 夜雨聆风
夜雨聆风10篇文章看懂AI Agent(九):评测与追踪——怎么知道AI Agent靠不靠谱?
跑起来不难,跑得好、跑得稳、跑得省,才是真本事
前面八篇,我们完整拆解了AI Agent的全套核心能力:
思考规划、工具调用、RAG检索、长期记忆、浏览器操作、安全权限防护……
到这里,一个完整的AI Agent已经能顺利“跑起来”。
但随之而来的,是所有落地者都会遇到的核心问题:
你怎么确定你的Agent到底靠不靠谱?
它时而成功、时而翻车。任务失败后,你只能看到“结果不对”,却完全找不到根因:
是规划逻辑错了?工具选错了?参数填错了?还是外部系统卡顿超时?
无法观测、无法评测、无法复盘的Agent,永远只是玩具,成不了落地工具。
今天这篇,我们彻底讲透:如何全方位评测Agent、全链路追踪问题、常态化迭代优化。
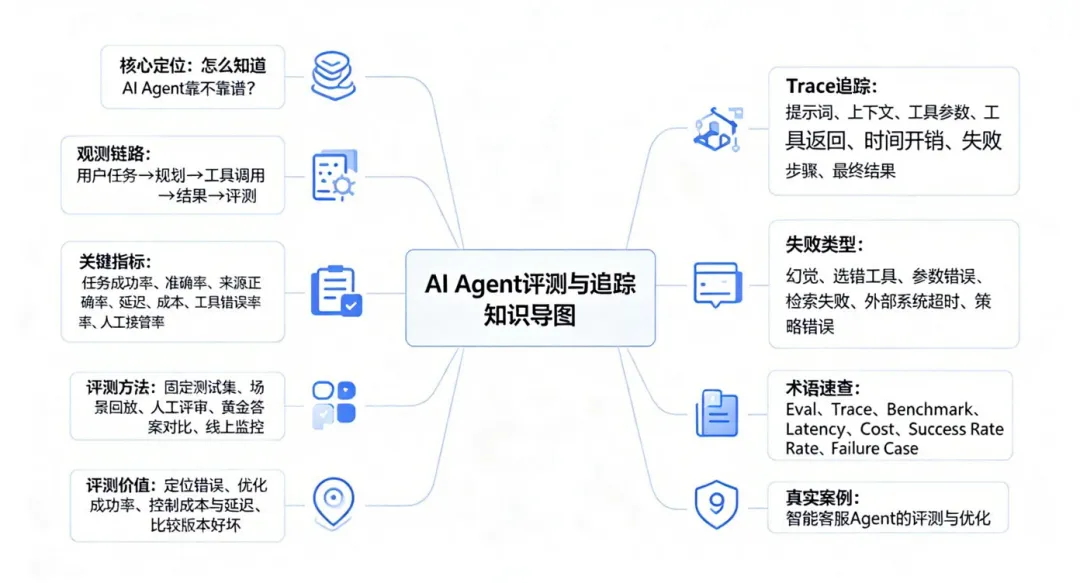
一、端到端全链路观测:每一步都有据可查
评判Agent质量,绝对不能只看最终结果。
想要精准定位问题,必须打通完整执行链路,记录每一个执行环节:
用户任务 → 智能规划 → 工具调用 → 结果输出 → 质量评测
链路中的每一步,都必须留存四大核心记录要素,缺一不可👇
记录项 | 详细含义 | 实战案例 |
|---|---|---|
输入 | 当前环节接收的原始信息、用户指令 | 用户指令:帮我预订明天的往返机票 |
输出 | 当前环节模型输出、执行动作与决策结果 | AI规划:调用航班搜索工具,查询明日往返航班 |
时间 | 单环节耗时、整体链路总耗时 | 任务规划环节耗时1.2秒 |
错误 | 环节报错、异常信息、错误码与失败原因 | 工具调用超时,请求错误码408 |
只有完成全链路记录,才能实现:每条任务可回放、每处错误可精准定位。
二、七大核心指标:量化判断Agent靠不靠谱
不靠感觉、不靠主观体验,用7项硬核数据,客观衡量Agent真实能力👇
核心指标 | 通俗解读 | 核心价值 |
|---|---|---|
任务成功率 | 完整满足用户所有需求、顺利闭环的任务占比 | Agent最核心指标,直接决定能否落地使用 |
准确率 | 输出内容与真实事实、用户需求的匹配度 | 杜绝答非所问、内容虚假、逻辑混乱等问题 |
来源正确率 | 引用资料、检索内容的来源是否真实可靠 | 从源头规避虚假信息、错误数据 |
延迟 | 用户发指令到得到最终结果的总耗时 | 直接影响用户体验,速度太慢毫无实用性 |
成本 | 单次任务模型调用+工具调用的总消耗 | 决定规模化落地的性价比,太贵无法商用 |
工具错误率 | 工具调用失败、参数错误、返回异常的比例 | 反映外部系统适配能力与工具调用稳定性 |
人工接管率 | 需要人工介入辅助完成的任务占比 | 比例过高,说明自动化形同虚设 |
行业理想落地标准:成功率99%、延迟<3秒、单条成本极低、人工接管率<1%。
三、Trace追踪:记录Agent的完整“执行日记”
Trace就像Agent的飞行黑匣子,完整记录任务全流程心路历程,出问题可随时回放复盘。
