 夜雨聆风
夜雨聆风前面三篇你已经会安装Claude code、也学会了如何有效跟Claude Code对话了。今天我们开始让Claude Code执行一些对话以外的工作。
第一个场景,让我们选择了最多人有共鸣的——资料整理。
你电脑里是不是有一些想看却一直没时间看的资料,比如:
一堆行业报告 PDF 会议纪要、合同 Word、Excel 报表 几十篇参考文献
现在有了Claude Code,你可以把这些资料喂给 Claude Code,让它替你读、替你提炼。

以下教程重点照顾用 DeepSeek、智谱 GLM 等国产模型的你。因为这里有个大坑,不讲清楚你会一头雾水。
一、先说个反直觉的真相
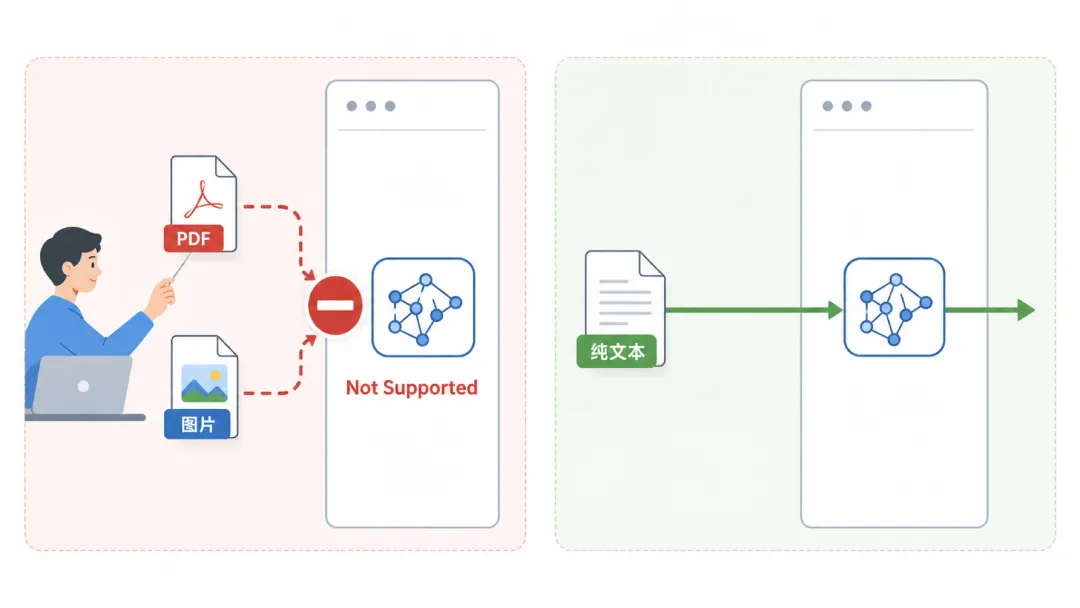
你可能以为:把 PDF 拖进去,AI 直接"看"一眼就读懂了。
用 Claude 原版模型确实可以。但用国产模型(DeepSeek / 智谱 GLM),不行。
为什么?因为国产模型接入 Claude Code 走的是"Anthropic 兼容接口",而这个接口——
- DeepSeek 官方明确写了:不支持图片、不支持 PDF 文档
[^1] - 智谱 GLM-4.6(最常用的那个)是纯文本模型
,也吃不了 PDF[^2]
