 夜雨聆风
夜雨聆风
先说点背景。
OpenAI 在 2025 年 5 月发布了新的 Codex,这东西跟你以为的"代码补全工具"完全不是一回事。之前那个 2021 年的 Codex 是 GitHub Copilot 的底座,给你在编辑器里补代码用的。这次的 Codex 是一个跑在云上的 Agent,能自己读代码库、写代码、跑测试、提 PR——你给它扔一个任务,它自己去干,干完给你看结果。
目前 GitHub 上的 openai/codex 仓库已经有 82k star,是今年 AI 编程领域讨论度最高的项目之一。
本文把它从安装到进阶全写了一遍,包括几个我觉得最值得重点讲的机制:AGENTS.md、三档 Effort 设定、Skills 自动化、Steer 实时干预、以及多 Agent 并行调度。
1. Codex 是什么,跟 Copilot 有什么本质差异
很多人第一反应是:这不就是 Copilot 升级版吗?
不是,差别挺大的。
GitHub Copilot 是编辑器插件,核心功能是光标旁边帮你补代码。你写一半,它给你续上。本质上是"提示补全",你还是主导者,它只是在你旁边提建议。
Codex 是 Agent。你给它一个任务描述,它会:
• 把你的代码库克隆到隔离沙盒里 • 自己分析代码结构和依赖关系 • 规划修改方案,执行文件读写 • 跑测试套件,根据失败日志自动修正 • 把结果整理成 PR 供你审核
全程你不需要动手。任务可以跑 1 分钟,也可以跑半小时。
这两个工具的定位根本不同。Copilot 是你手边的助手,Codex 是你可以派出去干活的下属——而且可以同时派好几个。
底层模型方面,早期版本基于 codex-1(o3 微调),目前 CLI 已支持 GPT-5.3-Codex 及更新的模型系列,可通过 --model 参数切换。
2. 三种入口
Web / CLI / IDE,各适合什么场景
目前用 Codex 有三条路:
Web 界面(chatgpt.com/codex):最简单,不需要装任何东西,浏览器打开就能用。适合快速验原型、问代码相关的问题、或者跑一次性的简单任务。但长任务管理和批量操作在网页上不太方便。
Codex CLI(终端工具):这是发挥 Codex Agent 能力的主要入口。可以在本地项目里直接跑,和 CI/CD 集成,写脚本调用,后面的大部分操作都是基于 CLI。
IDE 扩展(VS Code / Cursor / Windsurf):搜索安装 Codex — OpenAI's coding agent,在编辑器侧边栏里就能操作,适合想在写代码的过程中顺手调 Agent 的场景。
还有一个 Codex Desktop App(codex app 命令启动,或者直接访问 chatgpt.com/codex),macOS 和 Windows 都有,界面上是一个多 Agent 任务管理中心,左边列你开的所有任务线程,右边看 Agent 的实时操作日志。如果你同时跑好几个任务,这个比纯终端要好管理一些。
我自己现在主要用 CLI + 偶尔开 Desktop App 看任务状态。
3. 安装与认证
CLI 是核心
先确认 Node.js 版本在 18 以上,然后:
# npm 安装npm install -g @openai/codex# 或者 Homebrew(macOS)brew install --cask codex装完运行 codex,会出现一个界面让你选认证方式:
ChatGPT 账号登录(推荐):直接用 ChatGPT 账号,Agent 功能包含在 Plus/Pro/Team/Enterprise 订阅里。运行 codex,选 Sign in with ChatGPT,浏览器自动跳转授权页面。