一套完整的Trace日志,必须包含7项核心内容👇
记录项 | 大白话解释 |
|---|---|
提示词 | 模型接收的原始指令、系统提示、约束规则 |
上下文 | 对话历史、检索知识、用户画像、场景背景等全部信息 |
工具参数 | 调用了哪些工具、传入了哪些参数、参数格式是否合规 |
工具返回 | 工具执行后的原始返回结果、数据内容、异常提示 |
时间开销 | 规划、检索、工具调用、生成结果各环节耗时分布 |
失败步骤 | 具体出错环节、错误码、报错原因、异常场景 |
最终结果 | 任务最终输出内容、执行状态(成功/失败/部分成功) |
核心价值:没有Trace,排查问题全靠猜;有了Trace,优化迭代全靠数据。
四、五大评测方法:组合使用,兼顾质量与效率
单一评测方式总有短板,五种方法搭配使用,才能全方位校验Agent能力👇
评测方法 | 执行方式 | 核心优点 | 存在短板 |
|---|---|---|---|
固定测试集 | 使用标准化题库批量自动化测试 | 公平稳定、可横向对比、可自动化落地 | 场景固定,可能脱离真实业务场景 |
场景回放 | 复用真实用户历史对话,重新复现执行 | 完全贴合真实场景,可验证版本回归问题 | 需要长期积累真实业务数据 |
人工评审 | 专业人员对结果质量、逻辑、合理性打分 | 精度最高,可发现细微逻辑漏洞 | 耗时耗力、成本高、无法大规模批量测 |
黄金答案对比 | 将AI输出与权威标准答案做匹配对比 | 客观量化、数据直观、可量化打分 | 需要提前人工整理标准答案库 |
线上监控 | 上线后实时监控指标、捕捉异常、触发告警 | 实时发现线上问题,覆盖全量场景 | 仅能发现问题,精准定位需配合Trace |
行业最佳实践:
- 上线前:固定测试集 + 黄金答案对比,兜底基础质量
- 版本迭代:关键更新必须人工评审,规避隐性问题
- 上线后:线上实时监控 + 历史场景回放,持续优化
五、六大典型失败类型:精准踩坑+针对性解决
Agent绝大多数翻车问题,都逃不开这6类场景,对应精准解决方案👇
失败类型 | 问题释义 | 真实案例 | 优化方案 |
|---|---|---|---|
模型幻觉 | 生成虚假、不实、无依据的内容 | 公司年假实际10天,AI虚构回答15天 | 接入RAG知识库、工具溯源、输出内容过滤 |
选错工具 | 工具匹配错误,用错能力模块 | 用户查天气,AI错误调用股票查询工具 | 优化工具描述、增加示例、强化匹配逻辑 |
参数错误 | 参数缺失、格式错误、类型不匹配 | 天气查询传入数字ID,而非城市名称 | 新增参数强制校验、自动补全、格式修正 |
检索失败 | 检索无结果、返回内容不相关 | 查询业务问题,RAG匹配到无关文档 | 优化文本切块、查询改写、结果重排机制 |
外部超时 | 第三方API卡顿、限流、宕机无响应 | 日历服务超时,AI等待后直接任务失败 | 增加重试机制、超时降级、异常兜底方案 |
