 夜雨聆风
夜雨聆风🚀 一句话总结:这是一个集成了 Zotero、Python 脚本、Claude Code 和国产大模型的本地化论文分析系统,能够将 PDF 文献自动转换为 Markdown 笔记,并通过 AI 进行深度分析和可视化,极大提升科研效率。
🗺️ 阅读指南
本教程面向没有编程基础的科研新手。建议按步骤顺序操作,不要跳步。每一步末尾都附有常见错误提示,遇到问题时可以直接对照排查。
整个系统搭建完成后,你可以做到:把一篇 PDF 论文丢给 AI,8 秒后拿到结构化的 Markdown 笔记;把 20 篇论文同时交给 AI,出门喝杯咖啡,回来直接看分析报告和可视化图谱。
🏗️ 系统架构与核心组件
这个系统由六个核心组件构成,它们协同工作形成一条完整的流水线:
组件之间的依赖关系:
Claudian 插件运行在 Obsidian 内部,不依赖 Claude Code,两者是独立的入口 Python 脚本需要提前配置好 MinerU API Token 才能运行 CC Switch 是 Claude Code 的配置辅助工具,两者配套使用
🌐 完整工作流程
PDF 文献 ↓Zotero 管理(Zutilo 复制路径) ↓Python 脚本调用 MinerU API 转换 ↓Markdown 笔记(存入 Obsidian) ↓Claudian 插件调用 AI 分析 ↓Canvas 可视化图谱输出🔧 安装与配置指南
第一步:基础环境搭建
1. 文献管理:安装 Zotero 与 Zutilo 插件
Zotero 官网:https://www.zotero.org Zutilo 插件:https://github.com/wshanks/Zutilo
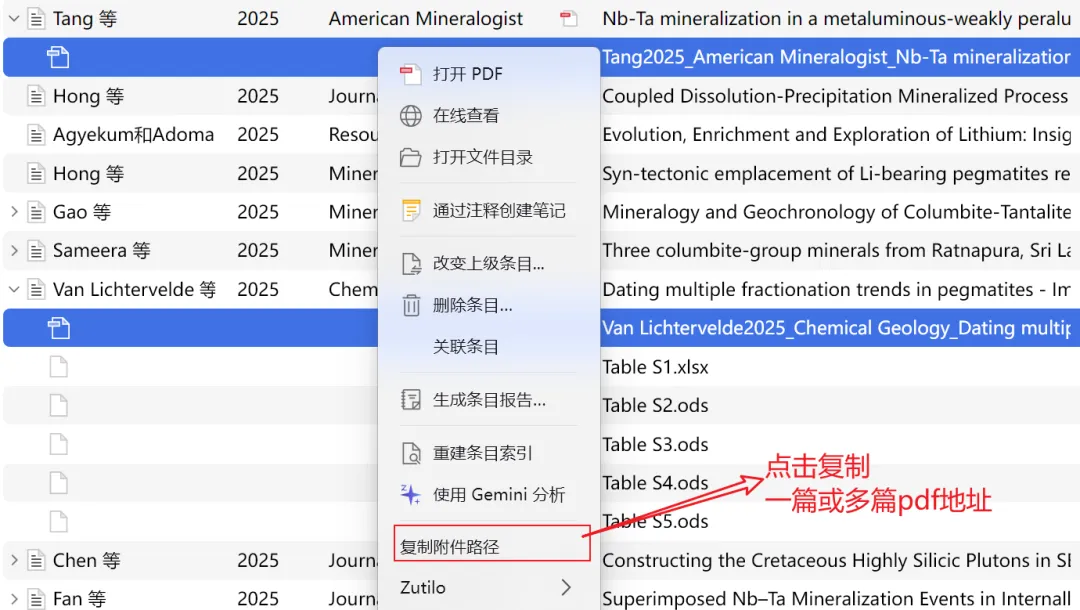
安装完成后,在 Zotero 中右键点击某篇或多篇文献的 PDF 附件,你会看到 Zutilo 新增的菜单项"复制附件路径"。这个路径就是后续 Python 脚本的输入来源。
2. 编程环境:安装 Python(推荐 Anaconda)
Anaconda 下载地址:https://www.anaconda.com/download
为什么用 Anaconda 而不是直接安装 Python?Anaconda 自带虚拟环境管理工具,可以为不同项目创建相互隔离的 Python 环境,避免不同项目之间的依赖冲突。本教程的脚本需要安装一些特定版本的库,放在独立环境里更安全。
安装完成后,打开"Anaconda Prompt"(Windows 开始菜单可以搜到),能看到命令行提示符前面有 (base) 字样,说明安装成功。
3. 笔记系统:安装 Obsidian
下载地址:https://obsidian.md/
Obsidian 本质上是一个基于本地 Markdown 文件的笔记软件,所有笔记都是普通的 .md 文件,存在你自己的电脑上。它的"双向链接"和"图谱视图"功能非常适合管理论文笔记之间的关联。
安装后,新建一个"库"(Vault),路径建议放在一个你熟悉的文件夹,比如 H:/ObsidianVaults/。后续所有 Markdown 笔记都会存入这里。
第二步:PDF 转 Markdown 脚本
获取脚本
GitHub 仓库:https://github.com/yaoqingluo/pdf2md 依赖的 API:MinerU 视觉大模型(https://mineru.net)
