夜雨聆风
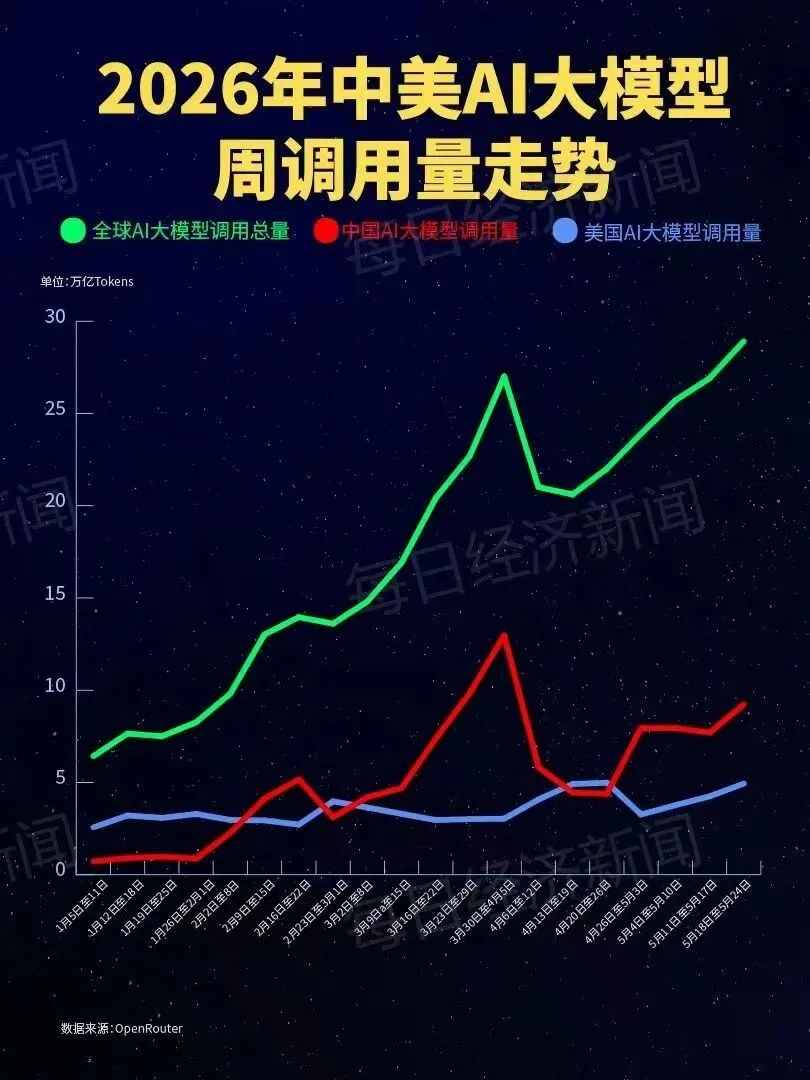
夜雨聆风2026年5月,一个标志性时刻悄然发生:中国AI大模型周调用量达到美国的2.11倍,连续四周稳居全球第一。这不是"弯道超车"——我们换了一条赛道。
先看数据:碾压级的2.11倍
据全球最大AI模型API聚合平台OpenRouter最新周报数据(统计周期:5月4日-10日):
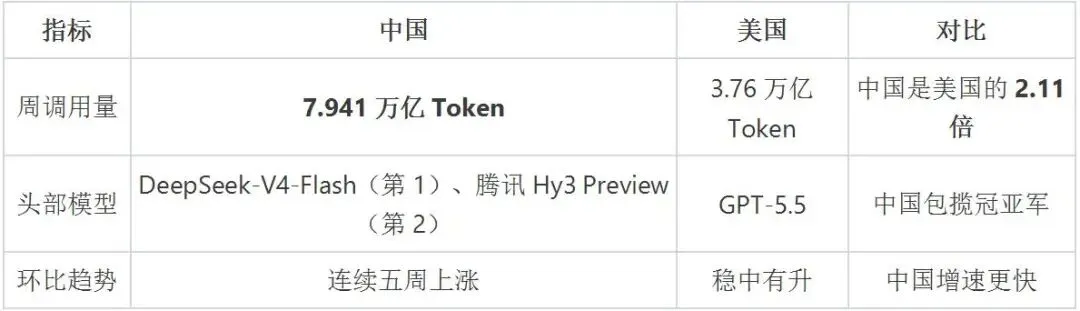
到最新一周(5月18日-24日),数据进一步拉大:中国周调用量攀升至9.223万亿Token,环比增长19.8%,全球总调用量达28.9万亿Token,连续五周创历史新高。
这不仅仅是"用量第一"的问题,而是头部模型排名被彻底改写:
·DeepSeek-V4-Flash以3.43万亿Token单周调用量登顶全球第一,环比暴涨66%
·腾讯Hy3 Preview以3.07万亿Token稳居第二,环比增长16%
·前两名全部是中国模型,这在AI历史上尚属首次
调用量碾压的背后,是一场成本革命。
5月22日,DeepSeek宣布永久降价:DeepSeek-V4-Pro API价格降至原价的1/4。调整后价格为:
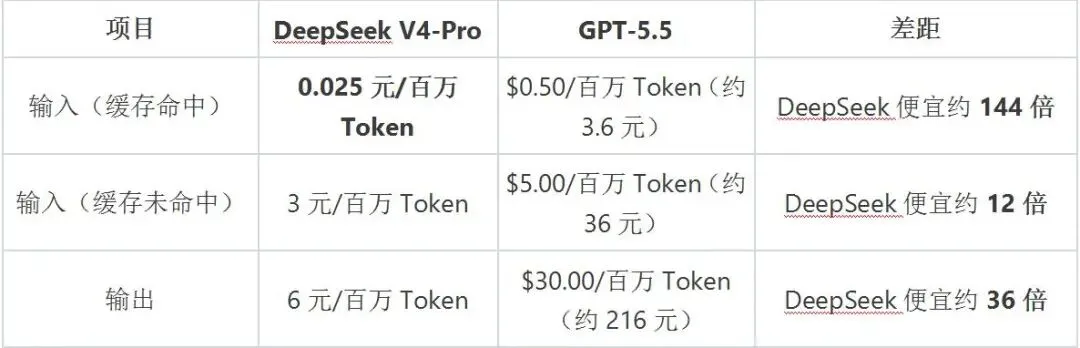
DeepSeek数据来源:官方公告(2026.5.22);GPT-5.5数据来源:OpenAI官方定价页(2026.5)
换算成月费,处理1亿Token的工作负载(80%输入/20%输出),GPT-5.5月费约892美元(约6400元),而DeepSeek V4仅约42美元(约300元)——相差21倍。
网友的评价更直白:"说白了就是收个电费。"
这种价格,让AI从"企业奢侈品"变成了"基础设施水电煤"。当调用成本几乎可以忽略不计,开发者自然倾向于多试、多用、多创新——这就是调用量暴增的根本驱动力。
国产效率:文心5.1把训练成本打到6%
5月9日,百度发布文心大模型5.1,走了一条完全不同的技术路线。
核心技术"多维弹性预训练"实现了:
·总参数压缩至原来的1/3
·激活参数压缩至1/2
·预训练成本仅为业界同规模模型的6%
同时在LM Arena搜索榜获得1223分,排名全球第四、国内第一,是唯一入围全球顶级梯队的国产模型。
数据来源:百度官方博客(2026.5.9)、Omdia评测报告(2026.5.18)
