 夜雨聆风
夜雨聆风——从PyTorch到MCU的完整部署工作流
导读: 训练好的AI模型怎么塞进一块几十块钱的MCU里?INT8量化后精度到底掉多少?没有NPU的芯片能跑Transformer吗?瑞芯微的NPU相比纯CPU能快多少倍?本文用一篇讲清楚。
适用平台: STM32、瑞萨RA/RH850、英飞凌PSoC/TC3xx、瑞芯微RK系列、ESP32等
📑 目录
- 一、总览:嵌入式AI部署全景 — 核心流程、有NPU vs 无NPU对比、推荐工作流
- 二、模型导出与优化 — ONNX导出、INT8量化(PTQ/QAT)、精度评估
- 三、无NPU平台部署方案 — CMSIS-NN、TFLite Micro、瑞萨/英飞凌部署
- 四、有NPU平台部署方案 — RKNN部署、NPU加速效果、注意事项
- 五、硬件平台选型指南 — 10款MCU选型矩阵、决策树、平台对比
- 六、实战案例 — 5个真实MCU部署案例(STM32/ESP32/STM32N6),含模型大小、推理时间、内存占用
- 七、常见问题与调试 — 问题排查、调试技巧、性能分析工具
- 八、总结 — 工作流选择建议、未来趋势
一、总览:嵌入式AI部署全景
1.1 部署核心流程
无论目标平台是什么,嵌入式AI部署都遵循以下核心流程:
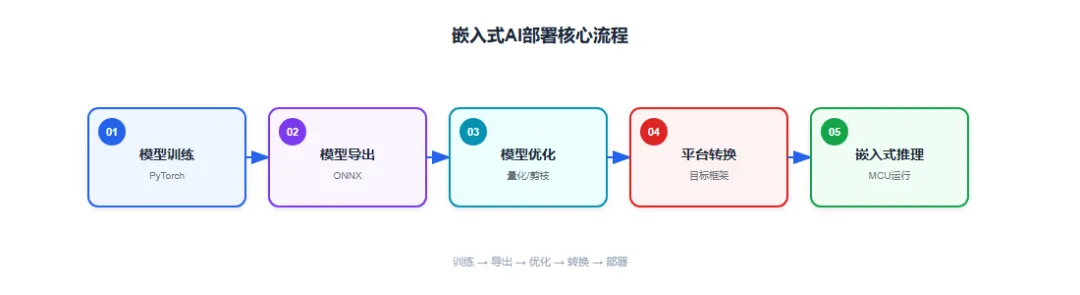
图:嵌入式AI部署核心流程
每个环节的关键决策点:
| 环节 | 关键决策 | 影响范围 |
|---|---|---|
| 模型导出 | opset版本、动态/静态shape | 后续转换兼容性 |
| 模型优化 | 量化精度(INT8/FP16)、是否剪枝 | 推理速度 vs 精度 |
| 平台转换 | 选择哪个部署框架 | 目标芯片支持度 |
| 嵌入式推理 | 内存分配、算子实现 | 运行效率和资源占用 |
1.2 有NPU vs 无NPU:工作流对比
| 维度 | 无NPU MCU | 有NPU MCU/SoC |
|---|---|---|
| 算力来源 | CPU(Cortex-M/RH850/TriCore) | NPU + CPU协同 |
| 核心瓶颈 | 计算速度、内存 | 模型转换兼容性 |
| 量化要求 | 必须INT8量化 | INT8/INT16均可 |
| 部署框架 | CMSIS-NN / TFLite Micro | RKNN / eIQ Neutron / 厂商SDK |
| 适用模型规模 | <1M参数 | 1M-100M参数 |
| 典型推理延迟 | 5-100ms | 1-10ms |
1.3 推荐工作流
无NPU MCU推荐工作流
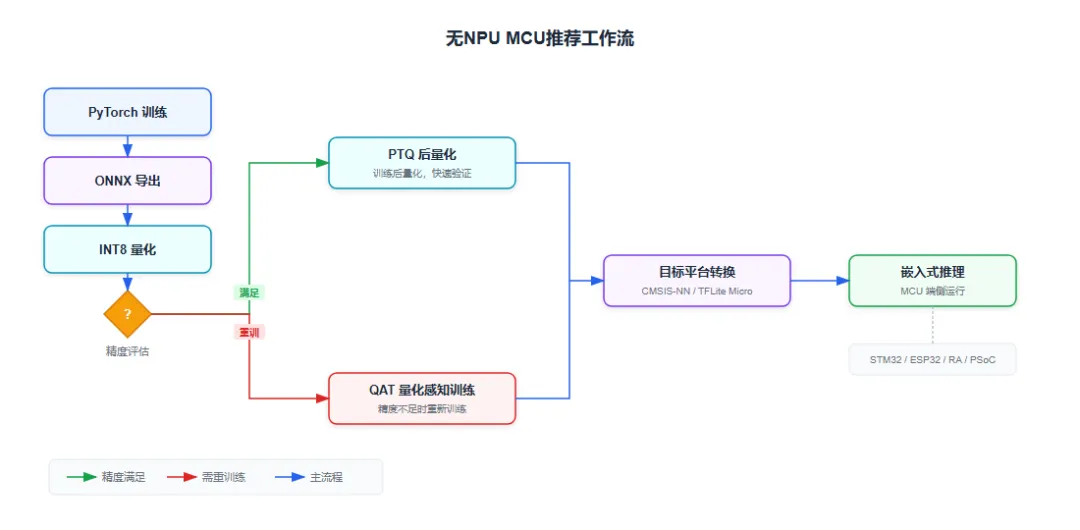
图:无NPU MCU推荐工作流
适用平台: STM32、瑞萨RA/RH850、英飞凌PSoC/TC3xx、ESP32
推荐框架选择:
| 平台 | 推荐框架 | 理由 |
|---|---|---|
| STM32 | STM32Cube.AI / CMSIS-NN | 官方支持,集成度高 |
| 瑞萨RA | FSP + e² studio | Helium SIMD加速 |
| 瑞萨RH850 | CS+ / 手写C | 车规级工具链 |
| 英飞凌PSoC/XMC | ModusToolbox ML | Imagimob AI支持 |
| 英飞凌TC3xx | Aurix Development Studio | TriCore原生优化 |
| ESP32 | TFLite Micro | 跨平台,社区活跃 |
| NXP i.MX RT | eIQ / CMSIS-NN | 双重支持 |
有NPU MCU/SoC推荐工作流
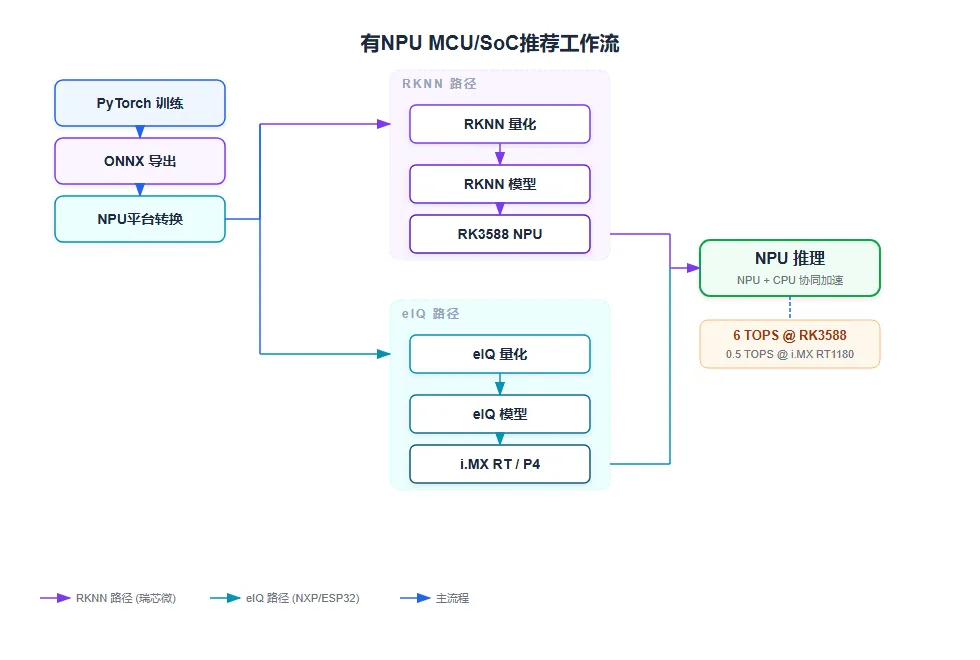
图:有NPU MCU/SoC推荐工作流
适用平台: 瑞芯微RK35xx系列、ESP32-P4、NXP i.MX RT1180、全志V853
推荐框架选择:
| 平台 | 推荐框架 | NPU算力 |
|---|---|---|
| 瑞芯微RK3588 | RKNN-Toolkit2 | 6 TOPS |
| 瑞芯微RK3576 | RKNN-Toolkit2 | 6 TOPS |
