 夜雨聆风
夜雨聆风AI 写代码越快,项目越需要“刹车”
OpenSpec 工程化实践 01/03。 这一篇先聊一个基础问题:AI 已经能很快写代码了,为什么真实项目反而更需要一套工作流?

先说一个不太体面的瞬间
我刚开始用 AI 写代码时,也很容易被它的速度打动。
你说:
帮我写一个登录页。
它写了。
你接着说:
加个暗色模式。
它也写了。
再补一句:
顺便把接口请求封装一下。
它还是能接着往下做。
这种体验很容易让人兴奋。以前要翻文档、找示例、写样板代码、调几个小错误,现在好像一句话就过去了。你看着文件不断变化,会有一种很明确的错觉:开发这件事是不是终于被“加速”解决了?
但用得稍微久一点,另一种感觉就会慢慢冒出来。
代码确实出来得快了,可你开始不太敢放心。它好像理解了你的意思,但总有一些地方和你想的不一样。你前面说过的限制,它后面可能忘了。你让它改 A,它顺手动了 B。聊到最后,对话越来越长,代码越来越多,你反而要花更多时间确认:它到底有没有按原来的目标在做?
这不是 AI 不努力。
很多时候,是我们把太多重要信息都留在了聊天窗口里。
AI 放大的,不只是生产力
过去我们说工程化,常常是在说代码质量、构建流程、测试、发布、监控。
这些当然都重要。
但 AI 进入开发流程后,我越来越觉得还有一个问题被放大了:变更本身有没有被说清楚。
一个真实需求从来不只是“写一段代码”。它至少包含几层东西:
为什么要做
这次做到什么程度
哪些行为要被保证
哪些东西暂时不碰
技术上为什么选这个方案
做完以后怎么判断真的完成了
以前人写代码慢一点,这些问题会在讨论、评审、联调、测试里一点点暴露。慢不一定是好事,但慢会给团队留出反应时间。
AI 不一样。
它可以在几分钟里生成一批文件,补一堆逻辑,甚至把测试也顺手写了。表面上进展很顺,风险却可能被往后推了。等你发现方向不对时,问题已经不再是一句“改一下”能解决的了,因为它可能已经把错误理解落进了代码结构里。
所以我现在看 AI 编程,不太愿意只问“它能不能写出来”。
更重要的问题是:
它写出来之后,项目能不能接得住?这也是我理解 OpenSpec 的起点。
它不是给 AI 再加一个更长的 Prompt,也不是把开发变成一套很重的审批流程。它解决的是另一件事:把一次变更,从一段临时对话,变成项目里可以被阅读、被检查、被继续、被归档的东西。
这里说的“刹车”,不是为了减速。
它更像开车上高速前那一下确认:方向盘在你手里,路况看过,目的地也没搞错。确认完,再踩油门。
如果把这个问题画出来,大概是下面这样:
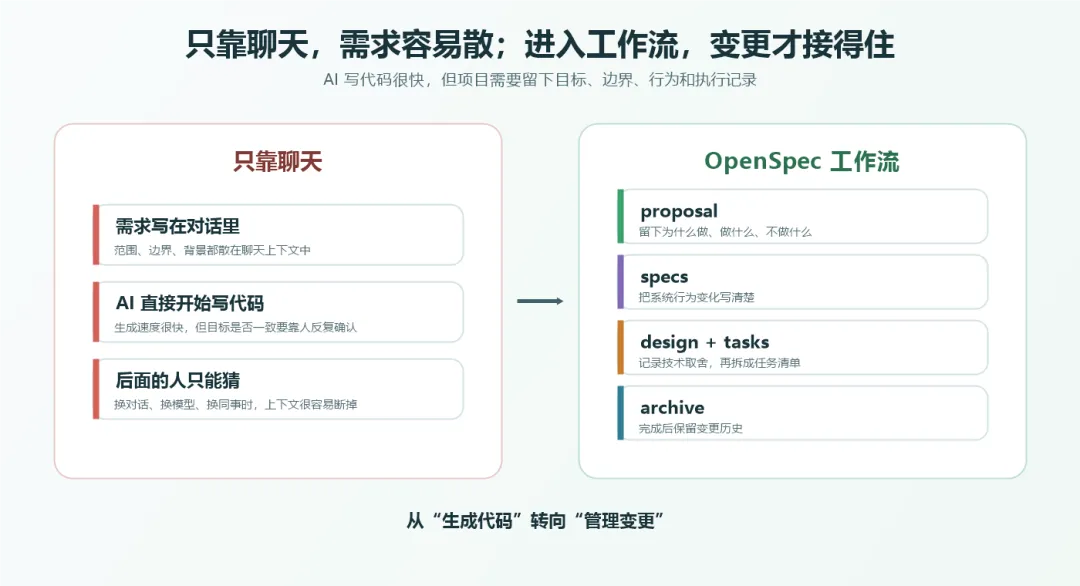
聊天窗口不是项目的一部分
现在很多人谈 AI 提效,会先聊 Prompt。
Prompt 当然重要。你说得越清楚,AI 给出的结果通常越稳定。但到了真实项目里,Prompt 有一个天然短板:它大多只存在于聊天记录中。
比如你让 AI 做一个会员权益功能,可能在对话里交代过:
普通会员只能看基础内容。 高级会员可以下载资料。 过期会员不能继续使用高级权益。 后台可以手动调整会员状态。 支付系统这期先不接,后面再说。
这些话在当下看起来很清楚。
问题是,过几天再回到项目时,代码还在,但这些上下文可能已经散了。为什么这期不接支付?后台为什么要能手动调整?过期会员是立刻失效,还是到当天结束失效?哪些是必须保证的行为,哪些只是当时顺口提到的想法?
