 夜雨聆风
夜雨聆风
AI视频角色总崩?「斜修四步法」让你的主角从头稳到尾
上周发了那篇《AI视频不是靠提示词,是靠资产库》之后,有不少朋友来问,思路懂了,但具体怎么建资产库呢。
说实话我也在想这个问题。我自己的方法不够系统,所以花了一些时间去研究,把目前最完整的方案梳理了出来。
然后发现了一套让我觉得「这也太系统了」的四步法。
上一篇文章我一直在讲一个道理,AI视频做不好,不是工具不行,是你还在用「单次生成」的思维做AI视频。真正稳定的AI视频,靠的是建立可复用的素材资产库。
但那篇文章只讲了为什么,没讲怎么做。
所以今天就顺着上篇,把四步法完整拆给你看。
每一步都有工具名、有参数、有踩坑点。不是那种「多试试几个种子」「提示词写得再细一点」的玄学建议,是真的可以照着做的操作手册。
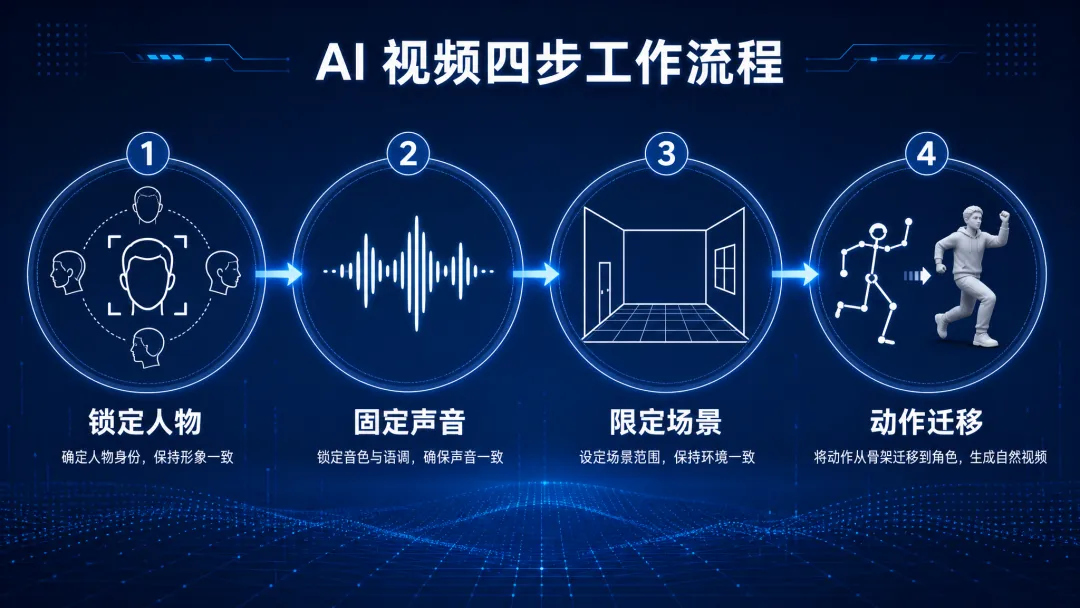
四步分别是,锁定人物、固定声音、限定场景、动作迁移。
一个一个来。
以前我做过一个很蠢的尝试。
我花了一下午坐在电脑前面,用某个AI视频工具,想生成一个女孩在咖啡馆里说话的连续镜头。第一条视频,还挺好的。女孩坐在靠窗的位置,头发扎起来,穿一件米白色毛衣,端着咖啡杯。
我还挺满意,心想AI视频进化得真快。
然后我生成第二条。
脸变了。
不是发型变了、角度变了那种变,是整个人的五官结构都不一样了。像换了一个演员,但穿了一模一样的衣服。
我当时就愣住了。
硬着头皮又试了第三条,这下发型也变了,咖啡馆也变了,从明亮简约风突然变成了暗色调工业风。
不是哥们。。。
我只是想让同一个人继续说下一句话,不是让她转世。
后来我才知道,这个问题几乎是所有AI视频工具的硬伤。因为每次生成都是独立的,模型不记得上一条视频里的是谁。它只是根据你的提示词重新「想象」一个角色出来。
这才是AI视频不稳定的根源。
不是你的提示词不够细。不是工具太垃圾。是你在让AI每次都重新发明轮子。
而「斜修四步法」解决的正是这个问题。它的核心逻辑很简单,先把轮子造好,以后每一次只需要组装的轮子,不需要重新造。

