 夜雨聆风
夜雨聆风每个和 LLM 打过交道的人,早晚都会撞上同一堵墙:模型没有记忆。
你说"我喜欢深色主题",下一轮对话它就忘了;你纠正过三次"我是素食者",第四次它还是推荐牛排。Context window 不是记性不好——它根本就没有"记住"这个机制。它只是在每次对话里重新读一遍所有内容,然后假装自己记得。
于是所有人的第一反应都一样:把历史全塞进 prompt 不就行了?
朴素全量灌入:一个注定失败的想法
"全量灌入"在 Demo 里看起来完美。但一旦你把这条路径放进生产环境,三个致命缺陷会同时发作。我们逐个算账,看看这个方案到底有多痛。
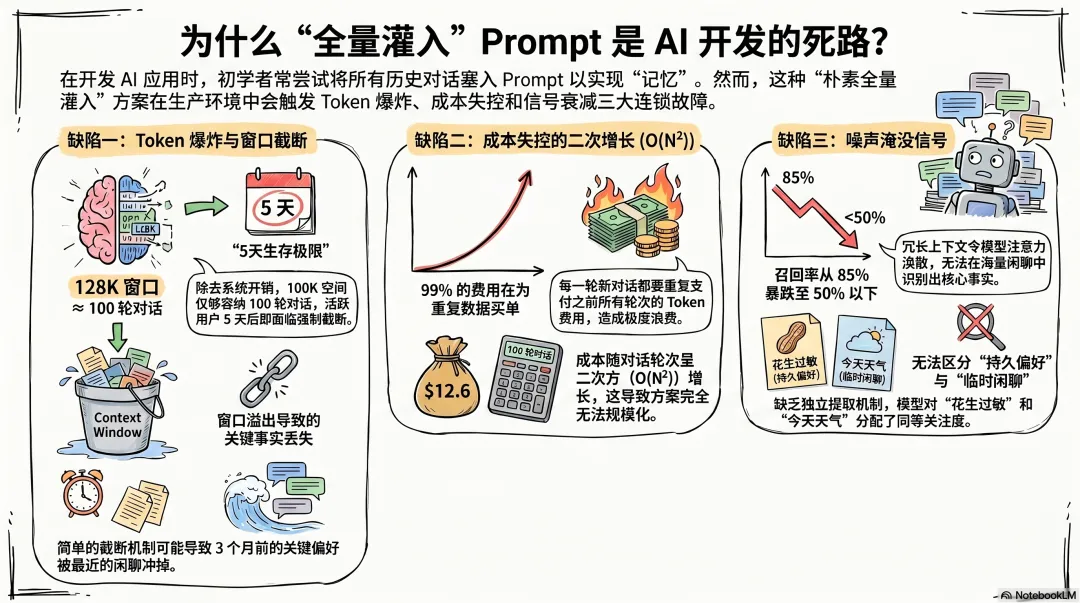
缺陷一:Token 爆炸——窗口再大也不够用
一个活跃用户的对话历史有多长?我们来算一笔真实的账。
假设一个用户每天和 AI 助手聊 20 轮对话,每轮平均 1000 token(包含用户消息 + 助手回复),一天就是 20,000 token。一个月就是 600,000 token。三个月就是 1,800,000 token。
GPT-4o 的 128K context window 看着大,但你不可能全给历史——系统提示(system prompt)通常占 2,000-5,000 token,工具定义(function calling schema)占 1,000-3,000 token,当前任务占 1,000-3,000 token。真实场景下,留给历史的窗口可能只有 100K-120K。
100K 能装多少历史?大约 100 轮对话。也就是说,用户聊了 5 天之后,第 6 天的对话就无法再包含完整历史了。你不得不做截断——但截断哪部分?截掉早期的?用户三个月前说的"我对花生过敏"可能比昨天说的"今天天气不错"重要一百倍。截掉近期的?那你丢失了当前对话的上下文连续性。
更关键的是:即使你能塞进去,也不应该塞。Context window 不是免费的——每一个你塞进去的 token 都在和当前任务争夺 LLM 的注意力。这就是第三个缺陷,我们先按下不表,先算第二个。
缺陷二:成本失控——二次增长的账单
每次请求都带上全部历史,意味着你为重复的内容反复付 token 费。这听起来像线性增长,但实际上是二次增长。
为什么?假设第 N 轮对话时,你带上了前 N-1 轮的历史。那么第 N 轮的输入 token 数约为 N × 1000(每轮 1000 token)。N 轮对话的总输入 token 数为:
总 token = 1000 × (1 + 2 + 3 + ... + N) = 1000 × N × (N+1) / 2这是 O(N²) 增长。100 轮对话的总输入 token 是 5,050,000——其中 99% 是重复付费。用户聊了 100 轮,第 101 轮的请求里 99% 的 token 都是上一轮已经付过费的重复内容。
以 GPT-4o 的价格(输入 $2.5/M token)计算,100 轮对话的输入 token 成本约 $12.6。注意这只是输入成本,还不包括输出。而且这只是 100 轮——一个真正的生产系统可能有成千上万的用户,每个用户可能聊几百上千轮。
这就是为什么"全量灌入"永远走不出 Demo。它不是一个"优化问题"——它是一个"根本不可能 scale"的问题。
