 夜雨聆风
夜雨聆风「先别写代码,先做计划」
大多数开发者用 AI 的方式,是把需求往对话框里一丢,然后等它吐代码。
OpenAI 自家工程师的用法完全相反。
2026 年 5 月,OpenAI 发布了一篇官方工程指南《How OpenAI uses Codex》,直接公开了内部团队每天怎么用自家 coding agent。这篇文章的内容来自对 OpenAI 工程师的访谈和内部使用数据,涉及 Security、Product Engineering、Frontend、API、Infrastructure、Performance Engineering 等多个技术团队。
▲ Alex Prompter 在 X 上转述了 OpenAI 的内部 AI 使用指南,称"这是他们团队做了但你可能没做的事"
这篇指南里最重要的一条实践,也是整个方法论的起点:
"For large changes, start by prompting Codex for an implementation plan using Ask mode, which then becomes the input for follow-up prompts when you switch to Code Mode."
「对大型改动,先让 Codex 在 Ask Mode 中生成实现计划,再把这个计划作为后续 Code Mode 的输入。」
翻译成大白话就是——先让模型做计划,你审完计划之后,它才能动手。

▲ OpenAI 官方文章开篇就写明:Codex 已在多个技术团队日常使用,材料来自工程师访谈与内部数据
Ask Mode 的底层逻辑:把审查前移
为什么要先让模型「问清楚」再动手?
OpenAI 官方原文的解释是:
"This two-step flow keeps Codex grounded and helps avoid errors in its output."
「两步流程能让 Codex 更有依据,减少输出错误。」
这里面的关键词是grounded——有依据、有锚点。
传统做法是直接让 AI 写完代码,然后你 review 一坨 diff。问题在于,如果模型从一开始就理解错了需求方向,那后面写的每一行代码都是在错误路径上越走越远。你花在 review 上的时间,大部分是在善后。
Ask Mode 的做法相当于在执行前插入了一个 checkpoint:让模型先列出它打算改哪些文件、怎么改、为什么这么改、有什么风险。你检查的对象从「已经写完的代码」前移到「即将执行的方案」。发现方向有偏差,改一句计划就行,不用推翻几百行代码。
这才是"让模型问清楚"的真正含义——把人类审查从事后救火变成事前把关。

▲ OpenAI 官方 best practices 页面:Start with Ask Mode 排在第一条
Prompt 要写成工程 Brief,别写成许愿
OpenAI 内部的第二条方法论,同样来自官方文章:
"Structure your prompt as if you are writing a Github Issue."
「把 prompt 写得像一个 GitHub Issue。」
什么意思?就是你给 AI 的指令不应该是「帮我优化一下这个页面」这种模糊需求,而应该包含:
- 背景
:这个功能当前的状态和已知问题 - 目标
:具体要达成什么效果 - 文件路径和组件名
:模型需要动哪些代码 - 参考模块
:「按照 module X 的方式实现」 - diff 或文档片段
:相关的上下文材料 - 非目标
:明确说清什么不用改
这和写一个好的 GitHub Issue 一模一样。工程师给同事派任务时不会只说「把这个弄好」,会把范围、约束、相关代码和验收标准全部列出来。给 AI 也一样。
prompt 的质量决定了模型输出的上限。而 prompt 的质量,取决于你愿意花多少工程化的功夫把上下文喂到位。
把 Codex 当异步任务队列:开会也能合 PR
OpenAI 内部工程师有一个用法让人印象深刻:
"I was in meetings all day and still merged 4 PRs because Codex was working in the background."
「我整天都在开会,但还是合并了 4 个 PR,因为 Codex 一直在后台工作。」
这背后的逻辑是——把 AI agent 当成一个异步任务队列。
OpenAI 的工程师在主线开发中碰到低优先级的 bug、支线的重构任务或者临时发现的小问题,不会切分支、换上下文,而是直接给 Codex 发一个任务,让它在后台处理。等自己忙完了,回来 review 它生成的 PR。
另一位后端工程师的说法更具体:
"If I spot a drive-by fix, I fire a Codex task instead of swapping branches and review its PR when I'm free."
「发现一个顺手能修的问题,我会开一个 Codex 任务,等空了再看它的 PR。」
Codex 本身是云端沙盒里的 coding agent(据 TechCrunch 报道,它运行在 OpenAI 的云端虚拟机上,可以预加载 GitHub repo),处理简单功能、修 bug、跑测试等任务大约需要 1 到 30 分钟。这让「后台跑任务」在产品层面成立。
AI 在这里扮演的角色更接近一个不会打断你的异步队列,不再是一个需要你盯着的对话窗口。
AGENTS.md:给 AI 写一份「入职手册」
OpenAI 的第五条方法论涉及一个具体的文件机制——AGENTS.md。
"Codex reads AGENTS.md files before doing any work."
