 夜雨聆风
夜雨聆风这个问题问到了根上。
我认识一位做跨境电商的老板,去年兴奋地告诉我他让团队用上了“AI员工”——接了一个号称“最聪明”的模型的API,让客服、文案、运营全部用AI干活。三个月后他拿到账单,差点没站稳:光Token消耗就花了17万。
他问我:“这东西不是按次收费吗?怎么比招十个员工还贵?”
我说:“你知不知道,你用的那个模型,完成同一个任务,比国产模型贵了50倍?”
他愣住了。
这就是今天这篇文章要讲的核心问题:Token,正在成为AI时代的“新货币”。不懂Token经济,你的AI员工不但不会省钱,还可能成为公司最大的成本黑洞。
一、Token是什么?把它想象成“AI的汽油”
先给一个最直白的解释。
你开车要加油,AI干活要消耗Token。每次你向AI提问、AI回答你、AI帮你分析数据、AI写报告……背后都在燃烧Token。
国内传统SaaS软件是这样的:你付一个固定年费,用多用少一个价。比如花5万买个CRM系统,公司100人用和1000人用,成本是一样的。
但AI不是。
AI的成本随用量线性增长——你今天问10个问题和问10万个问题,成本差一万倍。每个员工每一次点击“生成”,背后都在实时产生账单。
更麻烦的是,Token的定价不是“一个多少钱”这么简单。它有三层玄机:
角色分层:输入Token、缓存Token、输出Token,三者价格比例大约1:0.1:6。输出(AI回答你)比输入(你问AI)贵6倍。
性能分层:你要快的、准的、不卡顿的Token,就要付溢价。就像高铁票和绿皮火车的区别。
模型分层:顶级模型(如GPT-5级)单价高,但逻辑强,可能一次就搞定;便宜模型单价低,但可能让员工反复重试、人工修正,最后总成本更高。
这就像加油站的油价不光分92、95、98,还分白天晚上、自助还是人工、刷卡还是现金——不搞清楚规则,你就是那个被收割的。
前段时间非常火爆的OpenClaw(龙虾),说全民养龙虾也不为过,但大多数人不清楚OpenClaw就是一个token“黑洞”,从某云厂商获得的OpenClaw平均消耗Token统计:
OpenClaw Token消耗高,是因为它从“对话者”变成了“行动者”,其设计本身就是为复杂、多步骤任务而生。不了解其运行机制就去使用,就像开着一辆F1赛车去市区代步——油费自然贵得惊人。
核心逻辑在于:你不是在为每次对话付费,而是在为一个会自主思考、持续运行的“数字员工”的每一秒钟思考付费。 这也是它背后Token经济学的本质
二、一个中国老板的血泪教训
回到那位跨境电商老板的案例。
我帮他拉了一份账单分析,发现三个问题:
问题一:选错模型他们所有任务——从写产品描述到分析竞品评论到回复客户邮件——全部用同一个顶级模型。实际上,80%的简单任务用国产开源模型就能完成,价格只有顶级模型的1/17。
问题二:重复消耗同一个产品信息,客服问一遍,运营问一遍,文案问一遍,三个部门分别调用AI,同一个Token被反复烧了三次。如果有一个统一的知识库让AI先“记忆”,缓存命中率能到90%以上,成本直接打一折。
