 夜雨聆风
夜雨聆风文/华哥聊数据 | 十年磨一剑的大数据老兵,个人微信ID:bba80108
一、湖仓一体的技术基座
企业数据架构从传统数仓到数据湖,再到湖仓一体(Lakehouse),核心诉求始终是同时满足结构化查询的高性能和非结构化数据的灵活性。湖仓一体不是某款产品,而是一种架构理念,在对象存储(如S3、OSS)之上,通过开放表格式提供ACID事务、Schema演进、时间旅行等数仓级能力。

湖仓一体并非简单地把数仓和数据湖堆在一起。它解决了数据湖的核心短板,缺乏事务性、Schema管理和一致性保障。当前业界四大主流开源湖表格式对比如下:
特性 | Apache Iceberg | Delta Lake | Apache Hudi | Apache Paimon |
发起方 | Netflix(Apache顶级项目) | Databricks(Linux基金会) | Uber(Apache顶级项目) | 阿里巴巴(原Flink Table Store) |
核心优势 | 大规模表管理、多引擎兼容 | 与Spark生态及Databricks平台深度集成 | 流式upsert、增量处理 | 流批一体、与Flink生态紧耦合 |
ACID事务 | 支持 | 支持 | 支持 | 支持 |
引擎兼容 | Spark/Flink/Trino/Presto | Spark/Flink/Trino | Spark/Flink/Trino/Presto | Flink/Spark/Trino |
2025年以来,Iceberg凭借多引擎兼容性成为采用率最高的方案之一。Databricks的Unity Catalog在2025年重大升级中宣布全面支持Iceberg,企业可以在同一治理体系下管理Delta、Iceberg、Hudi等多种格式的数据表。但Delta Lake、Hudi、Paimon各自拥有活跃社区和明确适用场景,选型需结合自身技术栈评估。例如,实时增量更新场景倾向Hudi,流批一体重度依赖Flink的场景倾向Paimon。
开放表格式是湖仓一体的"地基",AI能力是"上层建筑"。地基不牢,AI的上层应用就缺乏可靠的数据语义支撑。 |
二、实战路径一,智能数据治理
数据治理是湖仓一体中AI落地最广泛、见效较快的场景之一。当数据源从十几个扩展到数百个,传统依赖人工编写规则、手动梳理血缘的方式已力不从心。AI的介入核心解决两个问题:"数据资产可发现性"和"数据可信度"两个问题。
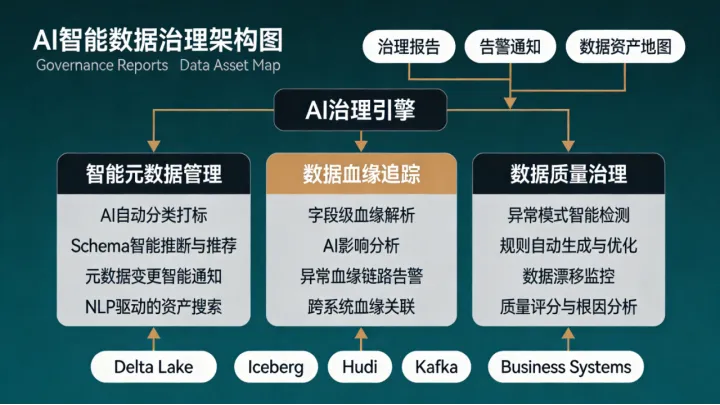
2.1 智能元数据管理
2.2 血缘追踪与质量检测
智能数据治理的核心思路是"统计学习+规则兜底"。AI负责发现人工规则难以覆盖的隐性异常,但最终的质量兜底仍依赖可解释的预定义规则。这种分层策略在金融等强监管行业中尤为重要。 |