「Codex 在开始任何工作之前,都会先读取 AGENTS.md 文件。」
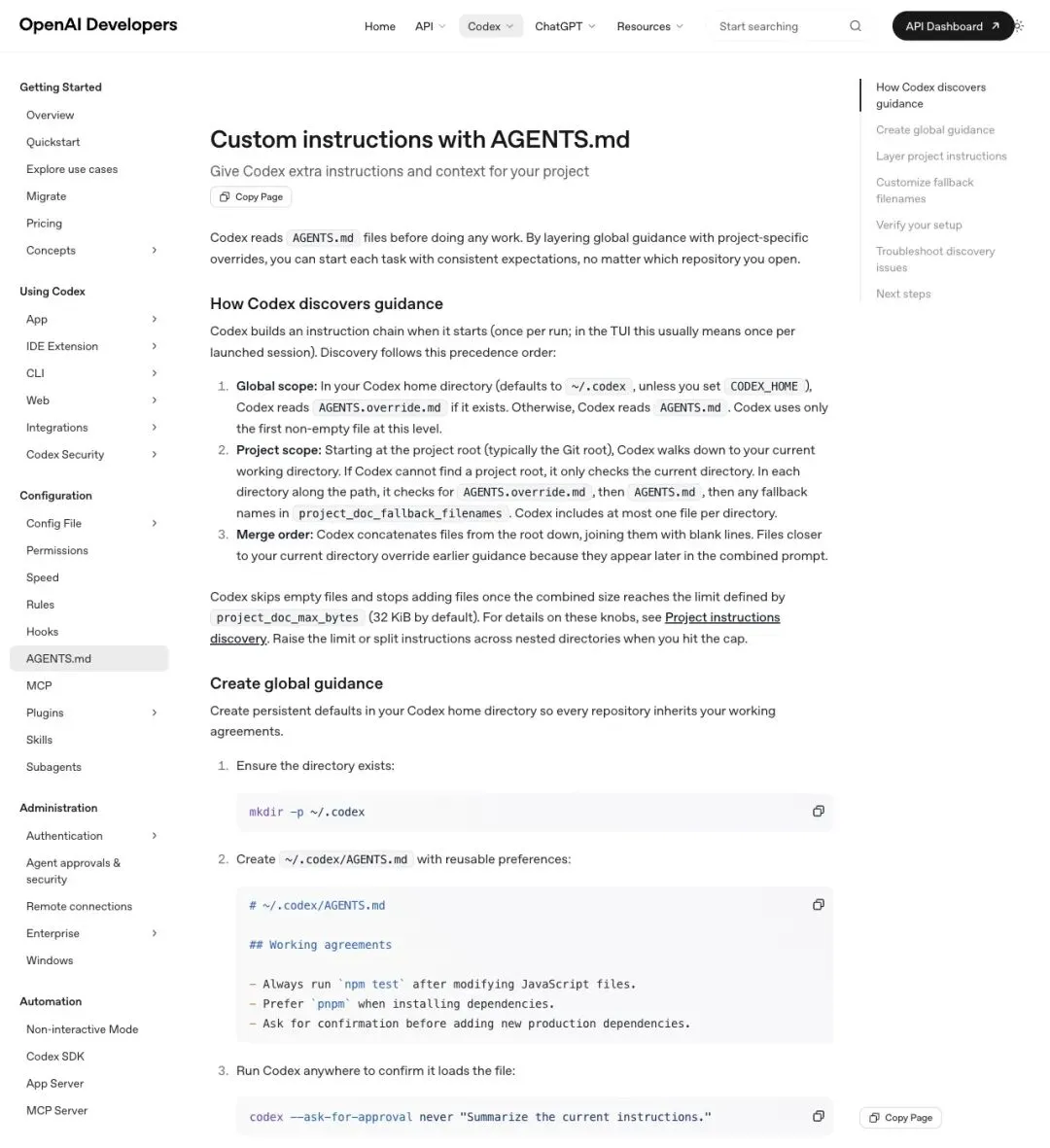
▲ OpenAI Developers 文档明确写道:Codex 在开始工作前会读取 AGENTS.md
AGENTS.md 的作用类似于给 AI agent 写的「入职指南」。你在这个文件里写清楚:
- 命名约定
:变量用 camelCase 还是 snake_case - 测试命令
:跑测试用什么脚本 - 业务逻辑
:哪些字段有特殊含义 - 已知坑点
:哪些依赖有版本问题 - 禁区
:哪些文件不能碰
人类新同事入职,会看 README 和 CONTRIBUTING.md。AI agent 入职,看的是 AGENTS.md。
OpenAI 的官方文档还建议按层级维护这个文件——全局一份、项目级一份,不同 repo 可以有不同覆盖。这样 Codex 在不同项目里都能快速进入状态,不用你每次都在 prompt 里重复说明上下文。
Best of N:同一个问题,让模型跑多个方案
OpenAI 内部的第六条实践是Best of N——同一个任务,让 Codex 同时生成多个方案,然后人类 review 比较,选最好的那个。
这在高风险决策场景特别有用。比如一个性能优化的方案,可能有三四种不同路径(改索引、改查询、加缓存、重构数据结构),让模型分别生成,你再对比权衡,比只看一个方案要靠谱得多。
但这里有一个容易忽略的成本:多个候选方案意味着更多的审查工作。如果你没有足够的测试覆盖和 code review 流程,Best of N 只是增加了表面上的选择,并没有提高实际质量。
开发者社区怎么看?
OpenAI 的官方指南发出来之后,Hacker News 上的开发者讨论也提供了一些不同角度。

▲ Hacker News 上关于 Codex App 的讨论,开发者关注点远不止模型能力
有人认为 Codex 免费开放和提高限额本质上是推动 adoption 的营销动作,提醒大家不要把官方宣传直接等同于实际使用率。
也有开发者分享了真实体验,说 Claude Code 和 Codex 在不同任务上互有胜负:
"Sometimes I can sit with Claude Code for an hour... try it with Codex and have it solved in five minutes, and also the opposite happens."