| 瑞芯微RK3568 | RKNN-Toolkit2 | 1 TOPS |
| ESP32-P4 | TFLite Micro | 0.4 TOPS |
| NXP i.MX RT1180 | eIQ Neutron | 0.5 TOPS |
二、模型导出与优化
2.1 ONNX导出
ONNX是嵌入式部署的通用中间格式,几乎所有部署框架都支持ONNX输入。
model.eval()
torch.onnx.export(
model, dummy_input, "model.onnx",
input_names=['input'], output_names=['output'],
opset_version=11, do_constant_folding=True
)
关键参数说明:
opset_version=11:嵌入式推荐,兼容性最好do_constant_folding=True:常量折叠优化- 固定输入尺寸比动态shape更利于嵌入式部署
导出后验证: 用 onnx.checker.check_model() 验证结构,再用 onnxruntime 推理对比PyTorch输出误差。
ONNX简化: 使用 onnxsim.simplify() 进行常量折叠和死代码消除。
2.2 量化技术
量化是嵌入式部署的关键步骤,将FP32模型压缩为INT8/INT16,大幅降低内存占用和推理时间。
💡 工程师笔记: 对于BMS等对精度要求高的场景,建议先用PTQ快速验证,若精度不满足再切换QAT。大多数情况下PTQ + 良好的校准数据集就够了。
| 量化类型 | 精度损失 | 压缩比 | 加速比 | 适用场景 |
|---|---|---|---|---|
| FP32 → FP16 | 极小 | 2x | 1.5-2x | 有FPU的高端MCU |
| FP32 → INT8 | 小 | 4x | 3-5x | 主流选择 |
| FP32 → INT4 | 中等 | 8x | 5-8x | 权重量化,精度敏感慎用 |
| 混合精度 | 可控 | 2-4x | 2-4x | 关键层FP16,其他INT8 |
训练后量化(PTQ)
最常用的量化方式,无需重新训练:
from onnxruntime.quantization import quantize_dynamic, QuantType
quantize_dynamic(
model_input="model.onnx", model_output="model_int8.onnx",
weight_type=QuantType.QInt8,
op_types_to_quantize=['MatMul', 'Conv']
)
静态量化(精度更高): 需要提供校准数据集,实现 CalibDataReader 类后调用 quantize_static(),QDQ格式更适合嵌入式。
量化感知训练(QAT)
精度要求高时使用,在训练过程中模拟量化效应:
import torch.quantization as quant
model.qconfig = quant.get_default_qat_qconfig('fbgemm')
quant.prepare_qat(model, inplace=True)
# 正常训练 → model.eval() → quant.convert(model) → export
量化精度评估
分别用原始模型和量化模型对同一测试集推理,计算MSE、MAE、最大绝对误差。若精度损失超过阈值,可尝试:改用QAT、调整 per_channel 参数、对关键层保持FP16。
三、无NPU平台部署方案
3.1 CMSIS-NN(ARM Cortex-M首选)
CMSIS-NN是ARM官方神经网络推理库,手写汇编优化,针对Cortex-M系列深度优化。
支持的算子: 卷积(arm_convolve_HWC_q7)、全连接(arm_fully_connected_q7)、LSTM(arm_lstm_unidirectional)、池化、激活函数、Softmax
转换方式:
| 方法 | 工具 | 适用场景 |
|---|---|---|
| STM32Cube.AI | 图形化IDE | STM32用户首选 |
| NNoM | Python CLI | 开源框架,灵活 |
| 手动转换 | Python脚本 | 完全可控 |