那国产模型用户就没法整理资料了吗? 当然不是。有个万能解法,而且更稳。当然,并不是说一定需要走以下步骤,我在最新版本的Claude Code里已经试过,不用安装,它已经聪明到自己写脚本或者自动去下载三方工具来对PDF提取内容了。以下步骤供大家参考。
二、万能第一步:把资料变成"纯文本"
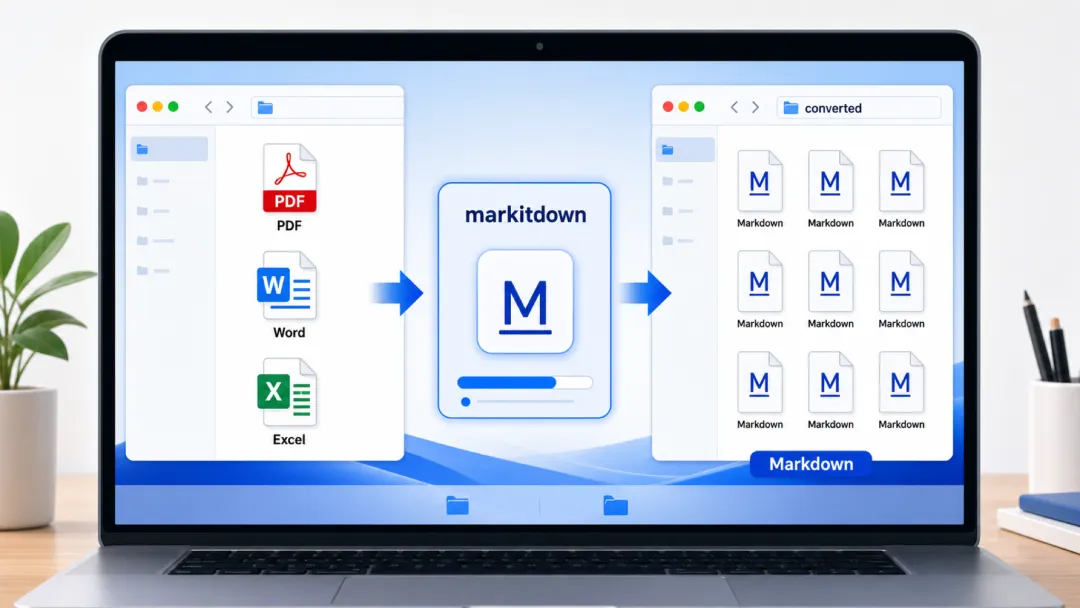
所有 AI 模型——不管 Claude 还是 DeepSeek、GLM——读纯文字都没问题。问题只出在"直接看 PDF/Word 这种特殊格式"上。
所以思路很简单:先把 PDF、Word、Excel 统统转成纯文本(Markdown),再交给 AI。 转换是在你电脑本地做的,完全不需要模型有什么多模态能力,DeepSeek、GLM 都照样顺畅。
转换神器叫 markitdown(微软开源的免费工具)[^4],专门干这个。
好消息是——你不用自己学怎么用它,让 Claude Code 替你装、替你转。
进到你的资料文件夹,启动 claude,直接说:
这个文件夹里有一堆 PDF 和 Word 文件。请先帮我装好 markitdown 工具,然后把所有这些文件转成 Markdown 纯文本,转好的文本放到一个 converted 子文件夹里。它会自己跑 pip install 'markitdown[all]'([all] 很关键,带上才能转 PDF/Word/Excel 全套格式),再一个个转换。转完,converted 文件夹里就是一堆 AI 能轻松读的 .md 文件了。
