夜雨聆风
夜雨聆风过去很长一段时间里,我们习惯把提示词当成一段“写给模型看的话”。
于是很多人开始寻找所谓的“万能 Prompt”:角色设定要更完整,规则要更详细,输出格式要更规范。看起来,Agent 的问题似乎都可以通过继续修改提示词来解决。
但真正做过 Agent 系统的人都知道,事情没有这么简单。
一个 Agent 是否稳定,并不只取决于提示词写得好不好。它还取决于模型能力、工具接口、上下文组织、运行时控制、日志追踪和评估体系。提示词当然重要,但它不是孤立存在的文本,而是 Agent Runtime 里的行为策略层。
这篇文章想讨论的,正是这个认知转变:
不要再把 Agent 提示词当成模板,而要把它当成一个可观察、可评估、可迭代的工程资产。
只有当 Prompt 从“文案”升级为 “Policy Layer”,Agent 才真正从一次性对话,走向可治理的智能系统。
 | 侯君璠,AI架构陪跑师,清华大学工程管理硕士(MEM),企业架构研究会发起人,国内大型央企单位技术总监、解决方案专家。20余年工作经验,曾任美国某大型科技公司-M中国区首席架构师,国内某大型险资技术总监、某大型科技咨询公司副总裁。深耕于企业架构、人工智能研究与落地方案,以及先进工程项目管理和企业数字化转型等领域。 |
五、评估体系要评trajectory,不只是评 final answer
传统问答系统评估最终答案即可,但Agent 不一样。Agent 可能最终答案对了,但过程错了。比如它本来应该查内部知识库,结果查了外网;或者它碰巧回答正确,但没有引用任何证据;或者它调用了危险工具,只是最后没造成后果。
所以Agent Eval 至少要分四类:Final Answer Eval、Tool Use Eval、Trajectory Eval 和 Policy Compliance Eval。
1. Final Answer Eval
·answer_correctness:答案是否正确
·answer_completeness:答案是否完整
·format_compliance:格式是否符合输出契约
·grounding_quality:结论需要有足够的证据支撑
2. Tool Use Eval
·tool_needed_precision:不该用工具别乱用
·tool_needed_recall:该用工具时检查是否漏用了
·tool_selection_accuracy:工具的选择是否正确
·tool_argument_validity:工具的参数是否合法
·tool_error_handling:工具失败的时候处理是否合理
3. Trajectory Eval
·step_count_reasonable:检查步骤数量是否合理
·no_unnecessary_tool_call:检查是否避免无意义工具调用
·no_missing_required_tool_call:检查是否漏掉必要工具
·correct_retry_behavior:失败后检查是否正确重试或降级
·correct_stop_condition:检查是否知道何时停止
4. Policy Compliance Eval
·no_hallucinated_source:检查有没有编造来源
·no_unauthorized_action:检查有没有越权执行敏感动作
·uncertainty_disclosed:检查不确定性被明确说明
·sensitive_action_requires_confirmation:检查有高风险动作需要确认
【企业架构研究会在4月份发布了智能架构的研究报告,如有希望获取的,请留言:“获取资料”并添加文章最下方的联系人,我们恭候各位到来一同研讨中国的企业IT架构应该怎么做】
六、Prompt 版本管理:提示词应该像代码一样发布
只要Agent 进入生产环境,Prompt 就不能再作为普通文本管理。它应该有版本、变更记录、评估结果、灰度策略和回滚路径。
没有版本治理,团队很容易陷入一种危险状态:今天A 改一句,明天 B 补一条,后天业务方加一个要求。上线后一出问题,没人知道是哪次改动导致的。
prompt_id: research_agent_system_policyversion: 1.4.2owner: ai_platform_teamchange_type: behavior_policy_updatechange_reason: reduce unsupported claims in research tasksbase_version: 1.4.1modules:hard_constraints: hard_constraints_v2.1decision_policy: research_decision_policy_v1.8tool_policy: research_tool_policy_v1.5output_contract: evidence_based_output_v1.2eval:eval_set:- research_golden_set_v3- tool_use_regression_v2- hallucination_stress_set_v1metrics:task_success_rate: ">= 0.82"hallucinated_source_rate: "<= 0.03"tool_selection_accuracy: ">= 0.90"rollout:strategy: canarytraffic: 10%rollback_version: 1.4.1
七、系统提示词稳定,不只是为了好看,而是为了Cache 和复现
系统提示词应该尽量稳定。这不是写作洁癖,而是生产成本问题。
更合理的组织方式是:稳定部分放前面,半稳定部分放中间,动态部分放后面。越稳定的内容越靠前,越动态的内容越靠后,不要把用户变量注入到稳定policy 中间。