核心推理流程:
#include "arm_nnfunctions.h"
// 输入量化 → 卷积 → ReLU → 全连接 → Softmax → 输出反量化
arm_convolve_HWC_q7_basic(input, IH, IW, IC, weights, OC, K, bias,
BIAS_SHIFT, OUT_SHIFT, temp_buf, output);
arm_relu_q7(output, size);
arm_fully_connected_q7(output, fc_w, in, out, BS, OS, temp, output);
arm_softmax_q7(output, out, output);
性能优化技巧: 循环展开(1.2-1.5x)、内存32字节对齐(1.1-1.2x)、CMSIS-DSP加速(1.5-2x)、激活函数查表(5-10x)、缓冲区复用(内存减半)
3.2 TFLite Micro(跨平台首选)
Google官方嵌入式推理框架,支持ARM、RISC-V、Xtensa等架构,核心库仅约16KB。
转换流程: ONNX → TensorFlow → TFLite(含INT8量化)
converter = tf.lite.TFLiteConverter.from_saved_model("tf_model")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.representative_dataset = representative_dataset
tflite_model = converter.convert()
嵌入式集成核心步骤:
// 1. 创建解释器并分配张量
tflite::MicroInterpreter interpreter(model, resolver, arena, arena_size);
interpreter.AllocateTensors();
// 2. 填入输入 → 3. interpreter.Invoke() → 4. 读取输出
内存优化: 张量共享(内存减30-50%)、算子融合、静态分配、选择性链接(库体积减半)
3.3 瑞萨RA系列部署
RA8M1基于Cortex-M85 + Helium SIMD,AI/ML加速3-5倍,2MB Flash + 1MB SRAM。
部署流程: PyTorch → ONNX → e² studio导入 → FSP AI模型转换 → Helium优化编译 → RA8M1运行
| 模型 | 参数量 | 推理时间 | 精度损失 |
|---|---|---|---|
| DLinear | 100K | ~3ms | <1% |
| LSTM | 200K | ~6ms | <1% |
| TCN | 500K | ~15ms | <2% |
3.4 英飞凌PSoC/XMC部署
英飞凌提供ModusToolbox ML + Imagimob AI工具链,支持AutoML和端到端部署。
from imagimob import ModelCompiler
model = ModelCompiler.load('model.onnx')
model.quantize(target='int8')
model.compile(target='psoc6', output='model_src/')
3.5 无NPU平台CPU优化策略
| 优化技术 | 原理 | 加速效果 |
|---|---|---|
| 循环展开 | 减少循环开销 | 1.5-2x |
| SIMD向量化 | 单指令多数据 | 2-4x |
| 查表法 | 预计算激活函数 | 5-10x |
| 定点运算 | 整数替代浮点 | 3-5x |
| 内存复用 | 原地计算 | 内存减50% |
激活函数查表实现:
static const int8_t sigmoid_table[256] = { /* 预计算值 */ };
int8_t sigmoid_lookup(int8_t x) {
return sigmoid_table[(uint8_t)x]; // uint8索引直接映射0-255
}
模型选择优先级(无NPU): DLinear > ModernTCN > LSTM > iTransformer > PatchTST
