 夜雨聆风
夜雨聆风ERA不是一个普通的 AI 聊天工具,而是把科研问题改写成可以打分的任务,再让大模型不断生成代码、执行代码、得到分数,并根据分数继续搜索更好的方案。
2026年5月,Google Research / Google DeepMind 团队在 Nature 发表了 ERA 相关论文 《An AI system to help scientists write expert-level empirical software》。ERA 的全称是 Empirical Research Assistance,可以理解为经验性科研软件助手。
它的目标不是简单帮你补全几行 Python,而是围绕一个明确的科学任务,自动尝试不同分析管线、模型结构、特征工程或数值方法,最终找到在指定评价指标上表现更好的代码。
这篇文章主要介绍
解释 ERA 到底是什么,适合解决什么问题; 用 WSL / Ubuntu + conda 虚拟环境 配置 ERA; 跑通官方公开仓库里的入门示例,并解释官网展示的几个 benchmark 到底做了什么。
1. 写在前面
如果你是 Windows 用户,我不太建议直接在 Windows 原生 PowerShell 里折腾 ERA。
原因很简单:ERA 的公开示例和大多数科研计算环境都更接近 Linux 工作流。用 WSL 或 Ubuntu,可以减少路径、依赖、权限、编译工具等方面的麻烦。
本文默认推荐两种环境:
方案 A:Windows 电脑 + WSL2 + Ubuntu 方案 B:真实 Ubuntu 系统或 Ubuntu 服务器
对于大多数 Windows 用户,WSL2 + Ubuntu 是最省事的路线。它让你在 Windows 里直接运行 Linux 命令行环境,不需要双系统,也不需要完整虚拟机。
还要注意一点:在 WSL 里做 Python 项目时,建议把项目放在 Linux 文件系统里,例如:
~/projects/era不要放在:
/mnt/c/Users/你的用户名/Desktop/era放在 /mnt/c 下面当然也能跑,但性能和路径兼容性更容易出问题。微软官方也建议,如果你是在 WSL 的 Linux 命令行里工作,应优先把项目文件放在 WSL 文件系统中。
2. ERA 到底是什么?
ERA 的核心机制是:
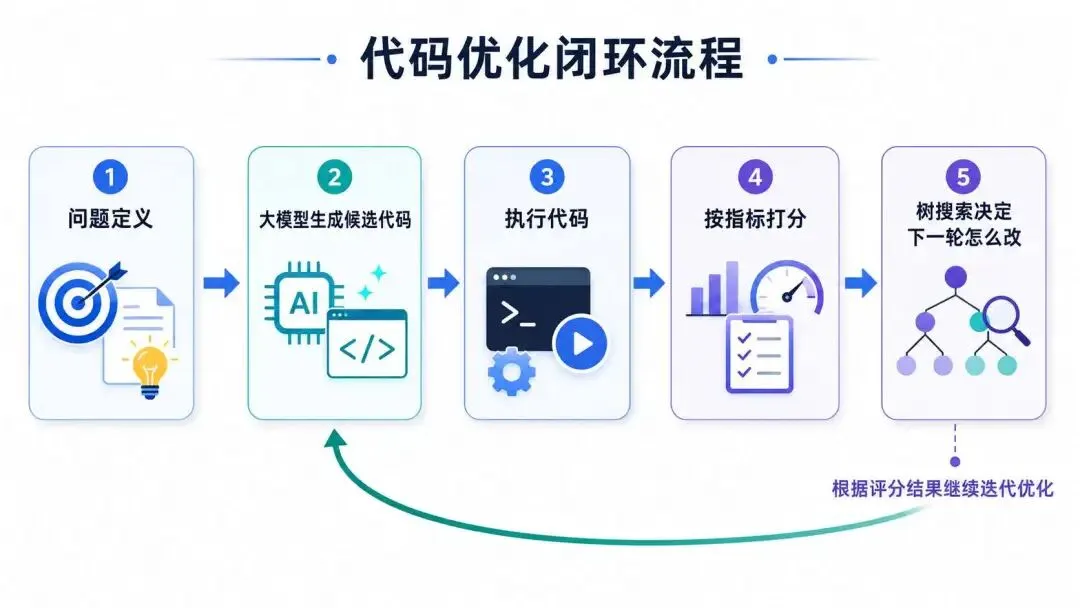
它比普通“让 ChatGPT 写代码”多了两个关键环节:执行 和 评分。
普通 AI 写代码通常是一次性的:你问一次,它答一次。
ERA 更像一个会反复试错的科研编程助手:
先写一个方案,跑一下,看分数,再写一个改进版,再跑一下,继续比较。
所以 ERA 最适合的问题,不是“帮我写一个函数”,而是这类任务:
有数据; 有明确评价指标; 有很多可能的分析方案; 需要反复尝试、比较和优化。
但是,它不等于完全自动的科学家。ERA 能帮你搜索代码方案,不能替代研究者定义问题、设计验证、判断结果是否可信。
3. 环境准备:WSL / Ubuntu
3.1 Windows 用户:安装 WSL2 + Ubuntu
在 Windows 上打开 PowerShell 管理员模式,运行:
wsl --install默认情况下,这个命令会安装 WSL 并安装 Ubuntu。如果你想指定 Ubuntu 版本,可以先查看可安装发行版:
wsl --list --online然后指定安装,例如:
wsl --install -d Ubuntu-24.04安装完成后,重启电脑,打开 Ubuntu 终端,按提示创建 Linux 用户名和密码。
检查 WSL 版本:
wsl -l -v建议使用 WSL2。如果显示的是 WSL1,可以改成 WSL2:
wsl --set-version Ubuntu-24.04 2如果你的发行版名字不是 Ubuntu-24.04,以 wsl -l -v 显示的名字为准。
3.2 Ubuntu 里安装基础工具
打开 Ubuntu 终端,先更新软件源:
sudo apt updatesudo apt upgrade -y安装基础工具:
sudo apt install -y git curl wget ca-certificates build-essential unzip建立项目目录:
mkdir -p ~/projectscd ~/projects后面所有 ERA 相关操作,都建议在 ~/projects 里完成。
4. 安装 conda:推荐 Miniforge,也可以用 Miniconda
这里推荐使用 Miniforge,因为它默认使用 conda-forge 频道,适合科研 Python 环境。你也可以用 Miniconda,二者都能创建 conda 虚拟环境。
4.1 方案一:安装 Miniforge(推荐)
在 Ubuntu 终端里运行:
cd ~wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.shbash Miniforge3-Linux-x86_64.sh -b -p "$HOME/miniforge3"rm Miniforge3-Linux-x86_64.sh初始化 conda:
source"$HOME/miniforge3/etc/profile.d/conda.sh"conda init bash关闭当前 Ubuntu 终端,再重新打开,检查是否安装成功:
conda --version如果能看到类似下面的输出,就说明成功了:
conda 26.x.x4.2 方案二:安装 Miniconda
如果你更习惯 Miniconda,也可以这样装:
cd ~wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda3-latest-Linux-x86_64.sh -b -p "$HOME/miniconda3"rm Miniconda3-latest-Linux-x86_64.sh初始化:
source"$HOME/miniconda3/etc/profile.d/conda.sh"conda init bash重新打开 Ubuntu 终端后检查:
conda --version4.3 避免 base 环境自动激活
很多人不喜欢每次打开终端就进入 (base)。可以关闭自动激活:
conda config --set auto_activate_base false然后关闭终端再打开。后面需要 ERA 环境时,我们手动激活即可。
5. 创建 ERA 专用虚拟环境
官方 README 写的是 Python 3.10+。为了稳妥,本文用 Python 3.10:
conda create -n era python=3.10 -yconda activate era确认 Python 版本:
python --version更新 pip:
python -m pip install -U pip安装常用科学计算依赖:
conda install -y -c conda-forge numpy pandas scikit-learn scipy matplotlib jupyter tabulate安装 Gemini 相关 SDK:
pip install -U google-genai google-generativeai为什么两个都装?