缺陷三:噪声淹没信号——最隐蔽的致命伤
前两个缺陷是算账就能算出来的,但第三个缺陷更隐蔽,也更致命。
用户说"我中午吃了沙拉",这和他三个月前说"我午餐通常吃沙拉"完全不是一个层次的信息。前者是随口一提的事实,后者是持久偏好。当你把所有历史等权灌入 context,LLM 无法区分哪些是持久的偏好、哪些是随口的闲聊、哪些是已经改变的旧偏好、哪些是当前状态的描述。
为什么?因为 LLM 对 context 中所有 token 的注意力是有限的。注意力机制的本质是"在有限的信息处理能力下分配关注度"。当 context 里有 10 万 token 的历史时,LLM 对"用户对花生过敏"这个关键事实的注意力,和"用户昨天说今天天气不错"的注意力是同一个量级的——因为它们在 context 里就是两个普通的 token 序列,没有任何机制告诉 LLM "这条比那条重要一百倍"。
这不是推测。LongMemEval 基准测试明确量化了这一点:当 context 中混入大量无关历史时,LLM 对关键事实的召回率从 85%+ 降到 50% 以下。不是 LLM 不努力——是它在噪声中根本找不到信号。
三条路径通向同一个结论:你需要的不是更大的窗口,而是一个知道什么该记住、什么该忘记的独立系统。
但为什么是"独立层"?为什么不直接用向量库?
到这里,你可能已经认同"需要记忆"了。但下一个问题是:为什么需要一个"独立的记忆层"?为什么不直接用一个向量数据库?
这是一个更深层的问题。向量数据库确实能做语义检索——你把对话存进去,搜索时按相似度召回。但这只解决了"存储和检索"的问题,没有解决"提取和演化"的问题。
具体来说,如果你直接把原始对话存入向量库,你会遇到三个新问题:
噪声无法过滤。 原始对话里充满了"嗯""好的""那我们换个话题"这种零信息量的内容。如果不过滤直接存,检索时这些噪声会占据大量结果位,把真正有价值的事实挤出 top_k。 事实无法去重。 用户可能在不同对话中三次提到"我是素食者",如果你每次都原封不动存进去,检索时 top 3 结果全都是同一条信息,浪费了宝贵的召回位。 偏好无法跟踪。 用户上个月说"我喜欢 MySQL",这个月说"我转 PostgreSQL 了"。如果你只存原始对话,检索时两条都会返回,LLM 不知道哪条是最新的——因为你没有"提取→去重→关联"的机制。
所以一个能用的记忆系统必须同时具备四种能力:提取(从噪声中捞出事实)、去重(不重复存储同一事实)、关联(知道新事实和旧事实的关系)、检索(召回最相关的记忆)。向量库只能做最后一种。这就是为什么 Mem0 需要 LLM + 向量库 + 历史数据库 + 实体存储的组合——缺了任何一个,整个链条就会在某个环节断裂。
Mem0 的回答:三层交付,三种入口
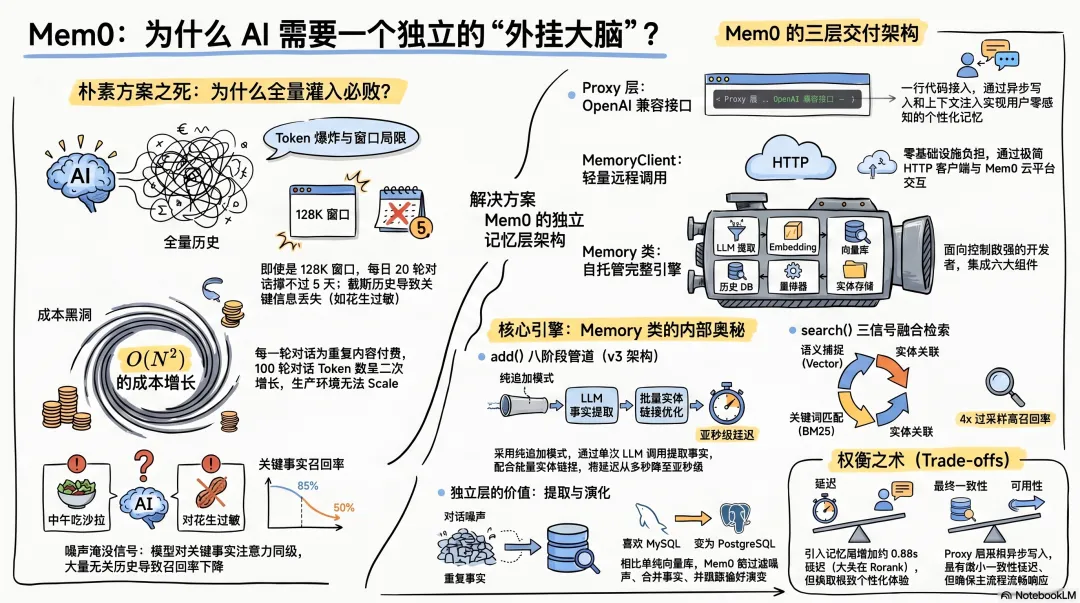 mem0 三层架构全景:Memory 类 / MemoryClient / Proxy
mem0 三层架构全景:Memory 类 / MemoryClient / Proxy
Mem0(读作"mem-zero")的架构选择很清晰——记忆不是 LLM 的附庸,它应该是一个独立的、可替换的层。这个定位体现在两个维度上:
交付层——三种部署模式对应三种需求:
pip install mem0ai | ||
docker compose up | ||
入口层——三种 API 形态覆盖三种集成方式:
mem0.memory.main.Memory | ||
mem0.client.main.MemoryClient | ||
mem0.proxy.main.Mem0 |
这个设计不是随意为之。三者的关系是一个精确的权衡谱:控制力从左到右递减,接入成本也从左到右递减。 你需要的是精细控制还是快速集成?答案决定了你站在谱的哪一端。
下面逐一拆解。
Memory 类:自托管的完整引擎
这是 Mem0 的核心。如果你选择 SDK 模式,你拿到的就是这个类。它的 __init__ 像一份宣言,告诉你一个独立的记忆层到底需要什么:
classMemory(MemoryBase):def__init__(self, config: MemoryConfig = MemoryConfig()):self.embedding_model = EmbedderFactory.create(...)self.vector_store = VectorStoreFactory.create(...)self.llm = LlmFactory.create(...)self.db = SQLiteManager(...)self.reranker = RerankerFactory.create(...) # 可选self._entity_store = None# 懒加载六个组件,每一个都不可或缺。为什么是这六个?因为缺了任何一个,记忆链条就会断裂:
embedding_model —— 把文本压缩为向量。这是记忆层存在的前提:只有把自然语言变成数学空间中的点,你才能做相似度检索,才能只召回相关记忆而不是全量灌入。没有它,你只能做精确关键词匹配——用户搜"不吃肉"就找不到"素食者",因为字面上没有重叠。默认使用 OpenAI 的 text-embedding-3-small。
vector_store —— 记忆的持久化层。它存储向量和元数据,支持语义检索。为什么不能只用 SQLite?因为 SQL 的 LIKE 查询不是语义检索——"偏好深色主题"和"喜欢暗色模式"语义相同但字面不同,SQL 找不到。只有向量相似度检索才能跨越字面的鸿沟。Mem0 通过工厂模式接入了十几种向量数据库,你换了数据库不用改一行业务代码。这是"独立层"的关键——记忆的存储与 LLM 解耦。
llm —— 负责"提取"而非"生成"。这是最反直觉的设计:记忆层自己也需要 LLM。为什么?因为原始对话里充满了噪声,你不可能把原始消息直接存为记忆。想象用户说:"嗯,好吧,那我觉得深色主题可能更适合我,之前一直用浅色的,眼睛有点累。"这条消息里只有"用户偏好深色主题,之前用浅色,原因是眼睛累"这一条事实。其余全是语气词和犹豫。LLM 的工作就是从这种噪声中提取出干净的事实——这个过程叫"记忆提取"(Memory Extraction)。默认使用 gpt-5-mini。
为什么不能用规则提取?比如用正则匹配"我喜欢X"?"我喜欢深色主题但有时候也用浅色"你怎么匹配?"我觉得还是暗色模式好一点"你怎么匹配?自然语言的多样性使得规则提取在实践中完全不可行——你必须用 LLM 理解语义。