如果这些信息没有进入项目,后面的人只能从代码里猜。
更麻烦的是,代码本身经常无法完整表达意图。Git 可以告诉你哪一行在什么时候变了,但它很难告诉你当时为什么这么做。PR 描述如果写得认真,能补一部分;但很多时候,真正的决策仍然散在聊天、会议、脑子里。
AI 参与以后,这个问题会更明显。
因为它会把“没说清楚”的地方迅速填满。填得有时还挺像那么回事。你一看,页面能跑,接口能通,测试也过了,但某个边界行为其实已经偏掉了。
这时候再回头追问“当时到底想要什么”,成本就高了。
OpenSpec 不是另一个 AI 编程助手
OpenSpec 不替代 Codex、Claude Code、Cursor、GitHub Copilot 这些工具。
它更像是在 AI 和项目之间加了一层轻量的变更工作流。
你仍然可以用自己熟悉的 AI 编程工具写代码。OpenSpec 做的事情,是把一次需求变更整理成项目里的文件,让 AI 动手之前,不只是拿到一句模糊指令,而是拿到一组相对稳定的上下文。
可以先看这张图:

以前我们常常是:
想法 -> 聊天 -> 代码 -> 再聊天 -> 再改代码用了 OpenSpec 后,更接近:
想法 -> 变更说明 -> 行为规格 -> 技术方案 -> 任务清单 -> 代码实现 -> 归档这不是为了把开发拆成一堆僵硬阶段。
OpenSpec 自己的理念其实很克制:fluid not rigid、iterative not waterfall、easy not complex、brownfield-first。翻成人话就是:不要把它当流程大锤,它应该允许你边做边修正;不要逼每个需求走完整仪式;它要服务已有项目,而不是只适合从零开始的新项目。
我觉得这个气质很重要。
因为 AI 编程真正需要的,不是再来一个“正确流程”,而是给变化一个容器。需求不清楚时可以探索,方案不对时可以改 design,任务拆粗了可以继续细化,做到一半发现范围变了,也应该回到 proposal 和 specs 里修正,而不是硬着头皮把一开始写错的东西执行完。
这也是 OpenSpec 跟很多传统规格文档不一样的地方。
它不是让你先写一本厚文档,然后再进入开发。它更像是把工程里本来就需要发生的那些判断,落到项目中一个能被 AI 和人共同读取的位置。
它在项目里放了什么?
初始化 OpenSpec 后,项目里会多一个 openspec 目录。
从使用者角度看,最重要的是两类东西:
openspec/
specs/ 当前系统行为的说明书
changes/ 正在进行或准备进行的变更
用一张图来看,OpenSpec 的核心模型其实就是三块:当前事实、本次变更、历史归档。
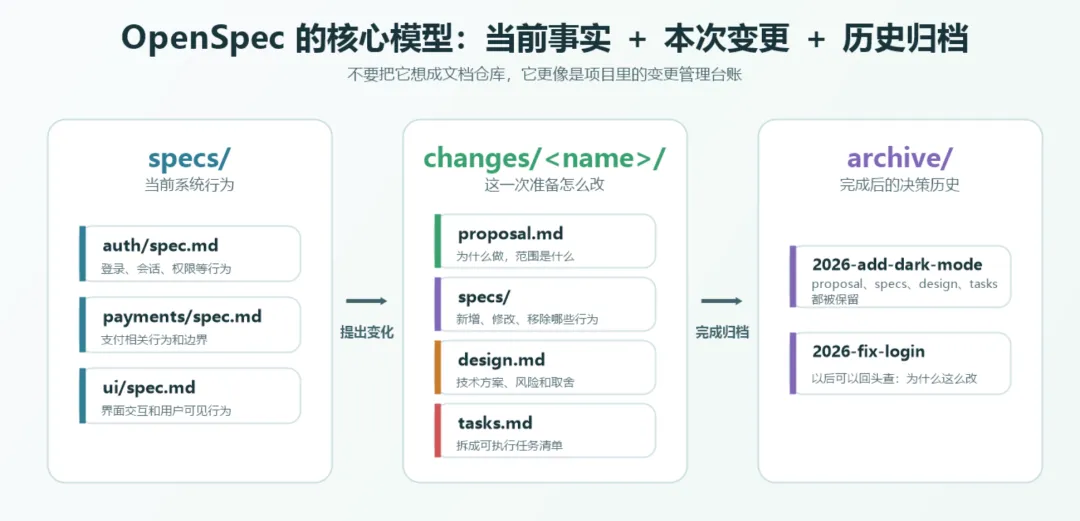
specs/ 记录的是系统现在应该是什么样。
这里的“应该”很关键。它不是代码现状的流水账,也不是技术实现手册。它更像系统对外承诺的行为说明:用户登录成功后应该发生什么,权限过期后应该怎么处理,数据导出时应该提供什么格式,接口在异常情况下应该返回什么。
changes/ 记录的是这一次准备怎么改。
一个项目可能同时有很多事情在做:新增暗色模式、修复登录跳转、优化商品查询、调整会员权益。OpenSpec 会把每个变化单独放进一个变更目录里,避免所有讨论、方案和任务混在一起。
一个典型变更目录大概长这样:
openspec/
changes/
add-dark-mode/
proposal.md
design.md
tasks.md
specs/
ui/
spec.md
这几个文件看起来像文档,但它们不是为了“显得正规”。每个文件都在回答一个具体问题。
proposal:先把意图钉住
proposal.md 是一次变更的起点。
它不需要长,但必须老实。
这件事为什么要做? 这次具体改什么? 哪些东西这次先不做? 如果范围变化,谁来判断是否还是同一个 change?
