 夜雨聆风
夜雨聆风本文是「AI 基础设施科普」系列第 4 篇。上一篇我们聊了 Prompt 工程,学会怎么"跟 AI 说清楚"。但还有一个隐藏因素在悄悄影响 AI 的表现——它的工作台大小,也就是今天的主角:上下文窗口。
一、AI 的"工作台"有多大?
想象你面前有一张桌子。你跟 AI 的每一轮对话,都是往桌上放一张纸条——你说的、它回的、你贴上去的参考文档、它生成的代码,全都在桌上。
桌子的大小,就是上下文窗口(Context Window)。
刚开始聊天时,桌上空空荡荡,你说的每一句话 AI 都看得见、记得住。但随着对话越来越长,桌上的纸条越堆越多——终于有一天,桌面满了。新的纸条放上去,最旧的就被推到地上,再也找不回来。
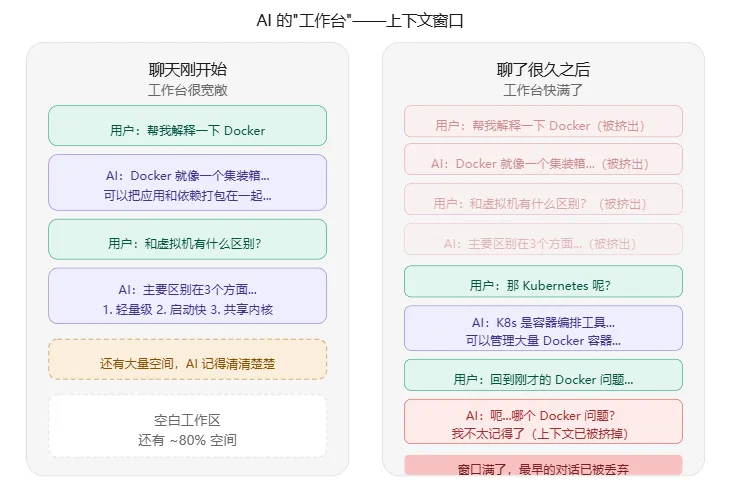
这就是为什么你会经历这种事:
前面聊了半小时 Docker,后面问"回到刚才那个问题",AI 一脸懵:“哪个问题?”
不是 AI 故意忘,是最早的对话已经被挤出了窗口,它真的看不见了。
二、Token:AI 眼中的"字数"
上下文窗口的大小,用 Token 来衡量。Token 不是字,更像是"语义片段":
经验换算:
• 1 个 Token 约 0.75 个英文单词 • 1 个汉字约 1.5-2 个 Token(中文比英文"贵")
所以一个 128K Token 的窗口,大约能装 6 万汉字。2026 年主流模型的窗口动辄 1M(百万 Token),能装下约 50 万汉字——听起来很多,但你要知道,一部长篇小说也就 30-50 万字,你跟 AI 来回聊 50 轮,加上它每次生成 500 字的回答,很快也能填满。
三、各家模型的窗口到底有多大?
2026 年二季度,上下文窗口的竞争已经白热化,形成了清晰的四个梯队:
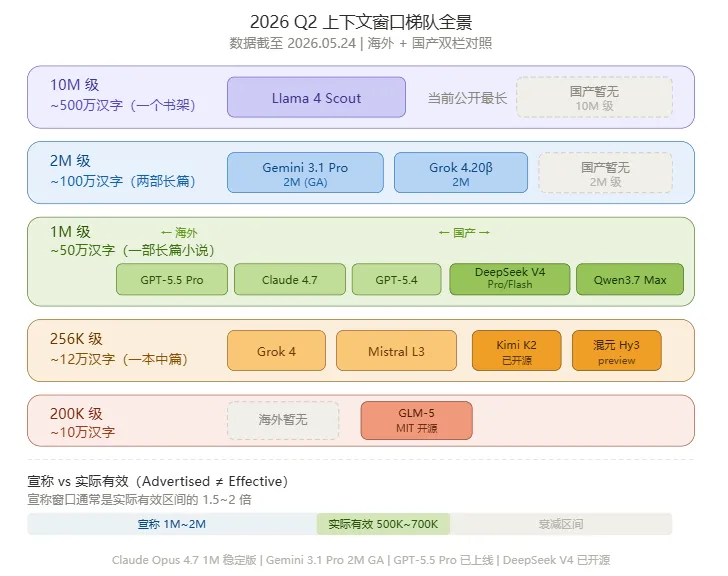
数据截至 2026.05.24。1M ≈ 50 万汉字,10M ≈ 500 万汉字(一个书架)。
几个值得注意的细节:
海外阵营
• GPT-5.5 Pro 已正式上线(4 月 23 日发布),1M 上下文,接棒 GPT-5.4 成为 OpenAI 最新旗舰;另有 GPT-5.5(标准版)和 GPT-5.5 Instant(ChatGPT 默认模型) • Claude Opus 4.7 / Sonnet 4.6 双线 1M 窗口,均已稳定可用,无长上下文溢价 • Gemini 3.1 Pro 2M 窗口已正式 GA(基于 Ring Attention),1M 以内完全稳定,1.5M 以上检索性能有衰减;Gemini 3.5 Flash(5 月 20 日发布)速度达同类 4 倍,也是 1M 窗口 • Grok 4.3(4 月 30 日发布)1M 窗口,输入成本降约 40%;Grok 4 标准版仍为 256K • Llama 4 Scout 10M 仍是当前公开最长上下文
国产阵营
• DeepSeek V4(4 月 24 日发布)分 Pro 和 Flash 两线,都支持 1M,推理成本较 V3.2 降 90%+,已开源 • Qwen3.7 Max(5 月 20 日发布)1M 上下文,Arena 盲测国产第一,支持 35 小时超长程任务 • Kimi K2(4 月 20 日发布)256K 上下文,但 13 小时不间断编码 + 300 子 Agent 并行的能力让人侧目,已开源 • 混元 Hy3(4 月 23 日发布)256K 上下文,295B 参数/21B 激活,效率提升 40% • GLM-5(2 月 11 日发布)200K 上下文,744B 参数(A40B 激活),MIT 开源
两三年前,GPT-4 的窗口只有 8K(约 4000 字),现在 1M 成了"标配",最大的到了 1000 万——涨了上千倍。而且国产模型已经不只是在追赶,DeepSeek V4 和 Qwen3.7 Max 都在 1M 梯队站稳了。
但数字大就一定好吗? 这里有个很多厂商不会主动告诉你的概念——
宣称 vs 实际有效