脚本有两个版本,两个都下载下来就行,后面根据需要选择:
| V1(纯文本版) | ||
| V4(全要素版) |
配置步骤
第一步:申请 MinerU API Token前往 https://mineru.net 注册账号,在控制台找到"API Token"并复制。MinerU 提供一定的免费额度,日常科研使用通常够用。
第二步:配置脚本下载脚本后,用文本编辑器打开(记事本即可),找到以下两处需要修改的地方:
# 修改为你的 MinerU API TokenAPI_TOKEN ="在这里粘贴你的Token"# 修改为你的 Obsidian 笔记文件夹路径(注意:Windows 路径用正斜杠 / 或双反斜杠 \\)OUTPUT_DIR ="H:/ObsidianVaults/文献笔记/"第三步:安装依赖库打开 Anaconda Prompt,依次运行:
conda create -n marker_env python=3.10conda activate marker_envpip install requests pathlib⚠️ 常见错误:运行脚本时提示"ModuleNotFoundError",说明依赖库没有安装在当前激活的环境里。检查命令行提示符前面是否显示
(marker_env),如果不是,先运行conda activate marker_env。
第三步:Claude Code 环境配置
Claude Code 是一个运行在命令行里的 AI 编程助手,本教程用它来执行本地脚本和 AI 交互。
1. 安装 Node.js
下载地址:https://nodejs.org/zh-cn 选择"LTS(长期支持)版本"下载安装,一路点"下一步"即可
安装完成后,打开命令提示符(Win + R,输入 cmd),运行:
node--version如果显示版本号(如 v20.11.0),说明安装成功。
2. 安装 Git(可选但推荐)
下载地址:https://git-scm.com/ 或在命令提示符中运行: winget install Git.Git
Git 是代码版本管理工具,安装后可以更方便地下载和更新 GitHub 上的项目。
3. 安装 Claude Code
在命令提示符中运行:
npminstall-g @anthropic-ai/claude-code-g 参数表示全局安装,安装后在任意目录都可以使用 claude 命令。
4. 解决登录卡住的问题
如果启动 Claude Code 后卡在登录引导界面,用文本编辑器打开(没有则新建)以下文件:
Windows 路径: C:\Users\你的用户名\.claude.json
在文件中写入:
{"hasCompletedOnboarding":true}保存后重新启动 Claude Code 即可跳过引导。
⚠️ 常见错误:提示"npm 不是内部或外部命令",说明 Node.js 没有正确添加到系统 PATH。重启电脑后再试;如果还不行,重新安装 Node.js 并勾选"Add to PATH"选项。
第四步:CC Switch 配置管理
CC Switch 是一个可视化的配置工具,用来管理 Claude Code 使用的 AI 模型和 API。
GitHub 项目:https://github.com/farion1231/cc-switch
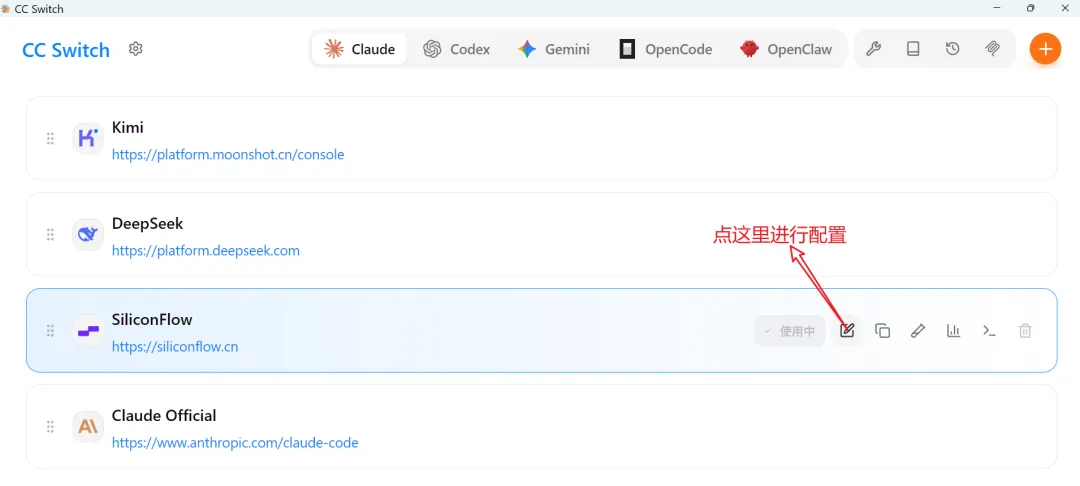
