 夜雨聆风
夜雨聆风文章前瞻:优质数据集与检测系统精选
点击链接:更多数据集与系统目录清单
点击公众号底部菜单栏或回复“数据集”“项目代码”获取~
一、农业作物分类检测数据集介绍
【数据集】yolo农作物分类检测数据集 10712 张,目标检测,包含YOLO/VOC格式标注,训练、验证、测试集已划分。
数据集中标签包含5种分类:names = ['panicle', 'soybean', 'wheat', 'corn', 'rice'],代表高粱、大豆、小麦、玉米、水稻。
检测场景为乡村农田、作物加工厂等场景,可用于快速区分作物种类、杂草及病虫害,显著提升农田监测效率等。
点击公众号底部菜单栏或回复“数据集”“项目代码”获取~

1、数据概述
车祸等级识别的重要性
(一)助力智慧农业转型升级,替代传统人工田间作业
传统农作物品种识别、长势排查、杂草病害筛查依靠人工下地目测,人工效率低、主观性强、人力成本逐年上涨、大面积农田巡检难以全覆盖。YOLO 系列算法具备实时端侧推理、多目标同步检测特性,可搭载无人机、田间巡检机器人、田间固定摄像头、手持智能终端,实现全天候、大范围农田自动化普查,是传统农业向数字化、智能化转型的关键落地技术。
(二)解决农田复杂场景识别难点
农田环境存在光照多变、作物枝叶重叠遮挡、杂草与作物形态近似、苗期植株细小、田间泥土干扰等难题。YOLO(YOLOv5/v8/v11)经过农田数据集优化后,依托锚框优化、Mosaic 数据增强、多尺度特征融合,可在复杂田间环境下精准区分不同品类农作物,弥补传统图像分类算法无法定位作物位置、只能单图全局分类的短板,实现分类 + 目标定位一体化。
(三)夯实农业精细化管理的数据底座
农作物分类检测输出作物种类、田间分布密度、株数统计数据,为农田大数据平台提供基础数据源,串联播种、灌溉、施肥、植保、收割全链条农事管理,改变以往凭经验种地的粗放模式。
基于YOLO的农作物分类检测系统
1. 田间精准植保(经济价值突出)
区分作物与杂草:精准定位杂草区域,指导变量除草、定向除草剂喷施,减少农药滥用,降低农资成本,减少农药残留污染土壤与农产品;
作物分类 + 病害附带检测:区分玉米、小麦、大豆、高粱等作物品类,同步识别患病植株,定点精准施药,大幅减少农药用量,提升粮食品质。
2. 播种与苗期长势监测
播种后苗期巡检:统计各类作物出苗密度、缺苗区域,指导补苗作业,优化田间播种方案,提升土地利用率与亩产;
规模化种植基地:无人机航拍 + YOLO 算法批量统计分区作物种类,核算不同品种实际种植面积,便于种植企业调整种养规划。
3. 农作物估产与农业统计
根据田间作物品类、植株数量、分布占比,结合作物生长周期模型,实现分品种产量预估,助力地方农业部门完成种植面积普查、粮食产能统计,为粮食储备、农业补贴、涉农政策制定提供客观数据,替代人工抽样统计,数据更客观高效。
4. 农机智能化落地配套
智能收割机器人、变量施肥农机搭载轻量化 YOLO 模型,田间实时识别作物品种,自动切换收割参数、施肥配比,实现一机多作物智能化作业,提升大型农机通用性与作业效率,降低农机改造与使用成本。
该数据集含有 10712 张图片,包含Pascal VOC XML格式和YOLO TXT格式,用于训练和测试快速区分作物种类、杂草及病虫害,显著提升农田监测效率检测。
图片格式为jpg格式,标注格式分别为:
YOLO:txt
VOC:xml
数据集均为手工标注,保证标注精确度。
2、数据集文件结构
Accident-level/
——test/
————Annotations/
————images/
————labels/
——train/
————Annotations/
————images/
————labels/
——valid/
————Annotations/
————images/
————labels/
——data.yaml