文心5.1传递的信号很明确:不拼参数规模,拼效率。这正是中国AI产业从"烧钱追赶"转向"精算超越"的关键转折点。
全局视角:日均140万亿Token,两年增长千倍
把视角拉高,一组来自国家数据局的官方数据更令人震撼:
·2024年初:中国日均Token调用量约1000亿
·2025年底:跃升至100万亿
·2026年3月:突破140万亿(国家数据局局长刘烈宏在中国发展高层论坛披露)
数据来源:国务院新闻办公室新闻发布会(2026.3.24)、新华网报道
两年时间,增长超过1000倍。
这个增速意味着什么?意味着AI已经从实验室走进工厂车间、走进客服坐席、走进每一个开发者的IDE。Token不再是一个技术概念,而是数字经济时代的新型"计量单位"——就像电表上的度数、水表上的吨数。
量子位智库发布的《2026中国AI应用全景图谱报告》也印证了这一点:2026年4月,国内AI应用Web端月访问量突破9亿,APP端月下载量超2.4亿,日活同比增长223%。
美国在做什么?GPT-5.5免费开放
当然,美国并没有闲着。
5月6日,OpenAI将ChatGPT默认模型切换为GPT-5.5 Instant,面向所有用户免费开放。核心升级包括:
·高风险场景(医疗、法律、金融)幻觉声明减少52.5%
·竞赛数学AIME成绩从65.4%提升至81.2%
·博士级科学推理GPQA从78.5%提升至85.6%
数据来源:OpenAI官方公告、aihub.cn模型数据库
OpenAI的策略很清晰:用免费模型铺量,用Pro版本变现。但在中国市场,这个策略遇到了"DeepSeek定价"这堵价格墙——当国产模型便宜100倍以上时,免费不再是护城河。
数字背后的真正含义
"调用量是美国的2倍"这个数字固然令人振奋,但真正重要的不是数字本身,而是它背后的三重含义:
第一,中国AI正在变成"水电煤"。从1000亿到140万亿日均Token,两年千倍增长说明AI已经嵌入经济运行的基础层,不再是锦上添花的工具。
第二,成本革命打开了应用天花板。 DeepSeek、文心5.1等技术突破让AI调用成本趋近于零,这才有了调用量碾压式增长的前提。
第三,竞争范式已经改变。从"谁的参数大"到"谁的成本低"、从"谁的模型强"到"谁用的人多"——这是一场中国AI擅长的效率战争。
当AI的调用成本比一杯咖啡还低,胜负就已经注定了。