 夜雨聆风
夜雨聆风
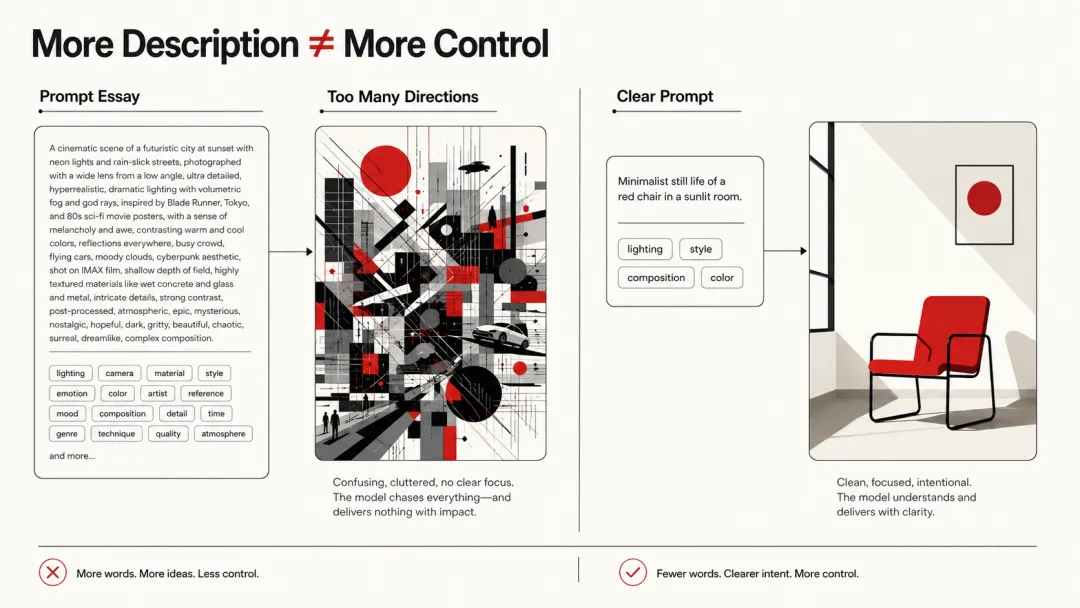
AI 生图提示词,并非越长越好
为什么你写了 几百上千字的提示词,AI 反而画得更乱?为什么你越强调"高质量、真实、电影感、8K",画面越油腻?
这背后其实不是模型不够强,而是你违反了一个近百年前的设计原则:Less is More。
"Less is more"——少即是多,你可能在生活中也见过这句话,这是一条关于信息传达的底层思维。

"Less is more" 起源于德国现代主义建筑大师密斯凡德罗,并成为现代主义设计中最具代表性的理念之一。距今快一百年的时间里,"少即是多"逐渐跨越建筑设计、平面设计、产品设计直到融入人的日常生活当中——每个时代都有人质疑它,每个时代它都被重新验证。
今天,它又在AI时代里再次被验证了一次。
而在 AI 生图的领域,Less is More 不再只是审美原则,更是一种提示词工程思路:关键词越多,权重越稀释;方向越多,模型越妥协。
我想借助ai生图这个概念去解释和应用一下这个思想:这个概念到底在说什么?为什么一个1928年的原则,到了2026年的AI工具上仍然成立?为什么想尝试AI生图的人都必须要理解?
一、"Less is More" 到底是什么?