问题三:被“中转站”坑了因为贪图方便,他们没有直接对接官方API,而是找了一个第三方中转站代充代调。后来发现,这个中转站号称提供Claude 3.5,后台实际给的是国产小模型——简单任务看不出来,但碰到专业问题,回答质量从83%正确率掉到37%。而且,中转站还多报了30%的Token消耗量。
这三个问题叠加,17万账单里,至少有12万是冤枉钱。
这不是个例。我们调研了十几家接入AI的中国中小企业,发现超过60%的公司不知道自己实际消耗了多少Token,更不知道花在哪儿了。
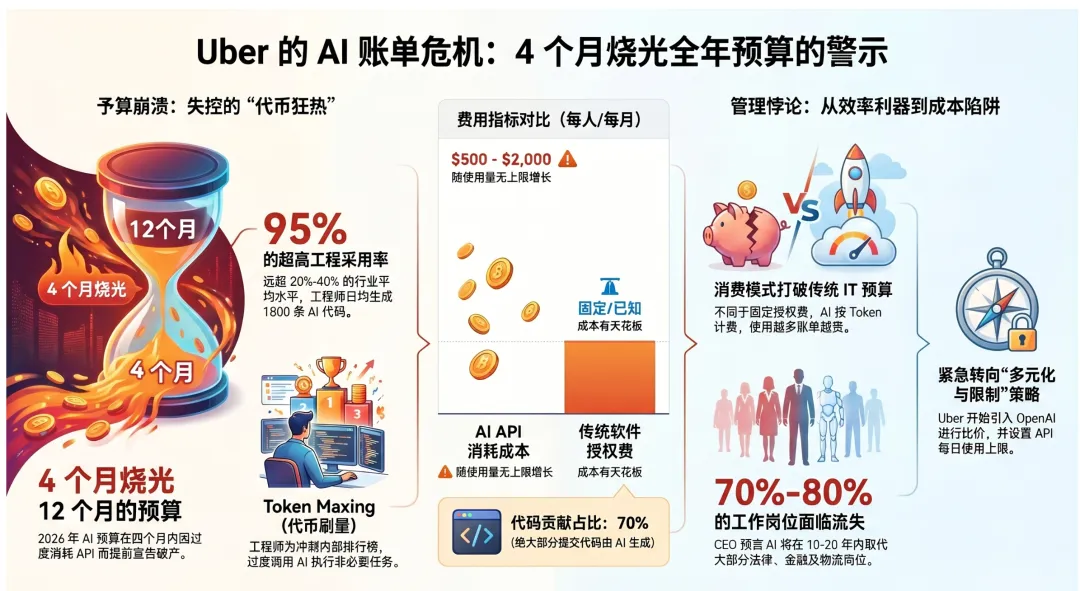
三、硅谷大厂也翻车:Uber四个月烧光全年AI预算
你以为只有中小公司会踩坑?就在最近,硅谷曝出了一个让所有CEO后背发凉的真实案例。
Uber,2026年。
这家全球出行巨头在全面推广AI编程工具后,仅仅过了四个月,就把全年的AI预算全部烧光了。
怎么回事?
Uber鼓励工程师使用Claude Code等AI编程助手来提升开发效率。这个初衷没问题——工程师们也确实很喜欢,采用率极高,几乎每个人都把AI当成了日常编码的标配。
但问题出在:没有使用限制,也没有成本意识。
工程师们写一行代码问一下AI,跑通一个测试问一下AI,查个文档问一下AI,甚至心情不好也跟AI聊两句。每个人每月光是Token消耗就高达2000美元。Uber有上万名工程师,你算算这个账。
硅谷给这种现象取了个名字——“Token刷量”。
这不是恶意行为,而是激励机制错位的结果:工程师的KPI是“写出更多代码、更快交付功能”,没人告诉他们“每消耗一个Token都是有成本的”。于是,AI被当成无限免费资源来用,消耗量远超实际业务需求。
Uber的管理层被这个账单打醒了。他们紧急开会,被迫重新审视AI战略——引入竞争工具来压价、设置使用配额、建立内部成本透明化机制。甚至连CEO都公开表达了一个更深的担忧:当AI真的比人便宜且好用的时候,公司会不会不得不裁员?
这个案例告诉我们一个残酷的事实:不是只有小公司会被Token账单吓到,硅谷大厂一样翻车。 区别在于,Uber还能靠融资和现金流扛过去,你的公司扛得住吗?
四、硅谷在疯抢Token,中国在输出“电力”
你可能觉得这个问题离你很远。但看看硅谷正在发生什么——
他们管这叫“Token-maxxing”(把Token用量推到极致)。硅谷的企业比拼的不是谁家AI更聪明,而是谁家每天烧掉的Token更多。因为Token消耗量已经成为衡量一家公司“AI原生度”的核心指标。甚至有风投开始直接把Token额度作为投资的一部分——给你钱你不一定会花,给你Token你一定得用。
另一边,中国开源模型正在全球杀出重围。MiniMax、Kimi、智谱AI等国产模型,在某些任务上的价格只有顶级模型的1/17,价差最大能达到70倍。而且中国模型采用了MoE(混合专家)技术,推理成本更低。
这意味着什么?