如果它转某个格式时报"缺依赖",提醒它"用 pip install 'markitdown[all]' 装全套"即可。
💡 markitdown 能转:PDF(文字版)、Word、Excel、PPT、HTML、CSV——常见办公格式基本全包[^4]。
三、第二步:让它综合成报告
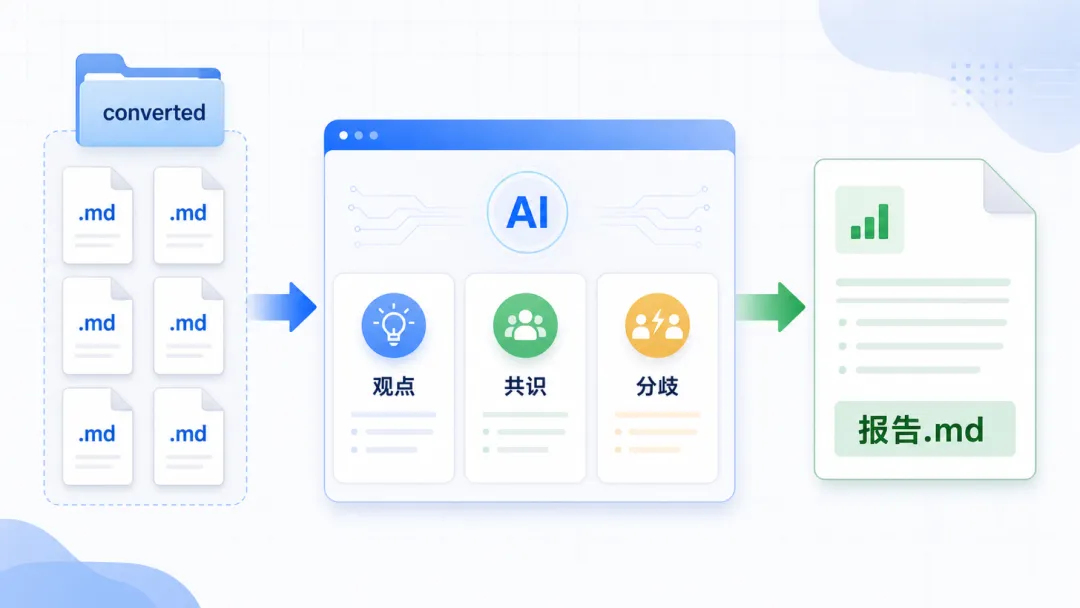
文本就位,开始派活。直接说人话:
读 converted 文件夹里所有的 .md 文件,帮我:1. 提炼每份的核心观点2. 找出它们的共识和分歧3. 汇总成一份报告,存成 报告.md这一步读的是纯文本,DeepSeek、GLM 完全胜任。
你出去倒杯水的工夫,报告.md 就静静躺在文件夹里了。
💡 关键心法:任务越具体,结果越好。"总结一下"太空泛;“提炼核心观点 + 找共识分歧 + 存成报告”——它就知道该交付什么。
🎁 偷懒版:其实你也可以把第二、第三步合成一句话——“把这个文件夹里的 PDF 和 Word 整理成一份综合报告”——它会自己想到"要先转文本再读"。但分步说更可控,新手建议先分步。
四、先让它列清单,你再决定
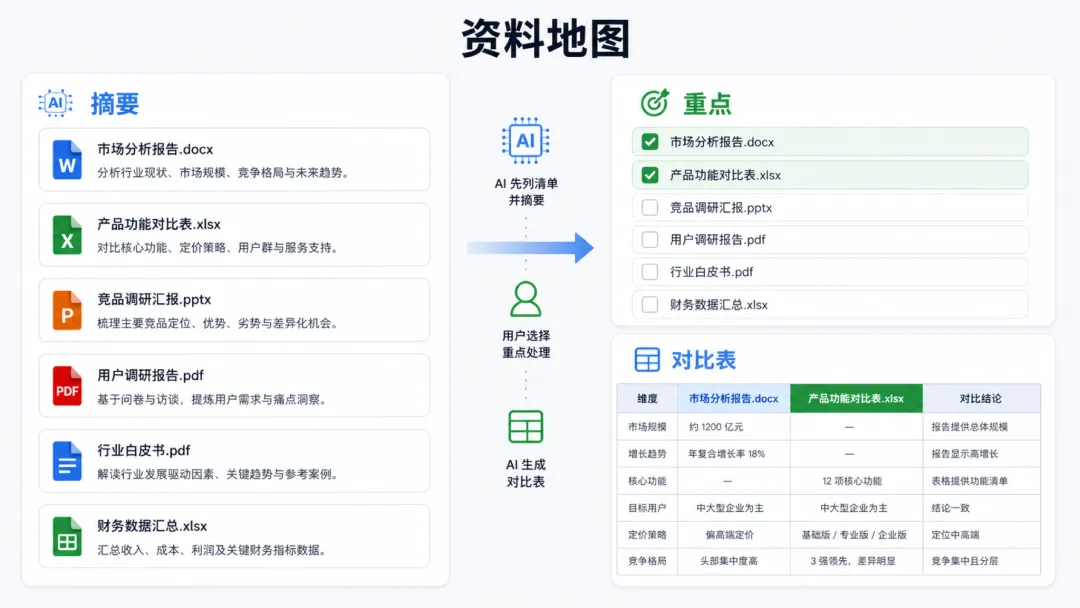