因为 ERA 仓库 README 里列的是 google-generativeai,但当前公开代码中的 llm.py 使用的是:
from google import genai这个写法对应的是新版 google-genai。两个都装,可以减少因为 SDK 名称变化导致的导入错误。
检查新版 SDK 是否可导入:
python - <<'PY'from google import genaiprint("google-genai import OK")PY如果能打印出 google-genai import OK,说明这一步没问题。
6. 克隆 ERA 仓库
进入项目目录:
mkdir -p ~/projectscd ~/projects克隆仓库:
git clone https://github.com/google-research/era.gitcd era查看目录:
ls你应该能看到类似这些内容:
README.mdimplementationdocsera_applications这里最重要的是:
implementation/ 入门演示和 FUTS 搜索实现docs/ 官网展示页面对应的实验列表era_applications/ 更接近真实科研任务的应用案例7. 配置 Gemini API key
ERA 需要调用 Gemini 模型生成候选代码,所以需要 Gemini API key。
最安全的做法是:只在当前终端会话里临时设置,不要把 key 写进代码。
在 Ubuntu 终端里运行:
read -s GEMINI_API_KEYexport GEMINI_API_KEYexport GOOGLE_API_KEY="$GEMINI_API_KEY"运行第一行后,终端会等待你输入 API key。粘贴后按回车即可。因为用了 -s,屏幕上不会显示你输入的内容。
检查环境变量是否存在:
python - <<'PY'import osprint("GEMINI_API_KEY exists:", bool(os.environ.get("GEMINI_API_KEY")))print("GOOGLE_API_KEY exists:", bool(os.environ.get("GOOGLE_API_KEY")))PY为什么两个变量都设置?
因为公开仓库 README 写的是 GOOGLE_API_KEY,但当前入门示例 playground_s3e1.py 读取的是 GEMINI_API_KEY。两个都设,最不容易出错。
8. 运行前先处理两个实操坑
当前公开仓库是研究代码,不是面向普通用户打磨过的一键安装包。第一次跑示例前,建议先处理两个问题。
8.1 第一个坑:sandbox.py 需要自己实现
ERA 会执行大模型生成的代码。因此,官方在 implementation/sandbox.py 里留了一个接口,提醒实际运行时应该使用沙箱环境。
这件事很重要。因为候选代码一旦执行,就可能读取、写入或删除它有权限访问的文件。
如果只是为了在本地跑通官方玩具示例,可以先用下面这个 教学版本地执行器 替换 implementation/sandbox.py。
再次提醒:
下面这段代码只用于教学演示,不是真正安全的沙箱。不要用它处理来历不明的数据,不要让它访问个人文件、SSH key、云盘目录、临床敏感数据或未脱敏数据。
在仓库根目录下运行:
cd ~/projects/eracat > implementation/sandbox.py <<'PY'# 教学演示版 sandbox.py# 仅用于跑通 ERA playground 示例;不是真正安全的沙箱。import jsonimport osimport subprocessimport sysimport tempfilefrom typing import Anyclass Sandbox:"""A minimal local runner for ERA toy demos. This is NOT a secure sandbox. For real research tasks, use Docker or another isolated execution environment with limited file and network access. """ def __init__(self, timeout_seconds: int = 60): self.timeout_seconds = timeout_seconds def run( self, program: str, function_to_run: str, test_input: Any = None, timeout_seconds: int | None = None, ): timeout = timeout_seconds or self.timeout_seconds with tempfile.TemporaryDirectory() as tmpdir: candidate_path = os.path.join(tmpdir, "candidate.py") runner_path = os.path.join(tmpdir, "runner.py") with open(candidate_path, "w", encoding="utf-8") as f: f.write(program) input_json = json.dumps(test_input) runner_code = f'''import importlib.utilimport jsondef to_jsonable(x): try: import numpy as np if isinstance(x, np.ndarray): return x.tolist() if isinstance(x, np.generic): return x.item() except Exception: pass if isinstance(x, (list, tuple)): return [to_jsonable(v) for v in x] if isinstance(x, dict): return {{str(k): to_jsonable(v) for k, v in x.items()}} return xspec = importlib.util.spec_from_file_location("candidate", r"{candidate_path}")mod = importlib.util.module_from_spec(spec)spec.loader.exec_module(mod)fn = getattr(mod, "{function_to_run}")inp = json.loads({input_json!r})result = fn(inp)print(json.dumps({{"ok": True, "result": to_jsonable(result)}}))''' with open(runner_path, "w", encoding="utf-8") as f: f.write(runner_code) try: proc = subprocess.run( [sys.executable, runner_path], cwd=tmpdir, capture_output=True, text=True, timeout=timeout, ) except subprocess.TimeoutExpired:return"Execution timed out", Falseif proc.returncode != 0:return proc.stderr, False try: last_line = proc.stdout.strip().splitlines()[-1] payload = json.loads(last_line)return payload.get("result"), bool(payload.get("ok")) except Exception as e:return f"Could not parse output: {e}\nSTDOUT:\n{proc.stdout}", FalsePY如果后面要做真实科研任务,建议改用 Docker、服务器隔离环境,或者至少使用独立用户、只读数据目录、受限输出目录和禁网执行环境。
8.2 第二个坑:模型名可能需要改
当前 implementation/llm.py 里有默认模型名。不同时间、不同账号、不同地区,Gemini API 可用模型可能不完全一样。
建议先把默认模型改成当前更适合文本和代码生成的模型,例如 gemini-2.5-flash:
cd ~/projects/era/implementationpython - <<'PY'from pathlib import Pathp = Path("llm.py")s = p.read_text()s = s.replace('model_name: str = "gemini-2.5-flash-image"','model_name: str = "gemini-2.5-flash"')p.write_text(s)print("patched llm.py")PY如果你想省钱,也可以把模型名改成:
gemini-2.5-flash-lite如果运行时报 model not found,不要硬猜模型名,去 Google AI Studio 或 Gemini API 模型列表里看你当前账号可用的模型。
9. 跑通官方入门示例
进入 implementation 目录:
cd ~/projects/era/implementation确认 conda 环境已经激活:
conda activate era确认数据文件存在:
ls data/playground-series-s3e1/train.csv如果能看到文件路径,说明示例数据在。
先只跑 2 轮,测试流程是否能跑通:
python - <<'PY'import playground_s3e1playground_s3e1.run_experiment(iterations=2)PY如果一切正常,你会看到类似输出:
Preparing local validation split...Both GOOGLE_API_KEY and GEMINI_API_KEY are set. Using GOOGLE_API_KEY.Evaluating initial solution...Initial Score (Neg RMSE): -0.7339448894714725Starting Search...Progress saved to futs_progress.jsonBest Score: -0.5857342388973916Best Code:import pandas as pdimport numpy as npfrom sklearn.ensemble import HistGradientBoostingRegressordef train_and_predict(train_path, test_path): # Load data train = pd.read_csv(train_path) test = pd.read_csv(test_path) # Drop 'id' column as it's not a feature train = train.drop('id', axis=1) test_ids = test['id'] # Store test IDs if needed for submission, though not used for prediction here. test = test.drop('id', axis=1) # Feature Engineering def create_features(df): # Base features from the dataset: # MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude # Features from the previous solution df['bedrooms_per_room'] = df['AveBedrms'] / df['AveRooms'] df['population_per_household'] = df['Population'] / df['AveOccup'] df['rooms_per_person'] = df['AveRooms'] / df['AveOccup'] df['MedInc_sq'] = df['MedInc']**2 df['HouseAge_sq'] = df['HouseAge']**2 df['lat_lon_prod'] = df['Latitude'] * df['Longitude'] df['lat_plus_lon'] = df['Latitude'] + df['Longitude'] df['lat_minus_lon'] = df['Latitude'] - df['Longitude'] df['MedInc_Lat_Prod'] = df['MedInc'] * df['Latitude'] df['MedInc_Lon_Prod'] = df['MedInc'] * df['Longitude'] # NEW, IMPROVED