 夜雨聆风
夜雨聆风想象一个情境(或许也是某位同学的真实写照):
凌晨三点的宿舍里,大四学生小李对着电脑屏幕欲哭无泪。她花了三个月做实验、写出来的毕业论文,被知网判定为"72%疑似 AI 生成"。导师告诉她,不降到 20% 以下,连答辩资格都没有。
于是接下来的一周,小李没有再修改任何研究内容。她的全部工作变成了:把长句拆成短句,把书面语改成口语,在严谨的学术论述中加入"众所周知"、"值得一提的是" 这类冗余表达,甚至故意写错几个字再改回来。
最后,她用另一个AI 工具把论文 "降重" 到了 11%,顺利通过了检测。
"我写的原创论文过不了,AI改出来的垃圾反而能过。" 小李在朋友圈写道,"这到底是在查学术不端,还是在逼所有人作弊?"
AI飞速发展的当下,几乎每一个毕业生都会经历一场类似的十分魔幻现实主义的考验。我们不禁要问:AIGC 查重,真的走到了它的反面吗?

一、AI率检测:从学术卫士到全民公敌
AIGC查重的初衷是好的。2022 年底 ChatGPT 爆火后,AI 代写一夜之间成为学术诚信的最大威胁。教育管理者们急需一个工具来遏制这股歪风,于是各种 AI 检测器应运而生。
但仅仅三年时间,这个工具就彻底异化了。
它的第一个致命缺陷,是技术原理上的先天不足。
几乎所有主流AI 检测器的核心逻辑都不是 "溯源",而是 "概率判断"。它们通过计算文本的 "困惑度"—— 也就是大模型预测下一个词的准确度 —— 来判断这段文字更像人写的还是 AI 写的。
这就导致了一个荒谬的结果:写得越规范、越严谨、越符合学术标准的文章,越容易被判定为AI 生成。
佛罗里达大学2026 年的最新研究显示,商用 AI 检测器对 2022 年之前(ChatGPT 诞生前)的人类学术论文,误报率高达 68.6%。朱自清的《荷塘月色》、刘慈欣的《流浪地球》,甚至连《资本论》的片段,都被判定为 高度疑似 AI 生成。
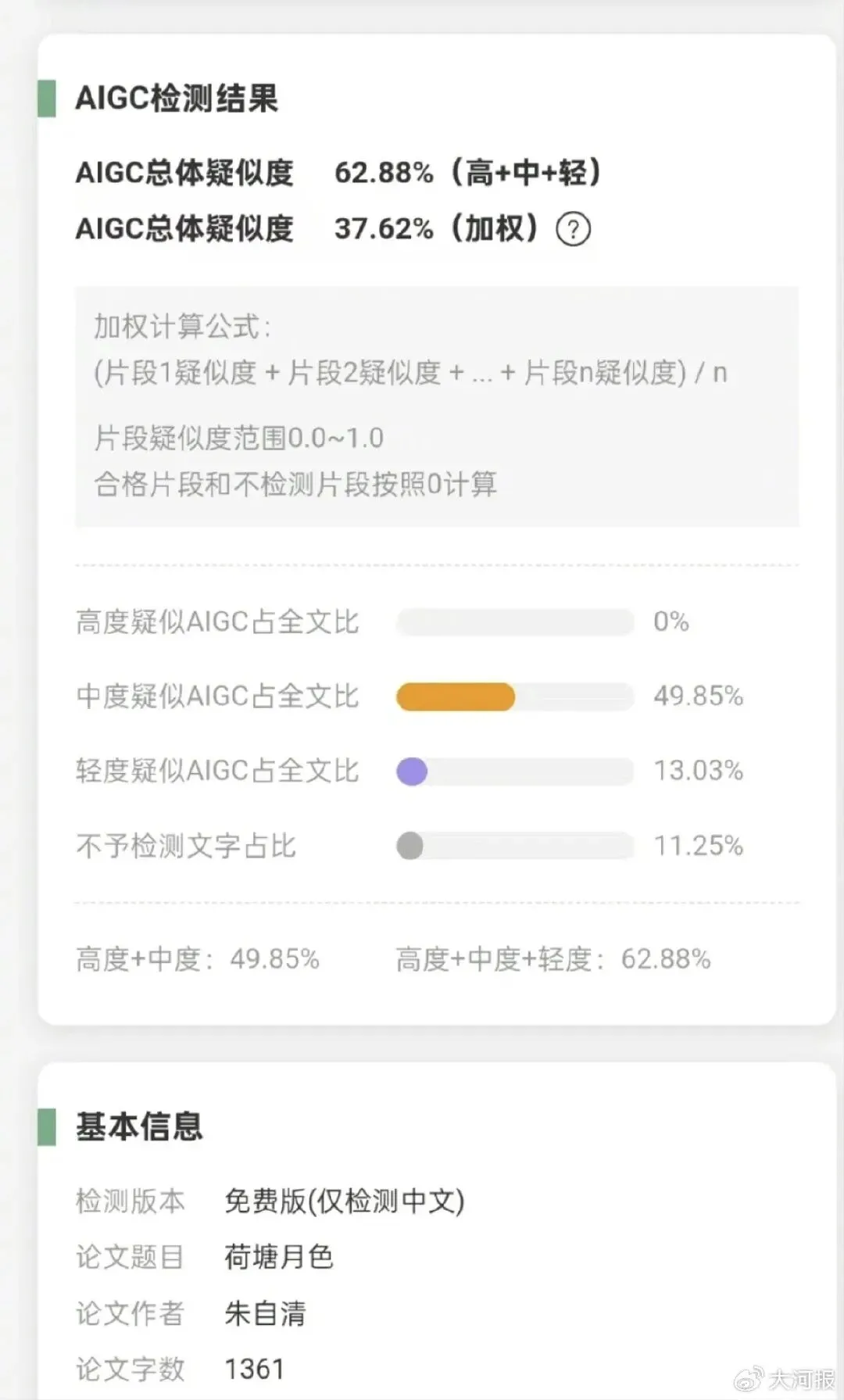
它的第二个致命缺陷,是执行标准上的管理僵化。
如今,全国超过90% 的高校都将 AIGC 检测与传统查重并列作为答辩的 "生死关"。但这个 "生死关" 的标准,却没有任何科学依据。