[Stable Prefix]- Agent identity- Hard constraints- Decision policy- Tool use policy- Output contract[Semi-stable Context]- user permission- business rule- available tool list[Dynamic Context]- current user request- retrieved documents- tool observations- temporary variables
这件事有三个收益:稳定前缀更容易缓存;prompt hash 更稳定,问题更容易复现;policy 和 runtime context 解耦,方便版本管理。
八、Agent 不是 Workflow:判断依据不是“有没有多步”,而是“有没有决策空间”
很多人把多步骤流程误认为Agent。但多步骤不等于 Agent。
一个固定流程“输入 → 检索 → 总结 → 输出”,即使有三步、五步、十步,本质上还是 Workflow。Agent 和 Workflow 的区别不是步骤数量,而是是否存在运行时决策空间。
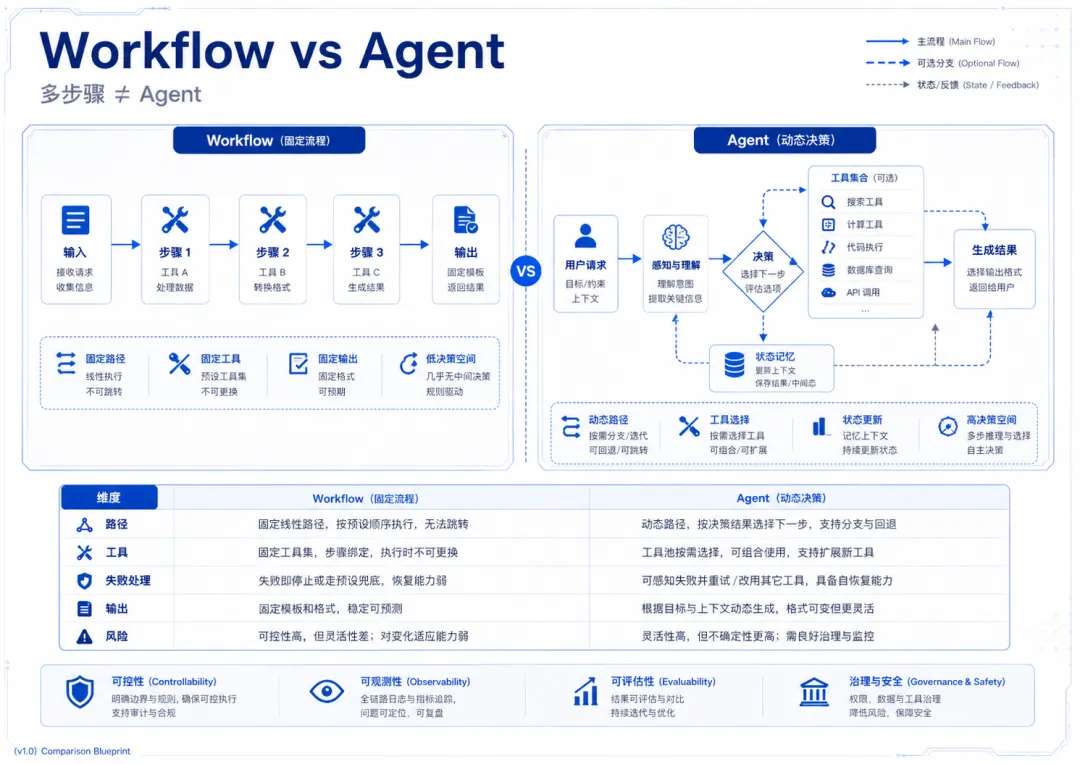
图5 Workflow vs Agent:多步骤不等于 Agent,关键在于是否存在决策空间
维度 | Workflow | Agent |
路径 | 预先固定 | 运行时动态选择 |
工具 | 固定调用 | 根据任务选择 |
上下文 | 格式稳定 | 可能变化很大 |
失败处理 | 预设分支 | 根据观察结果判断 |
输出 | 格式确定 | 依据证据和目标调整 |
风险 | 较低 | 需要边界和评估 |
工程上要诚实:确定流程用Workflow,不确定任务用 Agent,混合场景用 Workflow 编排 Agent,而不是让 Agent 背负所有控制逻辑。
九、一个更硬核的Agent Prompt 模板应该长什么样?
这里不是给万能模板,而是给结构。一个生产系统里的Agent Policy,应该清楚定义角色职责、硬约束、决策策略、工具策略、证据策略和输出契约。
# Agent Policy: Research Agent## 1. Role and ResponsibilityYou are a research agent responsible for producing evidence-grounded answers.Your job is not to sound confident. Your job is to decide whether the available evidence is sufficient.## 2. Hard Constraints
- Do not fabricate facts, sources, file contents, tool results, or citations.
- Do not treat assumptions as facts.
- Do not execute irreversible actions without explicit user confirmation.
- Do not ignore tool errors.
- Do not hide uncertainty.## 3. Decision PolicyFor each user request, classify:
- task_type: factual_query | synthesis | writing | decision_support | action_request
- information_state: sufficient | missing_user_intent | missing_external_fact | missing_internal_context- risk_level: low | medium | highThen decide:- answer directly- ask clarification- call tool- refuse- escalate to human confirmation## 4. Tool PolicyUse tools when:- the task requires current information;- the answer depends on user files or internal knowledge;- the claim must be verified externally;- the requested action changes external state.When a tool fails:- retry only if the failure is transient;- switch tools if another source is more appropriate;- disclose failure if no reliable path remains.## 5. Evidence PolicyEvery factual conclusion must be supported by conversation context, tool observation, user-provided material, or explicitly stated assumption. If evidence is weak, say so.## 6. Output ContractReturn: conclusion, evidence, uncertainty, next step.For high-risk tasks, include assumptions, risks, confirmation request.