API Key 登录:如果用 API Key 需要额外配置,参考官方文档 developers.openai.com/codex/auth。对于大多数个人用户来说,直接用 ChatGPT 账号更省事。
认证完成后,在你的项目根目录跑一句 codex 就能进入交互界面了。
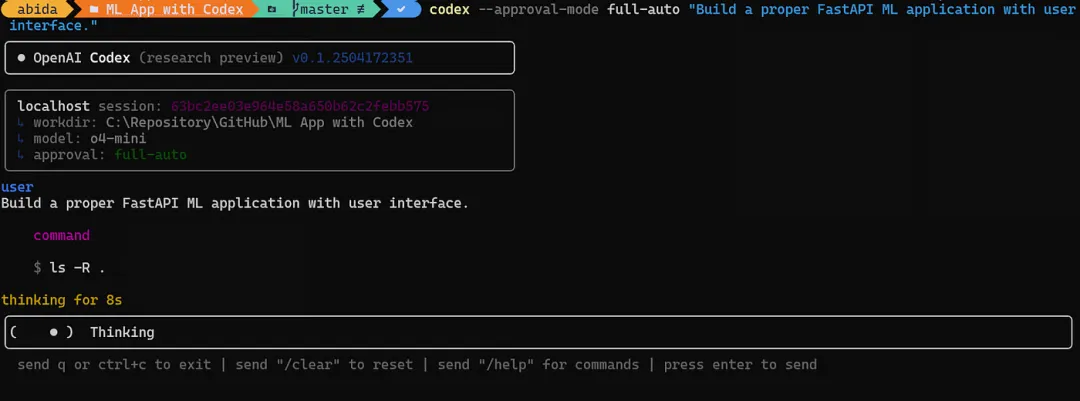
# 直接启动交互式界面codex# 或者直接给一个任务codex "解释这个项目的整体结构"4. 连接代码库
GitHub / 本地目录两种方式
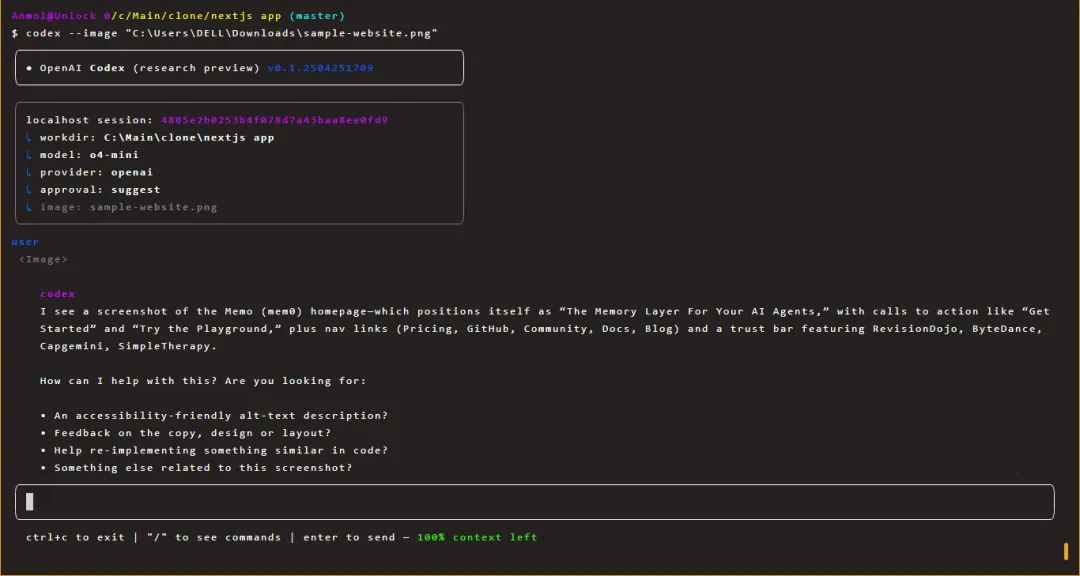
本地目录(最直接):在项目根目录运行 codex,它会自动扫描当前目录,不需要额外配置。
GitHub 集成:在 Web 界面或 Desktop App 里,有个 Connect Repository 选项,授权 GitHub 账号后,可以直接选仓库让 Codex 在云上处理。这种方式适合不想在本地跑的场景,或者代码库很大、本地跑着慢的情况。
连上之后,Codex 会把代码拉到一个临时的隔离沙盒里运行。沙盒环境里有完整的文件系统、终端权限,它可以装依赖、跑脚本、执行测试。每次任务结束后沙盒会清理掉,不会留痕迹。
5. AGENTS.md
这是给 AI 读的项目说明书
这个文件是 Codex 在 2025 年引入的一个很重要的机制,我觉得用好这个东西是把 Codex 从"能用"变成"好用"的关键步骤。
在项目根目录创建一个 AGENTS.md,里面写的是"告诉 AI 怎么理解这个项目"的规则。Codex 在接到任务之前,会先把这个文件读一遍。
## 技术栈- Node.js 20 + TypeScript 5.x(严格模式)- 数据库:PostgreSQL + Prisma ORM- 测试框架:Vitest## 编码规范- 所有异步函数必须有 try/catch 处理- 新建文件必须加 JSDoc 注释- 禁止使用 any 类型## 测试要求- 运行测试:`npm test`- 提交代码前必须跑完整测试,通过率 100%## 不可修改的文件- `config/secrets.json`- `migrations/` 目录下的已有文件这个文件支持多层级。根目录的 AGENTS.md 是全局规则,子目录里可以放特定模块的规则(比如 /api/AGENTS.md 专门管 API 模块的规范),Codex 会按层级合并。
开源仓库 openai/codex 本身就有一个 AGENTS.md,可以直接去 GitHub 上看看官方是怎么写的,挺有参考价值。
6. 三档底栏设置
权限 / 模型 / Effort
CLI 界面底部有三个核心设置,这块需要重点说一下。
权限模式(Approval Mode)
控制 Codex 能自主做什么、需要你确认什么。
• Read Only:只读。Codex 可以分析代码和给建议,但不能写文件,适合"我只想让它解释代码"的场景。 • Auto(推荐):自动执行读操作,写文件和跑命令时会在底部弹确认框,按 y批准。这是日常用的默认模式,安全和效率比较平衡。• Full Auto:完全自主,直接执行所有操作。建议只在你信任的隔离环境里用,或者配合 git 开了新分支的情况下。
模型选择
Codex 会根据任务类型自动推荐模型,一般用默认的就行。如果你的任务涉及复杂的架构判断,可以手动切换到更强的推理档。
Effort(推理强度)
这个设定直接影响任务的执行质量和速度。
