 夜雨聆风
夜雨聆风上周我发现一件吓人的事。
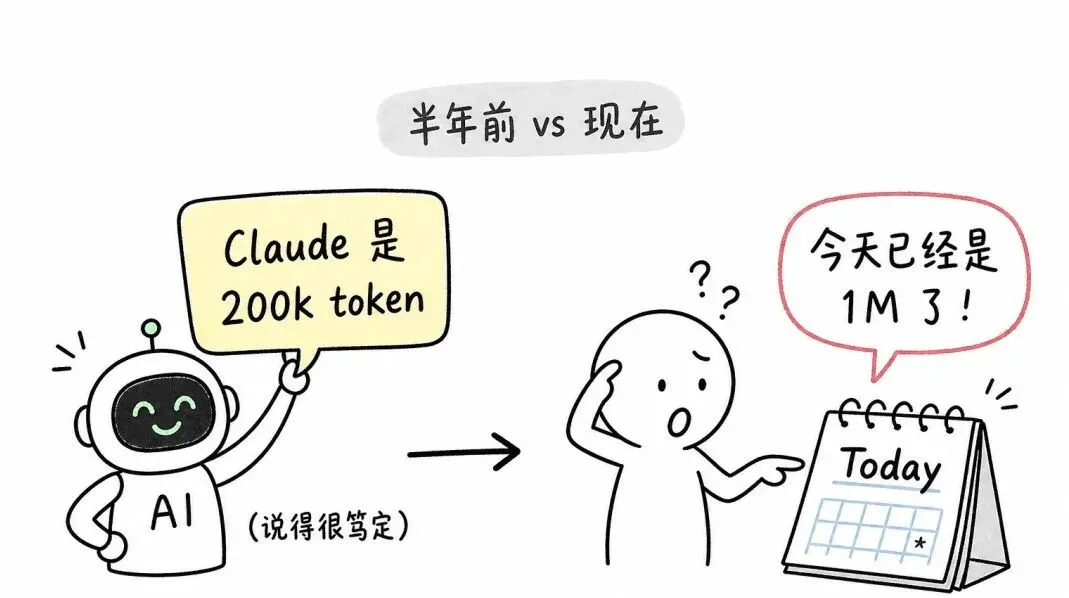
AI 帮我整理资料的时候写着「Claude 现在是 200k token」。说得很笃定,还引了官方博客做背书。
但今天已经是 1M token 了。
它不是在骗我,它只是把半年前的记忆当成现在写出来。这种错最坑,因为说得很笃定、还能引一堆背书,肉眼根本看不出来。等真要拿去用的时候才发现「这个早改了」,前面基于错误信息做的判断全要推翻。
所以我写了个 skill 叫 fact-check,专门让 AI 给 AI 整理出来的内容做事实核查。逻辑很简单:把内容里的事实声明逐条抽出来,去官方 docs 对照,出一份「对 / 过时 / 错 / 查不到」四级报告,外加修正 diff。
听起来挺直白的。但它的 4 个版本,每一版都是在跑真实任务时被它自己抓现行,被迫加纪律加出来的。
下面四个例子,全是用 fact-check 前后的真实对照。
v1.0:数字对不齐它都没告诉我
场景:我让 AI 帮我整理一份 Claude Code 配置项的 cheat sheet,准备扔进团队 wiki 给同事查。AI 整理出一堆功能说明,我跑了第一版 fact-check。
没用之前:cheat sheet 里有十几条事实声明(「X 字段默认值是 Y」「Z 配置项 deprecated 了」这种),全靠我自己一行行翻 docs 对,干完一上午。
用了之后:fact-check 跑完,告诉我「检查了 12 条声明,1 错 1 过时」。
听起来不错?但我数了一下它前面列的抽取表:14 条。最后正式报告里又只列了 11 条。
三处数字全不一样。它中间合并了?丢了?还是漏了?一个字没说。
我没法判断它给的「1 错 1 过时」对应哪几条。错的那条是 Claude Code 的某个参数?还是某个已经废弃的配置?过时的那条是默认值变了?还是字段名变了?没法跟进、没法验证、没法改。我跑这一遍 fact-check 干了什么?什么都没干。等于白审。
补 v1.1 纪律:禁止静默合并 / 丢弃;三处数字必须对齐(抽取表行数 = 口播数 = 报告表行数)。如果做了合并或丢弃,必须在报告末尾显式说明哪几条被合并、为什么。

v1.2:把同一个东西判成了两个
场景:我让 AI 帮我整理一份「Claude 桌面端产品对比」给同事看,要讲清楚 Claude Desktop 和 Claude Code Desktop 的区别。
没用之前:AI 整理的初稿里写「Claude Desktop 偏聊天、Claude Code Desktop 偏编程,是两个独立的 App」,听起来很有道理。
用了之后:fact-check 跑完,连着两轮告诉我:「作者把它们当两个 App 是对的 ✅。」
理由听起来逻辑挺顺:一个在 support.claude.com 的文档里,一个在 code.claude.com 的文档里,连官方文档站都不一样,能是同一个吗?
