 夜雨聆风
夜雨聆风
我做数据分析已经很多年了,SQL是我常用的工具。在我发现我可以用AI去写SQL之后,我着实兴奋了一段时间。最初的感觉,是它完全可以帮我偷懒了,我似乎不需要再动脑子,直接告诉它我想要查询什么、分析什么,它好像就能给我SQL语句。不过,在一段时间之后,我也发现这并不像一开始看起来那么简单美好。
经过了大概一年多跟AI的“拉扯”,我慢慢开始理解应该如何用AI去折腾我的SQL,让它能够真正帮我提高效率,又不会给我添乱。
这篇文章,是我的相关总结。

第一次翻车
我最初用AI处理SQL,是在备份我的网站,以及在增加我的网站安全性能的时候,按照ChatGPT的要求去处理。基本上没太大的问题。
但第一次用它做严肃的数据分析,就翻车了。
大概在去年春天的时候,我想要看一个用户回购率的数据。
我心想,这么简单的一个任务,我没有必要再自己写SQL了,交给AI吧。于是我在对话框里输入:帮我写一个查询,计算过去90天的用户回购率,按首次购买月份分组。
不到十秒钟,AI给了我一整段SQL:有CTE,有日期过滤,有GROUP BY,格式整齐,注释清楚,看起来非常像那么回事。我扫了一眼,觉得没问题,把它拷贝在执行界面直接跑了,但我很快就发现事情不对:为什么这个数字和上个季度的表现差了将近30%?
我心头一紧,这错得有点离谱呀。于是我赶紧检查,花了差不多半小时才定位到问题。确实是我的疏忽,AI默认用了 created_at 当作购买时间,但我们数据库里真正代表支付完成的字段是 paid_at。更麻烦的是,我们的 user_id 在历史数据迁移中有遗留问题,早期同一个真实用户可能会对应多个ID。AI不可能去查询一个它并不知道的数据表,然后去帮我打通user ID,它只是按最常见的写法猜了一个"看起来合理"的版本。
所以,SQL在运行的时候没有报错,但结论是错误的。
这一次让我意识到,SQL可以帮你做一些事情,但是在真正的作业环境中,它很容易出错。这种错误不是语法错误,而是藏在业务假设里的错误,也是藏在database的上下文中的错误。但这种错误更加致命,也更加麻烦,它会让你拿到一个似是而非的结论,并可能让你之后的分析和数据应用一塌糊涂。

AI为什么很难"直接帮你写SQL"
这次经历让我意识到,放手让AI去写SQL是不靠谱的,甚至所有的vibe coding其实都不可靠,不能直接完全放手。我们自己动手做SQL更可靠,并不是因为我们编程能力更强,而是我们能够同时对齐四个事情:表结构、业务口径、数据的状况(有哪些脏问题或历史遗留),以及具体要回答的业务问题。
但是,如果不提供大量的上下文信息,大模型就只能大致处理最后一件事情,而前三件事情则基本由它自己按照概率进行猜测。
所以,结果就是,它要么不断报错,要么就是虽然能跑,但是会给你很多莫名其妙的错误。这些错误例如下面的这些情况:
日期函数用错数据库方言;
NULL 值没处理好;
JOIN 之后数据被放大;
聚合层级不一致;
或者性能烂得一塌糊涂。
还有一个问题相当棘手,那就是复杂的查询呗迭代几轮之后,AI会忘掉前面的操作。当你不断让它改CTE、补过滤条件、调JOIN逻辑,到了第三轮第四轮,它经常会忘掉前面你确认过的某个细节,重新引入矛盾的写法。就算你不断提醒它,它仍然显得相当糊涂。

