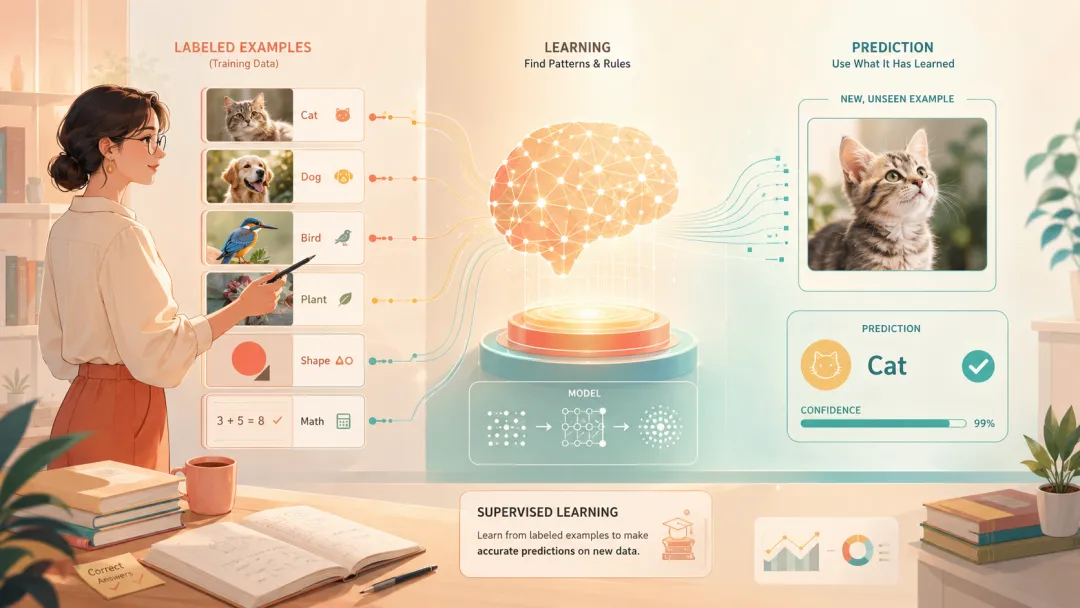
需要说明的一点是,监督学习的天花板其实就是数据标注的天花板。业内有句老话叫"有多少人工,就有多少智能"——模型再聪明,也跳不出标注员给它划定的圈子。这也是为什么近几年AI圈一直在想办法"摆脱标注依赖",而下面要讲的几种学习方式,就是不同的解题思路。
6.无监督学习
如果说监督学习是"照着答案学",那无监督学习(Unsupervised Learning)就是"没有答案,自己悟"。你只给模型一堆原始数据,不告诉它任何标签,让它自己从数据里找出隐藏的规律和结构。
无监督学习最典型的任务是聚类——把相似的东西自动归为一类。模型并不知道每一类"叫什么",但它能发现"这些东西彼此很像,那些东西明显不一样"。
举个例子:图书管理员整理旧书
图书管理员(模型):面对一仓库没有分类标签的旧书。
整理过程:他翻看每本书的封面、厚度、用纸、字体,把看起来"气质相近"的书摆到一起。
结果:最终堆出了几摞书——他不知道这几摞分别叫"小说""教材""画册",但他确实把同类的归到了一起。