该数据集已划分训练集样本,分别是:test目录(测试集)、train目录(训练集)、valid目录(验证集); Annotations文件夹为Pascal VOC格式的XML文件 ; images文件夹为jpg格式的数据样本; labels文件夹是YOLO格式的TXT文件; data.yaml是数据集配置文件,包含车祸等级检测的目标分类和加载路径。





Annotations目录下的xml文件内容如下:
<?xml version="1.0" encoding="utf-8"?><annotation><folder>driving_annotation_dataset</folder><filename>9eeec6b45.jpg</filename><size><width>1024</width><height>1024</height><depth>3</depth></size><object><name>wheat</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>976</xmin><ymin>724</ymin><xmax>1025</xmax><ymax>818</ymax></bndbox></object><object><name>wheat</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>828</xmin><ymin>389</ymin><xmax>936</xmax><ymax>471</ymax></bndbox></object><object><name>wheat</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>824</xmin><ymin>780</ymin><xmax>911</xmax><ymax>880</ymax></bndbox></object></annotation>
labels目录下的txt文件内容如下:
4 0.44136960600375236 0.285625 0.13602251407129456 0.071250000000000014 0.6852720450281425 0.713125 0.1904315196998124 0.088754 0.14587242026266417 0.47000000000000003 0.07598499061913697 0.04254 0.4366791744840525 0.14125000000000001 0.15103189493433397 0.0654 0.5107879924953096 0.49625 0.06660412757973734 0.07254 0.2298311444652908 0.8618750000000001 0.03564727954971857 0.136254 0.024390243902439025 0.325 0.04690431519699812 0.04754 0.08911819887429644 0.08 0.0600375234521576 0.0554 0.5942776735459663 0.41375 0.07598499061913697 0.02754 0.4521575984990619 0.02125 0.07879924953095685 0.03754 0.5792682926829268 0.795 0.15103189493433397 0.1975
3、数据集适用范围
- 目标检测
场景,监控识别,无人机识别 yolo训练模型或其他模型 - 乡村农田、作物加工厂等场景
可用于快速区分作物种类、杂草及病虫害,显著提升农田监测效率等
4、数据集标注结果

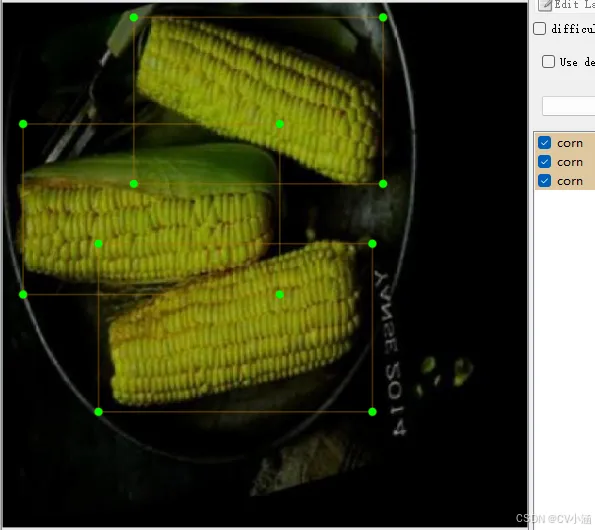
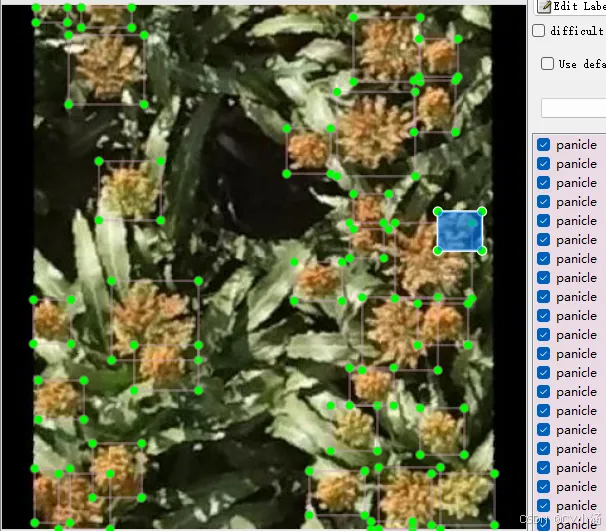

4.1、数据集内容
场景视角:人员视角数据样本、监控视角数据样本; 标注内容:['panicle', 'soybean', 'wheat', 'corn', 'rice'],总计5个分类; 图片总量:10712 张图片数据; 标注类型:含有Pascal VOC XML格式和yolo TXT格式;