先澄清:这不是在说"越少越好"。
从密斯的建筑理念来看,少指的并不是数量,而是优先级。
密斯的原意是:该理念主张以简约精炼代替繁复奢华,通过克制的形式传递更多美感,去除不必要的装饰,同时保留建筑的功能性与美感。


这一理念后续被进一步继承到极简主义,然后拓展到了工业设计、平面设计等领域,直到深入人的日常生活。
这并不是那个时代的审美偏好。而是密斯对于信息传达的底层逻辑的思辨,不管你是在1928年设计一栋建筑,还是在2026年写一段AI提示词,信息过载的后果都是一样的:什么都没表达出来。
以 乔布斯的一生 为例去生成一张图像
在辞藻堆砌的提示词下,AI产出的图像是这样的:

现在让我们砍掉全部冗余的装饰和细节,只保留:标题、主角、每个时间段的代表作品,重新调整提示词的写法,

简洁的表达,让保留下来的元素每个都获得更多的视觉权重,观者一眼就能抓住重点并理解。
那之前的图好看吗?好也不好,真不好说,但与后者相比,一定是后者在保证最容易理解,消耗的注意力最少的同时,实现了相同结果:向读者表达乔布斯的各个人生阶段。
这不是"少"的胜利,是 "清晰" 的胜利。
所以 Less is more 就是:去除冗余、专注本质
⚡ 核心定义
Less is more 不是"越少越好",而是**去除冗余、专注本质**。少的不是数量,是优先级——用最少的元素,让最重要的信息获得最大的表达力。
二、建筑设计中的"Less is More"
密斯·凡·德·罗设计的范斯沃斯住宅(Farnsworth House)是最好懂的例子:一个长方形玻璃盒子、八根工字钢柱、白色钢框架、没有装饰、没有隔墙。结构本身就是装饰。

极简听起来简单,做起来难。结构的诚实性——这是密斯的核心主张:不要假装柱子是大理石的,钢材就是钢材;要让结构的逻辑自己说话。极简建筑往往比装饰性建筑更贵,因为你不能用装饰来掩盖施工瑕疵,每一个接缝、每一个节点都必须精确。
