 夜雨聆风
夜雨聆风 很多人处理 PDF 的旧习惯很简单。
很多人处理 PDF 的旧习惯很简单。
要合并,搜一个在线 PDF 合并。要压缩,再搜一个压缩工具。要 OCR、签名、加水印、转图片、删页面,又打开另一个网站。普通文件这么做问题不大,但合同、扫描件、发票、身份证明、客户资料一旦也这样传上去,心里就会不踏实。
Stirling-PDF 值得看的地方就在这里。它不是只告诉你“功能很多”,而是给了一个本地或自托管处理 PDF 的选择。你可以先把敏感文件少传一步。
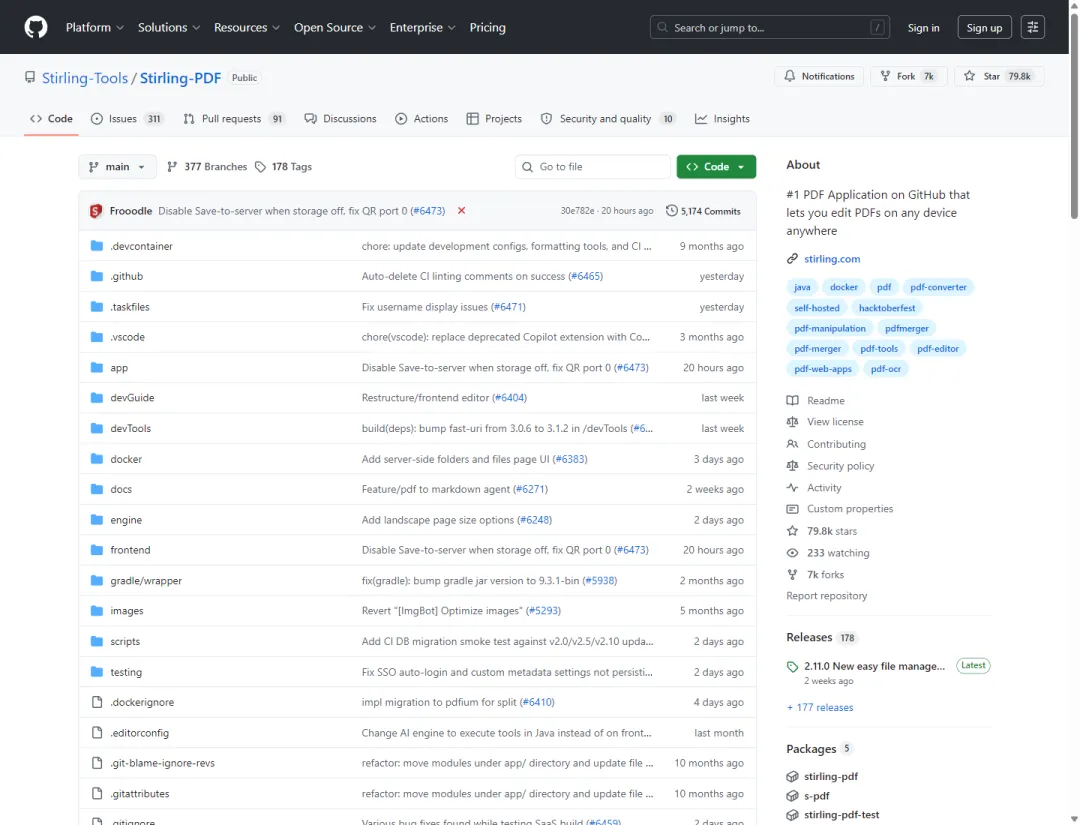
我先看仓库页。Stirling-PDF 是一个开源 PDF editing platform,README 里写得很清楚,可以当桌面 app、浏览器 UI,或者部署到自己的服务器上,用来 edit、sign、redact、convert、automate PDFs,而不是把文档发给外部服务。
这个点对普通用户和小团队都很现实。PDF 工具不是新东西,真正的问题是很多在线工具太顺手,顺手到你忘了文件本身可能很敏感。
README 的 quickstart 也很短。
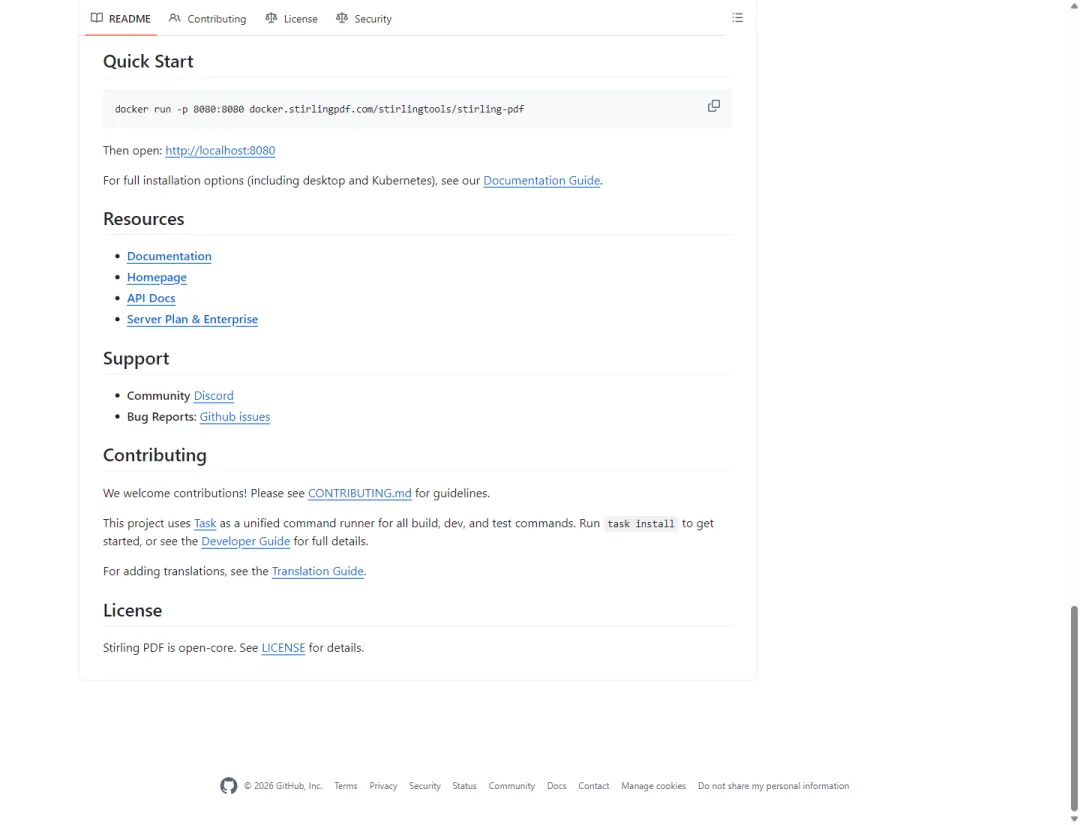
它给的是一条 Docker 命令,跑起来后打开本机 8080 端口。这说明它不是只能给开发者看源码,也不是只能用云端服务。对小团队来说,这种工具的理想用法不是每个人随便找网站,而是在一个可控环境里处理 PDF。
这篇我没有拉 Docker 镜像,也没有在本机跑,所以不写“亲测跑通”。但就选题判断来说,README、docs、license 和 telemetry 文档已经足够先做一轮判断。
docs 里最关键的一句是 local file processing with automatic deletion post-task。它还写了 60+ tools,包括 signing、converting、merging 等能力。你不用把它理解成一个“万能 PDF 工具”,更实际的看法是,它把常见 PDF 脏活集中到一个可控入口里。
这能减少两种阻力。
第一是情感阻力。你不想把合同、扫描件、客户资料丢给不知道是谁的网站。自托管和本地处理至少让你有机会把文件留在自己的机器或服务器里。
第二是惰性。PDF 操作本来就碎。合并一个工具,压缩一个工具,OCR 又一个工具。Stirling-PDF 把这些东西放进同一个入口,减少来回找网站和格式返工。