如果资料很多、很杂,别一上来就让它全做完。先让它列个清单给你看(转成文本之后):
converted 文件夹里每个文件大概讲什么?用一句话告诉我。它会给你一张"资料地图":
1. 2025行业白皮书.md —— 讲市场规模和增长预测2. 竞品分析.md —— 对比了 5 家主要厂商3. 会议纪要0512.md —— 上次战略会的决议...看完这张图,你再挑重点:
重点把第 1、2 份的数据提炼出来,做成一张对比表。这种"先勘探、再下手"的方式,比一股脑全扔给它更可控。
五、几个让结果更靠谱的小技巧

1. 让它标出处。 加一句"每个结论后面注明来自哪份文件",方便你回头核对。
2. 扫描版 PDF 要特殊处理。 如果你的 PDF 是拍照/扫描的图片(不是文字版),markitdown 转不出文字——这种得先用 OCR 工具(文字识别)转成文字。纯文字版 PDF 没这问题。
3. 一定要核对关键数据。 AI 提炼大体可靠,但涉及金额、日期、关键数字,自己回原文件核一遍。它是帮你省时间的助手,不是甩手不管的理由。
4. 让它存成文件。 加一句"存成 xxx.md",结果就落地成文件,不会聊完就没。
六、隐私:我的资料会被上传吗?
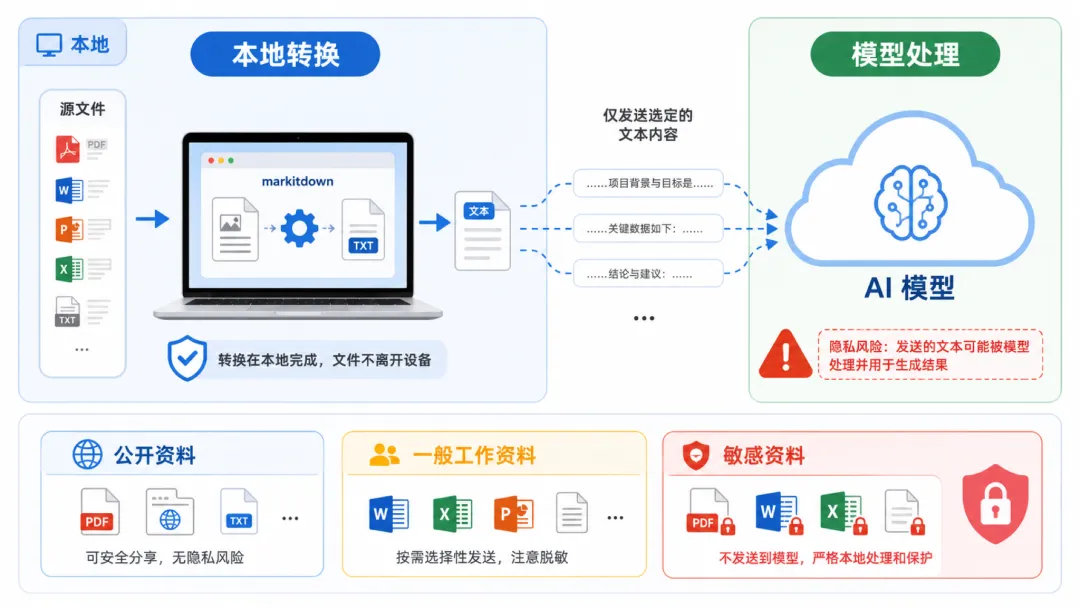
很多人最担心这个——“我把合同、报告喂进去,会不会泄露?”