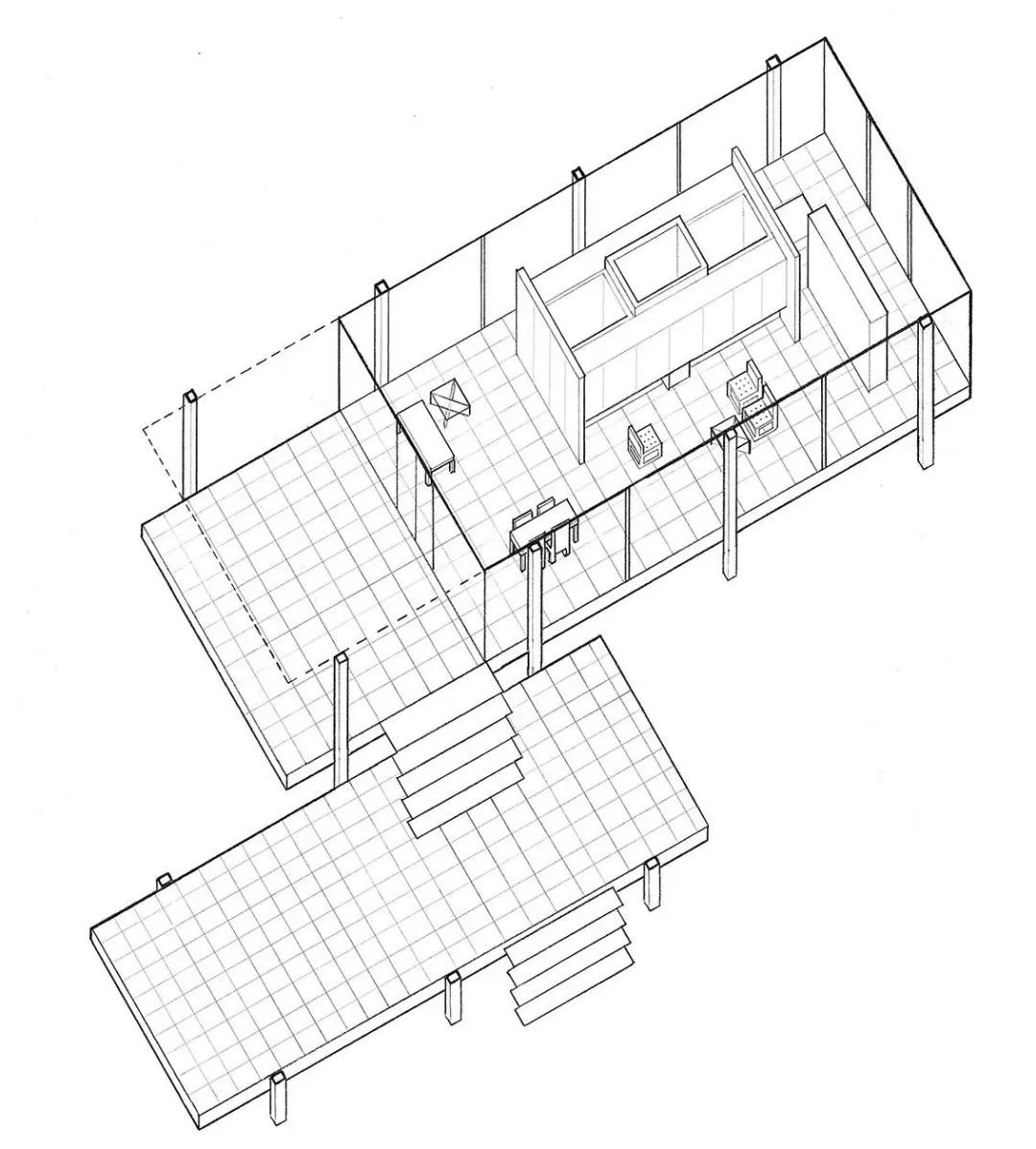
日本建筑师坂茂说:"空间的价值在于它没有被填满的部分。"中国园林的"漏窗"——透过一个洞能看到另一边的景色——这种"不全"反而让空间显得更深远有层次。


想象力需要空间,你把空间都填满了,读者的脑子就罢工了。
三、平面设计中的"Less is More"
留白是主动的设计决策,不是剩余空间。 苹果广告里产品只占30%,剩下70%是空白——那不是在浪费空间,是在引导你的视线。这就是 less is more 的具体操作:用空间引导注意力。

字体越多,沟通越失效。 一个作品用3种以上字体基本就毁了。每种字体都有自己的"声音",混用太多,信息的传达就会失真。好的平面设计通常只用:一种标题字体(粗、有冲击力)+ 一种正文字体(易读、克制)+ 一个字重变化(建立层级)。
色彩克制即力量。 高级品牌视觉的色谱通常只有三种:一个主色、一个辅助色、一个中性色。颜色有心理学重量,你同时用红黄蓝绿,观者的情绪没法稳定下来,反而记不住核心信息。
操作清单:[ ] 元素:一页不超过3个视觉焦点[ ] 字体:不超过2种(标题+正文)[ ] 色彩:主色+辅助色+中性色,不超过3个[ ] 留白:主动留白,[ ] 层级:主次分明,明确的视觉入口
这些原则不是1960年代的过时理论,今天打开Apple官网、Google Material Design规范,仍然是同一套逻辑。"少即是多"在平面设计中经久不衰,是因为人类视觉系统的处理方式没变——注意力有限,信息越多,吸收越少。

发现了吗?从建筑到平面设计,"少即是多"的底层逻辑始终没变:用最少的元素,让最重要的信息获得最大的表达力变的只是载体——建筑里的空间、海报上的留白、以及接下来要说的——AI提示词里的关键词。
四、文生图提示词设计:为什么 "Less is More" 在这里最重要?
