 夜雨聆风
夜雨聆风本文是「AI 基础设施科普」系列第 13 篇。上一篇我们聊了多模态——怎么让 AI “看得见、听得懂”。今天往更底层走一步:AI 怎么才能"懂意思"?为什么搜索"汽车"能找到"轿车",搜索"开心"能匹配到"快乐"?答案藏在两个关键词里:嵌入(Embedding)和向量数据库。
你在搜索引擎输入"怎么减肥",它能给你返回一篇标题叫"科学减脂指南"的文章——这两个词一个字都不一样,但搜索引擎知道它们说的是同一件事。怎么做到的?靠的不是关键词匹配,而是"懂意思"。
一、核心概念:什么是"嵌入"?
1.1 从生活类比开始
想象你在一个巨大的图书馆里,所有书按"内容相似度"排列——讲烹饪的书挨着讲烘焙的,讲物理的书挨着讲数学的。每本书在这个空间里有一个"坐标",内容越像的书,坐标越近。
嵌入(Embedding)做的事,就是把任何一段文本、一张图片、一段音频,变成这样一个"坐标"——一个数字数组。
比如:
"猫"和"狗"的向量很接近,因为它们语义相似;"汽车"的向量则完全不同,因为它属于不同类别。
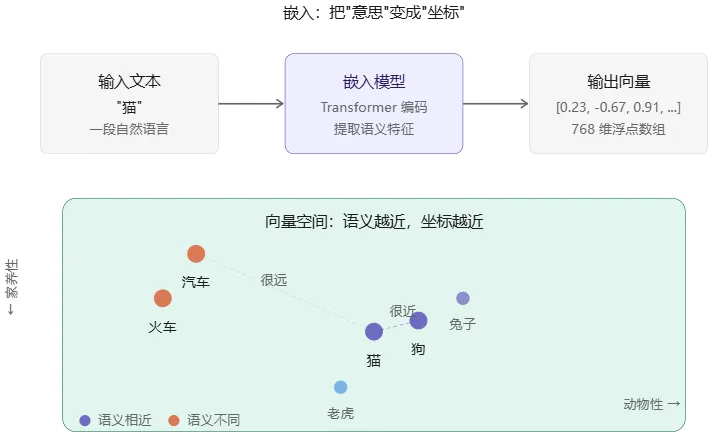
1.2 关键术语速解
| 嵌入(Embedding) | |
| 向量(Vector) | |
| 维度 | |
| 相似度 | |
| 余弦相似度 |
1.3 为什么不用关键词匹配?
关键词搜索找的是"字面一样",语义搜索找的是"意思一样":
核心区别:关键词是"字面匹配",语义搜索是"理解意图"。而语义搜索的底层,就是嵌入 + 向量相似度。
二、嵌入是怎么工作的?
2.1 从文本到向量的三步
原始文本 → 分词(Tokenization) → 编码(Encoding) → 向量嵌入(Vector Embedding)
分词:把"我 喜欢 猫"拆成 [“我”, “喜欢”, “猫”] 三个 Token 编码:通过 Transformer 神经网络提取语义特征 嵌入:输出固定长度的稠密向量,比如 768 个浮点数
2.2 "向量空间"的直觉
想象一个三维空间:
X 轴 = “动物性”(猫=0.9,汽车=-0.5) Y 轴 = “体积”(大象=0.95,蚂蚁=-0.9) Z 轴 = “家养性”(猫=0.8,老虎=-0.6)
实际嵌入维度是 768~3072 维,远超三维,但原理相同——每个维度捕捉一种语义特征,维度越高,表达越精细。
2.3 一个有趣的能力:向量算术
嵌入向量有一个神奇的特性——可以用数学运算表达语义关系:
"国王" - "男人" + "女人" ≈ "女王"
"巴黎" - "法国" + "中国" ≈ "北京"
"走路" - "慢" + "快" ≈ "跑步"
这不是魔法,而是嵌入在训练时自然学到了"性别差异"“国都关系”"速度差异"等语义维度。
三、向量数据库:存向量的"专业仓库"
有了嵌入模型能把文字变成向量,那这些向量存在哪里?怎么高效搜索?
3.1 为什么不用普通数据库?
