 夜雨聆风
夜雨聆风华盛顿大学David Baker团队在 《Nature Methods》 发表研究,推出新一代蛋白设计模型RFdiffusion2。该方法首次支持以原子级活性位点描述(theozyme)为条件,无需预先指定残基顺序或侧链构象,直接生成全新酶蛋白。在41个多样活性位点基准测试中,RFdiffusion2成功率为100%(41/41),而此前方法仅16/41。实验验证了四种不同机制的酶(逆醛缩酶、半胱氨酸水解酶、两种锌金属水解酶),仅筛选不到96个设计即获得活性,且结构完全原创(TM-score 0.47–0.54),为从头酶设计开辟了新范式。
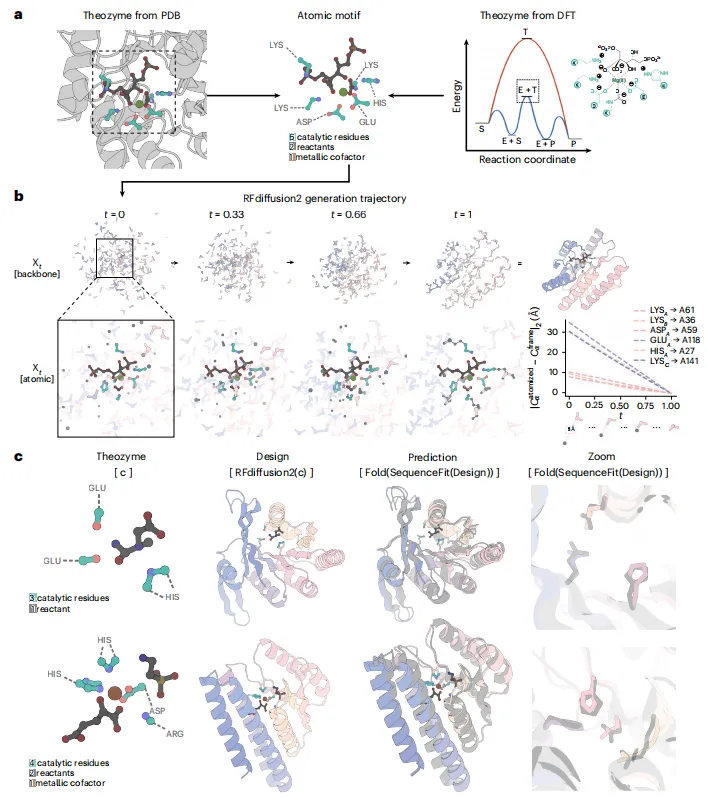
研究流程:
选择催化机理(已知酶结构或DFT计算过渡态)→ 构建原子级theozyme(含催化残基侧链原子和配体)→ RFdiffusion2生成蛋白骨架(同时推断残基索引和侧链构象)→ LigandMPNN设计序列 → 结构预测(Chai-1/AF3)筛选 → 表达纯化 → 动力学表征

一、为什么是突破?——“原子级”+“无索引”,让设计回归化学直觉
传统酶设计需将催化基团转化为带索引的残基主链,再反向搜索/扩散支架,过程复杂且受限。RFdiffusion2首次直接以原子坐标(而非残基级)作为条件,且支持“无索引残基”——即只提供原子位置,不指定是哪几个残基、在序列何处。模型自主推断侧链构象和序列索引,扩展设计空间数十个数量级,在41个多样活性位点上实现100%支架覆盖,并成功设计出多种活性酶。
二、实验逻辑+关键数据
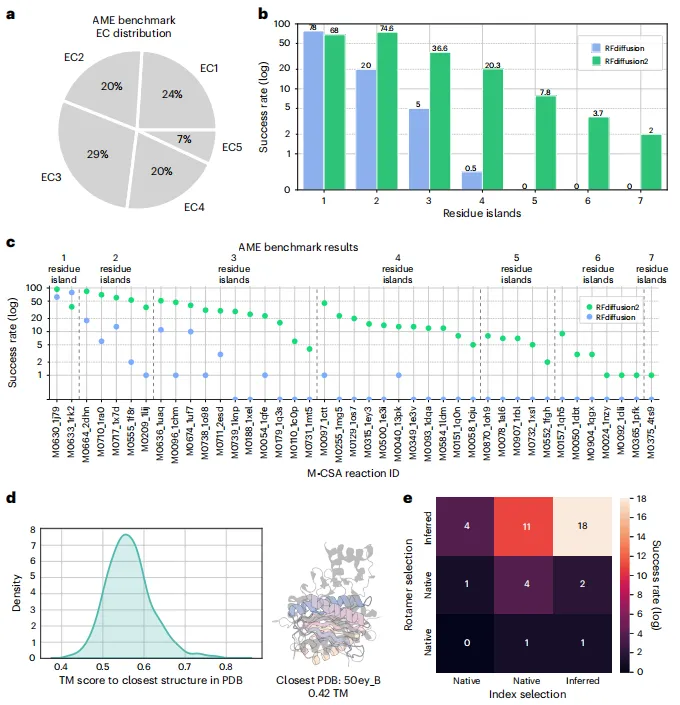
先构建高难度基准:从M-CSA数据库筛选41个催化活性位点(覆盖EC1-5类),随机抽取催化残基的部分原子作为“原子级基序”,其中包含多个不连续片段(最多7个“残基岛”)。→ 数据意义:模拟真实酶设计中最棘手的“多个不连续催化残基”支架问题。