OK,铺垫结束。现在说到重点——也是我写这篇文章的真正原因。
最近一段时间来我在高强度用GPT-Image-2做项目的预览图,也会自己随便画着玩。
一开始我测试的提示词写得像小论文。列举了光照、角度、材质、风格、情绪、色彩、构图、镜头参数、艺术家、风格参考……结果出来的图乱七八糟,风格杂糅。做人像的时候皮肤发塑料感、五官像3D渲染;做海报的时候排版混乱、元素之间互相抢戏、没有视觉重心;做场景图的时候光影打架、风格四不像。本来以为是负面提示词的问题,后来才发现可能路径有误,SD之后的生图大模型,写长提示词似乎很容易翻车。

1. 模型的理解方式:权重稀释与"妥协渲染"
文生图模型处理提示词的方式,不是"阅读理解",而是权重分配。这个点大多数教程都不会告诉你。
简单来说:你给的每个词,模型都会给它一定的"注意力权重"。你的提示词越长,权重越分散。当一个词和另一个词争夺模型的注意力时,结果就是都不够强。
但这还不是最严重的问题。最严重的是妥协渲染——当你同时给出互相矛盾的质感方向,模型不会报错,它会试图同时满足所有要求,结果每个方向都只做到了一半。
具体来说,长提示词会导致三种典型的翻车:
翻车一:质量词重复 → 画面"过度完成"
很多人以为,只要同时写上 ultra realistic、8k、masterpiece、best quality、highly detailed,画面就会更真实。但在较新的模型(比如GPT-Image-2)里,这类词堆太多,模型会把画面做得"过度完成"——做人像时皮肤过度锐化、每个毛孔都被刻意强调,看着像一张被AI精修过头的图,反而更假。