5、训练过程
5.1、导入训练数据
下载YOLOv8项目压缩包,解压在任意本地workspace文件夹中。
下载YOLOv8预训练模型,导入到ultralytics-main项目根目录下。
在ultralytics-main项目根目录下,创建data文件夹,并在data文件夹下创建子文件夹:Annotations、images、imageSets、labels,其中,将pascal VOC格式的XML文件手动导入到Annotations文件夹中,将JPG格式的图像数据导入到images文件夹中,imageSets和labels两个文件夹不导入数据。
data目录结构如下:
data/
——Annotations/ //存放xml文件
——images/ //存放jpg图像
——imageSets/ //置空
——labels/ //置空
整体项目结构如下所示:
5.2、数据分割
首先在ultralytics-main目录下创建一个split_train_val.py文件,运行文件之后会在imageSets文件夹下将数据集划分为训练集train.txt、验证集val.txt、测试集test.txt,里面存放的就是用于训练、验证、测试的图片名称。
import osimport randomtrainval_percent = 0.9train_percent = 0.9xmlfilepath = 'data/Annotations'txtsavepath = 'data/ImageSets'total_xml = os.listdir(xmlfilepath)num = len(total_xml)list = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list, tv)train = random.sample(trainval, tr)ftrainval = open('data/ImageSets/trainval.txt', 'w')ftest = open('data/ImageSets/test.txt', 'w')ftrain = open('data/ImageSets/train.txt', 'w')fval = open('data/ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()ftrain.close()fval.close()ftest.close()
5.3、数据集格式化处理
在ultralytics-main目录下创建一个voc_label.py文件,用于处理图像标注数据,将其从XML格式(通常用于Pascal VOC数据集)转换为YOLO格式。
convert_annotation函数
这个函数读取一个图像的XML标注文件,将其转换为YOLO格式的文本文件。
它打开XML文件,解析树结构,提取图像的宽度和高度。
然后,它遍历每个目标对象(
object),检查其类别是否在classes列表中,并忽略标注为困难(difficult)的对象。对于每个有效的对象,它提取边界框坐标,进行必要的越界修正,然后调用
convert函数将坐标转换为YOLO格式。最后,它将类别ID和归一化后的边界框坐标写入一个新的文本文件
import xml.etree.ElementTree as ETimport osfrom os import getcwdsets = ['train', 'val', 'test']classes = ['panicle', 'soybean', 'wheat', 'corn', 'rice'] # 根据标签名称填写类别abs_path = os.getcwd()print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('data/Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('data/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()for