同一篇论文,在知网、维普、万方的检测结果差异可达46%;不同高校的红线,从 985 的 "文科≤20%、理工≤15%" 到普通本科的 "≤40%" 不等。更离谱的是,绝大多数高校不接受任何申诉 ——Word 修订历史、实验原始数据、思维导图,这些最能证明人类创作的证据,在一个冰冷的数字面前一文不值。
最讽刺的是,AI查重不仅没有消灭 AI 代写,反而催生了一个更庞大的灰色产业链。
现在的流程已经变成了:AI写论文→AI 查论文→AI 改论文。学生们发现,只要告诉 AI"按照知网的检测逻辑改写,增加口语化表达、拆分长句、打乱逻辑",就能轻松把 80% 的 AI 率降到 0%。
而真正老老实实自己写论文的学生,却不得不花费大量时间和金钱,去对抗一个本不该存在的算法。
这已经不是在防范学术不端了。这是在惩罚原创,奖励作弊。
二、回归本质:我们真正该查的,从来都不是"谁写的"
学术界还有声音在争论"AI 率多少才算合理" ,但其实是问错问题了。
学术诚信的核心是什么?是"不能抄别人的东西",还是 "不能用工具写东西"?
答案显然是前者。
一篇论文,无论你是用手写的、用键盘敲的,还是用AI 辅助润色的,只要其中的思想、数据、实验、论证是你自己的,它就是一篇合格的学术论文。
反过来,如果一篇论文的核心观点是抄来的,数据是造假的,实验是编的,那么就算它每一个字都是你亲手写的,它也是学术不端。
AI率检测的根本错误,就在于它把 "写作方式" 当成了评价标准,而完全忽略了 "学术贡献" 这个本质。
它惩罚的是"用 AI 写论文",但不惩罚 "抄别人的思想";它奖励的是 "写得不像 AI",但不奖励 "有原创性的思考"。
这就是为什么我们说:与其查AI 率,不如查原创率。
最关键的是:AI 可以帮你写任何文字,但 AI 不能替你产生原创的思想、原创的数据、原创的实验、原创的论证。这是人类学者不可替代的核心价值,也是"查原创率" 不容易失效的根本原因。
三、"1+3+1"原创率评价体系:一个可落地的解决方案

问题来了:"原创率听起来很好,但怎么查呢?总不能让老师一篇一篇去看吧?"