比如暗色模式这个需求,proposal 可以写得很短:
为什么做:
夜间使用时,用户反馈当前界面太亮,希望提供暗色模式。
这次做什么:
提供亮色 / 暗色切换,记住用户选择,首次进入时尊重系统偏好。
这次不做什么:
不做自定义主题色,不做每个页面单独配置主题,不重做整体视觉设计。
这几句话没有技术含量,但很有工程价值。
因为 AI 很容易沿着相关性往外扩。你说“做一个登录页”,它会想到注册、找回密码、用户中心、权限系统。站在 AI 的角度,这些都相关;站在交付角度,它们未必属于这一次改动。
proposal 的作用,就是把这次变更的身份钉住。
后面如果有人说“顺便做自定义主题吧”,你就有一个判断点:这是当前 change 的自然延伸,还是应该另开一个 change?
很多项目失控,并不是因为一开始目标大,而是因为每一步“顺便”都看起来合理。
specs:写行为,不写实现
specs/ 是 OpenSpec 里最容易被低估的一部分。
它写的不是“怎么实现”,而是“系统应该表现成什么样”。
我们平时和 AI 聊代码,很容易直接进入实现细节:
用 React Context 管主题状态。 CSS 变量放到 global.css。 localStorage 里存 theme。
这些当然有用,但它们不是用户实际关心的行为。
换成 spec 的写法,更接近这样:
Requirement: Theme Selection
系统应该允许用户在亮色和暗色主题之间切换。
Scenario: Manual toggle
当用户点击主题切换按钮时,界面应该立即切换主题,并在下次访问时保留这个选择。
Scenario: System preference
当用户没有保存过主题选择时,系统应该使用设备当前的颜色偏好。
这里没有强调代码怎么写。
它关心的是用户能感知到什么,系统对外承诺什么。这一点对 AI 很重要,因为实现方式可以调整,但行为要求不能丢。
如果后面发现 React Context 不合适,可以换成别的方案;如果 localStorage 不够,可以改成服务端保存。只要行为没变,spec 仍然成立。
反过来,如果行为变了,就应该回到 spec 改,而不是只在代码里悄悄改。
这会逼我们区分两件事:实现的变化,和系统承诺的变化。
很多团队在长期项目里最缺的,其实就是这个区分。
delta spec:为什么它适合老项目
OpenSpec 还有一个很实用的设计:它不是每次都要求你重写完整规格,而是写“变化”。
也就是 delta spec。
你可以把它理解成行为层面的 diff。
比如一个已有系统里,本来有登录功能。现在你要新增双因素认证,不需要把整个认证系统重新描述一遍,只需要说明这次新增、修改、移除了哪些行为。
常见写法是:
ADDED:新增什么行为
MODIFIED:修改什么行为
REMOVED:移除什么行为
这个设计对老项目很友好。
真实项目里,大多数工作都不是从零开始。我们更多是在已有系统上加一点、改一点、删一点。delta spec 承认这个现实:你不需要为了一个中等需求把全系统重新写一遍说明书,你只需要把这次改变说清楚。
这也是 OpenSpec 的 brownfield-first。
它适合已有代码库,因为它把“改动”当成一等公民,而不是把“完整规格”当成唯一入口。
design:把取舍留下来
不是每个需求都需要很重的设计文档。
一个按钮文案调整,没必要写 design。一个小的 UI 样式修复,proposal、spec、tasks 可能就够了。
但如果改动涉及多个模块、新增依赖、数据迁移、权限模型、性能风险,就值得写 design.md。
design.md 主要记录技术判断:
为什么选这个方案
还有哪些方案被放弃
现有架构里有没有可复用的模式
有什么风险
出问题怎么回滚
哪些地方需要特别测试