打个比方:普通数据库是"按索引查字典",向量数据库是"在茫茫人海中找最像你的人"。
3.2 向量搜索的核心算法:HNSW
最主流的向量索引算法叫 HNSW(Hierarchical Navigable Small World),核心思路:
把所有向量组织成一个多层"跳表" 搜索时从最稀疏的顶层开始,快速定位大致区域 逐层往下细化,最终找到最近的几个向量 结果:百万级向量中搜索,只需要几毫秒
代价:HNSW 返回的是"近似最近邻",不是绝对最近——但在实际应用中,速度换精度的权衡完全值得。
3.3 2026 主流向量数据库横评
| Qdrant | |||
| Pinecone | |||
| Milvus | |||
| Weaviate | |||
| Chroma | |||
| pgvector |
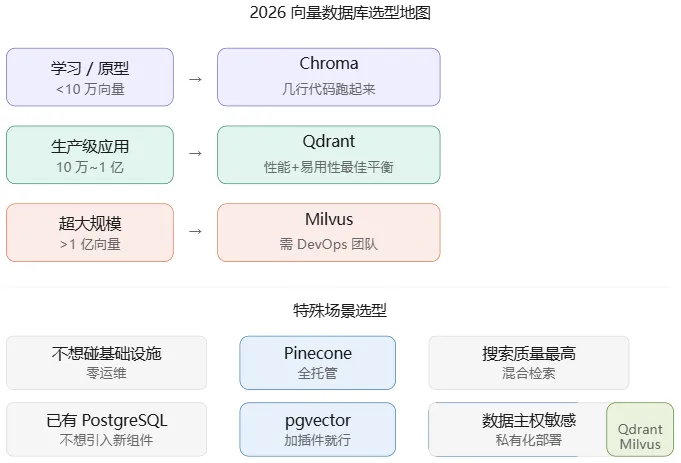
3.4 选型一句话总结
刚入门学习 → Chroma,几行代码跑起来 做个小产品上线 → Pinecone,不用管服务器 认真做生产级应用 → Qdrant,性价比最高 数据量巨大(亿级) → Milvus,但要有运维团队 搜索质量要求极高 → Weaviate,混合搜索效果最好 已有 PostgreSQL → 直接加 pgvector 插件,最省事
四、2026 嵌入模型谁最强?
嵌入模型是整个链条的起点——模型质量直接决定搜索精度。2026 年的格局已经大变。
4.1 MTEB 排行榜 Top 10
MTEB(Massive Text Embedding Benchmark)是最权威的嵌入模型评测,涵盖 8 大类 56 项任务。
关键发现:OpenAI 的嵌入模型自 2024 年 1 月后未更新,已被多个新模型超越。2026 年,开源模型在 MTEB 排行上已经全面压制闭源 API。
4.2 分场景推荐
| 中文场景 | ||
| 中文轻量部署 | ||
| 多语言 | ||
| 代码检索 | ||
| 多模态 | ||
| 私有化部署 | ||
| 快速接入 API |
4.3 一个容易被忽略的参数:上下文长度
上下文长度决定了"一次能嵌入多长的文本":
实操建议:大多数场景 8K 够用。如果你的文档经常超过 5000 字,优先选 Qwen3(32K)或 Cohere(128K),避免切片导致语义断裂。
五、完整链路:从文档到答案
把嵌入模型和向量数据库串起来,就是 RAG 的核心链路(第 6 篇讲过 RAG,这次从底层机制看):
写入阶段:
文档 → 切片(Chunking) → 嵌入模型 → 向量 → 存入向量数据库
查询阶段:
用户问题 → 嵌入模型 → 查询向量 → 向量数据库搜索 Top-K → 返回最相关文档片段 → 喂给大模型生成答案
5.1 切片(Chunking)是个技术活
文档不能整篇丢给嵌入模型(太长会截断),必须切成小段:
实操建议:先用固定长度 + 重叠切分跑起来,效果不好再升级到语义切分。
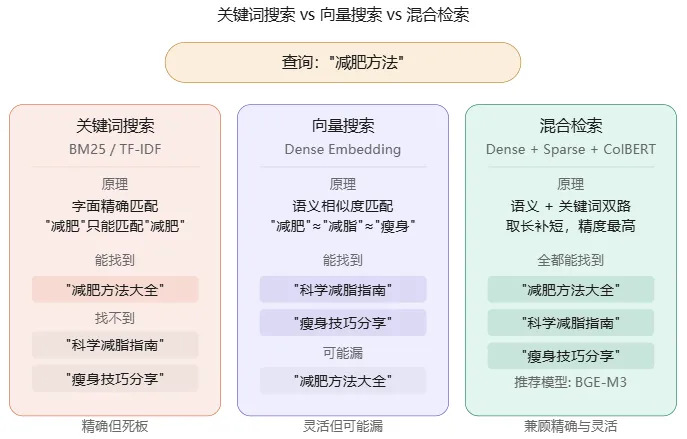
5.2 混合检索:精度再上一层
纯向量搜索有时会"懂意思但漏细节",纯关键词搜索会"精准但不灵活"。混合检索把两者结合:
稠密向量(Dense):捕捉语义相似度,“减肥"匹配"减脂” 稀疏向量(Sparse):捕捉关键词精确匹配,“BGE-M3"只匹配"BGE-M3” 多向量(Multi-vector / ColBERT):每个 Token 一个向量,精细到词级别重排
BGE-M3 是目前唯一同时支持三种检索方式的开源模型,这也是它在中文 RAG 场景广受欢迎的核心原因。
六、常见误区与避坑
误区一:“向量维度越高越好”
反面:768 维够用的场景上了 3072 维,存储翻 4 倍,搜索变慢,精度反而可能下降(维度灾难)。