db (SQLiteManager) —— 记忆的变更历史。为什么记忆层需要数据库?因为记忆不是一次写入就完事的——它会被更新、合并、删除。你需要知道一条记忆是什么时候创建的、什么时候被修改过、修改前的内容是什么。这不是"nice to have"——当你发现某条记忆是错误的,你需要追溯到它是从哪次对话中提取出来的。SQLite 记录每一条记忆的 ADD/UPDATE/DELETE 事件,让你可以追溯任何一条记忆的完整生命周期。
reranker —— 二次排序。为什么向量检索的结果需要重排?因为"语义相似"不等于"上下文相关"。用户问"我不吃肉",向量检索最相似的结果可能是"用户不喜欢吃水果"(都涉及饮食偏好的否定句),但真正相关的是"用户是素食者"。Reranker 用更精细的模型(通常是 cross-encoder)重新评估每条结果与查询的相关性,把信号从噪声中捞出来。
entity_store —— 实体存储,懒加载。这是 Mem0 2026 年 4 月算法升级的核心新增:从记忆中提取实体(人名、地点、偏好类别),独立存储并关联到记忆。为什么需要独立的实体存储?因为纯语义检索对专有名词的匹配能力很弱——用户搜"张三",语义检索可能找到"李四"(都是人名,语义相似度高),但用户要的是精确匹配。实体存储用精确的文本匹配 + 向量相似度的组合,解决了专有名词召回的问题。
这六个组件通过工厂模式创建,配置全部集中在 MemoryConfig:
classMemoryConfig(BaseModel): vector_store: VectorStoreConfig llm: LlmConfig embedder: EmbedderConfig history_db_path: str reranker: Optional[RerankerConfig] = None version: str = "v1.1" custom_instructions: Optional[str] = Noneversion: str = "v1.1" 这个字段值得注意。它不是软件版本号,而是 API 行为版本——不同版本的 add() 返回格式不同。这是一个在生产系统中持续演进的信号。
add():八阶段管道,一次 LLM 调用
理解了组件,再看 add() 方法——这是记忆层最核心的写入路径。当前架构(v3)采用了一个精心设计的八阶段管道:
Phase 0: 上下文收集 → 从 SQLite 取最近 10 条消息作为上下文Phase 1: 现有记忆检索 → 向量搜索找到 top-10 相关已有记忆Phase 2: LLM 提取 → 单次调用,从对话中提取关键事实Phase 3: 批量嵌入 → 一次性编码所有提取出的记忆文本Phase 4: 逐条处理 + Hash 去重 → MD5 去重,跳过已有记忆Phase 5: 批量持久化 → 一次性写入向量库 + 批量写历史Phase 6: 批量历史记录Phase 7: 实体链接 → 批量提取实体、嵌入、搜索、插入/更新Phase 8: 保存消息 + 返回有两个设计选择特别值得关注:
单次 LLM 调用。 旧版算法对每条记忆做 ADD/UPDATE/DELETE 三路判断,需要多次 LLM 调用。v3 改为"纯追加"模式——只提取,不修改。一次 LLM 调用搞定所有提取,延迟从多秒降到亚秒级。为什么只需要一次调用就够了?因为"提取事实"和"管理状态"是两种完全不同的认知任务——提取只需要理解语义,管理状态还需要判断增删改关系。当你把管理状态的任务交给下游的 hash 去重和检索评分时,LLM 只需要做它最擅长的事:理解语义。代价是记忆可能冗余(同一事实可能被多次提取),但 Hash 去重机制在写入时消除了大部分冗余。
实体链接的批量优化。 Phase 7 不是逐条处理实体,而是先做全局去重(收集所有记忆的实体),再批量嵌入、批量搜索已有实体,最后一次性批量插入新实体。这意味着 10 条新记忆涉及 30 个实体时,只需要 3 次批量操作而非 30 次单次操作。为什么必须批量?因为每次嵌入和搜索都是一次网络请求——30 次串行请求的延迟可能超过 10 秒,而 3 次批量请求可以在 1 秒内完成。
search():三信号融合检索
写入是为了读取。search() 方法的检索路径同样是多信号融合的:
Step 1: 预处理查询 → BM25 词形还原 + 实体提取Step 2: 查询嵌入Step 3: 语义搜索 → 向量相似度,过采样 4xStep 4: 关键词搜索 → BM25,同样的过采样Step 5: BM25 分数归一化Step 6: 实体加权 → 匹配查询中的实体,给关联记忆加分Step 7: 构建候选集Step 8: 多信号融合排序 → 语义 + BM25 + 实体,加权融合Step 9: 格式化结果Step 10: 可选 Rerank关键洞察:没有任何单一检索信号是足够的。 纯语义搜索分不清"我不用 MySQL"和"我用 MySQL"(语义太接近,向量几乎重合);纯关键词搜索分不清"不喜欢辣"和"喜欢微辣"(词重叠太多,BM25 给出几乎相同的分数)。只有三者融合——语义捕捉意图、关键词捕捉精确匹配、实体捕捉结构关联——才能达到 LoCoMo 91.6 分的水平。
为什么需要过采样 4x?因为任何单路检索都有遗漏。语义搜索可能漏掉精确关键词匹配的记忆,BM25 可能漏掉语义相关但字面不同的记忆。4x 过采样意味着你请求 top_k=20 时,每路检索返回 80 个结果,然后融合排序从中选出最好的 20 个。代价是检索量增大 4 倍,但这是保证召回率的必要成本。
MemoryClient:远程 API 的薄壳
如果你不想管向量库、不想管 LLM、不想管任何基础设施,MemoryClient 是你的选择。
classMemoryClient:def__init__(self, api_key=None, host=None, client=None):self.api_key = api_key or os.getenv("MEM0_API_KEY")self.host = host or"https://api.mem0.ai"self.client = httpx.Client(base_url=self.host, ...)它的结构极简:一个 httpx 客户端,所有方法都是对 Mem0 云平台 API 的 HTTP 调用。add() 调 POST /v3/memories/add/,search() 调 POST /v3/memories/search/,get_all() 调 POST /v3/memories/。