对比RFdiffusion与RFdiffusion2:RFdiffusion2无需逆旋转异构体采样和索引枚举,直接输入原子基序即可生成。在41个案例中,RFdiffusion2全部找到合格支架(催化残基重原子RMSD<1.5 Å且无配体冲突),而RFdiffusion仅16/41成功。尤其在4–7个残基岛时,RFdiffusion成功率趋近0(图3b-c)。→ 数据意义:原子级+无索引条件化彻底解决了复杂活性位点支架难题。
消融实验证明推断能力:对比“给定天然旋转异构体+天然索引”、“随机采样”、“RFdiffusion2自主推断”三种策略。在3–6个残基岛案例中,自主推断策略表现最佳,甚至优于给定天然值(图3e)。→ 数据意义:模型自主搜索旋转异构体和索引空间比固定假设更有效。
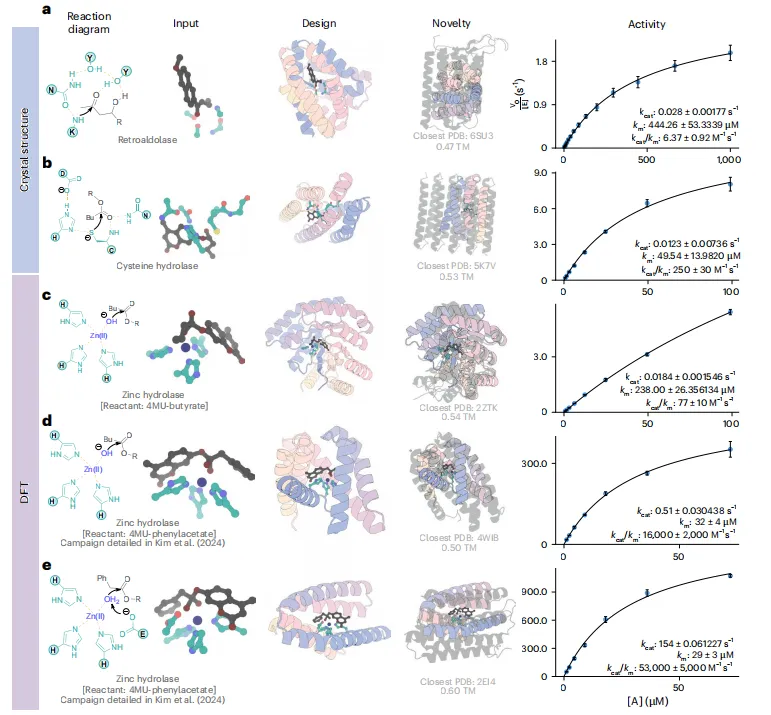
实验验证四种酶:分别设计逆醛缩酶(kcat/KM=6.34 M⁻¹s⁻¹)、半胱氨酸水解酶(248 M⁻¹s⁻¹)、两种锌金属水解酶(77和16,000 M⁻¹s⁻¹)。每个案例测试设计数≤96,均获得活性。最活跃的设计与PDB中任何已知结构无明显相似性(TM-score 0.47–0.54)。→ 数据意义:模型不仅能计算上成功,更能产出真实催化活性、结构全新的酶。
三、结果验证或讨论
流匹配(Flow Matching)替代扩散
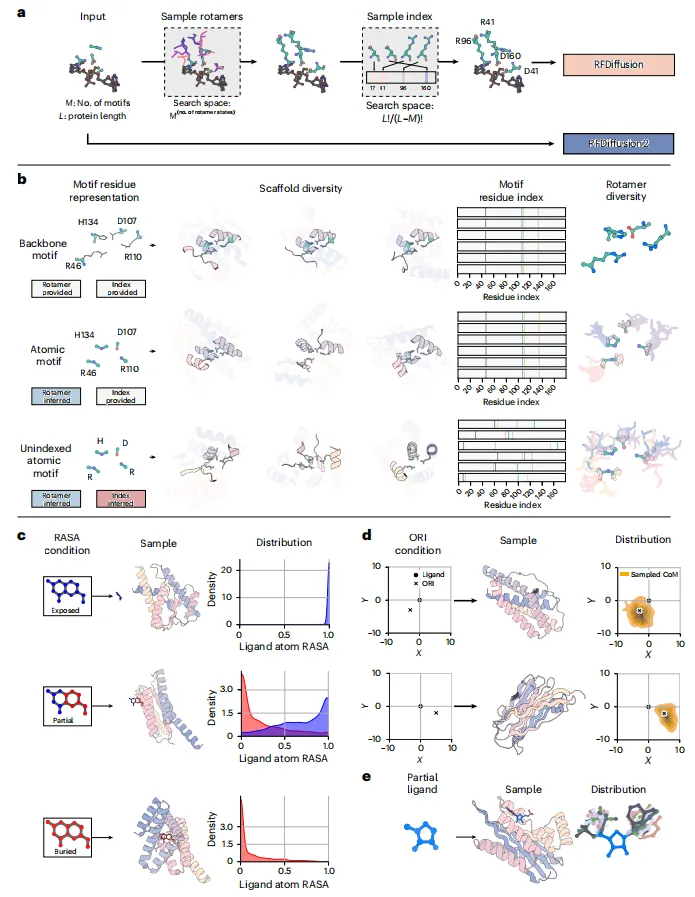
RFdiffusion2改用流匹配框架,训练更稳定,无需辅助损失或自条件化。同时引入随机中心化(stochastic centering)使模型能自主优化基序与支架的相对位置,解决了以往扩散模型在第一步偏移固定的问题。
多级条件控制
用户可为配体原子指定相对溶剂可及表面积(RASA),控制活性口袋深浅;通过ORI伪原子指定支架质心与配体的相对位置;可输入部分配体,模型补全其余构象。这些能力让设计师能精细调控酶口袋几何和埋藏程度。
无索引残基的妙用
催化三联体(如Cys-His-Asn)的残基在序列上可能相隔很远,传统方法需枚举所有索引组合。RFdiffusion2通过训练时随机“去索引化”残基,学得将无索引原子映射到骨架上的能力,一次生成即确定索引和侧链,极大简化流程。