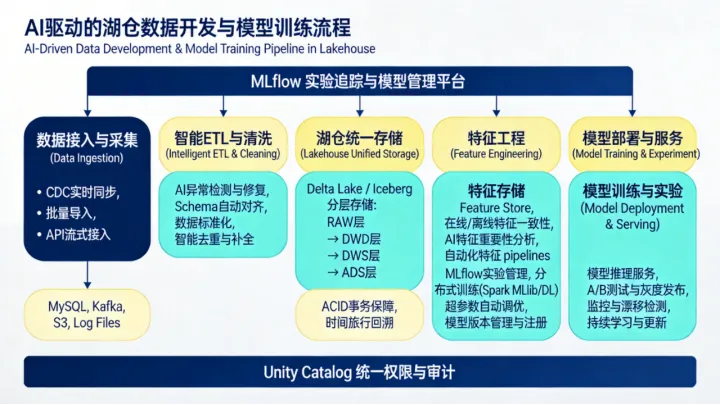
三、实战路径二,智能数据开发与模型训练
3.1 Text-to-SQL与智能ETL
Text-to-SQL是当前湖仓一体中最成熟的AI应用之一。以Databricks为例,其Databricks Assistant内置于Notebook、SQL编辑器及AI/BI仪表板,可直接对接Unity Catalog元数据,理解表结构、字段含义和业务上下文,辅助生成和优化SQL查询。AI/BI Genie则更进一步,面向业务用户提供自然语言交互式数据分析体验,但需预先配置语义层和业务说明才能发挥最佳效果。在金融、零售等业务分析密集的场景中,此类工具能显著缩短数据获取的等待时间。
ETL流程的智能化主要体现在两个环节。一是智能Schema对齐:上游数据源发生Schema变更时,系统自动检测变更并推荐下游ETL脚本的适配方案,例如源表新增字段时建议是透传、忽略还是转换。Databricks的Delta Live Tables等声明式数据管道框架已支持Schema演进感知和自动适配,AI在此环节的介入尚处于探索阶段。二是作业调度优化:平台已支持自动扩缩容和资源动态分配,更深度的AI调度推荐(如分析作业执行历史推荐并行化策略)是下一步方向。
Text-to-SQL目前更适合查询分析场景(SELECT类),复杂ETL逻辑仍需工程师主导编写,AI辅助生成初稿。 |
3.2 特征工程与模型训练一体化
湖仓一体为ML模型训练提供了天然优势:所有训练数据统一存储在湖仓层,无需在不同系统间搬运数据,避免了数据副本不一致问题。但真正实现"湖仓+AI"闭环,还需解决特征管理和实验管理两个关键问题:



GO
资料下载

加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!

四、落地案例与经验总结
四条落地经验
五、局限与展望
AI在湖仓一体中的实践仍处于早期阶段,虽然已经在治理、开发、模型训练等环节展现出明确的效率提升价值,但距离"开箱即用的智能数据平台"还有相当距离。当前存在三个明确局限:
展望未来,三个方向值得关注:一是大模型与湖仓元数据体系深度整合,LLM对业务术语和数据语义的理解能力将大幅提升Text-to-SQL的准确率和数据探索的深度;二是多模态AI打通结构化分析与非结构化理解的壁垒,湖仓一体天然支持存储图像、文本、音频等非结构化数据,AI的多模态能力可以将两类分析统一在同一平台上完成;三是从AI辅助走向自治数据管道,实现数据管道的自动监控、自动修复、自动优化,进一步降低数据运维的人力投入。这些方向的落地,都建立在湖仓一体基础设施成熟和统一治理体系完善的前提之上。
当前阶段AI的定位是"效率倍增器"而非"架构替代品"。打好开放表格式地基、建立统一治理体系、从高ROI场景切入、坚持人机协作——这四条才是落地的关键成功因素。 |
如果你觉得这篇文章有启发,欢迎点赞 + 在看 + 转发,让更多数据同行看到!
更重要的是——点个关注【华哥聊数据】,追更不迷路!
博主留言:
加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!

我们不止讲概念,更输出可落地的解决方案。
下期见