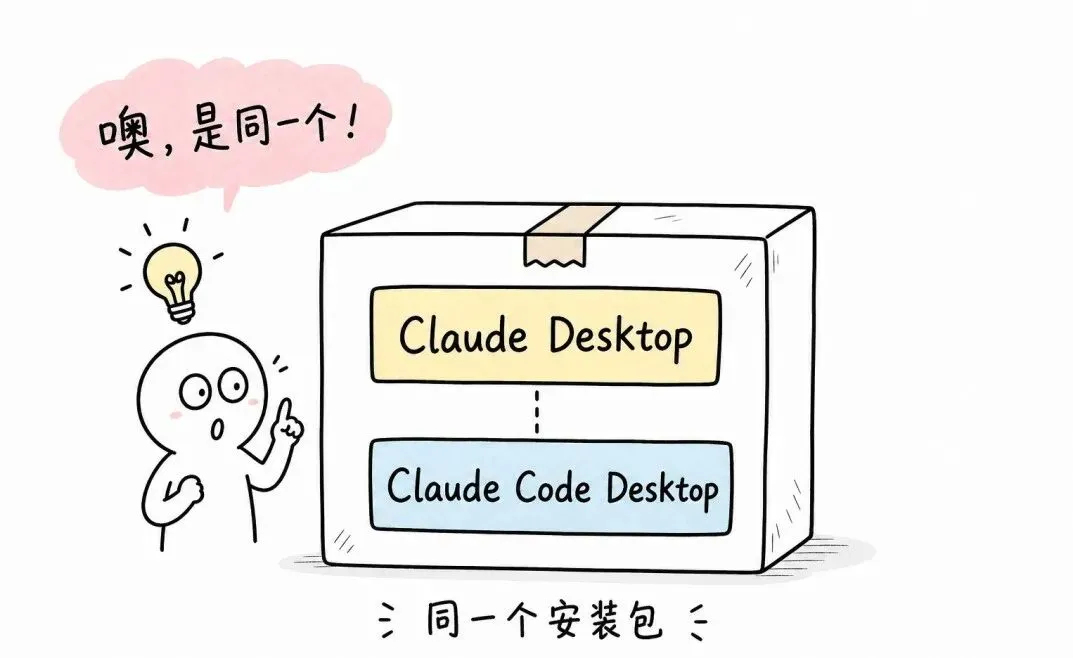
实际上就是同一个 App。
只是这个 App 在不同时期、不同业务线,文档站起了不同的名字。下载下来是一个安装包。
我让它做「交叉验证」才发现的:去官方下载页看是不是一个安装包、去 FAQ 翻有没有「X 和 Y 是什么关系」、去官方博客看历史改名记录。它做完才说:「噢,是一个东西。」
整份对比要从「两个 App 对比」改成「同一个 App 的两种使用模式」,差远了。
补 v1.2 纪律:名字不同不代表实体不同。当同一概念在不同官方文档站出现不同叫法时,必须先做交叉验证(下载页、FAQ、博客)再下判断。
v1.3:抓出我之前被另一个 AI 带偏的判断
场景:5 月 15 日,我让 AI 帮我整理三份对比清单给团队:「Cursor Rules vs Anthropic Skill」「AGENTS.md 跨工具兼容性」「always-on Rule 的最佳实践」。
没用之前:第二份清单里写「AGENTS.md 是开放标准,Cursor、Codex、Claude Code 都原生支持 ✅」。
这话不是 AI 这次自己想出来的。是我之前跟另一个 AI 聊「AGENTS.md 是行业标准」时,它顺嘴推断「既然是开放标准,那同类 AI 工具都该支持」,我就信了,记在脑子里、又口头传给了这次的 AI。
用了之后:fact-check 跑出来的报告里,有一行让我心一沉:
「Claude Code 官方明确写 reads CLAUDE.md, not AGENTS.md,不支持原生读 AGENTS.md。」
我愣了一下。我之前一直觉得「AGENTS.md 谁都支持」是个常识,居然是从一次 AI 顺嘴推断里来的,我自己根本没核实过。
幸亏跑了 fact-check,否则这条「权威错」就要进团队 wiki 了:说得很笃定、引一堆背书,但核心结论不对。看的人一旦把 AGENTS.md 配给 Claude Code,怎么都跑不通,回头还以为是自己配错了。