image_set in sets:if not os.path.exists('data/labels/'):os.makedirs('data/labels/')image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()list_file = open('data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/data/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()
5.4、修改数据集配置文件
在ultralytics-main目录下创建一个data.yaml文件
train: data/train.txtval: data/val.txttest: data/test.txtnc: 5names = ['panicle', 'soybean', 'wheat', 'corn', 'rice']
5.5、执行命令
执行train.py
model = YOLO('yolov8s.pt')results = model.train(data='data.yaml', epochs=200, imgsz=640, batch=16, workers=0)
也可以在终端执行下述命令:
yolo train data=data.yaml model=yolov8s.pt epochs=200 imgsz=640 batch=16 workers=0 device=0训练结果如下图所示:
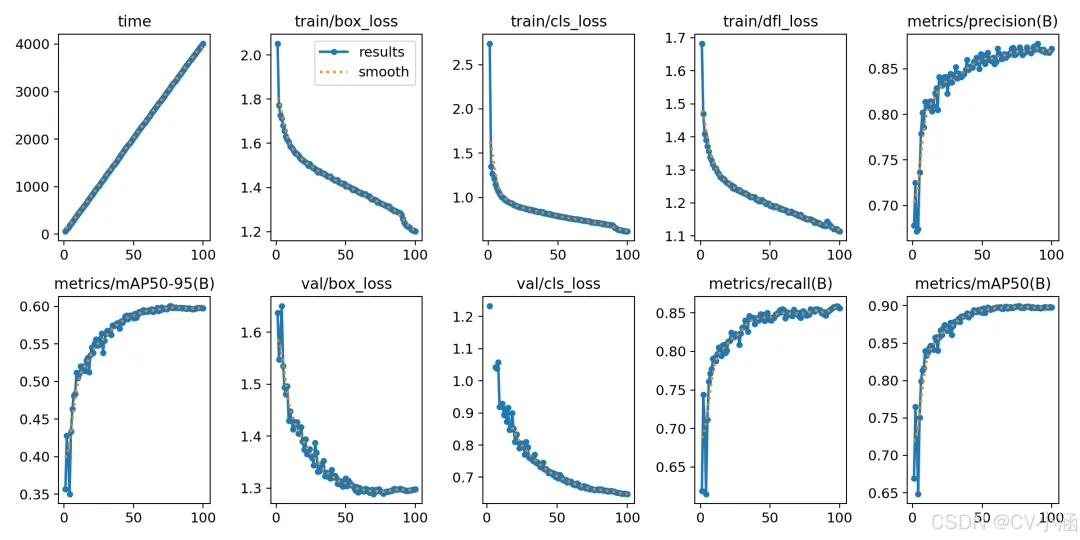
5.6、模型预测
你可以选择新建predict.py预测脚本文件,输入视频流或者图像进行预测。
代码如下:
import cv2from ultralytics import YOLO# Load the YOLOv8 modelmodel = YOLO("./best.pt") # 自定义预测模型加载路径# Open the video filevideo_path = "./demo.mp4" # 自定义预测视频路径cap = cv2.VideoCapture(video_path)# Get the video propertiesframe_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = cap.get(cv2.CAP_PROP_FPS)# Define the codec and create VideoWriter objectfourcc = cv2.VideoWriter_fourcc(*'mp4v') # Be sure to use lower caseout = cv2.VideoWriter('./outputs.mp4', fourcc, fps, (frame_width, frame_height)) # 自定义输出视频路径# Loop through the video frameswhile cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 inference on the frame# results = model(frame)results = model.predict(source=frame, save=True, imgsz=640, conf=0.5)results[0].names[0] = "自行修改中文名称"# Visualize the results on the frameannotated_frame = results[0].plot()# Write the annotated frame to the output fileout.write(annotated_frame)# Display the annotated frame (optional)cv2.imshow("YOLOv8 Inference", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture and writer objectscap.release()out.release()cv2.destroyAllWindows()