FEATURES # 1. Geographical distance features to known points (e.g., major cities for coastal/urban influence) # San Francisco coordinates (approximate center) sf_lat, sf_lon = 37.77, -122.41 df['dist_to_SF'] = np.sqrt((df['Latitude'] - sf_lat)**2 + (df['Longitude'] - sf_lon)**2) # Los Angeles coordinates (approximate center) la_lat, la_lon = 34.05, -118.24 df['dist_to_LA'] = np.sqrt((df['Latitude'] - la_lat)**2 + (df['Longitude'] - la_lon)**2) # 2. Interaction features for strong predictors # Income per household member df['MedInc_x_AveOccup'] = df['MedInc'] * df['AveOccup'] # Interaction between house age and median income df['HouseAge_x_MedInc'] = df['HouseAge'] * df['MedInc'] # Interaction between average rooms and average bedrooms df['Rooms_x_Bedrms'] = df['AveRooms'] * df['AveBedrms'] # 3. Log transformations for skewed features (Population and AveOccup) # Using log1p to handle potential zero values gracefully, though typically not an issue here. df['log_Population'] = np.log1p(df['Population']) df['log_AveOccup'] = np.log1p(df['AveOccup']) return df train = create_features(train.copy()) test = create_features(test.copy()) # Define features (X) and target (y) X = train.drop('MedHouseVal', axis=1) y = train['MedHouseVal'] # Ensure feature columns are aligned between train and test sets test_features = test[X.columns] # Model Training # Using HistGradientBoostingRegressor, a fast and efficient gradient boosting model. # It often provides better performance than RandomForestRegressor with similar constraints. # max_iter is set to 50, equivalent to n_estimators in other boosting models, as per constraints. # random_state for reproducibility. model = HistGradientBoostingRegressor(max_iter=50, random_state=42) model.fit(X, y) # Predict predictions = model.predict(test_features) return predictions这里的 Neg RMSE 指的是负的 RMSE。因为 FUTS 搜索默认是最大化分数,所以脚本把 RMSE 取了负数:
RMSE 越低越好;负 RMSE 越高越好。确认 2 轮没问题后,再跑默认 10 轮:
python playground_s3e1.py运行结束后,查看结果文件:
ls results一般会看到:
futs_progress.json查看搜索进度:
python - <<'PY'import jsonfrom pathlib import Pathp = Path("results/futs_progress.json")print("exists:", p.exists())if p.exists(): hist = json.loads(p.read_text())print("number of records:", len(hist))print("first record:", hist[0])print("last record:", hist[-1])PY如果你想把进度画成图,可以运行:
python - <<'PY'import jsonfrom pathlib import Pathimport matplotlib.pyplot as plthist = json.loads(Path("results/futs_progress.json").read_text())xs = [r["iteration"] for r in hist]ys = [r["best_score"] for r in hist]plt.figure()plt.plot(xs, ys, marker="o")plt.xlabel("Iteration")plt.ylabel("Best score so far: negative RMSE")plt.title("ERA toy demo progress")plt.tight_layout()Path("results").mkdir(exist_ok=True)plt.savefig("results/futs_progress.png", dpi=200)print("saved: results/futs_progress.png")PY然后查看:
ls results/futs_progress.png这张图展示的是:随着迭代次数增加,ERA 当前找到的最好方案有没有变好。
10. 这个 California Housing 示例到底演示了什么?