值得注意的是它的参数校验与 Memory 类完全对齐——user_id、agent_id、run_id 必须通过 filters 传递,不接受顶层参数。这不是巧合,而是刻意的设计一致性:无论你用本地 Memory 还是远程 MemoryClient,API 契约是同一个。 切换部署模式不需要改业务代码。为什么这很重要?因为你可能从 SDK 原型开始,验证可行后迁移到自托管服务,最后上云——如果每次迁移都要改业务代码,迁移成本会让你永远停在原型阶段。
Proxy 层:OpenAI 兼容的魔法接口
第三种入口是最优雅的。Mem0 类(注意:这不是 Memory,是 mem0.proxy.main.Mem0)实现了一个 OpenAI 兼容的 chat 接口:
classMem0:def__init__(self, config=None, api_key=None, host=None):if api_key:self.mem0_client = MemoryClient(api_key, host)else:self.mem0_client = Memory.from_config(config) if config else Memory()self.chat = Chat(self.mem0_client)调用方式对 OpenAI SDK 用户零学习成本:
from mem0 import Mem0mem0 = Mem0(api_key="your-key")response = mem0.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": "推荐个餐厅"}], user_id="alice")Proxy 层在背后做了三件事,用户完全无感:
异步写入记忆 —— 用户的新消息被扔进后台线程调用 mem0_client.add(),不阻塞主流程 检索相关记忆 —— 用最近 6 条消息构造搜索查询,调用 mem0_client.search() 注入上下文 —— 把检索到的记忆格式化为"Relevant Memories/Facts"前缀,拼接到用户消息前,然后交给 litellm 调用实际 LLM
这三个步骤的执行顺序是关键:先写再读。为什么不先读再写?因为新消息可能包含当前对话的关键上下文。假设用户说"我上次说的那个方案,还是算了吧"——如果你先读再写,检索时还找不到"上次说的那个方案",因为你还没写进去。先写确保后续检索能覆盖到最新的记忆。而异步写入意味着用户不会感知到任何延迟。
但这里有一个微妙的问题:既然是异步写入,那"先写再读"中的"写"可能还没完成就开始"读"了怎么办?答案是:Proxy 层的异步写入只是把任务提交到后台线程,实际的 add 操作会在后台完成。检索时不依赖本次写入的结果——它依赖的是之前已经持久化的记忆。本次写入的记忆要到下一次检索才能被召回。这是一个可接受的 trade-off:你牺牲了"同一轮对话内的新记忆立即可检索"的能力,换来了"用户零感知的延迟"。
Proxy 层的代价也显而易见:你失去了对记忆提取和检索的精细控制。你不能自定义提取 prompt、不能调 BM25 参数、不能控制实体链接的行为。它是一个"80/20 方案"——80% 的场景只需要 20% 的控制力。