⚠️ 踩坑提醒: 模型选型比部署优化更重要。一个100K参数的DLinear在STM32F4上推理15ms,而1M参数的Transformer在STM32H7上需要200ms+。先选对模型,再优化部署。
四、有NPU平台部署方案
4.1 瑞芯微RKNN部署(NPU加速首选)
RKNN-Toolkit2支持PyTorch/ONNX/TensorFlow模型转换,INT8/INT16量化,算子融合和模型压缩。
from rknn.api import RKNN
rknn = RKNN()
rknn.config(target_platform='rk3588')
rknn.load_onnx(model='model.onnx')
rknn.build(do_quantization=True, dataset='calib_data.txt')
rknn.export_rknn('model.rknn')
RK3588 NPU加速效果:
| 模型 | 参数量 | NPU推理 | CPU推理 | 加速比 |
|---|---|---|---|---|
| MobileNetV2 | 3.5M | 1ms | 15ms | 15x |
| LSTM(1M) | 1M | 3ms | 25ms | 8x |
| Transformer(10M) | 10M | 8ms | 200ms | 25x |
4.2 NPU部署注意事项
🔑 关键认知: NPU不是万能的。NPU只加速它支持的算子(如卷积、矩阵乘),不支持的算子会自动回退到CPU执行。如果模型中包含大量NPU不支持的算子(如自定义激活函数),加速效果会大打折扣。
- 算子兼容性:NPU不支持所有算子,不支持的算子自动回退到CPU
- 量化校准:NPU通常要求INT8量化,校准数据需覆盖典型场景
- 内存分配:NPU有专用内存,需合理分配输入/输出/中间tensor
- 异步推理:NPU支持异步推理,可实现流水线并行
五、硬件平台选型指南
5.1 无NPU MCU选型矩阵
| 平台 | 厂商 | 架构 | 主频 | 内存 | AI算力 | 适用模型 | 部署工具 |
|---|---|---|---|---|---|---|---|
| STM32F103 | 意法半导体(ST) | Cortex-M3 | 72MHz | 20KB | ~50 MFLOPS | DLinear微型版 | 手写C |
| STM32F407 | 意法半导体(ST) | Cortex-M4F | 168MHz | 192KB | ~100 MFLOPS | DLinear, 小型LSTM | CMSIS-NN |
| STM32H743 | 意法半导体(ST) | Cortex-M7 | 480MHz | 1MB | ~500 MFLOPS | TCN, PatchTST, LSTM | CMSIS-NN, Cube.AI |
| GD32H7 | 兆易创新 | Cortex-M7 | 600MHz | 3.5MB | ~600 MFLOPS | TCN, LSTM, 轻量Transformer | CMSIS-NN, 手写C |
| ESP32-S3 | 乐鑫科技 | Xtensa LX7 | 240MHz | 512KB | ~600 MFLOPS | 轻量Transformer | TFLite Micro |
| NXP i.MX RT1170 | 恩智浦(NXP) | Cortex-M7 | 1GHz | 2MB | ~1 GFLOPS | iTransformer, TimesNet | eIQ, CMSIS-NN |
| 瑞萨RA8M1 | 瑞萨(Renesas) | Cortex-M85+Helium | 480MHz | 1MB | ~1.5 GFLOPS | TCN, LSTM | FSP, e² studio |
| 瑞萨RH850 1374 | 瑞萨(Renesas) | RH850 G3K | 240MHz | 512KB | ~300 MFLOPS | DLinear, LSTM | CS+, 手写C |
| 英飞凌PSoC6 | 英飞凌(Infineon) | Cortex-M4F+M0+ | 150MHz | 288KB | ~100 MFLOPS | DLinear, 小型LSTM | ModusToolbox ML |