厂商公布的叫 Advertised Context(宣称窗口),但社区实测发现,真正能稳定利用的范围叫 Effective Context(实际有效区间),两者经常差距明显:
这就像买了个 1000 平的仓库,但只有中间 600 平能正常存取,角落的东西经常找不到。窗口越大,这个"有效区"和"宣称值"的差距往往也越大。宣称窗口通常是实际有效区间的 1.5-2 倍。
所以现在行业里真正比拼的,已经不是"谁窗口更大",而是谁能在超长上下文里还能保持推理稳定。
四、冷知识:窗口中间的信息,AI 看得最差
2023 年斯坦福大学的研究发现了一个反直觉的现象,叫做 “Lost in the Middle”(迷失在中间):
如果你把关键信息放在上下文的最开头或最末尾,AI 能准确找到;但如果放在中间,准确率会骤降到接近 0。
类比一下:你让一个人读一篇 3 万字的文章,然后问他"第 1.7 万字附近写了什么"——大概率答不上来。AI 也一样,它的"注意力"分布不是均匀的,开头和结尾最清晰,中间是盲区。
这给我们的启示:
• 最重要的指令放在开头——系统提示词、核心需求,别藏着掖着 • 最关键的信息也放在开头——"请基于以下背景回答"的背景,放在最前面 • 中间放次要细节——示例、补充说明等 • 结尾再强调一次关键要求——“记住,不要超过 300 字”
这个"开头-结尾强、中间弱"的模式,在所有主流模型上都成立,只是程度不同。
五、窗口用满了会怎样?
当对话长度逼近上下文窗口上限时,通常有三种处理方式(取决于你用的平台):
大多数产品用的是滑动窗口——你看不出异常,但 AI 已经"失忆"了。最危险的情况是你以为它还记得,它其实已经忘了。
六、四招省下你的上下文窗口
既然窗口是有限资源,那就要精打细算。以下四个方法,按"省心程度"从高到低排列:

1. 及时开新对话
聊完一个话题就新建对话,别在一个窗口里聊一天。这是最简单也最彻底的——窗口直接清零,AI 重新开始。
2. 用摘要代替原文
让 AI 先把前文压缩成一段摘要,然后把摘要贴到新对话里继续。10 页原文变成 3 行要点,窗口瞬间释放。
实操:“请把我们刚才的讨论总结为 3-5 条关键结论,我需要在新对话中继续使用。”
3. 结构化输入
同样一件事,散文式描述和结构化描述的 Token 消耗差很多:
散文版(约 200 Token): “我希望你帮我写一个用户注册功能,用户需要填写用户名、邮箱和密码,用户名要 3-20 个字符,邮箱要验证格式,密码至少 8 位包含大小写和数字,注册成功后发一封确认邮件”
结构化版(约 80 Token):
功能:用户注册
字段:用户名(3-20字符) | 邮箱(格式校验) | 密码(8位+大小写+数字)
后置:发确认邮件
同样的信息量,结构化写法省 60% Token。
4. 把记忆存到外部
如果你用的平台支持 Memory 功能(比如 MEMORY.md 文件),把项目背景、个人偏好、常用规则写进去。这样即使开新对话,AI 也能通过读取 Memory 文件恢复关键信息,不用每次都重新说一遍。
七、一个被忽视的真相:窗口越大,费用越高
如果你用的是按 Token 计费的 API(而不是包月订阅),上下文窗口的消耗直接跟钱挂钩:
• 每次对话,你发送的全部历史 + AI 的最新回复,都要重新计费 • 第 1 轮:100 Token 计费 • 第 10 轮:前面 9 轮 + 第 10 轮,可能 5000 Token 计费 • 第 50 轮:累积可能到 5 万 Token,每一轮都在为全部历史买单
所以,开新对话不只是"省窗口",也是在省钱。
一句话总结
上下文窗口是 AI 的短期工作台——有限、会满、中间容易丢东西。用好它的关键是:重要的放两头,中间放次要的,满了就开新对话,长期记忆存到外面。
下期预告:AI 怎么做到"上网搜索"、“写文件”、"查数据库"的?答案是一个叫 Tool Use(工具调用) 的机制——下一篇我们拆开看看,AI 是怎么长出"手"来的。
本文是「AI 基础设施科普」系列第 4 篇1. Skills 全解析 | 2. Memory 机制 | 3. Prompt 工程 | 4. 上下文窗口 ← 你在这里系列文章