• Low:响应最快,适合简单的代码解释、找 bug、小改动。 • Medium(默认):平衡档,日常 bug 修复和功能添加够用了。 • High:深度思考,AI 会先列详细计划,多轮模拟验证后再动手。涉及多文件改动、架构调整的任务建议用这档。
怎么说呢,Low 档有时候会偷懒,遇到稍微复杂的任务直接就给了一个半成品。如果你发现它输出质量不稳定,先把 Effort 调高再试。
7. Plugins 和 Skills 是两回事
这个概念很多人用了很久还搞不清楚,我来区分一下。
Plugins(插件):给 Codex 接外部工具的接口,基于 MCP 协议实现(后面第 12 节专门讲)。比如给它装一个文件系统插件,它就能访问特定目录;装 GitHub 插件,它就能直接查 Issue 列表。Plugins 扩展的是 Codex 的"能力边界"。
Skills(技能):存放在 ~/.codex/skills/(个人全局)和 .codex/skills/(项目级)目录下的 .md 文件,定义的是"完成某类特定任务的标准流程"。比如你写一个 deploy-to-vercel.md,里面描述了部署到 Vercel 的步骤,以后你发给 Codex "把这个项目部署上去" 的时候,它会自动调用这个 Skill 里的流程来执行,而不是每次都从头摸索。
简单说:Plugins 是工具,Skills 是 SOP(标准操作流程)。
8. Skills 自动化
可以把重复操作封装成定时任务
这个功能是 Codex 目前让我觉得最实用的设计之一。
一般的 AI 工具是"你问它答"。Codex 多了一个 Automation 机制——你可以把一个 Skill 设定成定时自动运行,无需触发。
举个实际的场景:假设你每周需要统计项目的测试通过率和代码覆盖率,整理成报告发给团队。以前你得手动跑脚本、整理数据、发邮件,搞一次要二十分钟。
在 Codex 里的操作流程是这样的:
第一步,建立 Skill 文件
在 ~/.agents/skills/weekly-report.md 里写:
## 任务名称Weekly Code Quality Report## 执行流程1. 运行 `npm test -- --coverage` 获取测试数据2. 解析 coverage/lcov-report/index.html,提取总覆盖率3. 统计本周新增/修改文件数量(`git diff --stat HEAD~7`)4. 将数据整理成 Markdown 格式的摘要5. 通过邮件 API 发送给 team@company.com## 输出格式- 测试通过率:XX%- 代码覆盖率:XX%- 本周变更文件数:XX第二步,设置自动化
在 Codex 里告诉它:
把 weekly-report 这个 Skill 配置成每周一早上 9 点自动执行第三步,忘了它
到时间了它自己跑,你只需要看邮件就行。
这种自动化能做的事情很多:每天跑一次安全扫描、每次 push 之后自动生成 changelogs、定期整理 GitHub Issues 的优先级……我现在手动干的事情已经少了一大块。
9. Steer
这部分作为任务进行中的实时干预
这块需要说一下,因为大多数 Agent 工具都有个让人难受的设计:你发了指令,它开始跑,这时候你发现方向不对,但没办法,只能等它跑完再重来。
Codex 加了一个 Steer 操作,解决了这个问题。
例如「任务执行过程中,你可以随时在对话框里发新消息来干预它的方向,Codex 会即时调整后续操作,不用等它跑完再重来」。
对于执行时间长的任务,这个功能很实用。我以前的习惯是"先让它跑,不对再重来",有了 Steer 之后可以边看边调,节省不少时间。