| 英飞凌XMC7200 | 英飞凌(Infineon) | Cortex-M7 | 350MHz | 1MB | ~400 MFLOPS | TCN, LSTM | ModusToolbox ML |
| 英飞凌TC387 | 英飞凌(Infineon) | TriCore 1.6P | 300MHz×3核 | 2MB | ~800 MFLOPS | TCN, LSTM, 轻量CNN | Aurix Dev Studio |
| TMS320F28004x | 德州仪器(TI) | C28x DSP | 100MHz | 256KB | ~200 MFLOPS | DLinear, 小型LSTM | TI C2000 SDK |
| SAM E54 | Microchip | Cortex-M4F | 120MHz | 512KB | ~80 MFLOPS | DLinear | MPLAB Harmony |
5.2 有NPU MCU/SoC选型矩阵
| 平台 | 厂商 | CPU架构 | NPU算力 | 内存 | 适用模型 | 部署工具 |
|---|---|---|---|---|---|---|
| 瑞芯微RK3588 | 瑞芯微(Rockchip) | 4×A76+4×A55 | 6 TOPS | 8GB | 大型Transformer, CNN | RKNN-Toolkit2 |
| 瑞芯微RK3576 | 瑞芯微(Rockchip) | 4×A72+4×A53 | 6 TOPS | 4GB | 大型Transformer | RKNN-Toolkit2 |
| 瑞芯微RK3568 | 瑞芯微(Rockchip) | 4×A55 | 1 TOPS | 2GB | 中型CNN, LSTM | RKNN-Toolkit2 |
| NXP i.MX RT700 | 恩智浦(NXP) | Cortex-M33+M7 | 0.5 TOPS | 4.5MB | 中型CNN, LSTM | eIQ Neutron |
| ESP32-P4 | 乐鑫科技 | RISC-V双核 | 0.4 TOPS | 32MB | 轻量CNN, Transformer | TFLite Micro |
| 全志V853 | 全志(Allwinner) | Cortex-A7 | 0.5 TOPS | 64MB | 中型CNN | TFLite, ONNX |
5.3 选型决策树
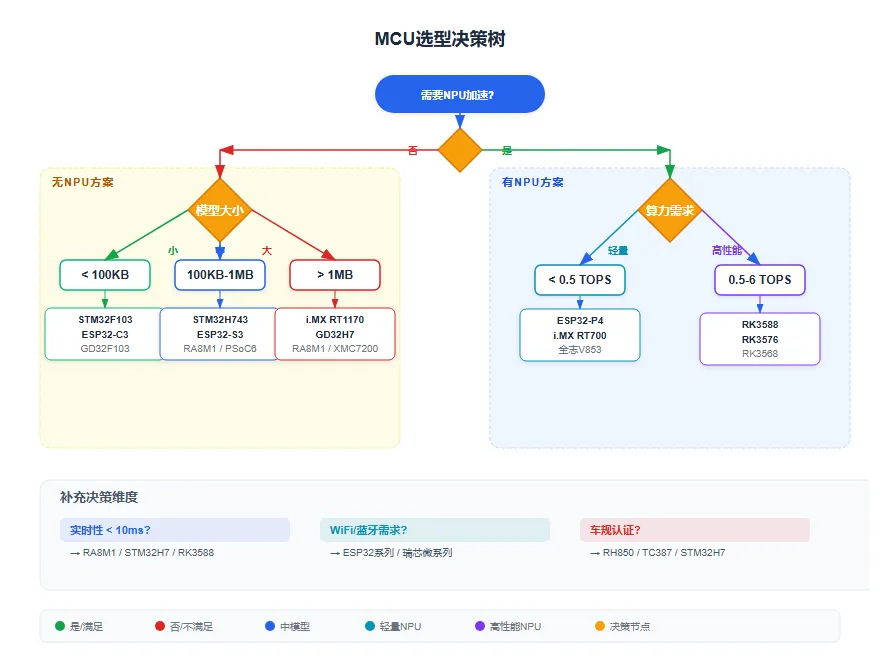
图:MCU选型决策树(按NPU需求→模型大小→内存容量分层决策)
补充决策维度:
| 决策点 | 选择建议 |
|---|---|
| 实时性 < 10ms? | 是 → RA8M1 / STM32H7 / RK3588(NPU) |
| WiFi/蓝牙需求? | 是 → ESP32系列 / 瑞芯微系列 |
| 车规认证? | 是 → RH850 / TC387 / STM32H7 / NXP i.MX RT |
5.4 各平台对比总结
| 维度 | STM32(ST) | 兆易创新GD32 | 瑞萨RA/RH850 | 英飞凌PSoC/TC3xx | 瑞芯微RK | NXP i.MX RT | TI C2000 | ESP32 |
|---|---|---|---|---|---|---|---|---|
| AI工具成熟度 | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| 社区生态 | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| 性价比 | ★★★★☆ | ★★★★★ | ★★★☆☆ | ★★★☆☆ | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| 功耗 | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★★ | ★★☆☆☆ | ★★★★☆ | ★★★★★ | ★★★☆☆ |
| 实时性 | ★★★★★ | ★★★★★ | ★★★★★ | ★★★★★ | ★★★☆☆ | ★★★★★ | ★★★★★ | ★★★☆☆ |