这些东西很多团队平时其实也会讨论,只是讨论完就散在会议和聊天里。
AI 参与后,更应该把这些判断留下来。否则过一段时间再看代码,你只知道“它这么写了”,但不知道当时为什么选择这样写。
我觉得 design 最大的价值,不是让方案看起来正式,而是给未来的自己和同事留一条路。
当后来的人准备改这块代码时,他可以看到:原来当时不是没想到另一种方案,而是因为迁移成本、兼容性、上线风险,暂时没选。
这能少很多“前人怎么这么写”的误解。
tasks:让 AI 按可检查的单元工作
tasks.md 是最贴近执行的文件。
AI 很适合按清单工作,但清单必须足够具体。
比如暗色模式可以拆成:
1. 创建主题状态管理
2. 增加亮色 / 暗色样式变量
3. 实现主题切换按钮
4. 保存用户选择
5. 处理首次访问时的系统偏好
6. 补充测试或手动验证
这比一句“实现暗色模式”要稳定得多。
因为每个任务都能被执行,也能被检查。AI 做到哪里、漏了什么、有没有做多,都更容易看出来。
这里还有一个细节:tasks 不是给 AI 的待办清单,也是给人的 Review 索引。
如果你打开 PR,看到它勾选了“处理首次访问时的系统偏好”,你就知道应该去看它到底怎么处理 prefers-color-scheme,有没有刷新后保留,有没有考虑已有用户选择覆盖系统偏好。
任务拆得越清楚,Review 就越不像大海捞针。
archive:别让决策只活在当时
一个变更完成后,OpenSpec 会把它归档。
归档不是把文件清理掉。
它的意义是:这次变化的上下文被保留下来了。以后你再看这个项目,不只知道某段代码是在某个提交里改的,还能看到当时为什么要改、行为要求是什么、方案怎么定的、任务怎么拆的。
很多项目越做越难改,不只是因为代码复杂。
还有一个原因是:决策历史丢了。
你只看到最后的代码形状,却看不到中间那些约束和取舍。于是后来的人只能重新猜一遍,再用新的猜测去覆盖旧的猜测。
OpenSpec 的 archive 想补的就是这一层。
它让一次变更不是“聊完就散、写完就忘”,而是沉淀成项目历史的一部分。
什么情况下值得用?
说到这里,可能有人会担心:这会不会太麻烦?
这是个很实际的问题。
我的答案是:不是所有改动都该用。
如果只是改一个按钮颜色、修一个文案错别字、写一个临时脚本,直接让 AI 改就可以了。为了流程而流程,最后只会让人反感。
OpenSpec 更适合这些情况:
改动会影响多个模块
需求里有比较多边界条件
行为变化会影响用户或下游系统
后面需要别人 Review 或接手
代码不是一次性的,未来还要维护
你担心 AI 写得太快,自己跟不上它的上下文
说得直接一点:
小脚本追求快就行。
长期项目不能只追求快,还要能说清楚、查得到、接得住。
结语:刹车不是慢,是让速度有方向
AI 编程刚开始吸引人的地方,是快。
它能帮我们省掉很多重复劳动,也能把一些原本要花很久的实现快速搭出来。
但越往真实项目里走,我越觉得,只追求“生成速度”是不够的。
如果需求只在聊天里,方案只在脑子里,任务只靠 AI 自己猜,那么代码生成得越快,后面越容易乱。
OpenSpec 给我的启发是:AI 编程需要的不是更厚重的流程,而是一套刚好够用的变更工作流。
先把为什么做说清楚。 再把系统行为写明白。 然后再谈技术方案和任务拆分。 最后让 AI 按这个上下文去实现。
这样一来,AI 不只是“会写代码”,而是开始进入一个可以协作、可以审查、可以回溯的工程过程。
这也是我觉得 OpenSpec 值得写一组文章聊下去的原因。
下一篇,我们用一个具体需求,把 OpenSpec 的完整流程跑一遍:
从 /opsx:propose 开始,经过 proposal、specs、design、tasks,再到 /opsx:apply、/opsx:sync 和 /opsx:archive,看看它在真实开发里到底怎么用。