这里提出一个可能的方案——"1+3+1" 的原创率评价方案。它既兼顾了公平性,又考虑了可操作性。但它肯定也不能做到完美,仅供参考。
一个核心原则:工具中立原则
首先,我们必须明确一条底线:AI 作为写作辅助工具的使用完全合法,不构成学术不端。
学生无需隐瞒使用AI 的情况,反而应该鼓励在论文末尾注明 "本文使用 XX 工具进行文献检索、语言润色、数据可视化"。
只有当学生将AI 生成的内容冒充为自己的原创思想、原创数据、原创实验时,才构成学术不端。
这条原则一旦确立,所有的对抗和焦虑都会瞬间消失。学生可以光明正大地使用AI 提高效率,把时间花在真正重要的研究上,而不是和算法斗智斗勇。
三道原创性防线
第一道防线:过程性原创性验证(占比60%)
这是最有效、最难以作弊的环节,也是当前教育体系最缺失的部分。
一个代写者可以帮你写出一篇完美的终稿,但他无法帮你伪造一整个研究过程。
应该要求学生提交一份完整的数字创作档案,其中包括但不限于:
•从选题到终稿的所有大纲草稿、修改痕迹
•实验原始数据、代码提交记录、访谈录音
•文献阅读笔记、思维导图
•与导师的所有沟通记录
…
这些材料不需要老师逐字逐句地看,只需要在开题、中期和答辩时进行抽查。一个真正做过研究的学生,他的档案一定是丰富、连贯、有迹可循的;而一个代写的学生,他的档案大概率是空白、断裂、经不起推敲的。
第二道防线:结果性原创性检测(占比30%)
不需要完全抛弃现有的检测工具,只需要对它们进行升级和降权。
保留传统的文字重复率检测,作为基础筛查,但阈值可以适当放宽(如≤30%)。同时,引入更先进的检测技术:
•思想重复率:用语义相似度检测技术,检测论文的核心观点、论证逻辑与已有文献的相似度
•数据原创性:对实验数据进行统计检验,检测是否存在数据造假、篡改等问题
•代码原创性:对计算机相关专业的论文,进行代码相似度检测
这些检测的目的,不是为了抓出"用了 AI 的人",而是为了抓出 "抄了别人的人"。
第三道防线:答辩现场原创性验证(占比10%)
答辩是检验原创性的最后一道关口,也是最有效的关口。
答辩委员会不应该问"你这篇论文是不是 AI 写的",而应该问这些问题:
•"你为什么选择这个研究问题?它的学术价值在哪里?"
•"这个(实验)结果为什么和你的预期不一样?你是怎么解释的?"
•"你这个观点和 XX 学者的观点有什么不同?你是怎么反驳他的?"
•"如果让你重新做这个研究,你会改进哪些地方?"
…
这些问题没有标准答案,但只有真正做过研究的人才能回答得出来。对于高度怀疑存在代写的论文,还可以要求学生在现场用30 分钟写一段关于论文核心内容的总结或拓展。
一个兜底机制:学术不端申诉与调查委员会
建立独立的学术不端调查委员会,由不同学科的专家组成。对于被怀疑存在学术不端的学生,委员会有权查阅其完整的研究过程档案,并给予学生充分的申辩权利。
只有在有确凿证据证明学生存在思想、数据或实验造假的情况下,才能认定为学术不端。
四、AI时代,我们需要什么样的学术评价?
可能有人会说,这样的方案会大大增加学校和老师的工作量。
确实,过程性评价比简单地看一个数字要麻烦得多。但教育本来就是一件麻烦的事。如果我们为了省事,就用一个冰冷的数字去评价一个学生几个月甚至几年的努力,那我们就不配做教育。
更何况,AI本身就可以帮我们承担大部分重复性的工作。文字重复率检测、数据统计检验、代码相似度检测,这些都可以交给 AI 去做。老师只需要把精力放在最核心的地方:评价学生的思想和创造力。
也有人会说,这个方案的评价标准不够统一,容易产生主观判断。
但学术评价本来就不可能是完全客观的。一篇论文的价值,从来都不是一个数字能够衡量的。我们与其追求虚假的"数字公平",不如追求真正的 "实质公平"。
还有人会说,研究过程性原创性的部分内容也是可以用AI生成的。

只能说,想偷懒的人总有办法偷懒;但是查原创率起码可以让认真做学术、做研究的学生不被僵化的查AI率限制甚至惩罚。
AI时代已经到来,这是一个不可逆转的趋势。我们不能像鸵鸟一样把头埋在沙子里,试图用禁令和检测来阻挡技术的进步。
我们应该做的,是拥抱这个变化,重新定义学术诚信的内涵,重新设计学术评价的体系。
我们要培养的,不是不会用工具的人,而是会用工具创造的人。
我们要守护的,不是"每一个字都必须亲手写" 的古老传统,而是 "独立思考、求真务实" 的学术精神。
别再查AI率了。
让我们回到学术的本质,去查原创率,去查思想,去查那些真正属于人类的、不可替代的东西。
这才是解决当前乱象的唯一出路,也是高等教育的终极使命。