但这不是闭眼推荐。
license 要看。仓库 README 写的是 open-core,LICENSE 文件也说明主内容按 MIT License,但 proprietary、saas、desktop、engine 等目录如果存在,会按各自目录里的 license 处理。自己用通常问题不大,准备二次分发、集成进商业系统,不能只看 GitHub 右侧的 license 标签。
telemetry 也要看。官方文档写明 analytics 是 opt-in,可以禁用,也说明不会收集 document content、PDF data 或 file metadata。这个说明是加分项,但真正部署时还是要检查配置,特别是公司内网、客户资料、合规要求比较高的场景。
还有一个现实问题,OCR、大文件、批处理都吃资源。你用在线工具时,算力和等待时间由别人承担。你放到本地或自托管环境,性能、存储、权限、备份和升级就要自己负责。
所以它适合三类人。
第一类是经常处理 PDF 的普通用户和知识工作者。你不一定要部署服务器,先知道有这种本地路径就够了。
第二类是小团队、运营、财务、法务、行政。你们手里有合同、扫描件、票据、客户材料,最不该每个人各自找在线网站。
第三类是开发者和内部工具负责人。它可以作为一个 PDF 处理入口,也可以通过 API 接进现有流程,但要先把 license、telemetry、权限和资源成本讲清楚。
不适合谁。你一年只处理一两个普通 PDF,文件也不敏感,没必要折腾。你只是想临时压缩一份公开材料,用系统自带工具或可信在线服务可能更快。你如果准备放到生产环境,也别只看一条 Docker 命令,先看部署、配置、升级和访问控制。
我的建议很简单。先不要拿真实合同测试。打开仓库和文档,看 quickstart、license、telemetry,再用一份非敏感 PDF 试。确认它能覆盖你最常见的几件事,比如合并、压缩、OCR、脱敏,再考虑是否部署给团队。
如果你也经常在不同 PDF 网站之间来回跳,Stirling-PDF 值得打开看一眼。它真正省的不是几次点击,而是少一次把敏感文件随手传出去的冲动。项目地址:https://github.com/Stirling-Tools/Stirling-PDF
感谢阅读,后面继续拆这种能帮普通人和小团队少踩坑的 GitHub 项目。