中国企业有一个巨大的成本优势——你可以用远低于硅谷同行的算力成本,跑出差不多的AI效果。因为Token是通过消耗电力和算力生成的,中国有便宜的电力、便宜的计算资源,相当于你在用“中国电价”在AI战场上竞争。
有分析师把这种现象叫做“电力价值出海”——你的AI服务不需要出口任何实物,只需要通过API接口把Token卖给全球开发者,完成跨境结算。这是中国第一次在AI时代拥有结构性成本优势。
但前提是:你得知道怎么用好这个优势。如果你连Token的基本计价规则都不懂,这个优势跟你没有关系。
五、老板必须掌握的四个Token常识
我帮各位老板提炼四个最实用的原则,记下来就能少踩坑:
原则一:按任务复杂度分级使用模型简单任务(如回复“好的收到”)、中等任务(如写产品描述)、复杂任务(如分析财报数据),分别用不同级别的模型。用顶级模型处理简单任务,就像用导弹打蚊子。
原则二:建立“缓存优先”的调用逻辑公司里80%的提问是重复的。把常见问题和回答缓存下来,下次有人问同样的问题,AI直接从缓存里取,成本只有正常调用的十分之一。
原则三:永远走官方渠道,警惕中转站第三方中转站虽然方便(解决支付、地区限制等问题),但超过60%的中转站存在模型调包、虚报Token、数据转卖等黑箱操作。你的业务数据可能正在被拿去训练别人的模型。正规的聚合平台如OpenRouter会有透明定价和5%左右的合理抽成,但绝大多数小中转站是坑。
原则四:监控单位任务的Token消耗不要只看总账单。要算“每个有效任务花了多少Token”。如果同一个任务,上周花1000 Token,这周花3000 Token,说明哪里出了问题——可能是模型变了、提示词写烂了、或者被恶意多扣费了。
六、恩八恩正在做的事