独立记忆层的代价
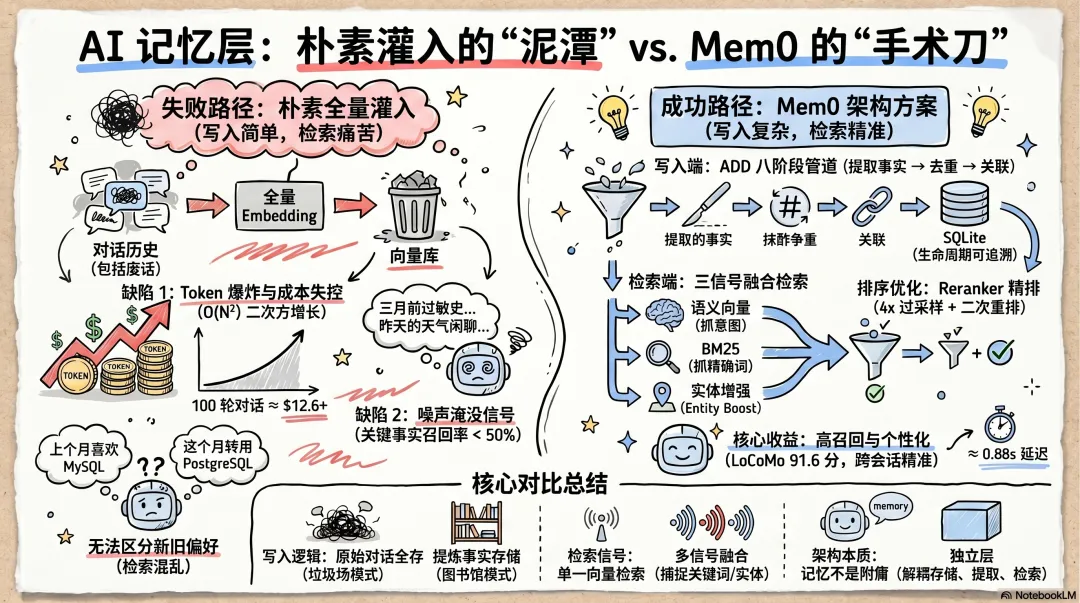 朴素全量灌入方案 vs mem0 的 ADD + 三信号检索
朴素全量灌入方案 vs mem0 的 ADD + 三信号检索
技术选择从来不是免费的。一个独立的记忆层引入了三组必须正视的权衡:
延迟 vs 个性化。 每次对话前多一次向量检索 + 可选的 rerank,p50 延迟增加约 0.88 秒(LoCoMo 基准数据)。对于实时性要求极高的场景(高频交易、实时游戏),这个延迟可能不可接受。但对于客服、助手、知识管理这类场景,不到 1 秒的延迟换来的是跨会话的个性化体验——这几乎总是值得的。
但我们需要追问:这 0.88 秒花在了哪里?语义检索(一次向量搜索)约 50-100ms,BM25 检索约 20-50ms,实体加权约 50-100ms,Rerank 约 200-500ms。大头在 Rerank——如果你不用 Rerank,p50 延迟可以降到 0.3-0.4 秒。这是 Mem0 把 Rerank 做成可选组件的原因:不是所有场景都需要最精细的排序,但所有场景都需要记忆检索。
一致性 vs 可用性。 记忆是异步写入的(Proxy 层尤其明显),这意味着用户说了"我是素食者",下一次请求可能还没生效。这是 eventual consistency——和分布式系统里同样的问题,同样的解法:如果你的场景要求强一致性,就用同步写入的 Memory 类而非异步的 Proxy。架构给了你选择权。
但 eventual consistency 的影响到底有多大?用户说"我是素食者"后紧接着问"推荐个餐厅",新记忆可能还没入库。但此时检索到的旧记忆里可能已经有了"用户不喜欢吃辣""用户偏好健康饮食"等相关信息,LLM 仍然会给出合理推荐。真正出问题的是用户说"别再推荐意大利菜了"后立即问"推荐个餐厅"——如果这条否定记忆还没入库,LLM 可能仍然推荐意大利菜。这种场景下,同步写入是唯一的安全选择。
系统复杂度 vs 可复用性。 六个组件、八阶段管道、三信号检索——这比"全量灌入 prompt"复杂了几个数量级。但这个复杂度换来了可复用性:同一个记忆层可以服务于客服机器人、个人助手、代码 Agent,它们共享同一条记忆("用户偏好深色主题"),但各自只检索自己关心的子集。没有独立记忆层,每个 Agent 都要自己造一套记忆机制,重复且不一致。
更深一层:为什么"共享记忆"这么重要?因为用户不会对客服机器人说一遍偏好,再对个人助手说一遍,再对代码 Agent 说一遍。用户的偏好是统一的——他喜欢深色主题,不管在哪个 Agent 里都一样。如果每个 Agent 各自维护记忆,就会出现客服机器人知道"用户是素食者"但个人助手不知道的荒谬场景。独立记忆层确保了用户画像的一致性,这是多 Agent 系统的基石。
这些权衡指向同一个结论:独立记忆层不是万能药,但对于需要个性化、需要跨会话持续性、需要多 Agent 共享记忆的系统,它是目前最务实的解法。 Mem0 的架构本质上是在说——记忆和推理是两个不同的问题,它们值得被分开解决。
下一篇,我们将深入 Memory.add() 的八阶段管道,看 Mem0 如何用一次 LLM 调用完成记忆提取,以及"纯追加"模式背后的工程权衡。