「有时候用 Claude Code 卡了一小时的问题,Codex 五分钟就解决了;反过来也一样。」
这说明 coding agent 的可靠性仍然取决于具体任务类型、工程 harness 和上下文配置。没有哪个模型在所有场景下都更强。
还有大量关于 native app、Electron、系统集成和资源占用的讨论。开发者关心的不只是模型输出的质量,还有整套工具的完整体验——权限管理、OS 适配、上下文窗口、CPU 和内存占用。
边界在哪里?
需要提醒的是,OpenAI 这篇文章的定位是Codex 研究预览阶段的内部工程实践,不代表所有 AI 工具的通用定律。
几个关键边界:
Ask Mode 需要人类把关。让模型先生成计划确实有用,但计划本身也可能遗漏测试路径、忽略安全约束。人类仍然要审查计划的完整性,不能把「先问」等同于「问了就对」。
「整天开会还合了 4 个 PR」是个人案例。这来自 OpenAI 一位工程师的描述,用来说明异步工作流的可能性。但把它理解成"每个人每天都能多合 4 个 PR"就过头了。
AGENTS.md 提供的是上下文,不代替安全保障。它告诉模型项目里的约定和禁区,但权限隔离、CI 流水线、自动化测试这些真正的安全边界还得靠别的机制。
Forbes 把 Codex 在内部的使用描述为"自主运行数据平台",但 OpenAI 官方原文始终在人机协作的框架下讨论这些实践。不要把媒体的措辞直接当成 OpenAI 的承诺。
给开发者的 Checklist
把 OpenAI 内部实践提炼成可操作的清单:
1. 先 Ask,再 Code。让模型列出实现计划、涉及的文件、风险点和测试路径,你审完再让它执行。
2. Prompt 按 Issue 标准写。背景、目标、非目标、文件路径、参考模块、验收标准,一个都不少。
3. 给 repo 维护 AGENTS.md。写清命名规范、测试命令、依赖版本、业务逻辑和禁区。
4. 低优先级任务扔给 agent 异步处理。不打断主线工作流,空了再 review。
5. 高风险决策用 Best of N。让模型生成多个方案,但一定要有 review 和测试兜底。
6. 不要把任何一个 agent 当万能工具。不同模型在不同任务上表现不同,根据实际效果切换。
真正拉开差距的地方在于,能不能把模型接入自己已有的工程流程——任务分解、上下文管理、审查机制和测试覆盖——而不只是知道某个万能 prompt。
工具在进化,但工程纪律不会过时。
— END —