看到这里,你可能会说:“你说的这些原则都对,但我一个老板怎么可能去盯每个任务、每个模型的Token消耗?”
你说得对。这不是人力能解决的问题。
恩八恩正在研发一套面向企业的AI成本智能优化系统。简单来说,它可以帮助企业在不改变员工使用习惯的前提下,在Token消耗层面进行智能优化,从而显著降低实际的Token成本。让每一笔Token投入都花在刀刃上,避免无效调用和资源浪费。
同时,恩八恩基于AI工作流的设计理念,天然就是极度省Token的——系统会判断哪些环节真正需要AI介入,只在必要的时候调用模型,其他流程走传统逻辑即可。这样一来,企业不需要改变员工的使用习惯,后台就已经省掉了大量不必要的Token开销。
可以明确的是:恩八恩的Token智能优化系统目标是让每一块钱的Token投入,都能换来最大的业务产出。让企业不再为“看不见的Token”买单。
写在最后
Jack Dorsey说过一句话:Token正在成为一种“新货币”。我认为更准确的比喻是:Token是AI时代的电力,而你需要一个“智能电表”和“节能方案”。
Uber的教训告诉我们,即使是硅谷大厂,也会因为“Token刷量”而烧穿预算。未来的企业竞争,不再是比谁人多、谁钱多,而是比谁能更高效地把Token转化成商业价值。
同样花一块钱的Token,有的公司能完成100次有效任务,有的公司只能完成10次。十倍的成本差距,就是十倍的速度差距。
而速度,决定了你能不能在AI时代活下来。
你的AI员工已经在路上。但如果你不搞懂他们“吃什么、吃多少、怎么吃得更省”,你请来的不是员工,是祖宗。

点赞 + 分享,扫码加疯哥体验企业AI员工

《老板如何获得AI员工个》系列