无监督学习的价值,在于它能从数据里挖出连人类都没意识到的模式。电商平台给你打的"用户画像"、银行风控里的"异常交易识别",背后很多都是它在干活。它的局限也很明显:模型找出来的"规律"未必是你想要的规律,结果好不好,很多时候得靠人工再去解读。
7.强化学习
监督学习靠答案,无监督学习靠悟性,而强化学习(Reinforcement Learning)靠的是试错。模型在一个环境里不断尝试各种行动,做对了给奖励,做错了给惩罚,慢慢学会怎么做能拿到最多的奖励。
它跟前两者最大的区别是:没有现成的数据集。模型的"学习材料"是自己一次次行动产生的反馈,边做边学,越做越好。
举个例子:训练小狗坐下
主人(环境):手里拿着零食,发出"坐下"的指令。
小狗(模型):一开始不懂指令,乱跑乱跳,偶尔屁股着地了一下。
奖励反馈:屁股一着地,主人立刻给零食;其他动作没有奖励。久而久之,小狗就学会了一听到"坐下"就乖乖坐下——因为它发现这么做最划算。
强化学习是这两年大模型圈最火的训练范式之一。你听过的RLHF(基于人类反馈的强化学习),就是用它来让ChatGPT这类模型学会"说人话、说让人喜欢的话"。可以说,监督学习决定了模型的下限,而强化学习决定了模型的上限。
8.AI三要素
决定一个 AI 模型上限的从来不是某个单一的天才设计,而是三件东西在共同作用——算法、算力、数据。这三者缺一不可,且彼此咬合得非常紧。
算法是方法论:用什么样的数学结构去学规律(卷积神经网络、Transformer、扩散模型等)。
算力是发动机:训练一次大模型,需要数千乃至数万张 GPU 同时运行数周。无论海外还是国内,每家模型训练过程还是优先考虑使用英伟达。国产卡还是侧重在推理端发展。
数据是燃料:模型再聪明,也只能学会它"看过"的东西,而且数据越脏、越偏、越少,模型就越蠢、越偏、越脆弱。
举个例子:一家米其林后厨
菜谱(算法):告诉厨师怎么处理食材、火候怎么掌控。同样的牛排,顶级菜谱做出米其林,普通菜谱做出家常。
厨房与火候(算力):菜谱再精妙,只有一个家用煤气灶,也炒不出米其林水准,专业后厨需要恒温烤箱、急火灶、低温慢煮机一整套设备。
食材(数据):前两者都到位,如果食材不新鲜、不丰富,做出来的菜也不可能美味。

现在大家最关注算力(因为它最贵、最看得见,动辄几十亿美金的 GPU 集群)。技术圈最关注算法(因为它有论文、有英雄叙事),但真正决定一个模型上限的,往往是最不性感的那个——数据。
OpenAI 早期最重要的工作不是写代码,而是清洗、筛选、标注 GPT 训练所用的整个互联网级文本数据集。圈里有句老话:"Garbage in, garbage out"(垃圾数据进,垃圾模型出)。
2025年6月,Meta以143亿美元收购Scale AI 49%股权,并将Alexandr Wang招入公司,任命为首席AI官(Chief AI Officer),统管Meta所有AI研发。Scale AI就是一家专门做AI数据标注的公司。
9.AGI
AGI(Artificial General Intelligence,通用人工智能)指的是一种像人一样会"举一反三"的AI。它不局限于某个特定任务,而是能在各种各样的领域里学习、思考、解决问题,达到甚至超越人类的水平。
要理解AGI,得先看它的对立面——专用人工智能(也叫"弱AI")。之前我们熟悉的绝大多数AI都属于这一类:AlphaGo只会下围棋,让它去开车它不会;人脸识别系统只会认人脸,让它写诗它也不会。而AGI的目标,是造出一个什么都能学、什么都能干的"通才"。
举个例子:专科医生 vs 全科天才
专科医生(专用AI):在自己的科室里是顶尖高手,眼科医生看眼睛比谁都准,但你让他做心脏手术就很懵。
全科天才(AGI):不仅能看病,还能写代码、教数学、谈判、创业。遇到从没见过的领域,他能快速自学上手,几天就达到专业水平。
关键差别:专科医生的能力是"训练出来的",AGI的能力是"长出来的"——它有一种可以迁移到任何领域的通用智能。

现在AGI目前还没有公认的定义和衡量标准。OpenAI说GPT-5距离AGI更近了一步,DeepMind有自己的五级AGI路线图,也有学者认为现在的大模型路线根本走不到AGI。
它更像是行业里一个"心照不宣的远方"——所有人都朝那个方向跑,但没人能准确说出终点线在哪。而这恰恰是它最迷人也最危险的地方:当你不知道终点在哪时,你也不知道自己什么时候会突然抵达。
下个篇章我们通过11个AI概念聊聊——模型如何从一张白纸变聪明的。