AI能帮我了,但跟我最开始想的不一样
AI不应该是主角,但它可以做一个非常棒的僚机。不是让它替我写,而是让它负责整个工作流里那些枯燥、机械、费时间,但又不需要我亲自死磕的部分。
我开始让它做如下的事情:
最常用的,是让AI审查我已经写好的查询。 这种方法尤其对于那些复杂的查询特别有用。AI虽然自己写SQL不怎么行,但是让它来挑错确实是个好手。虽然它有的时候认真的有点过头,但确实能发现一些我容易忽视的问题。比如有几次它帮我找到了不必要的重复扫描,或者发现某个子查询完全可以合并掉,这种优化自己写的时候不一定第一眼能想到。
结果不对的时候,AI是非常好的调试搭档。它不一定能每次都帮我直接定位到问题,但是会不断给我思路,告诉我如何排除各种可能性。这对于我这种不做专门SQL开发的数据分析师,非常有用。
然后,那些枯燥的需要大量阅读的体力活,让AI帮我先阅读再总结,能极大节省我的时间和精力。例如,那些三百行、五六个CTE、几乎没注释的历史SQL。最麻烦的不是修改,而是一开始根本不知道它在算什么。我现在的做法是先丢给AI,让它告诉我每个CTE在做什么、最终指标从哪些表汇总、哪些过滤条件最关键,然后自己再对照着读。它的理解不一定100%准确,但能让我从"完全陌生"快速进入"知道该重点看哪几块"的状态,省掉很多定向阅读的时间。
最后,AI也可以帮我把查询结果翻译成业务语言。SQL的输出从来不是最终交付物,真正的交付物是把数字解释给不看SQL的人听。我自己有个坏习惯,一解释数据就总想把技术的上下文都交代清楚,但这种方法虽然严谨,但常常会让业务同事听的云山雾绕。现在我会把结果和初步观察一起贴给AI,让它帮我提炼三条核心发现,压缩成管理层能看懂的摘要。这个习惯直接改善了我写周报的效率。

AI开始也能写SQL了,不过需要调教
让AI一直当僚机还是让我有些不甘心。于是我尝试重新让它编写复杂的SQL。不过,这一次,我需要先手动帮它解决那三个它无法自动了解的信息:表结构、业务口径、数据的状况(有哪些脏问题或历史遗留)。
我会先让AI在生成代码之前,列出它需要确认的事情:涉及哪些表、关键字段的定义是什么、哪些业务口径需要我确认、结果可能被哪些因素影响。
如果用的是能读取项目文件的工具,比如Cursor、GitHub Copilot、Claude Code,情况会好很多。这些工具可以直接读取migration文件、schema定义、历史SQL脚本,也就是说AI不再是凭经验猜"你可能有个created_at字段",而是真的能看到你的表里有哪些字段、它们怎么关联。
这一点对有工程背景的人会更明显。但即便只是普通BA,如果能在问问题之前,把相关表结构、关键字段说明、几条样本数据整理给AI,准确率也会高很多。
核心逻辑就一句话:你给AI的上下文越完整,它就越少需要猜,写出来的SQL就越可靠。
当然,使用读取项目文件的工具,我并不想强烈推荐,因为不同的公司对数据库的安全管理的要求会很不相同,一定要务必确保符合公司安全要求再使用。

我现在比较稳定的工作流
大概分六步:
先自己想清楚业务问题。 我要验证什么,最终需要看到什么结果,哪些业务规则绝对不能错。这个阶段想不清楚,AI只会更快地产生垃圾代码。
给AI足够的上下文。 涉及哪些表、关键字段是什么、已知的业务口径、数据库类型。BigQuery和MySQL的语法差别很大,这一句话能省掉很多来回。
让AI先给结构骨架,不要直接要完整版。 我一般让它先给CTE结构和JOIN思路,自己确认方向对了再让它补完整。
自己逐行核对业务假设。 重点检查时间字段、去重逻辑、JOIN关系、边界过滤,以及AI有没有擅自编造字段。
跑完之后让AI再做一轮审查。 优化性能、排查异常、重构可读性,这一步通常比第一轮生成更有价值。
用AI帮我整理输出。 把数字翻译成业务摘要、核心发现、后续建议。