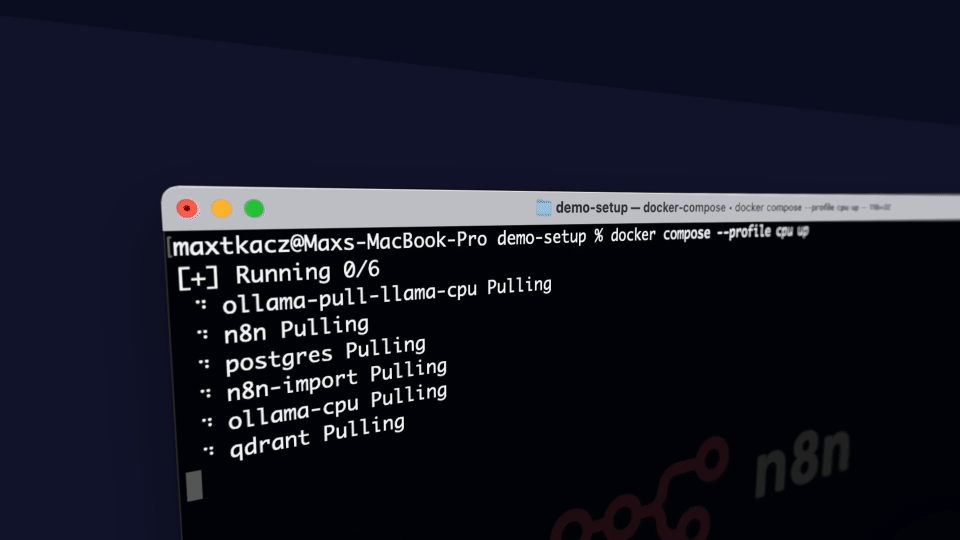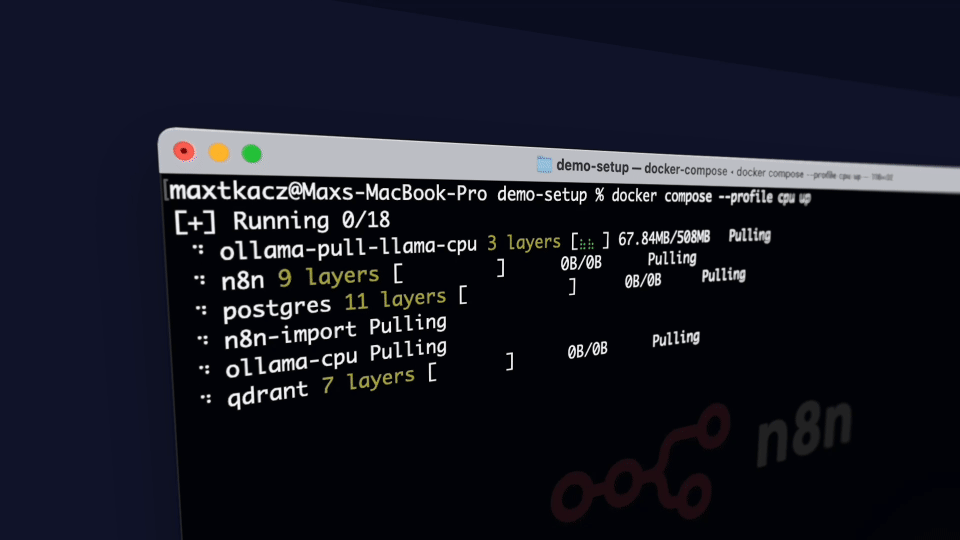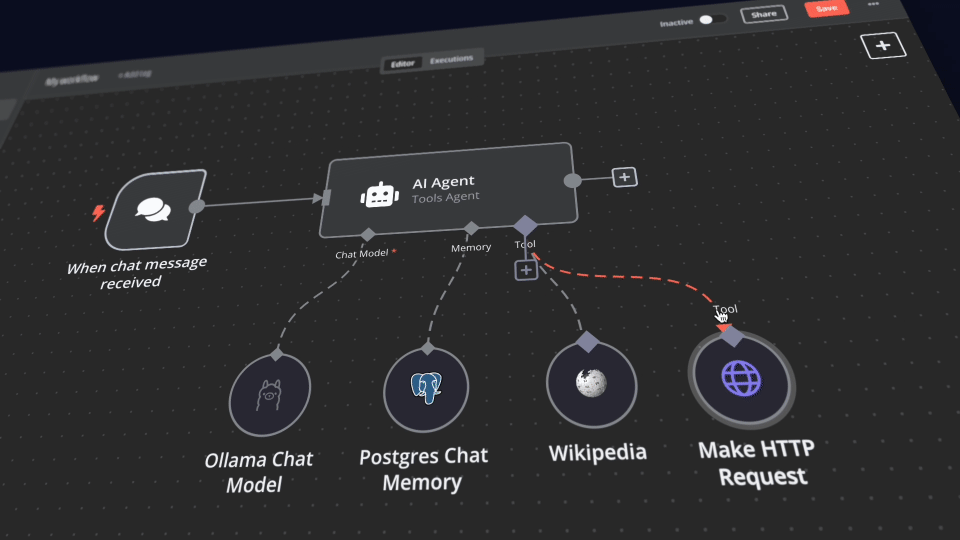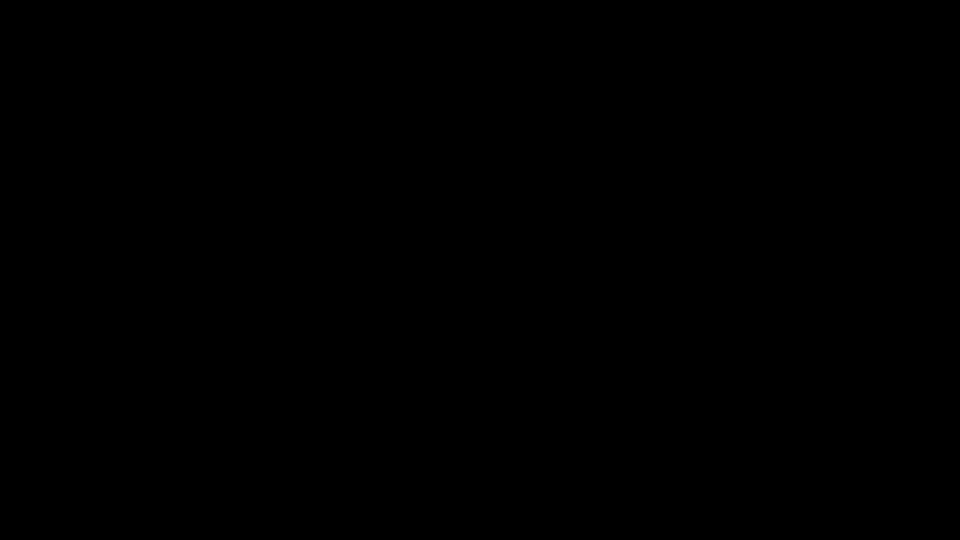
《掌握n8n,开启AI自动化之旅》系列
第四章:(基础篇) n8n+Deepseek 保姆级教程,手把手搭建智能工作流。
第五章:(高级篇) n8n+Deepseek 保姆级教程,手把手搭建智能工作流
第六章: (落地篇) 每隔10分钟接收重大AI新闻,让500强高管直呼真香!
第七章:(实战力作) n8n+Deepseek+FLUX 模型,1小时生成100张新闻海报
第九章:n8n刚支持MCP就完了?OpenAI打响AI Agent标准之战
第十章:(入门篇) n8n MCP动手搭建、实战案例拆解 n8n+MCP+A2A
第十二章:AI自动化入门必读!Zapier、Make、n8n 该如何选择?
第十三章:中文版 n8n 桌面神器发布!Windows、Mac免安装一键运行,效率暴涨指南
第十四章: 一文读懂 n8n Webhook 节点,搭建复杂AI工作流的基石 - 新手秒懂
《掌握Deepseek,开启AI白嫖之旅》系列
数据说话:阿里Qwen 2.5-Max vs DeepSeek-V3
手把手教你满血版 DeepSeek-V3、R1 API 调用,速度飞快还不要钱
火山引擎篇 手把手教你满血版 DeepSeek-V3、R1 API 调用,全网低延时支持500wTMP
有任何疑问请留言
你的问题可能是别人的灵感,欢迎在评论区畅所欲言~