然后说第一步,锁定人物。
这一步是整个四步法的基础。你得先给角色建立一套标准的「证件照」,让AI知道这个人长什么样。
具体怎么做呢。
先打开豆包,切到专家模式。把你要做的那个故事脚本扔进去,让它帮你生成主角的形象描述,以及对应的AI绘画提示词。
为什么要用豆包而不是直接写提示词。因为豆包能理解故事语境,它知道「一个30岁离职创业的女性」应该长什么样、穿什么风格的衣服、留什么发型。你自己写的话很容易遗漏细节,漏一个细节AI就自己脑补一个,脑补多了角色就不像了。
拿到形象描述和提示词之后,打开Lip TV,新建一个图像节点。
模型选Nano Banana。比例选16:9。
在提示词里,把刚才豆包帮你生成的描述加上这句话,「左侧生成人物近景照,右侧生成全身设定图」。
这一步很关键。一图两用,近景照用来做人脸参考,全身图用来做服装和体态参考。以后你每生成一条新的视频,都@这两张图,人脸就不会跑了。
但这还不够。
同一个角色只有一张正面照,AI还是容易崩。因为你可能会让他转头、侧脸、低头看手机。这些角度AI都没见过,它怎么办?只能猜。一猜就崩。
所以你还得补充多角度视图。再新建几个图像节点,分别生成正脸、侧45度、侧90度、背面,还有一个面部特写。
这就是你的角色资产库。
听起来步骤很多,但其实你只需要做一次。一个角色从零到建完资产库,大概20分钟。建完之后,你每次做新视频,把设定图连上去就行。
这一步最常踩的坑是什么。参考图不够「干净」。
什么叫不干净。就是你生成的参考图里,角色站在一片杂乱背景前面,身上一堆配饰,光线还很复杂。这种图AI根本提取不出准确的面部特征。
记住一句话,参考图越素,生成越稳。纯色背景,正面光源,去掉首饰墨镜帽子这种遮挡物。
如果这一步做好了,AI视频最大的痛苦「变脸」,就解决了。
说真的,光这一步,就能省掉你以前80%的「抽卡」时间。

第二步,固定声音。
人是视觉动物,看到脸变了会立刻发现。但声音变了,很多人反而注意不到。
但你的观众能感觉到。
他们可能说不出来哪里不对,但就是觉得「这条视频跟上次看的不太一样」「怎么怪怪的」。这种说不清的违和感,比脸崩了更可怕,因为它不会立刻被察觉,但它会慢慢消耗观众的信任。
固定声音有两条路。
第一条路,从零创建一个声音。在Lip TV里新建一个音频节点,模型选MiniMax Beat。把你准备好的台词输进去,别只输文字,把停顿和语气词也标上。
比如「大家好我是大风扇(停顿)今天我们来聊一个让很多做AI视频的朋友非常头疼的问题」。
MiniMax Beat这个模型厉害在它能理解语气。你选一个「优雅甜美」或者「沉稳冷静」的音色,它会自动匹配语调。不像有些TTS,一句话从头平到尾,听得人想睡觉。
做完这些之后,新建一个视频节点,把刚才建好的人物设定图和这个音频节点都连上去。模型选 seedance 2.0全能参考模式,@刚才建的所有素材,点生成。
第二条路,复用你已有的声音。
如果你之前生成过一条很满意的视频,里面人物的声音特别好听,但你没保存当时的音频参数,怎么办。
先把那条视频下载到本地。打开剪映,把视频拖进去,分离音频。截取那个角色的声音片段,导出MP3。
然后回到Lip TV,新建音频节点,把这段MP3导入。后面的操作跟第一条路一样。
不管走哪条路,声音资产库建好以后就不要再动了。同一个人物,所有视频都用同一个声音。观众在任何一个视频里听到的是同一把嗓子,你就在不知不觉间建立了「这个账号的声音辨识度」。
我有时候觉得,声音的一致性比脸的一致性还重要。因为脸崩了观众能看出来,但声音变了,观众只会觉得浑身不舒服,又说不清为什么。这种莫名其妙的「掉粉感」,才是最致命的。

第三步,限定场景。
很多AI视频博主做到前三步就停了。人物建好了,声音固住了,心想这下稳了吧。
然后场景崩了。
你让角色坐在咖啡馆里,第一次是北欧风简约咖啡厅,第二次变成了美式复古咖啡厅,第三次变成了不知道哪里的暗黑工业风。
咖啡还是那个咖啡,但咖啡馆换了三个城市。
场景控制的核心是「先建空场景,再放人进去」。
新建一个图片节点,写场景描述提示词,模型还是Nano Banana。但这次提示词里不要出现人物,只描述空场景。比如「明亮的咖啡馆窗边,上午十点的阳光打进窗户,白色大理石桌面,桌上有一杯拿铁和一本翻开的笔记本」。
先生成空场景画面。
然后关键的一步来了。把场景图接上之后,再新建一个图像节点,生成这个场景的「立体空间四宫格」。就是把场景从四个角度展示出来,像一个房间的四面墙被打开展平。
接着打开任何一个修图软件,在四宫格上标注人物应该站的位置、面向哪个方向。
最后新建视频节点,把人物设定图、标注了位置的场景图、未标注的场景图一起连上去。提示词里@引用这些素材。
听起来很繁琐是不是。
但你再想想你之前每次重抽花了多少时间。建一个场景资产库需要15分钟。每次「抽卡」到崩溃需要两个小时。
哪个更高效,你比我清楚。