公开仓库的 playground_s3e1.py 用的是一个 Kaggle 风格的房价回归任务。它不是为了证明 ERA 能解决房地产问题,而是为了演示 ERA 的基本循环。
它做的事情大致是:
读取 train.csv;把数据切成训练集和本地验证集; 用线性回归作为初始方案; 让 Gemini 生成新的 train_and_predict(train_path, test_path)函数;执行生成的代码; 用 RMSE 给代码打分; 让 FUTS 树搜索决定下一轮从哪个方案继续改。
这和普通调参不完全一样。
普通调参通常是在固定模型里调几个参数。ERA 的搜索空间更大:它可以改变特征工程、模型类型、模型组合、数据处理方式,甚至改写整个分析函数。
当然,入门示例里为了速度和安全,已经限制了很多东西,例如不允许使用 xgboost 或 lightgbm,也限制了随机森林和 boosting 的树数量。
所以我们不要把这个玩具示例理解成“ERA 已经帮我做出最佳模型”。更准确地说,它演示的是:
ERA 如何把一个可评分的机器学习任务,变成生成代码—执行—评分—继续改进的闭环。
11. 常见报错与处理
11.1 ModuleNotFoundError: No module named 'google.genai'
说明没有安装新版 Google GenAI SDK。处理:
conda activate erapip install -U google-genai再测试:
python - <<'PY'from google import genaiprint("OK")PY11.2 Set GEMINI_API_KEY
说明当前终端没有设置 API key。重新设置:
read -s GEMINI_API_KEYexport GEMINI_API_KEYexport GOOGLE_API_KEY="$GEMINI_API_KEY"11.3 model not found
说明模型名不可用。打开 implementation/llm.py,把模型名改成你当前账号可用的模型,例如:
gemini-2.5-flashgemini-2.5-flash-lite具体以 Google AI Studio / Gemini API 模型列表为准。
11.4 tabulate 相关报错
pandas.DataFrame.to_markdown() 需要 tabulate。处理:
conda install -y -c conda-forge tabulate11.5 运行很慢或卡住
可能原因包括:
模型响应慢; API 限流; 候选代码训练时间太长; 项目放在 /mnt/c 下面导致 WSL 文件访问变慢; 网络访问不稳定。
建议先只跑 2 轮:
python - <<'PY'import playground_s3e1playground_s3e1.run_experiment(iterations=2)PY确认没问题后再增加迭代次数。
12. 安全提醒:不要在日常电脑环境里裸跑生成代码
ERA 和普通聊天机器人最大的区别是:ERA 会执行大模型生成的代码。
这意味着,候选代码理论上可以做很多事情:
读取当前目录文件; 写入或覆盖文件; 读取环境变量; 消耗大量 CPU / 内存; 如果有网络权限,还可能访问外部网络。
所以真实科研任务里,建议至少做到:
项目目录:单独建立; 公开数据目录:尽量只读; 输出目录:只允许写入结果; 个人目录:不要挂载给候选代码; API key:不要暴露给候选代码执行环境; 网络:候选代码执行阶段能关就关; 权限:不要用 root 用户运行候选代码; 资源:限制单轮运行时间、内存和磁盘空间。
这也是为什么本文虽然给了一个教学版 sandbox.py,但反复强调它不是真正安全的沙箱。
如果你只是跑官方玩具示例,教学版足够理解流程。
如果你要做真实课题,建议使用 Docker 或服务器隔离环境。
13. 成本提醒:ERA 会消耗 token,也会消耗计算资源
ERA 每一轮都可能调用一次大模型:发送问题描述、数据预览、历史方案、上一轮代码和分数;模型返回新的候选代码;本地执行候选代码;记录分数;进入下一轮。
因此,成本主要来自两部分:1. Gemini API token;2. 本地或云端计算资源。
入门示例这种小表格任务,成本一般不会太夸张。但如果你把 ERA 用到复杂任务,例如 3D 医学影像、深度学习训练、大规模单细胞数据或复杂仿真,真正烧钱的可能不只是 token,还有 GPU、内存、存储和运行时间。
14. 官网展示的几个例子主要做了什么?有什么用?
ERA 官网展示了六个主要 benchmark:
scRNA-seq Batch IntegrationCOVID ForecastingGeospatial AnalysisZAPBenchGIFT-EvalIntegrals下面逐个解释。
14.1 scRNA-seq Batch Integration:单细胞批次整合
单细胞 RNA 测序数据经常来自不同实验室、不同平台、不同批次。直接合并时,模型可能学到的是“哪个实验室测的”,而不是真实细胞类型或疾病状态。
这个任务的目标是:
尽量去掉技术批次差异,同时保留真实生物差异。
难点在于,校正太弱,批次效应还在;校正太强,又会把真正的生物信号抹掉。
ERA 在这个任务中搜索新的批次整合方法。官方博客提到,ERA 在 OpenProblems v2.0.0 batch integration benchmark 上发现了 40 个超过顶尖人工方法的新方法。
有什么用?