推荐配置(使用 Silicon Flow 的国产模型)
Silicon Flow 是一个国内 AI 模型服务商,集成了 DeepSeek、GLM 等主流国产模型,价格还行,网络稳定。
官网:https://cloud.siliconflow.cn 费用参考:充值 50 元加上系统赠送的代金券,正常科研使用可以用一个月左右
在 CC Switch 中配置如下(或直接编辑 ~/.claude.json):
{"alwaysThinkingEnabled":false,"autoUpdatesChannel":"latest","env":{"ANTHROPIC_AUTH_TOKEN":"你的 Silicon Flow API Key","ANTHROPIC_BASE_URL":"https://api.siliconflow.cn","ANTHROPIC_DEFAULT_HAIKU_MODEL":"Pro/deepseek-ai/DeepSeek-V3.2","ANTHROPIC_DEFAULT_OPUS_MODEL":"Pro/deepseek-ai/DeepSeek-V3.2","ANTHROPIC_DEFAULT_SONNET_MODEL":"Pro/deepseek-ai/DeepSeek-V3.2","ANTHROPIC_MODEL":"Pro/deepseek-ai/DeepSeek-V3.2","CLAUDE_THINKING_BUDGET_TOKENS":"0"}}注意两处关键配置,否则 Claude Code 会卡顿:
第一行: "alwaysThinkingEnabled": false最后一行: "CLAUDE_THINKING_BUDGET_TOKENS": "0"
⚠️ 常见错误:API 连接失败,提示 401 或 403 错误。检查
ANTHROPIC_AUTH_TOKEN是否填写了正确的 Silicon Flow API Key(不是 Anthropic 官方的 Key)。
第五步:Obsidian 插件配置
安装 Claudian 插件
Claudian 是一个 Obsidian 插件,让你在笔记界面内直接调用 AI,并支持自定义"技能"(Skills)来扩展功能。
GitHub 项目:https://github.com/YishenTu/claudian
安装步骤(手动安装):
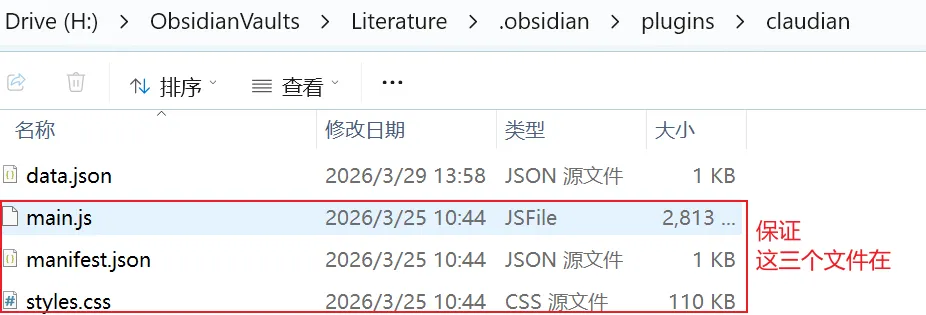
前往 GitHub 下载最新版本的三个文件: main.js、manifest.json、styles.css打开 Obsidian 库所在的文件夹,进入 .obsidian/plugins/目录在 plugins文件夹内新建一个名为claudian的子文件夹将三个文件复制进去 在 Obsidian 设置 → 第三方插件 → 找到 Claudian,点击启用
配置 Claudian
进入 Obsidian 设置 → Claudian,填写:
API Key:你的 Silicon Flow API Key Base URL: https://api.siliconflow.cn/v1(注意末尾有/v1)模型选择: Pro/zai-org/GLM-4.7或其他你在 Silicon Flow 上可用的模型
安装 Skills(可选但强烈推荐)
Skills 是可以让 Claudian 调用的预定义操作集合,相当于给 AI 配备工具箱。
