 夜雨聆风
夜雨聆风哈喽,大家好,我是干货满满的晓技术老师。
一个多月没更新了,今天抽空给大家分享一款我最近使用的Ai工具,Z.ai。和豆包、deepseek相比,Z.ai更擅长的是长文本识别、整理和分析。
拿我最近的使用场景来说。
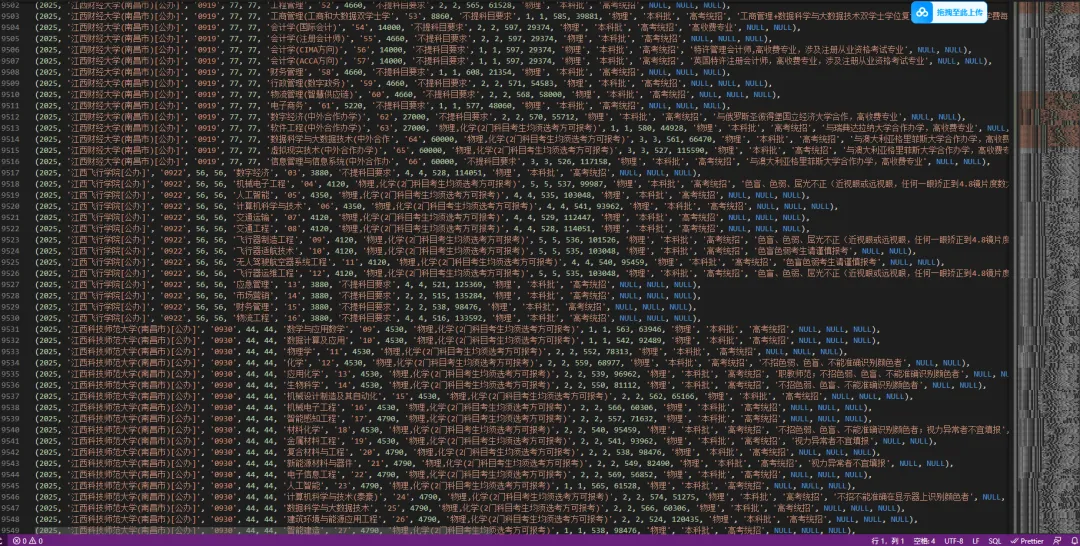
我找了2025年全国高校在河北省的招生计划(PDF版),以及各个高校在河北省的专业录取分数(PDF版);然后,让豆包、deepSeek、Z.ai同时提取2个PDF里面的内容,并按照招生批次、升学渠道进行分类、整理、合并,最终归纳为一个批量插入的sql语句。
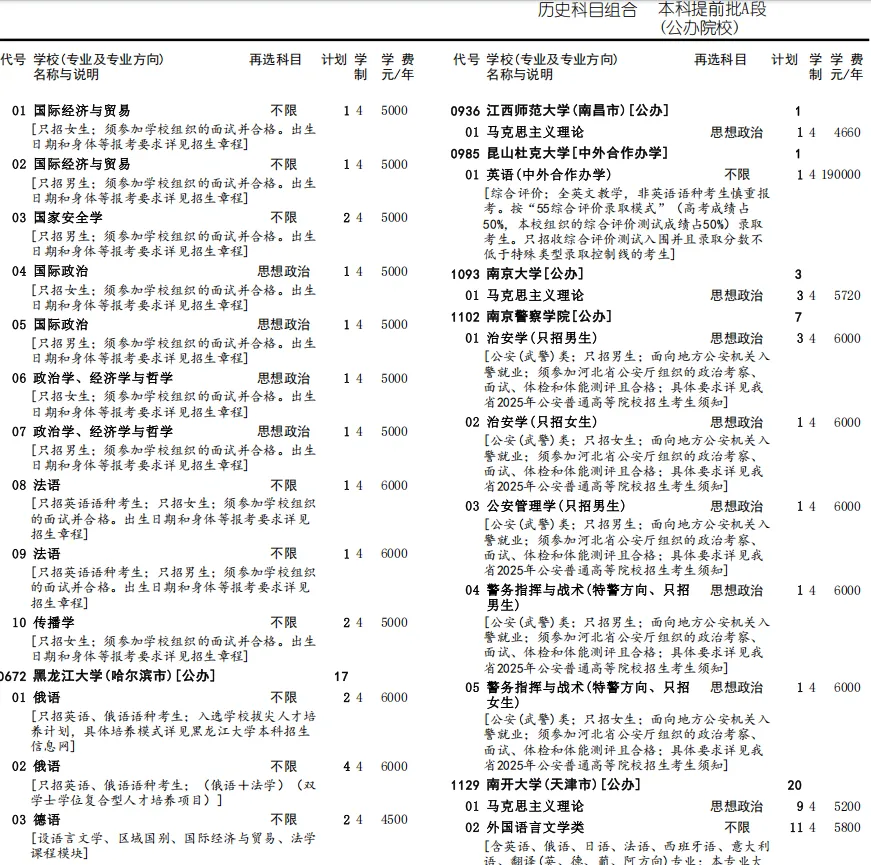
就是这样一个复杂且庞大的工程,豆包和deepSeek是直接拒绝工作的,或者只能识别前30%的内容;并且识别的数据有大量的幻读、错误;即使后期手动勘误,也需要耗费大量的精力。
总体给人的感觉就是,豆包和deepSeek就是一个半自动机器,生成的东西就是没有加工的原矿石。
但Z.ai就强的离谱,我投给它的PDF大概有1000页内容,文本长度应该是百万级别的。Z.ai不仅全部接收了任务,且是0丢失数据,跨文件间的文本对应、合并也是0失误。
更牛批的是,你完全不用考虑Z.ai能不能干好、能不能完成?它就像一个能力超强、又不需要频繁给情绪价值的高级牛马,只要提出问题和需求,Z.ai就能搞定。这一点,或许比你周围的同事更贴心。
其实,我在之前的文章里就给大家推荐过Z.ai。比如用它分析几万行数据的宋词全集,找出诗词中提及他人,或者诗词是送给其他诗人的,Z.ai会超快高质量的完成数据清洗和整理。
好了,写了这么多,其实我不想把这个工具分享出来的,生怕用户多了,Z.ai会收费,或者把蒸馏的模型给我们用;但是,谁让你们是我的铁铁呢,大家有福同享,一起牛逼!