| 车规认证 | ★★★★☆ | ★★☆☆☆ | ★★★★★ | ★★★★★ | ★★☆☆☆ | ★★★★☆ | ★★★★★ | ★★☆☆☆ |
| NPU支持 | 无 | 无 | 无 | 无 | 有 | 部分型号 | 无 | 部分型号 |
📌 厂商覆盖说明: 本文覆盖了国际主流MCU厂商(ST、NXP、英飞凌、TI、Microchip、瑞萨)和国产主流厂商(兆易创新、瑞芯微、乐鑫、全志),涵盖汽车电子、工业控制、IoT三大应用领域。
六、实战案例:真实MCU部署案例汇总
📌 说明: 以下案例均为真实在MCU/嵌入式平台上部署并实测的案例,数据来自厂商官方报告、学术论文或开发者实测博文,附有信源链接。
6.1 案例一:STM32F407 手势识别部署(开发者实测)
来源: CSDN开发者博文(LCG元),2025年12月
信源链接:https://blog.csdn.net/michael_jovi/article/details/156116923
案例概述: 将TensorFlow Lite手势识别CNN模型通过STM32Cube.AI部署到STM32F407VET6(Cortex-M4F @ 168MHz),使用MPU6050六轴传感器采集加速度数据,识别5种手势(上划/下划/左划/右划/静止)。
实测部署数据:
| 指标 | 数值 |
|---|---|
| 芯片平台 | STM32F407VET6(Cortex-M4F @ 168MHz) |
| 模型类型 | 1D-CNN(INT8量化) |
| 模型大小 | ~32KB(权重) |
| RAM占用 | 45KB(权重32KB + 缓冲区13KB) |
| 推理时间 | 6.9-8.2ms(不同手势略有差异) |
| 上划识别准确率 | 94% |
| 下划识别准确率 | 89% |
| 静止识别准确率 | 97% |
| 功耗优化 | 睡眠模式下平均电流从28mA降至9mA |
部署工具链: TensorFlow 2.x → TFLite(INT8量化)→ STM32Cube.AI → STM32F407
6.2 案例二:ESP32-S3 语音关键词检测(开发者实测)
来源: ESP32-S3端侧AI产品实战分析,2026年
信源链接:https://m.toutiao.com/group/7636669681608229376/
案例概述: 将DS-CNN关键词检测模型通过TFLite Micro部署到ESP32-S3(Xtensa LX7 @ 240MHz),实现离线语音唤醒和命令词识别。
实测部署数据:
| 指标 | 数值 |
|---|---|
| 芯片平台 | ESP32-S3(双核Xtensa LX7 @ 240MHz) |
| 模型类型 | DS-CNN(INT8量化) |
| 模型大小 | ~150KB(权重) |
| SRAM占用 | ~120KB(激活值80KB + 音频缓冲40KB) |
| 推理时间 | 关键词检测<100ms(含音频预处理) |
| AI加速效果 | 较ESP32(无AI指令集)快2-3倍 |
| 功耗降低 | 约40%(AI向量指令集优化) |
| 深度睡眠电流 | 10μA |
关键结论: ESP32-S3的AI向量指令集对CNN推理加速显著,150KB的DS-CNN模型可完全放入SRAM运行,无需外扩PSRAM。
6.3 案例三:ESP32-S3 人脸检测部署(开发者实测)
来源: ESP32-S3端侧AI产品实战分析,2026年
信源链接:https://m.toutiao.com/group/7636669681608229376/
案例概述: 将MobileNet-SSD变体人脸检测模型部署到ESP32-S3,用于AI智能门禁场景,本地完成人脸检测和识别,无需云端。
实测部署数据:
| 指标 | 数值 |
|---|---|
| 芯片平台 | ESP32-S3(双核Xtensa LX7 @ 240MHz) |
| 模型类型 | MobileNet-SSD变体(INT8量化) |
| 模型大小 | ~1.5MB(权重,存PSRAM) |
| SRAM占用 | ~300KB(激活值) |
| PSRAM占用 | ~1.5MB(模型权重) |
| 推理时间 | <200ms |
| 输入分辨率 | 96×96 ~ 224×224 |