最后,贴出来我常用的一些让AI处理SQL的Prompt模板
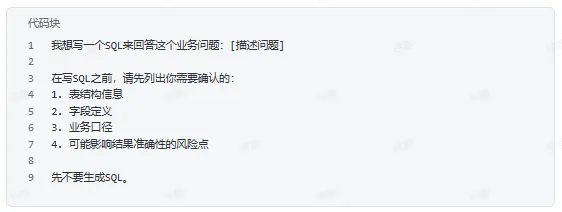
一、先澄清需求,不要急着生成
生成前先确认
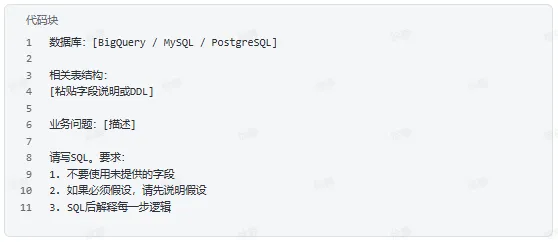
二、生成第一版SQL
基于Schema生成
先给结构骨架
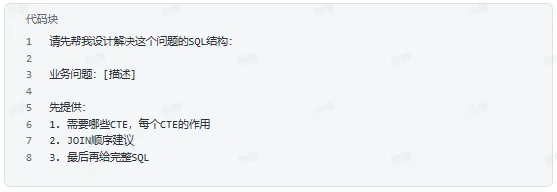
三、写完之后审查
优化现有查询
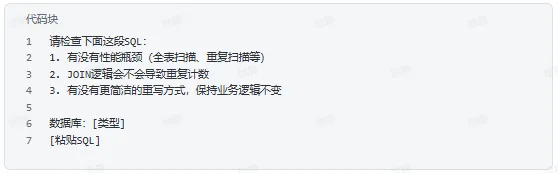
检查是否编造字段
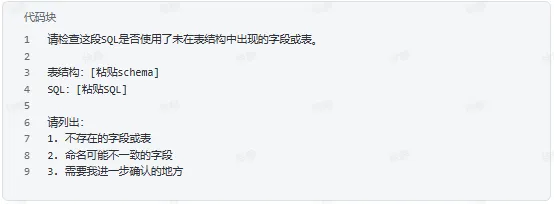
检查JOIN放大风险

四、结果不对时调试
列出可能原因
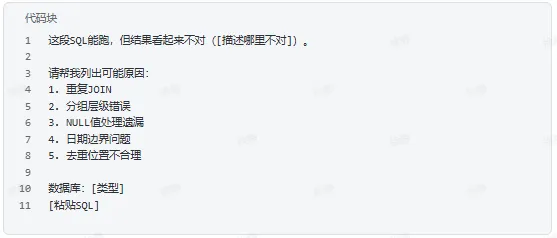
给排查计划,不要直接乱改

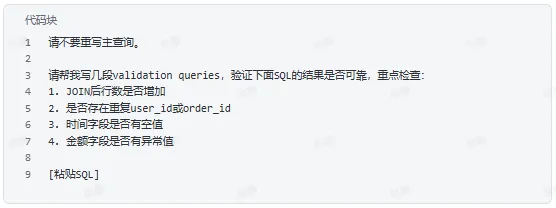
生成验证查询
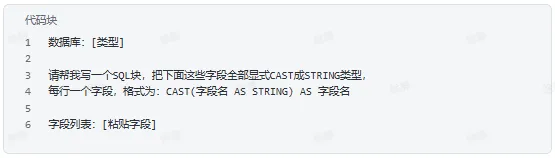
五、处理机械性的重复工作
批量生成重复代码
SQL方言转换
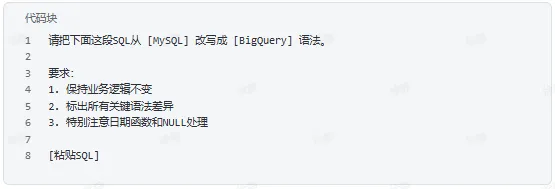
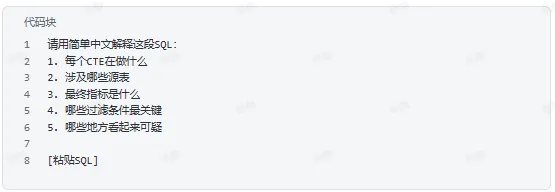
六、读懂历史SQL
解释复杂查询
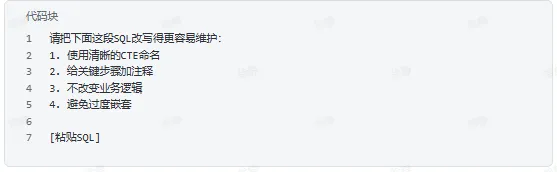
重写成可维护版本
七、结果出来后的分析表达
翻译成业务语言
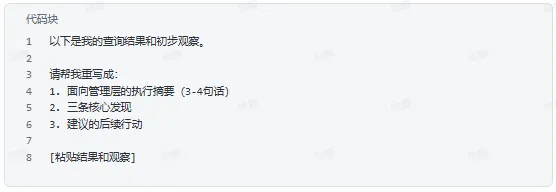
从结果里找异常和洞察
-宋星大课堂-
课程详情扫描二维码,备注“宋星大课堂”咨询

-加入知识星球-
扫码加入,收获数据做营销运营的干货精华
-加入读者群-
添加我的个人微信,备注“读者群”,并自我介绍

