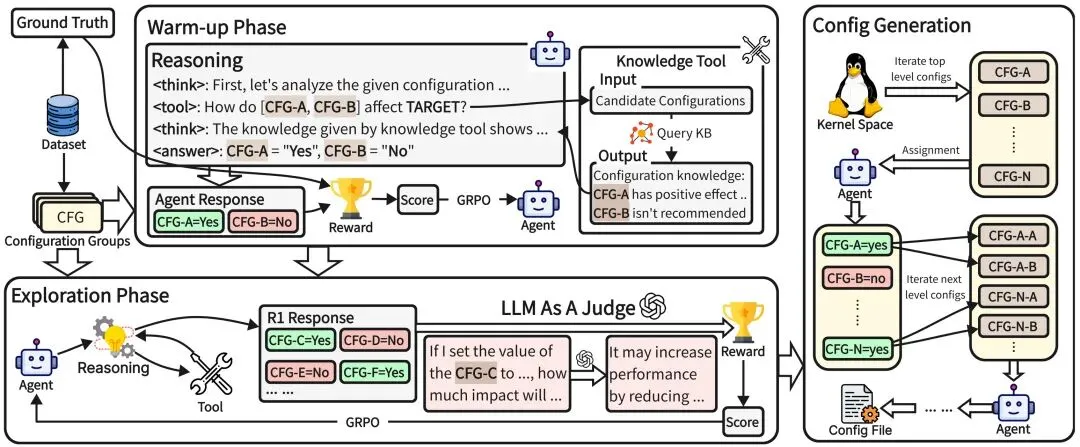
KDD 2026 | 中科院软件所提出 TuneAgent:强化学习智能体自动调优 Linux 内核📌 一句话总结:本文提出 TuneAgent,将 Linux kernel tuning 建模为受约束的 RL 交互问题,通过规则奖励和两阶段训练自动生成可编译、可启动的内核配置,最高带来 5.6% 整体性能提升。🔍 背景问题:Linux 内核调优长期依赖专家经验,自动化方法仍难以同时保证性能、合法性与泛化性:1️⃣ 内核配置空间超过 18,000 个选项,存在复杂依赖、层级和互斥约束,错误组合可能导致编译失败或系统崩溃;2️⃣ 性能反馈稀疏且昂贵,每次评估都可能涉及重编译、部署和 benchmark,难以直接用于高效搜索;3️⃣ 配置收益高度依赖 workload,同一组参数可能提升 Nginx 却损害 Redis,跨场景迁移能力有限。💡 方法简介:TuneAgent 将内核调优形式化为 MDP,把当前配置、workload 特征和运行性能作为 state,把启用、关闭或赋值配置项作为 action,并在约束环境中迭代优化 tuning policy;方法将复杂 kernel space 划分为功能相关的 configuration groups,动作进一步分解为 group selection 与 configuration assignment,从而降低探索难度并显式保持依赖一致性;奖励函数由三部分组成:format reward 约束 、<tool_call>、 的结构化输出,answer reward 检查 Bool、Menu、Choice、Value 四类配置语义,performance reward 用 LLM-as-a-Judge 近似性能增益;训练采用两阶段 GRPO:先在 warm-up 阶段学习格式与配置正确性,再在 exploration 阶段引入性能奖励,让 agent 从“会合法修改”逐步转向“会有效优化”。📊 实验结果:在 UnixBench 上,TuneAgent-7B 达到最高 overall score 662.2,相比默认 heuristic 配置 627.2 提升 35.0,相比 Qwen2.5-7B-Instruct 619.6 提升 42.6;对比强基线时,TuneAgent-7B 超过 GPT-4o 的 632.9、DeepSeek-R1 的 650.5 和 AutoOS 的 638.8,说明领域化 RL 比单纯 prompt 或通用推理模型更适合受约束系统优化;配置有效性方面,TuneAgent-7B 整体 validity 达到 93.8%,显著高于 Qwen-7B 的 58.4%;完整奖励相比只用 format reward 或 format + performance reward,同时提升性能与可部署性;真实应用泛化实验显示,TuneAgent 在 Nginx 上最高提升 51.8%,在 PostgreSQL 上稳定提升 8.6%–9.4%,在高度优化的 Redis 上仍有 1.5%–3.8% 增益,体现出跨 workload 的实用鲁棒性。📂 项目主页:https://github.com/LHY-24/TuneAgent📄 论文原文:https://arxiv.org/abs/2508.12551✨ 一句话点评:TuneAgent 用“约束内核空间—规则强化学习”的关系揭示了 OS 自动调优的本质:真正能优化系统的不是会写配置的 LLM,而是能在合法空间中持续试错、验证并对齐性能目标的 agent——这意味着未来系统优化应当从“专家经验调参”走向“可部署的强化学习内核智能体”。
 夜雨聆风
夜雨聆风