做海报也一样。堆上 award-winning design、stunning visual、eye-catching、beautiful typography,模型的理解是"把所有设计手段全用上"——你得到一张塞满装饰元素、字体特效、渐变阴影的海报,什么都突出了,什么都没突出。
好东西的质感是克制的,不是堆出来的。高级的商业杂志大片不会强调每个毛孔,好的海报不会同时用五种字体特效。
翻车二:风格参数堆叠 → 模型进入"模拟风格"状态,而不是做好内容本身

摄影向的典型翻车:85mm f/1.2、shallow depth of field、Kodak Portra 400、film grain、cinematic tone……相机参数堆太多,模型会把重点放在"模拟某种相机效果"上,而不是自然呈现画面本身。于是过强虚化、假胶片颗粒、过度调色——看着像套了一层摄影滤镜,而不是一张真实的照片。
但这个问题不止摄影有。做海报也一样。你写 Swiss minimalist、Japanese wabi-sabi、brutalist typography,三种设计流派塞进一张图,模型不会挑一个执行——它会试图融合所有风格,结果每个流派的特征都剩一点,拼在一起什么都不像。
翻车三:描述方向互相冲突 → 妥协渲染 → 什么都不像
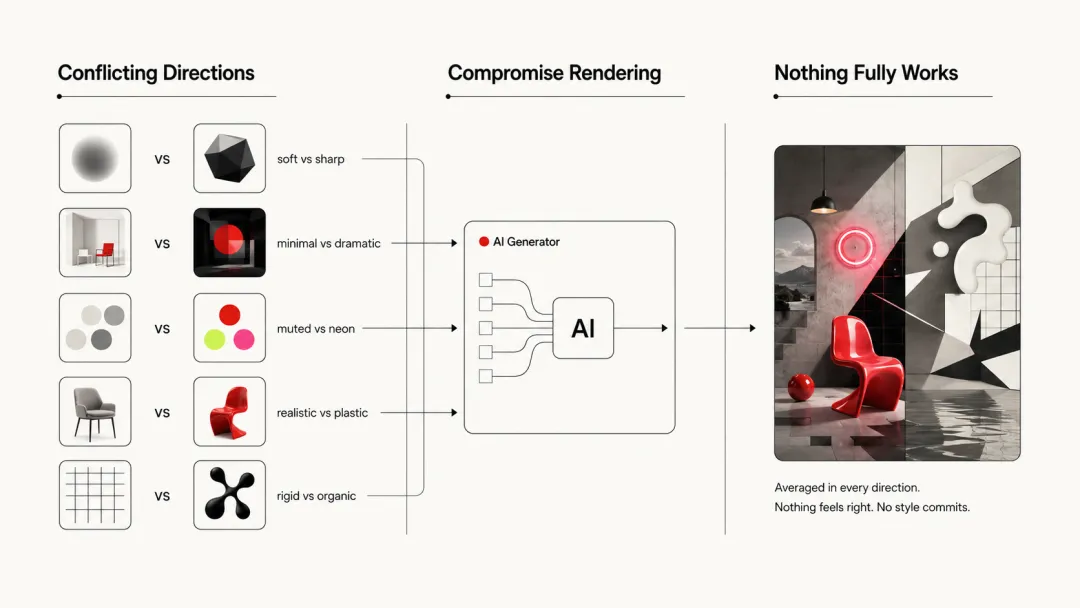
这是最隐蔽的问题。做人像时,长提示词里经常同时出现:"自然皮肤纹理" + "胶片颗粒" + "锐利对焦" + "电影级光影"。模型被迫找折中——皮肤既想真实又像塑料,画面既想柔和又被锐化。
做海报也一样。你同时要求 bold dramatic typography + subtle minimal text + vibrant neon colors + muted earth tones + geometric rigid layout + organic flowing composition——模型没法决定这张海报到底是什么性格,最后每个方向都执行三分之一,拼出一张谁看了都记不住的东西。