第四步,动作迁移。
这一步是四步法里最让我觉得「卧槽」的一步。
你做AI视频的时候肯定遇到过这种场景,想让角色自然地抬起右手,指向画面外的某个东西。提示词里写了「右手抬起指向右侧」,结果生出来的是角色在挥手、在挠头、在旋转跳跃闭着眼。
就是不做你让它做的。
AI不懂「抬手」是什么。它只会从训练数据里找一个最像「抬手」的片段拼给你。但训练数据里「抬手指向远方」「开心地挥手」「挠头发」看起来动作都差不多,AI分不清。
所以别再跟提示词较劲了。
动作迁移的思路完全相反。不是用文字描述动作给AI听,而是直接拍一段动作视频给它看。
你找个朋友,或者自己架个手机,对着镜头做一遍你想要的动作。不用专业设备,手机就行。光线清楚、动作干脆、背景简单,三个要点。
然后把这段视频导入可灵3.0,新建一个视频节点,把示范视频和人物设定图都连上去。
模型选可灵3.0动作迁移。
提示词简单写就行,甚至不写都可以。因为你要的不是AI「理解」你的文字描述然后「想象」一个动作,你要的是AI直接把示范视频里的动作,原样复刻到你的角色身上。
我当时第一次试这招的时候,真的给我一下子整不会了。
之前花了无数时间调提示词、换种子、换模型,结果搞定这事儿的方法就是,直接拍给它看。
太简单了。
简单到我一开始不相信这能行。
但它就是能行。

这四条讲完了。我知道你可能在想,这也太麻烦了吧,建完四套资产库得花多少时间。
我跟你说个我自己的账。
我以前做AI视频的流程是,写提示词2分钟,生成1分钟,发现脸变了,改提示词2分钟,再生成1分钟,发现脸还是不对但问题变成了发型变了,再改,再生成。
一条10秒的视频,运气好20分钟出来,运气不好,一个下午就没了。最后挑出一条勉强能用的,收工。
现在呢。
一个角色资产库建好,20分钟。以后这条角色每生成一条新视频,稳定出片的概率不再是「六分之一」或者「十分之一」,而是接近「每次都能用」。
我以前一个下午可能出一条能用的片子。现在一个下午能出四五条,每一条的主角都是同一个人。
这就是系统化方法跟碰运气之间的差距。

跟上一篇文章一样,我想再次强调,AI视频工具本身没有问题。可灵3.0、Lip TV、Nano Banana、MiniMax Beat,这些都是很好的工具。但工具再强,你拿来做「一次性许愿」,它就给你一次性结果。你拿来做「工厂里的流水线」,它就给你稳定产出。
四步法说穿了就是一个流水线。流水线的上游是资产库,中游是生成,下游是你的判断和审美。
很多人以为AI时代核心竞争力是会用工具。但我觉得不是。会用工具的人太多了,每天都有新的AI教程出来,谁都能学。
真正的竞争力是,你愿不愿意花那20分钟,把别人觉得「太麻烦」的系统搭起来。
大部分人不会搭。不是因为笨,是因为懒。也不是因为懒,是因为他们总觉得「下一版工具会解决这个问题」「下个月的模型就不需要这么麻烦了」。
但说实话,我也不知道下一版会不会更好。
我只知道,今天把资产库建好的人,今天就开始稳定出片了。
明天再建的人,明天才开始。
一直等着的人,一直在等。

聊到这儿我突然想起一个词,叫「磨刀不误砍柴工」。小时候觉得很土的一句话。但现在做AI视频做久了发现,这句话是真理。
四步法就是你磨刀的过程。花20分钟磨刀,换来的是以后每次砍柴都不费劲。
但大多数人做的事是什么。拿着一把钝刀,拼命砍。砍不动了就换个方向继续砍。再砍不动了就换一把新刀继续砍。就是不磨。
AI时代磨刀这件事被严重低估了。
因为所有工具都在告诉你「一键生成」「一句话出片」「你不需要任何技能」。这些口号很诱人,但它们制造了一个巨大的幻觉,让你觉得未来不需要任何准备工作。
而真正做内容的人知道,准备才是胜负手。
准备决定了你每一条视频是「靠运气」还是「靠系统」。
好了,四步法我完整拆完了。总结一下,锁定人物,解决变脸问题。固定声音,解决「说不清的违和感」。限定场景,解决背景漂移。动作迁移,解决AI听不懂人话。
这四个资产库建好之后,每次做新的AI视频,你不是在「祈祷这一次能抽到好的」,而是在「调用你已经建好的生产系统」。
这两种感觉完全不同。
我不知道这套方法对大家有没有用,但我自己试下来,确实是我目前为止见过最系统的AI视频稳定方案。如果你也在做AI视频,或者想做但被「抽卡」折磨到怀疑人生,试试这四步。不需要一次全搭完,先从步骤一开始,把人物资产库建起来。
有些朋友上次看了《AI视频不是靠提示词,是靠资产库》,给我留言说思路打开了但不知道具体怎么弄。
希望这篇能补上那个窟窿。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标。
谢谢你看我的文章,我们,下次再见。
—— 大风扇 AI内容创作顾问