补 v1.3 纪律:「行业标准」不等于「每家都支持」。跨工具支持声明必须每家工具独立去官方文档查 explicit 的支持声明,不能默认推断。
v1.4:细化一遍又抓出两个
场景:那三份对比短版做完后,我让 AI 帮我把每一条都加上举例和反例,做成详细版。
没用之前:详细版里加了两个看起来很合理的例子:
「.cursor/rules 只有 Cursor 看到,.codex/ 只有 Codex 看到 → 都是工具私有格式」
「Claude 现在是 200k token,always-on Rules 一多就挤爆上下文」
用了之后:fact-check 又抓出两个。
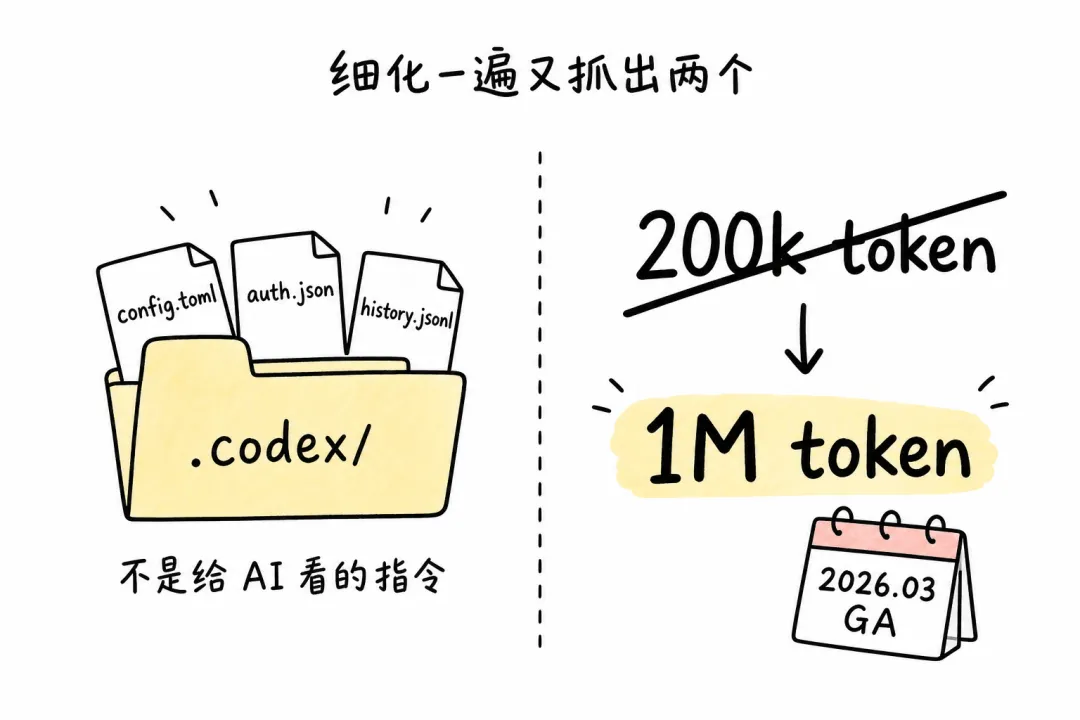
第一个,.codex/ 这个目录根本不是「Codex 的私有指令格式」。它是 Codex 的配置目录,存的是 config.toml、auth.json、history.jsonl 这种东西。说白了就是 Codex 自己的设置和登录信息,不是用户写给 AI 看的指令。Codex 真正给 AI 看的指令文件,用的是开放标准 AGENTS.md。
我把它当反例举,是错位的。应该换成 .windsurfrules 那种真正「只服务一家工具」的格式。
第二个,「Claude 现在是 200k token」这句话半年前写是对的。今天再写就是错的。Claude Sonnet 4.6 / Opus 4.6(2026 年 3 月 13 日起 GA)已经是 1M token。
补 v1.4 纪律:
1.看到 .xxx/ 目录名别想当然,先去查官方 docs 那个目录到底是「配置」还是「私有指令」
2.上下文窗口、价格、版本号这种时间敏感的「现状数字」必须当场查最新官方源,不能信作者写的时候的数字
4 次迭代的共同点
回头看这 4 个版本,每一条新加的纪律都不是我空想出来的:
这跟我以前写工作流文档完全不一样。
以前写文档,我习惯先把「所有可能踩的坑」想一遍,写进去。听起来很周全,但实际上你想不到的坑它一定会踩。
那些坑只能在真实场景里冒出来。
skill 也一样。第一版只能写到「最少能跑」的程度,剩下的纪律全靠它自己跑出来被打脸、再回头补。