10. 多 Agent 并行调度
真正的一个人顶一支小队
这是 Codex 整个设计里我认为最有价值的部分,也是和其他工具拉开差距的地方。
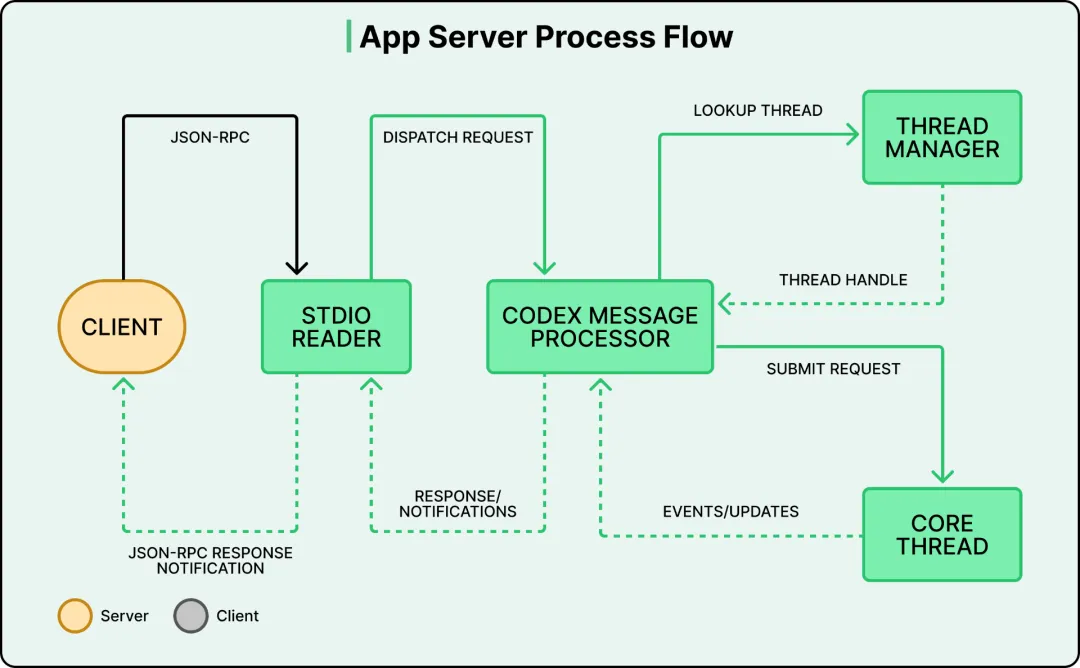
操作模式很简单:一个代码目录,开多个 Chat 窗口,每个窗口背后跑一个独立的 Agent,每个 Agent 负责不同的任务,互不干扰。
举个具体的例子,假设你要做一个完整的功能上线:
你给 A 发完任务立刻切到 B,B 发完切到 C,C 发完切到 D,全部挂起来让它们跑。哪个完成了就会在对话框标题上亮起提示,你点进去验收。
需要注意的是,这几个任务最好在逻辑上是相对独立的,或者至少把文件级别的冲突风险降低。如果两个 Agent 同时改同一个文件,会出问题。通常的做法是:明确划分文件职责边界,或者让各个 Agent 在不同分支上工作,最后手动 merge。
这种工作方式的效率提升不是线性的。不是"开 4 个 Agent,快 4 倍",因为你还要花时间分配任务、验收结果、处理冲突。但在分工清晰的场景下,节省的时间是真实的。
11. Codex + Claude Code
实践中,两个工具怎么搭配更好
这是我实际用下来觉得最好的组合。
Codex 在处理多文件任务、并行调度、复杂业务逻辑上更强。但前端 UI 的视觉细节这块,Claude Code 的表现普遍更好——CSS 写得更准,组件设计更合理,UI 相关的判断更接近人的审美。
组合使用的方式很直接:Codex 和 Claude Code 可以同时读写同一个本地目录,不需要任何手工同步。
典型流程:
1. 用 Codex 把主要功能逻辑写完,包括 API 对接、数据处理、基本的组件结构 2. 在同一个目录下开 Claude Code,让它专门负责 UI 美化、样式调整、交互细节
Claude Code 在同一目录下用这个命令启动(跳过权限确认):
claude --dangerously-skip-permissions这个 flag 的意思是自动审批所有文件操作,不用每次手动确认。注意只在你信任的本地项目里用,别在不确定的环境里开这个。
两个工具读写同一套文件,Codex 改的逻辑部分 Claude Code 能看到,Claude Code 改的样式部分 Codex 也能感知,协作是自然的。
12. MCP 集成
给 Codex 接外部工具
MCP(Model Context Protocol)是 AI 工具连接外部数据源和工具的标准协议,Codex 原生支持。
配置方式有两种:
CLI 命令(快速添加):
# 给 Codex 接文件系统访问权限codex mcp add filesystem -- npx -y @modelcontextprotocol/server-filesystem /path/to/project# 接联网搜索(需要 Brave 的 API Key)codex mcp add brave-search --env BRAVE_API_KEY=你的key -- npx -y @modelcontextprotocol/server-brave-search# 接 GitHub(可以直接查 Issue)codex mcp add github -- npx -y @modelcontextprotocol/server-github配置文件(持久化设置):
编辑 ~/.codex/config.toml:
model = "codex-1"model_reasoning_effort = "medium"[mcp_servers.filesystem]command = "npx"args = ["-y", "@modelcontextprotocol/server-filesystem", "/Users/yourname/projects"][mcp_servers.github]command = "npx"args = ["-y", "@modelcontextprotocol/server-github"]env = { GITHUB_TOKEN = "你的token" }接了 GitHub MCP 之后,你可以直接告诉 Codex "看一下 Issue #123 说的是什么问题,然后修复它",它会自己去读 Issue 内容,不需要你手动复制粘贴。
在 CLI 里输入 /mcp 可以查看当前已加载的所有插件状态,确认有没有连上。
13. 避坑清单
把我自己遇到的和整理到的高频问题写在这里,省得你走弯路。
① Supabase MCP 断线了一定要重启
接了 Supabase 的 MCP 插件之后,如果遇到 Codex 突然读不到数据库结构、或者报连接错误,不要在对话里发指令让它"重试"——直接重启 Codex 进程。Supabase MCP 的连接有时候会静默断掉,重启是最快的解决方式。
② AGENTS.md 里写"不要修改 xxx 文件"一定要用绝对路径
写 config/secrets.json 有时候会被忽略,写 /项目根目录/config/secrets.json 效果更可靠。特别是涉及敏感配置文件时,这条值得注意。
③ 多 Agent 并行时务必开分支
两个 Agent 同时改同一目录的不同文件,大多数时候没问题。但如果你没有用 git 分支隔离,一旦出现文件冲突,恢复起来会很麻烦。规范做法是:给每个 Agent 的任务单独开一个分支,跑完 review diff 再 merge。
④ Effort 设置 High 之后第一次响应会慢
High 档的推理过程会先做规划再执行,有时候你发完指令,三四十秒内没有任何输出,这是正常的,它在"想",不是卡住了。如果超过两分钟还没动静,再考虑重试。
⑤ Full Auto 模式下别对着主分支操作
Full Auto 模式 + 主分支 = 危险组合。Full Auto 是真的不问你就改,如果它判断出了偏差,你的主分支代码可能会被改乱。要么用 Auto 模式,要么在开了单独分支的情况下再用 Full Auto。
⑥ 任务描述越具体越好
"帮我优化这段代码"这种指令出来的东西质量很随机。换成"优化 src/utils/formatDate.ts 的性能,处理 null 值边界情况,不改变函数签名" 这种写法,结果要稳定得多。上下文越清晰,任务越具体,Effort 浪费越少。
⑦ 遇到 MCP 报"Permission Denied"
Codex 对项目根目录以外的路径访问很严格。如果你的 MCP 插件需要访问项目以外的目录,要在 config.toml 的 trusted_paths 里显式添加,不然直接拒绝。
结尾
我是真的觉得,用 Codex 这类 Agent 工具,门槛其实不高,但你能用到什么程度,差距主要在于"会不会管理 Agent"。AGENTS.md 写得好不好,任务拆分得合不合理,Skills 自动化有没有建起来——这些细节决定了你是把 Codex 用成"偶尔问一下",还是真正把它变成工作流的一部分。
开源地址:https://github.com/openai/codex
文档地址:https://developers.openai.com/codex
如果你在某个步骤卡住了,先去 GitHub 的 Issues 区搜一下,3.8k 个 Issue 里大概率有人遇到过同样的问题。