⚡ 关键洞察
**不是模型没理解你的需求,而是你给了太多方向,它只能平均执行。** 就像你跟厨师说"我要这道菜又辣又甜又酸又咸又清淡又浓郁"——厨师没法同时满足,最后端上来的东西,什么味都有,什么味都不对。
2. 核心原则:一个提示词=一个核心意图
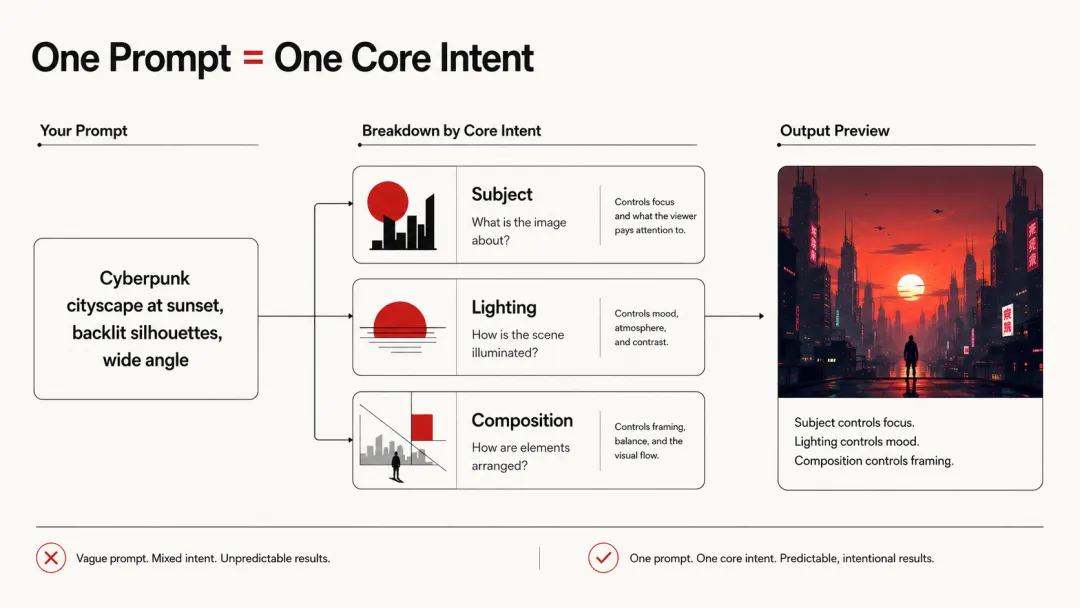
好的提示词设计,应该从一个核心意图出发。不是"我要一张赛博朋克城市夕阳逆光广角低角度仰拍蓝色主调高对比度电影感8K分辨率Unreal Engine渲染by Syd Mead by Blade Runner 2049的图"。
而是:
"Cyberpunk cityscape at sunset, backlit silhouettes, wide angle"
三个元素,足够了。
为什么?因为这三个元素已经定义了:- 主题:赛博朋克城市(cyberpunk cityscape)- 光照:夕阳逆光(sunset, backlit)- 构图:广角(wide angle)
剩下的——色彩、对比度、渲染风格——模型会根据这三个核心元素的逻辑关系自动推断。赛博朋克+夕阳,模型知道要用冷暖对比(这是赛博朋克的美学基础)。广角+城市,模型知道要强调透视。你不需要手动指定"高对比度",模型会从"backlit"和"cyberpunk"的关联中推导出来。
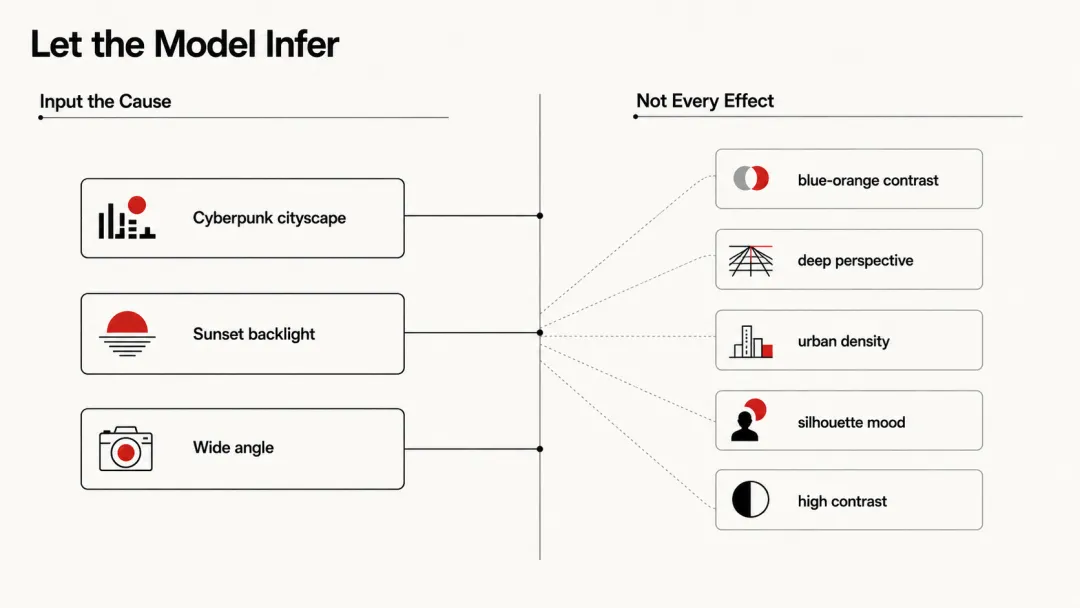
Less is more 在提示词设计中的第一定律:让模型推断,不要手动指定它能自己推导的东西。