那这种「打脸式迭代」危险吗?
危险。但它是唯一可靠的路径。
如果我不让它在真任务里跑,我永远不会发现它会「静默合并声明」,也永远不会发现「Claude 200k token」这句话已经过时了。
写在后面
写完这一轮,我对「AI 给 AI 审稿」这件事有了新的理解。
很多人以为,AI 之间是「自证陷阱」:A 编了一段错话,B 看不出来,因为 B 跟 A 是同一拨训练数据训出来的,两个 AI 会串通。
但 fact-check 这一轮跑下来,我发现并不是。
AI 不会跟 AI 串通。AI + 工具 + 纪律,才会跟 AI 翻脸。
原因是 B 根本不是「另一个 A」。
B 是 A 加上一套工具、加上一套纪律。A 的目标是写得通顺,B 的目标是找到原文。A 用脑子里的记忆(有截止日的训练数据),B 必须当场去拉实时官方文档。A 没人逼它「找不到不许猜」,B 被强制了。
所以 B 抓 A 的,不是它自己的智慧,是「实时世界」。官方文档才是真正的裁判,B 只是搬运工。它甚至会抓出我之前跟另一个 AI 对话时被顺嘴带偏的判断,因为带偏那次也是「靠记忆」,跑 fact-check 时 B 拿的是「实时 docs」。
反过来也成立。如果让 B 去审一段「我建议你这样做」的方法论,外部没有官方源可查,B 跟 A 一样只能凭感觉,结论会高度相似。这就是为什么 fact-check 写明「跳过方法论不审」:不是看不上,是真的审不了。
但前提是你得给它纪律。没有纪律的 B,确实会跟 A 串通(「差不多就是这样吧」);有纪律的 B,会在你最不希望的地方拆穿你(「这话是错的,幸亏被拦下来了」)。
写 fact-check 的过程,本质上是在给 AI 装「自我反省」的能力。
而它装得最好的地方,不是技术多复杂,而是 4 个版本里每一条纪律都来自被自己抓现行 —— 没有这一步,纪律就是空话。
人也一样。你想自查的时候,光在脑子里转一圈不算数。得把「裁判」搬到脑子外面:数据、checklist、不留情面的朋友。
你最近被 AI 一本正经地骗过哪条信息?评论区聊聊。
👉 推荐阅读