Obsidian 官方 Skills:https://github.com/kepano/obsidian-skills 可视化 Skills(生成 Canvas 图):https://github.com/axtonliu/axton-obsidian-visual-skills
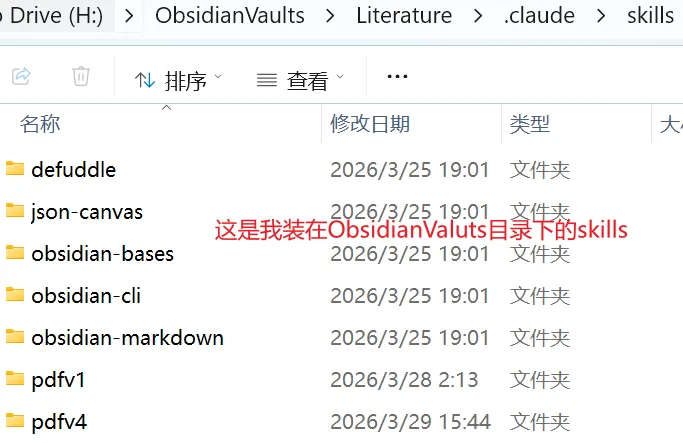
下载后,将 skills 文件放入你的 Obsidian 库的 .claude/skills/ 文件夹中或者放在你的用户名/.claude/skills/ 文件夹(claude code的安装位置)中
⚠️ 常见错误:Claudian 提示"技能未找到"。检查 Skills 文件是否放在了正确路径(
.claude/skills/,注意开头有点号,是隐藏文件夹,Windows 需要开启"显示隐藏项目"才能看到)。
第六步:创建自定义 Skills(PDF 转换技能)
为了让 Claudian 能够直接调用 PDF 转 Markdown 脚本,需要创建两个自定义 Skill 文件。
Skill 的工作原理: 你在 Claudian 中输入 /pdfv1 路径,Claudian 会读取对应的 Skill 文件,将 {{inputPath}} 替换为你输入的路径,然后执行对应的命令。
在 .claude/skills/ 文件夹内,分别创建以下两个文件:
文件一:pdfv1.md(纯文本转换)
!bash "C:/Users/你的用户名/anaconda3/envs/marker_env/python.exe" -u "H:/ObsidianVaults/Scripts/pdf_to_obsidianV1.py" "{{inputPath}}"文件二:pdfv4.md(全要素转换)
!bash cmd /c "chcp 65001 >nul && \"C:\\Users\\你的用户名\\anaconda3\\envs\\marker_env\\python.exe\" -X utf8 -u \"H:\\ObsidianVaults\\Scripts\\pdf_to_obsidianV4.py\" \"{{inputPath}}\""说明:
将 你的用户名替换为你 Windows 的实际用户名(可以在C:\Users\下看到)将 H:/ObsidianVaults/Scripts/替换为你实际存放脚本的路径V4 版本的路径用的是双反斜杠 \\,这是 Windows 命令行的转义写法,不要改成单斜杠Skill 文件内容里写的 {{inputPath}}是一个占位符,Claudian 会自动把它替换成你输入的路径,你不需要手动修改
⚠️ 常见错误:运行技能后提示"系统找不到指定路径"。用文件管理器逐级检查路径是否真实存在,特别注意用户名和文件夹名称的大小写。
🎬 实战演示:地质学论文分析案例
完成以上六步配置后,下面演示完整的使用流程。
第一步:从 Zotero 复制 PDF 路径
在 Zotero 中,右键点击论文的 PDF 附件 → Zutilo → 复制附件路径。你会得到类似这样的路径:
E:\Zoterolib\storage\Y33IDUMB\Palinkaš2014_American Mineralogist_The role of magmatic and h.pdf第二步:在 Claudian 中运行转换命令
在 Obsidian 的 Claudian 输入框中,输入:
/pdfv1 E:\Zoterolib\storage\Y33IDUMB\Palinkaš2014_American Mineralogist_The role of magmatic and h.pdf耗时约 8 秒,输出纯文本 Markdown 笔记,自动保存到你配置的 Obsidian 笔记文件夹。
如果需要保留图表,改用 V4:
/pdfv4 E:\Zoterolib\storage\Y33IDUMB\Palinkaš2014_American Mineralogist_The role of magmatic and h.pdf耗时约 14 秒,输出包含图片和表格的完整 Markdown 笔记。

第三步:让 AI 深度分析并生成 Canvas 图
转换完成后,在 Claudian 中输入:
@文献笔记/Palinkaš2014_American Mineralogist_The role of magmatic and h.md请详细分析这篇论文讲了什么,并调用 obsidian-canvas-creator 技能生成结构图其中 @文献笔记/... 是 Claudian 的文件引用语法:@ 符号后面跟 Obsidian 库内的文件路径,AI 会自动读取该文件的内容进行分析。
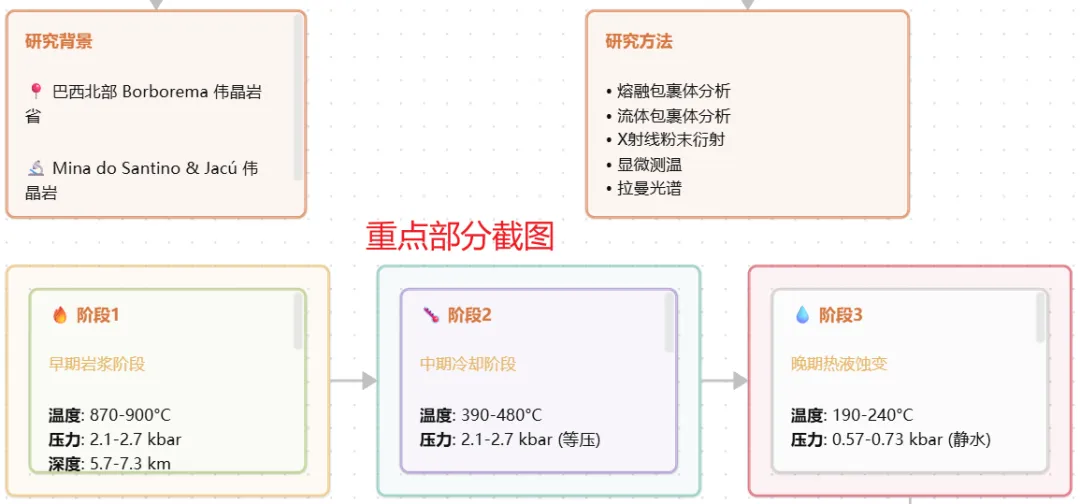
进阶用法:多文献批量分析
你可以在一条消息里同时处理多篇论文,转换和分析一次完成:
/pdfv1 E:\Zoterolib\storage\R7HR7QUF\Van Lichtervelde2025_Chemical Geology_Dating multiple fractionat.pdfE:\Zoterolib\storage\LE3F83JW\Tang2025_American Mineralogist_Nb-Ta mineralization in a.pdf请执行上面的命令将这几篇论文转为 md 文档后,告诉我这几篇论文主要讲了什么示例分析结果

🌟 核心优势
本地化处理:笔记和知识库完全本地存储,MinerU 转换过程通过加密 API 传输,转换完成后文件不留存于服务器 自动化工作流:从 PDF 到分析报告,一条命令完成 知识积累:每篇论文转换后形成永久 Markdown 笔记,构建属于你自己的知识库 批量处理:可一次性分析 20+ 篇文献,自动生成对比综述 可视化输出:自动生成 Canvas 思维导图、知识图谱等可视化结果
🔧 故障排除汇总
alwaysThinkingEnabled | "alwaysThinkingEnabled": false 和 "CLAUDE_THINKING_BUDGET_TOKENS": "0" | |
.claude/skills/ 下,Windows 需显示隐藏文件夹 | ||
chcp 65001 强制 UTF-8,确认完整复制了命令 |
🎉 结语
到这里,整条工作流已经打通:文献获取 → 本地结构化 → AI 批量分析与输出。
看起来有点"折腾",但本质上是把零散的论文,变成一个可以不断积累、反复调用的知识体系。相比在网页端一次次上传 PDF、一次次重新分析,本地化之后,AI 面对的是你整个数据库,而不只是单篇文献。
这意味着什么?你可以一次丢给它 10 篇、20 篇论文,让它去总结、对比、帮你搭综述框架,而你可以去喝杯咖啡、发会呆,甚至睡一觉,回来直接看结果。
如果喜欢,请点个关注!