改成:768~1024 维已经能满足绝大多数需求。只有大规模、高精度场景才需要更高维度。
误区二:“嵌入模型随便选一个就行”
反面:用英文优化的模型做中文搜索,结果"汽车"和"汽车人"傻傻分不清。
改成:中文场景务必选 Qwen3-Embedding 或 BGE-M3,它们对中文语义理解经过专门优化。
误区三:“有了向量数据库就不需要普通数据库了”
反面:把结构化数据(用户信息、订单记录)也存进向量数据库,查询复杂又低效。
改成:向量数据库存向量、做语义搜索;结构化数据留在 MySQL / PostgreSQL。两者搭配,用 ID 互相关联。
误区四:“相似度高就一定相关”
反面:搜索"苹果股价",返回了"苹果的营养价值"——相似度 0.87,但完全不相关。
改成:高相似度 ≠ 高相关性。重要场景加 Reranker(重排序模型)做二次筛选,或用混合检索补上关键词精确匹配。
七、实操建议:从 0 到 1 搭建语义搜索
如果你第一次接触,建议按这个路径走:
第一步:选嵌入模型
中文 → BGE-M3(开源,支持混合检索) 英文 / 快速接入 → OpenAI text-embedding-3-small
第二步:选向量数据库
学习阶段 → Chroma(pip install 就能用) 已有 PostgreSQL → pgvector(加个插件就完事)
第三步:核心代码(伪代码)
# 1. 嵌入文档
vectors = embedding_model.encode(documents)
# 2. 存入向量数据库
vector_db.upsert(ids, vectors, metadata)
# 3. 语义搜索
query_vector = embedding_model.encode("用户的问题")
results = vector_db.search(query_vector, top_k=5)
# 4. 把结果喂给大模型
answer = llm.generate(question, context=results)
第四步:优化
效果不好 → 换更好的嵌入模型 搜索太慢 → 加 HNSW 索引、降维度 精度不够 → 加 Reranker 或切到混合检索
八、2026 年行业趋势
| 开源碾压闭源 | |
| 多模态嵌入 | |
| 超长上下文 | |
| 混合检索成标配 | |
| pgvector 崛起 |
小结
| 嵌入 | |
| 向量 | |
| 向量数据库 | |
| 余弦相似度 | |
| 混合检索 | |
| HNSW |
记住这个链路:文档 → 切片 → 嵌入 → 向量数据库 → 语义搜索 → 大模型生成答案。这就是 RAG 的底层基础设施。
下一篇我们聊另一个底层话题:模型量化与推理加速——AI 怎么才能跑得又快又省?
本文是「AI 基础设施科普」系列第 13 篇。关注获取更多 AI 硬核科普。
系列传送门
第1期:AI 时代的「插件革命」—— Skills 全解析 第2期:AI 的「记忆」是怎么工作的?——Memory 机制全解析 第3期:同一个问题,为什么 AI 每次回答都不一样?——Prompt 工程入门 第4期:AI 聊着聊着就"变笨"了?——上下文窗口深度解析 第5期:不只是"聊天机器人"——AI Agent 到底是什么? 第6期:AI 怎么才能不瞎编?——RAG 检索增强生成全解析 第7期:AI 怎么才能"动手干活"?——工具调用(Tool Use)全解析 第8期:AI 的"万能插座"——MCP 协议全解析 第9期:AI 怎么才能变成"你的人"?——模型微调(Fine-tuning)全解析 第10期:AI 在"想什么"?——思维链与推理模型全解析 第11期:AI 为什么会"变坏"?——AI 安全与对齐全解析 第12期:AI 怎么才能"看得见、听得懂"?——多模态全解析