从已知结构扩展到DFT设计
对于锌水解酶,团队未依赖天然酶结构,而是用密度泛函理论(DFT)计算过渡态几何,直接输入theozyme。RFdiffusion2据此生成支架并获得高活性酶(kcat/KM达16,000 M⁻¹s⁻¹),证明模型能从纯化学机理出发设计新酶。
四、方法优势
原子级条件化:直接使用催化残基侧链原子坐标+配体原子坐标,保留全部化学信息,无需手工将侧链转为主链框架。
无索引残基处理:通过在训练中随机遮蔽残基索引信息,模型学习将“游离”原子自动匹配到合适的主链位置并分配正确序列索引,彻底消除指数级组合搜索。
流匹配+SE(3)流:旋转和平移用黎曼流匹配,确保旋转采样的统计效率;训练不依赖预训练权重,从零开始收敛稳定。
灵活的控制接口:RASA(溶剂可及表面积)条件控制埋藏深度;ORI伪原子控制整体位置;部分配体推断生成完整配体构象。
高性能基准AME:首次发布包含41个真实催化位点的原子级支架基准,涵盖高难度多残基岛案例,可长期用于评测新模型。
五、意义与展望
理论层面:证明了深度生成模型可以直接从原子级的“化学意图”生成完整的蛋白-配体复合物,将酶设计从“拼接已有片段”转变为“自由探索化学空间”。
技术层面:RFdiffusion2可作为通用平台,用于金属蛋白设计、小分子结合蛋白、蛋白-蛋白界面改造等需要原子精度控制的任务。AME基准将推动AI酶设计的标准化评估。
转化层面:该方法能快速生成针对任意底物的水解酶、转移酶等,有望应用于生物修复(塑料降解)、生物催化(药物中间体)、生物传感等领域。未来结合DFT自动化计算过渡态,可实现全自动“机理→酶”设计流程。
文献来源:
Ahern W, Yim J, Tischer D, et al. Atom-level enzyme active site scaffolding using RFdiffusion2. Nat Methods. 2025. doi:10.1038/s41592-025-02975-x
纳米抗体筛选、小鼠单抗筛选、兔单抗筛选、抗体人源化、抗体亲和力成熟、AI抗体设计,欢迎交流咨询。