策略拦截 | 触发安全、合规、权限策略被拦截 | AI尝试群发邮件,被安全护栏直接拦截 | 优化提示词、调整权限范围、适配合规策略 |
六、评测与追踪的四大核心价值
1. 精准定位问题,大幅降低排查成本
依托Trace全链路日志,无需人工盲猜,几分钟即可定位根因,替代几小时的低效排查。
2. 持续提升任务成功率
通过数据复盘薄弱环节,针对性优化规划、检索、工具调用能力,让Agent效果稳步上涨。
3. 严控成本与响应延迟
监控每一步耗时、消耗,通过替换轻量化模型、合并工具调用、减少无效请求,大幅降本提效。
4. 数据化对比版本优劣
摒弃“感觉更好”的主观判断,用统一指标、测试集、失败率数据,科学判定版本好坏,稳妥迭代上线。
七、高频术语速查|零基础秒懂
专业术语 | 大白话解释 |
|---|---|
Eval(评测) | 通过数据指标、测试标准给AI能力打分,量化质量高低 |
Trace(追踪) | 任务全流程黑匣子,完整记录每一步操作,用于复盘排错 |
Benchmark基准测试 | 标准化测试题库,相当于AI的“统考卷子”,用于版本对比 |
Latency延迟 | 用户提问到AI输出结果的总耗时,数值越低体验越好 |
Cost成本 | 单次任务调用模型、工具产生的全部费用 |
Success Rate成功率 | 完整闭环、满足需求的任务占比,核心落地指标 |
Failure Case失败案例 | 任务失败的典型样本,是迭代优化的核心素材 |
八、真实落地案例:客服Agent全流程优化复盘
业务场景:企业智能订单客服Agent,负责帮用户查询订单、物流状态。
❌ 上线初期数据(问题突出)
- 任务成功率:72%
- 平均响应延迟:8秒
- 单次任务成本:0.5元
- 人工接管率:15%
🔍 基于Trace日志排查根因
1. 40%失败:参数缺失——查询订单未自动提取用户ID,直接请求失败
2. 30%失败:外部超时——订单系统响应缓慢,5秒超时直接终止任务
3.20%失败:工具选错——物流问题错误调用商品详情工具
4. 10%失败:零散逻辑、检索匹配问题
✅ 针对性优化动作
1. 补齐参数逻辑:强制提取用户ID,缺失则主动反问用户
2. 优化超时策略:超时阈值从5秒调整为10秒,新增2次自动重试
3. 优化工具区分:细化工具描述,增加场景示例,杜绝工具错配
📈 优化后迭代数据
- 任务成功率:72% → 91%
- 响应延迟:8秒 → 5秒
- 单次成本:0.5元 → 0.3元
- 人工接管率:15% → 6%
持续迭代优化后,可稳步冲击95%以上成功率,完全满足企业落地标准。
九、全文核心总结
Agent能跑起来只是基础,可评测、可追踪、可迭代,才是真正可用的落地产品。
没有评测,你永远不知道Agent的真实水平;
没有追踪,出了问题只能盲目排查、无从下手;
没有对比,版本迭代只能靠感觉、无法科学优化。
评测与追踪,是AI Agent从“demo玩具”走向“企业级工具”的必经闭环。
如果这个AI Agent系列干货对你有帮助,欢迎点赞、在看、转发,一起从零吃透AI Agent!