说清楚:
- 转文本(markitdown)是在你电脑本地做的
,这一步不联网、不上传。 但 AI 理解内容时,相关文字会发给模型处理(这是所有 AI 工具的共性)。
所以:
一般工作资料、公开报告、学习材料 → 放心用 - 高度敏感
的(身份证、银行流水、未公开核心机密)→ 自己掂量
想最稳妥?用本地模型,数据完全不离开你的电脑。退一步,用 DeepSeek/GLM 等国产后端,数据至少不发往国外。
七、练手任务
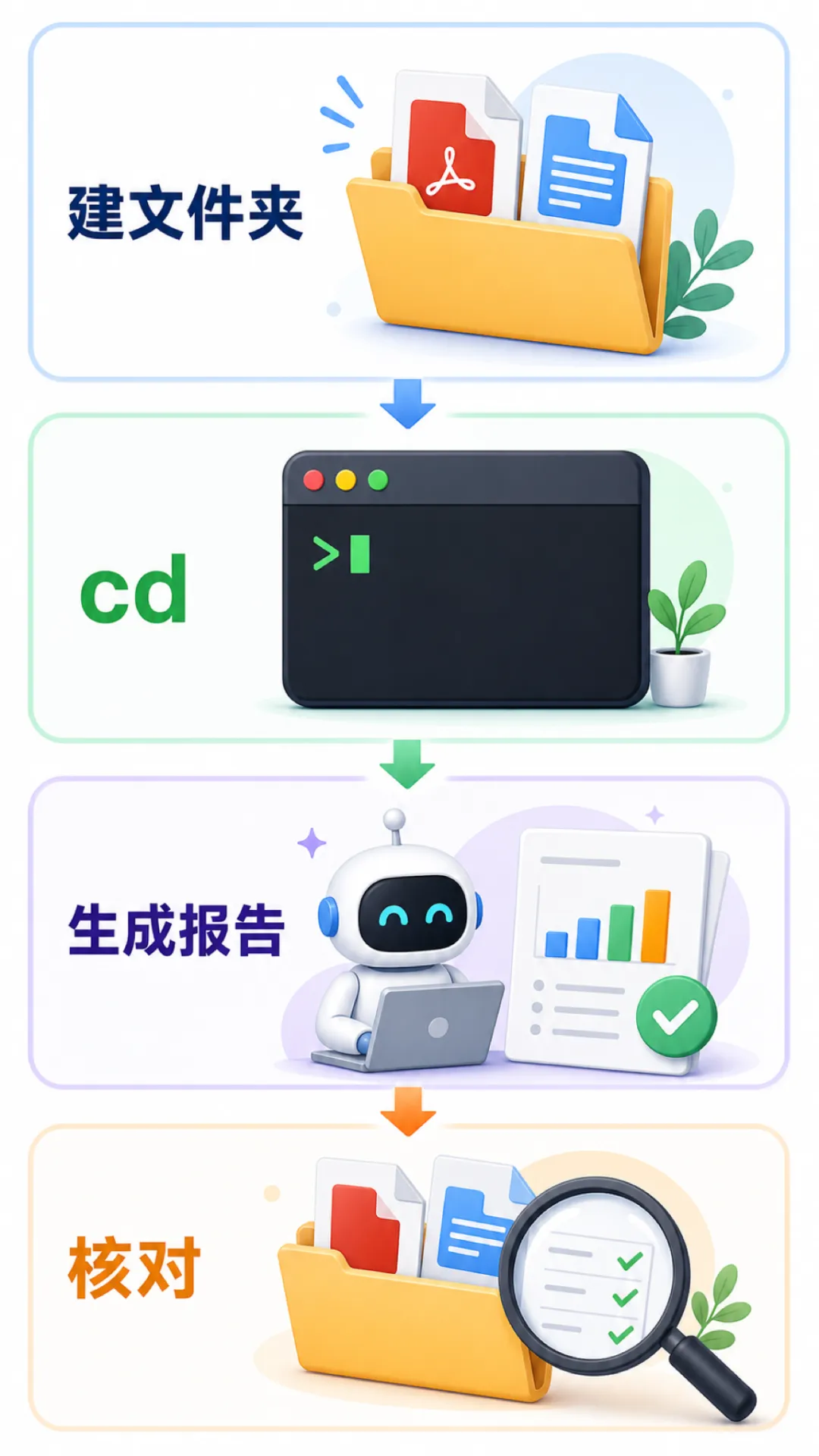
找一个你真实存着没空看的资料堆,今天就处理掉:
建个文件夹,把 PDF / Word 拖进去 cd 进去,claude 启动 让它"装 markitdown → 把文件转成 Markdown → 综合成报告" 回原文件核对关键数据
做完你会有种"积压清空"的爽感。
写在最后
资料整理是 Claude Code 最容易出效果的场景——因为读和提炼正是 AI 的强项,而这恰恰是最耗你时间的体力活。
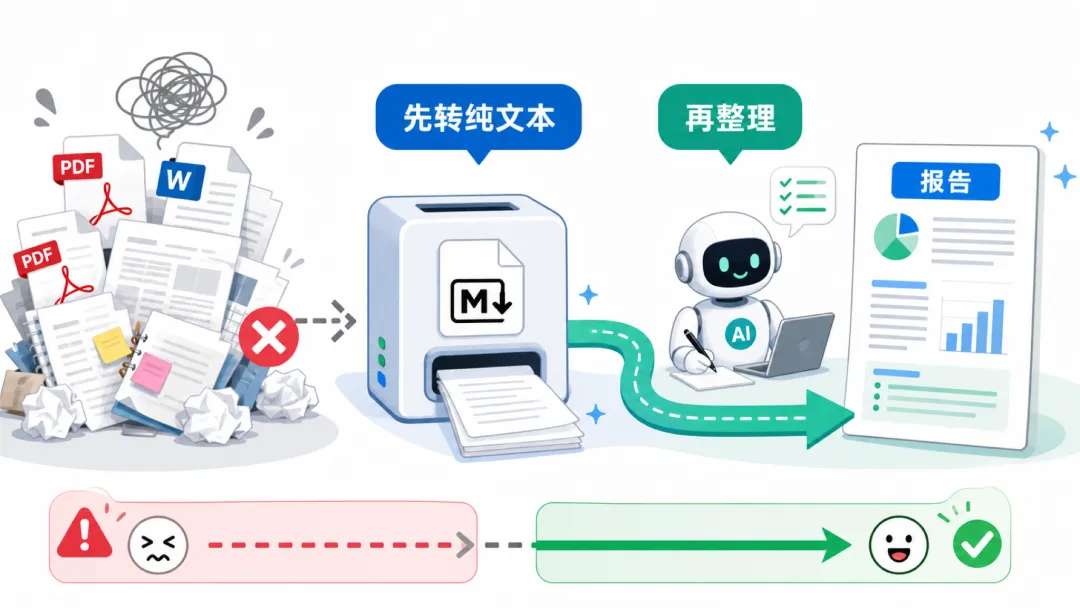
国产模型用户记住这条万能路线:
先转纯文本(markitdown),再让 AI 整理。
绕开了"国产模型读不了 PDF/Word"的坑,DeepSeek、GLM 都能顺畅干活。
下一篇 [[C05-写作伙伴]],换个场景——教你和它一起,从一句话大纲写出一篇完整文章。
[^1]: 来源:DeepSeek Anthropic 兼容 API 官方文档 https://api-docs.deepseek.com/guides/anthropic_api (Message Fields 兼容表明确标注 image、document 类型 “Not Supported”) [^2]: 来源:智谱 GLM 模型文档 https://docs.bigmodel.cn/ ——接入 Claude Code 常用的 GLM-4.6 为文本模型;视觉能力在独立的 GLM-4.6V 系列。 [^3]: 来源:Claude Code 源码 src/utils/pdfUtils.ts(isPDFSupported() 仅按模型名是否含 claude-3-haiku 判定,对国产模型一律放行,无法感知后端真实能力) [^4]: 来源:microsoft/markitdown https://github.com/microsoft/markitdown (MIT 开源,支持 PDF/Word/Excel/PPT/HTML/CSV 转 Markdown)
相关阅读
[[C03-第一次对话]] — 上一篇:怎么跟它说话 [[C05-写作伙伴]] — 下一篇:一起写文章 [[番外-国内网络与镜像完全指南]] — 国产模型怎么接入 [[README]] — 本系列完整目录