如果批次整合做得更好,研究者就能更可靠地合并大型单细胞队列。这对疾病细胞图谱、药物靶点发现、多中心队列分析都很重要。
14.2 COVID Forecasting:新冠住院人数预测
这个任务要预测未来几周不同地区的新冠住院人数。它不是简单输出一个数字,而是做概率预测,要给出不同分位数范围,并用指标评价预测质量。
官方博客提到,ERA 生成了多个预测模型,表现超过 CDC ensemble 和各个单独模型。
有什么用?
公共卫生部门需要提前知道未来住院压力。预测更准,医院床位、人力、药品和应急资源调配就更有依据。
这个例子说明,ERA 不只适合生命组学,也能处理公共卫生时间序列预测。
14.3 Geospatial Analysis:遥感图像语义分割
这个任务是给遥感图像中的每个像素分类,比如建筑、道路、水体、植被等。
ERA 在遥感数据集上搜索图像分割方案。官方博客提到,高分方案组合了 U-Net、UNet++、SegFormer、预训练编码器和 test-time augmentation 等策略。
有什么用?
遥感语义分割可以用于土地利用监测、城市扩张分析、灾害评估、森林变化追踪和环境监管。
这个例子展示的是:ERA 可以自动组合已有视觉模型和工程技巧,搜索更好的图像分析方案。
14.4 ZAPBench:斑马鱼全脑神经活动预测
ZAPBench 是一个神经科学任务,目标是预测斑马鱼大量神经元的活动。
这类任务很难,因为它既是高维时间序列,又涉及神经系统动态。官方博客提到,ERA 找到的新时间序列预测模型超过了已有基线,还探索了把生物物理神经模拟器纳入混合模型的可能性。
有什么用?
神经科学不只想要“预测更准”,还希望模型能帮助解释神经系统如何工作。如果 ERA 能帮助构建兼具预测能力和机制解释的模型,就可能用于系统神经科学中的模型发现。
14.5 GIFT-Eval:通用时间序列预测
GIFT-Eval 是一个通用时间序列预测 benchmark,覆盖多个领域、多个数据频率和多类预测问题。
ERA 的任务不是只针对一个固定数据集调参,而是尝试构建一个更通用的预测库,让它在整个 benchmark 上取得更好的平均表现。
有什么用?
时间序列预测在科研和产业中都非常常见:流行病、气候、水文、能源、零售、金融都离不开预测。
这个例子说明,ERA 可以尝试从多个数据集里总结更通用的预测策略。
14.6 Integrals:困难积分的数值求解
这个例子看起来离生物医学很远,但很能说明 ERA 的通用性。
任务是求解困难积分。官方博客提到,ERA 生成的方案在一组保留测试积分上明显优于标准 SciPy 数值方法。
有什么用?
很多物理、工程、应用数学问题都会遇到难以稳定数值计算的积分。ERA 在这里展示的是:只要问题能被明确打分,它不一定局限于机器学习建模,也可以参与数值计算方法探索。
15. ERA applications 目录还展示了什么?
除了官网六个 benchmark,公开仓库的 era_applications/ 目录还放了一批更接近真实科研问题的案例。
可以把它们理解成 ERA 可能进入的应用方向:
这些案例有一个共同点:
不是让 AI 直接给出一句答案,而是把科学问题拆成可评价的计算任务,再让 ERA 在大量候选代码中搜索更好的方案。
当然,ERA 还远不是万能工具。它需要清晰的问题定义,需要可靠的评价指标,需要安全的执行环境,也需要研究者对结果保持判断力。
尽管如此,我已非常兴奋。