图片推理,代码如下:
import warningswarnings.filterwarnings('ignore')from ultralytics import YOLOif __name__ == '__main__':model = YOLO('models/best.pt')model.predict(source='test_pic',imgsz=640,save=True,conf=0.25)
也可以直接在命令行窗口或者Annoconda终端输入以下命令进行模型预测:
yolo predict model="best.pt" source='demo.jpg'6、获取数据集
点击公众号底部菜单栏或回复“数据集”“项目代码”获取~二、YOLO农业作物分类检测系统
1、创建环境并安装依赖:
conda create -n ultralytics-env python=3.10conda activate ultralytics-envpip install -r requirements.txt
2、启动项目
python app.py打开浏览器访问:http://localhost:5000
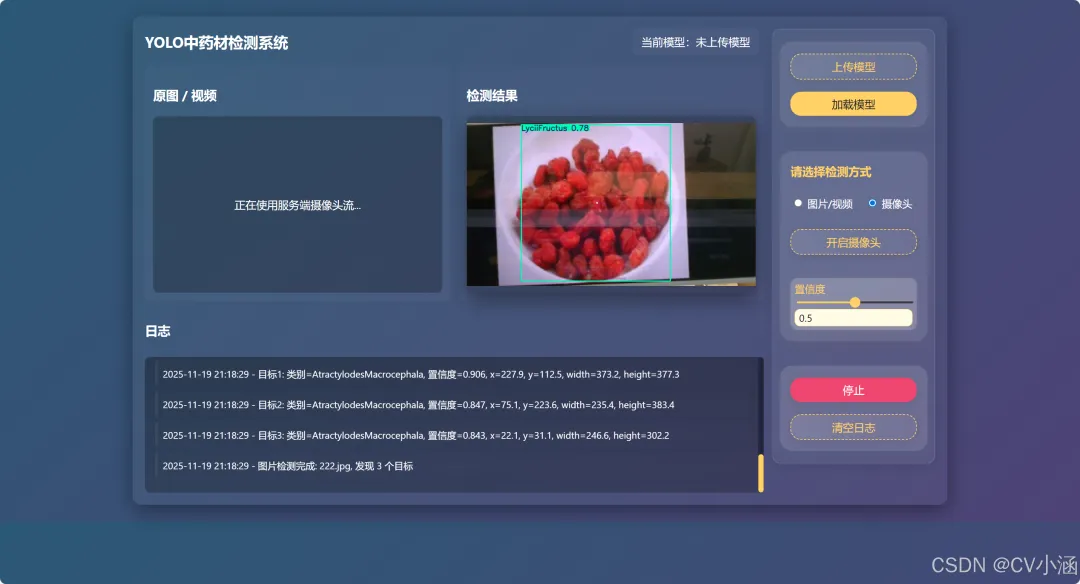
3、效果展示
3.1、推理效果
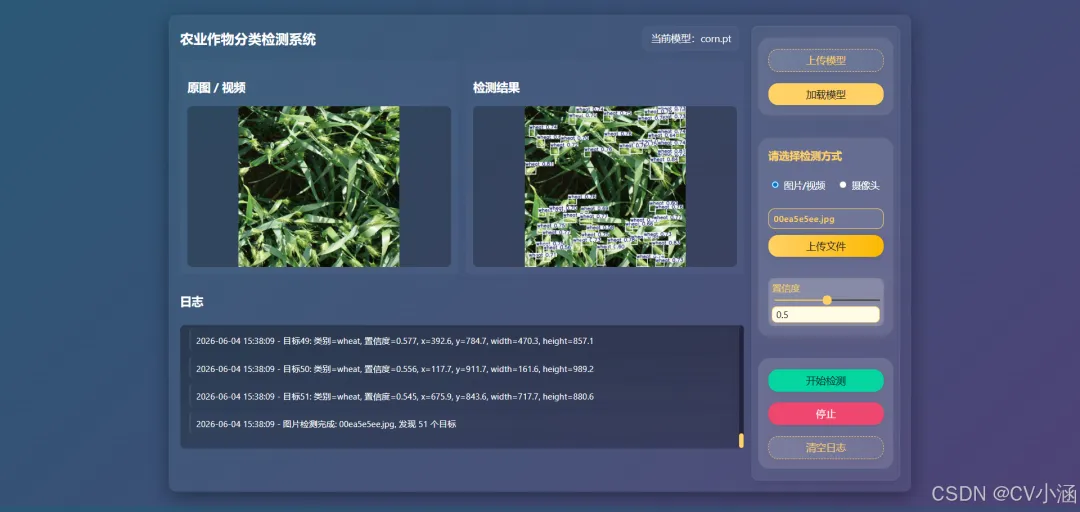
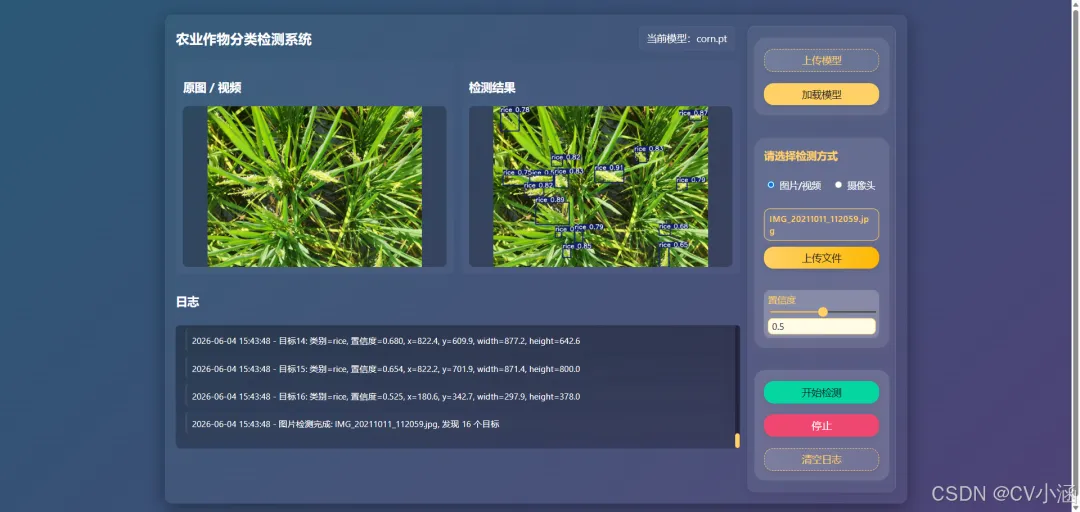
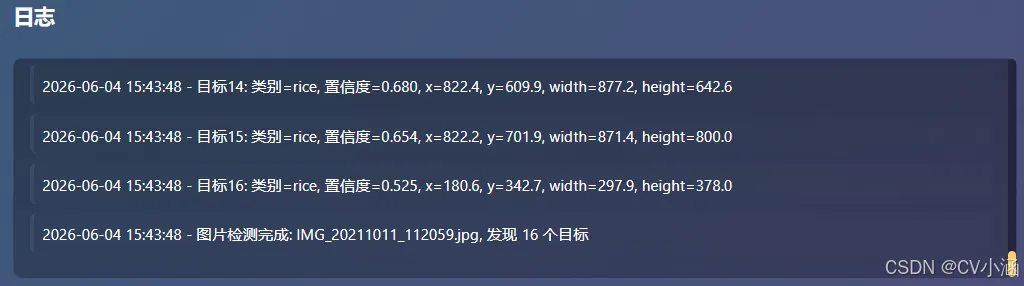
3.2、日志文本框
3.3、摄像头检测
正常点击按钮开启即可,可外接摄像头。
4、前端核心页面代码
<!doctype html><htmllang="zh-CN"><head><metacharset="utf-8"><metaname="viewport"content="width=device-width,initial-scale=1"><title>视觉检测系统 - Web UI</title><linkrel="stylesheet"href="/static/style.css"><linkrel="icon"href="/favicon.ico"></head><body><divclass="container main-flex"><!-- 左侧内容区 --><divclass="left-content"><header><h1>YOLO农业作物分类检测系统</h1><divid="currentModelDisplay"class="modelDisplay"title="当前模型">当前模型:未上传模型</div></header><main><divclass="videoPanel"><divclass="pane"><h3>原图 / 视频</h3><divclass="preview"id="srcPreview">预览区</div></div><divclass="pane"><h3>检测结果</h3><divclass="preview"id="detPreview">检测结果</div></div></div><sectionclass="logArea"><divclass="logHeader"><h3>日志</h3></div><divclass="logInner"><divid="logs"class="logs"></div></div></section></main></div><!