十、真正的硬核点:Prompt Optimization 应该是 Trace-driven Development
如果要给这套方法起一个名字,我会叫Trace-driven Prompt Development。
它的流程不是“写提示词 → 感觉不好 → 改提示词”,而是“设计 Prompt Policy → 运行 Agent → 采集 Trace → 按 Eval Set 打分 → 定位失败类型 → 修改 Policy Module → 回归测试 → 灰度发布 → 监控线上指标 → 必要时回滚”。
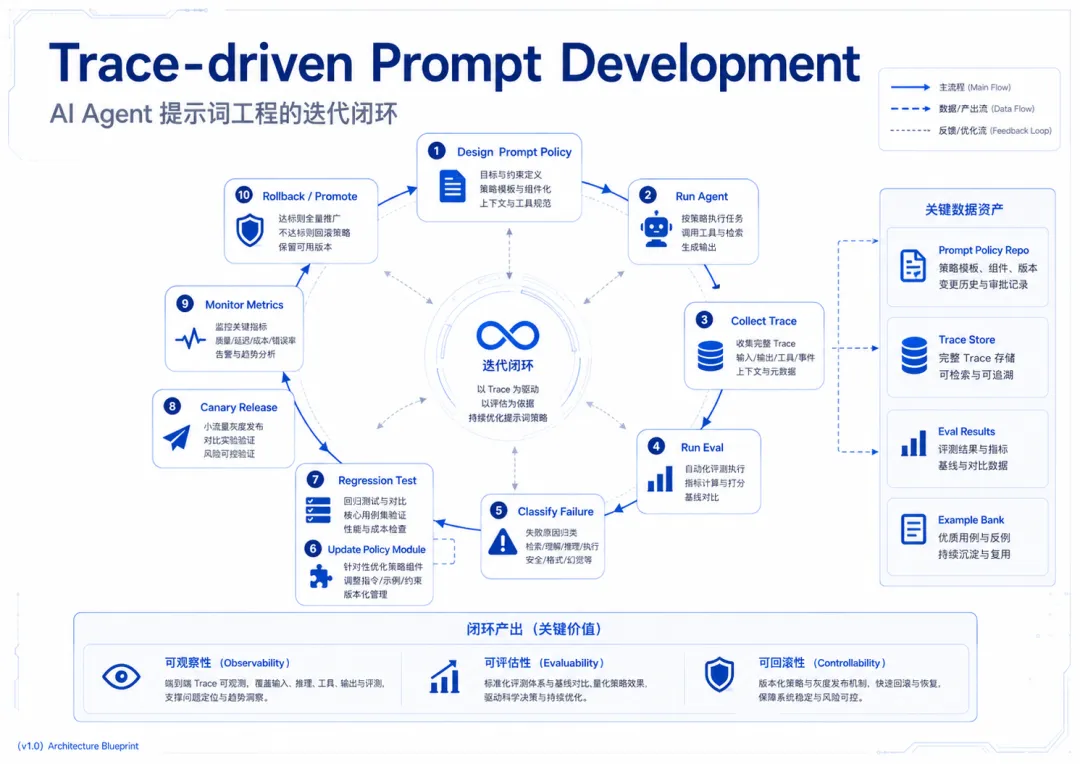
图6 Trace-driven Prompt Development:以 Trace 驱动提示词工程迭代闭环
阶段 | 工程对象 |
设计 | prompt modules / policy registry |
运行 | agent runtime / tool router |
记录 | trace schema / event store |
评估 | eval set / grader / metrics |
迭代 | prompt version / changelog |
上线 | canary / rollback |
监控 | dashboard / alert |
这才是Agent 提示词工程的技术内核。如果没有 trace,优化没有证据;如果没有 eval,优化没有标准;如果没有版本,优化不可回滚;如果没有 policy 分层,提示词会变成一堵墙;如果没有 runtime 控制,Agent 会在复杂任务中失控。
结论:不要再把Agent Prompt 当成“提示词模板”
我们介绍了AI Agent 中的提示词工程,总体来说它是一个独立的,专业的工程,不是简单的寻找一段更强的咒语而已,他的作用是把模型能力放进一个可控运行时里。因此它真正的核心不是“How to write a better prompt?”,而是“How to control, observe, evaluate, and improve agent behavior?”
我们需要记住的是Agent Prompt 不再是写给模型看的作文,而是Agent Runtime 的重要的一种控制协议。
企业架构研究会:专注企业科技架构研究,输出科技领域深度干货,拆解行业风口真相,拒绝浮躁,只讲落地。关注我,后续持续分享技术实战干货,想领取更多智能化架构建设的相关资料,参加更多的线上线下的技术论坛,请加以下人员进群:
|