| 应用场景 | 智能门禁刷脸开锁 |
关键结论: 人脸检测模型较大(1.5MB),需存储在PSRAM中。PSRAM访问延迟比SRAM高,需仔细规划内存布局。关闭Wi-Fi/BT可提升实时性。
6.4 案例四:自供能TinyML预测性维护系统(IEEE TIM论文)
来源: IEEE Transactions on Instrumentation and Measurement, 2023 — 陈梓杰、梁俊睿(上海科技大学)
信源链接:https://ieeexplore.ieee.org/document/10229236
案例概述: 基于自供电振动传感和TinyML的端侧预测性维护系统,在微控制器上运行轻量级ML模型(Autoencoder),实现对三种振动故障特征和其他特征的准确分类。
实测部署数据:
| 指标 | 数值 |
|---|---|
| 运行平台 | 微控制器(MCU) |
| 模型类型 | Autoencoder异常检测(轻量级ML) |
| 模型大小 | 数十KB |
| 分类任务 | 3种振动故障 + 正常 |
| 节能效果 | 较惯性传感器节能66.8% |
| 供能方式 | 自供能,无需外部电源 |
| 验证方式 | 实验室 + 场地测试 |
6.5 案例五:STM32N6 人脸识别门禁系统(ST官方案例)
来源: ST官方边缘AI案例库
信源链接:https://www.st.com/content/st_com/zh/st-edge-ai-suite/case-studies/secure-entry-systems-using-id3-face-recognition-with-liveness-detection.html
案例概述: 基于STM32N6 MCU(集成Neural-ART NPU加速器),实现人脸识别+活体检测的安防门禁系统。通过RGB摄像头与ToF传感器进行边缘处理,全部推理在MCU端完成。
部署数据:
| 指标 | 数值 |
|---|---|
| 芯片平台 | STM32N6(Cortex内核 + Neural-ART NPU) |
| 计算性能 | 600 GOPS |
| 推理方式 | NPU加速 |
| 应用场景 | 安防门禁、实时人脸识别 |
| 特点 | 边缘端完成全部推理,反欺骗检测 |
6.6 案例总结与选型建议
| 应用场景 | 参考案例 | 芯片平台 | 模型大小 | 推理时间 | RAM占用 |
|---|---|---|---|---|---|
| 手势/活动识别 | 案例一 | STM32F407 @ 168MHz | ~32KB | 6.9-8.2ms | 45KB |
| 语音关键词检测 | 案例二 | ESP32-S3 @ 240MHz | ~150KB | <100ms | ~120KB |
| 人脸检测 | 案例三 | ESP32-S3 @ 240MHz | ~1.5MB | <200ms | ~300KB |
| 预测性维护 | 案例四 | MCU(自供能) | 数十KB | — | — |
| 人脸识别门禁 | 案例五 | STM32N6 + NPU | — | — | — |
💡 工程师笔记: 从以上真实案例可以看出,数十KB的模型在168MHz MCU上推理时间约7-8ms;150KB的模型在240MHz MCU上推理时间约100ms级;1.5MB的模型需要PSRAM支持。模型大小每增加一个数量级,推理时间和内存需求也相应增加。选型时务必先量化模型、评估资源需求,再选择合适的MCU平台。
七、常见问题与调试
7.1 部署问题排查
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 推理结果全零 | 量化scale错误 | 检查量化参数,重新校准 |
| 推理崩溃 | 内存不足 | 增大tensor arena,优化模型 |
| 精度严重下降 | 量化范围不当 | 使用QAT或调整量化策略 |
| 推理速度慢 | 未使用优化库 | 使用CMSIS-NN/TFLM |
| 编译错误 | 算子不支持 | 替换为支持的算子 |
7.2 调试技巧
// 调试宏:打印张量前10个元素,逐层排查
#define DEBUG_TENSOR(name, tensor, size) \