-- 右侧按钮栏 --><asideclass="right-bar"><!-- 1. 模型上传/加载区 --><sectionclass="model-section"><buttonid="uploadModelBtn"class="ghost">上传模型<inputid="modelFileInput"type="file"accept=".pt"title="选择 .pt 模型文件"></button><buttonid="loadModel">加载模型</button></section><!-- 2. 检测方式选择区 --><sectionclass="detect-mode-section"><divclass="detect-mode-title">请选择检测方式</div><divclass="detect-mode-radio-group"><label><inputtype="radio"name="detectMode"value="upload"checked> 图片/视频</label><label><inputtype="radio"name="detectMode"value="camera"> 摄像头</label></div><divid="detectModeUpload"class="detect-mode-panel"><divclass="uploaded-file-name"><spanid="uploadedFileName"class="placeholder">未选择文件</span></div><divstyle="height: 22px;"></div><buttonid="uploadBtn">上传文件<inputid="fileInput"type="file"accept="image/*,video/*"title="上传图片或视频"aria-label="上传图片或视频"></button></div><divid="detectModeCamera"class="detect-mode-panel"style="display:none;"><buttonid="cameraDetectBtn"class="ghost">开启摄像头</button><divid="cameraPreview"class="camera-preview"><videoid="localCameraVideo"autoplaymutedplaysinline></video><divclass="camera-controls"><buttonid="stopCameraBtn"class="ghost">关闭摄像头</button></div></div></div><divclass="confWrap"><labelclass="conf">置信度<inputid="confRange"type="range"min="0.01"max="0.99"step="0.01"value="0.5"><inputid="confValue"type="number"min="0.01"max="0.99"step="0.01"value="0.5"></label></div></section><!-- 3. 操作按钮区 --><sectionclass="action-btn-section"><buttonid="startBtn"disabledclass="start">开始检测</button><buttonid="stopBtn"disabledclass="stop">停止</button><buttonid="clearLogs"class="ghost">清空日志</button></section></aside></div><scriptsrc="/static/app.js"></script></body></html>
6、代码获取
点击公众号底部菜单栏或回复“数据集”“项目代码”获取~以上内容均为原创。