printf("%s: ", name); \
for (int i = 0; i < (size > 10 ? 10 : size); i++) \
printf("%.4f ", tensor[i]); \
printf("\n");
7.3 性能分析工具
| 工具 | 用途 | 平台 |
|---|---|---|
| STM32CubeMonitor | 实时性能监控 | STM32 |
| SEGGER SystemView | RTOS任务分析 | 多平台 |
| Keil MDK Performance Analyzer | 函数级性能分析 | ARM |
| ESP-IDF Profiler | FreeRTOS任务分析 | ESP32 |
八、总结
8.1 部署工作流选择建议
| 场景 | 推荐工作流 | 理由 |
|---|---|---|
| STM32平台 | PyTorch → ONNX → STM32Cube.AI | 官方支持,集成度高 |
| ARM Cortex-M通用 | PyTorch → ONNX → CMSIS-NN | 极致性能,GD32等兼容 |
| 瑞萨RA系列 | PyTorch → ONNX → FSP | Helium SIMD加速 |
| 英飞凌PSoC/XMC | PyTorch → ONNX → ModusToolbox | Imagimob AI支持 |
| 英飞凌TC3xx | PyTorch → ONNX → 手写C/TriCore优化 | 车规BMS首选 |
| TI C2000 | PyTorch → ONNX → 手写C/DSP优化 | 电机+BMS一体化 |
| 瑞芯微RK系列 | PyTorch → ONNX → RKNN | NPU加速,6TOPS |
| NXP i.MX RT系列 | PyTorch → ONNX → eIQ | 有无NPU型号可选 |
| 跨平台需求 | PyTorch → ONNX → TFLite Micro | 生态成熟,移植方便 |
8.2 未来趋势
- 编译器优化:MLIR、TVM等编译器将提供更自动化的优化
- 神经架构搜索(NAS):自动搜索适合嵌入式的模型结构
- 稀疏计算:利用模型稀疏性进一步加速
- 混合精度:FP16/INT8混合精度成为主流
- 边缘AI芯片:专用NPU逐渐普及,降低部署门槛
附录:参考资料
A. 官方文档
- CMSIS-NN: https://arm-software.github.io/CMSIS_5/NN/html/
- TensorFlow Lite Micro: https://www.tensorflow.org/lite/microcontrollers
- STM32Cube.AI: https://www.st.com/en/embedded-software/x-cube-ai.html
- RKNN-Toolkit2: https://github.com/rockchip-linux/rknn-toolkit2
- Renesas FSP: https://www.renesas.com/en/software-tool/flexible-software-package
- ModusToolbox: https://www.infineon.com/modustoolbox
B. 开源项目
| 项目 | 链接 | 说明 |
|---|---|---|
| NNoM | https://github.com/majianjia/nnom | MCU神经网络框架 |
| emlearn | https://github.com/emlearn/emlearn | 嵌入式机器学习库 |
| TinyML Examples | https://github.com/tensorflow/tflite-micro | TFLM官方示例 |
| CMSIS-NN | https://github.com/ARM-software/CMSIS-NN | CMSIS-NN示例 |
C. 学习资源
- 《TinyML》书籍
- Coursera: Introduction to Embedded Machine Learning
- ST/瑞萨/英飞凌官方AI教程
- ARM AI开发者社区
文档完成