这话听起来有点反直觉。你可能会想:"我不管,我就是要指定,这样才可控。" 但其实恰恰相反——你指定得越多,模型越混乱,你越不可控。
3. 不同模型,不同策略
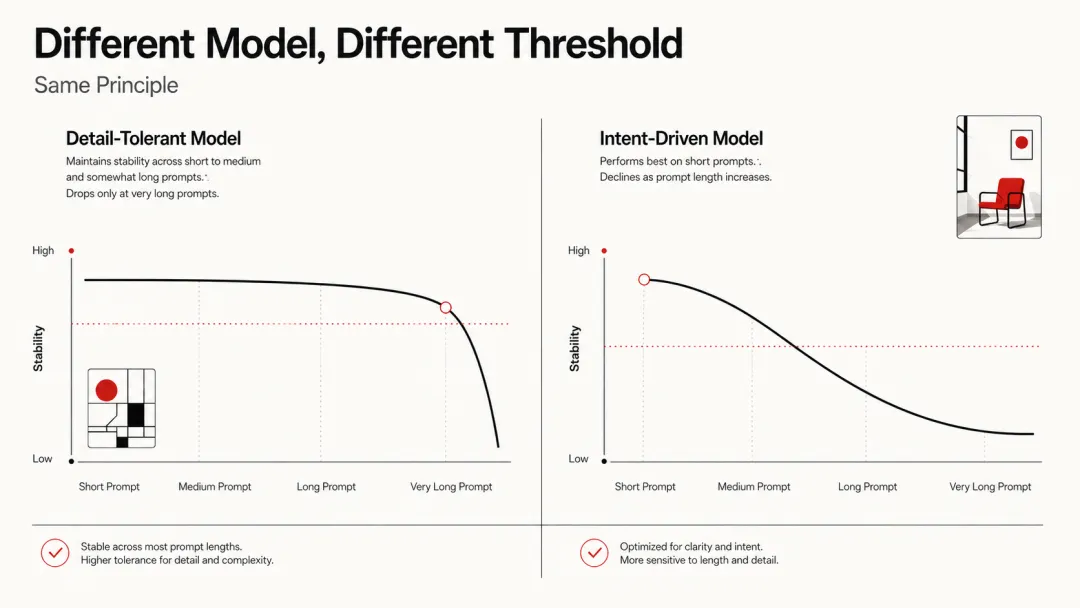
这里要补充一个重要的点:不同的文生图模型,对提示词长度的耐受度不同。
94大佬做过一个很扎实的对比:同一套"Nano Banana风格"的长提示词(300+字,堆满了皮肤纹理、胶片颗粒、85mm镜头、F1.2光圈、8K、masterpiece……),在Nano Banana上跑出来的效果还不错,但直接拿去跑GPT-Image-2,画面就开始出现塑料感、不自然锐化、多余噪点。
为什么?因为不同模型的"理解方式"不一样:- Nano Banana 类模型:可以适度丰富描述,强调细节和风格堆叠,它能在多层参数中找到平衡- GPT-Image-2 类模型:更擅长理解整体意图,给它一个清晰的方向,它自己补全细节。堆得越多,越容易跑偏
这就像不同性格的厨师:有的厨师喜欢你把每道工序都交代清楚,他照着做;有的厨师你只需要说"做一道川菜",他自己发挥反而更好。你给后者一份详细菜谱,他反而被束缚住了。
但不管哪个模型,"Less is More"的基本原则都是对的——区别只是"少到什么程度"。在所有模型上,删掉重复的、冲突的、多余的词,效果都会提升。只是GPT-Image-2对"冗余"的容忍度更低而已。
4. 权重的显式控制:用更少的词获得更多控制
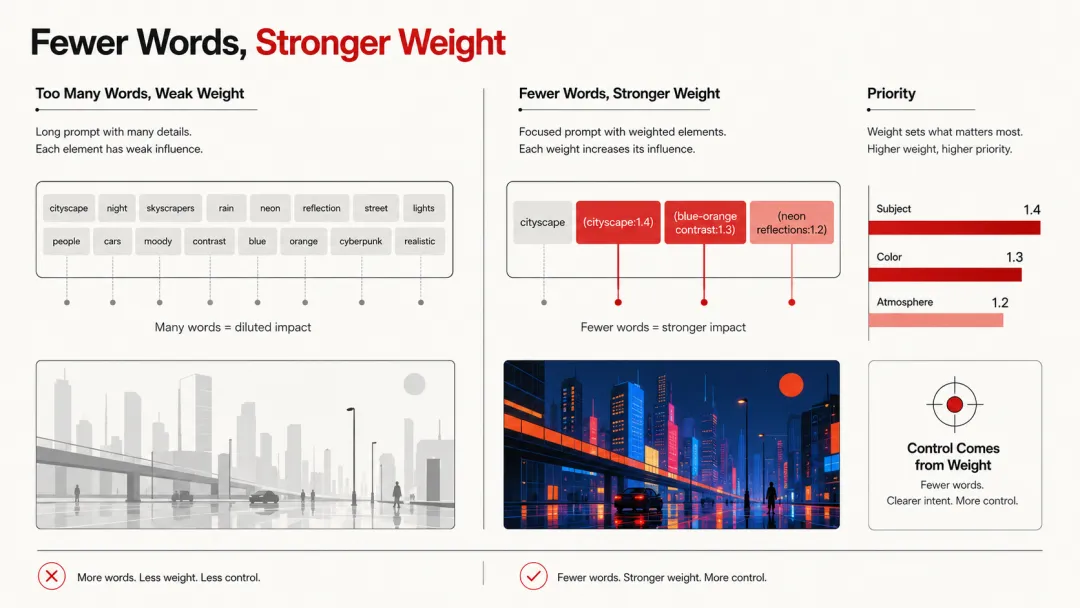
很多人以为"控制力"来自"更详细的提示词",并非如此。
真正的控制力来自权重语法——用更少的词,但让每个词都"说得起分量"。
大多数文生图模型支持类似这样的语法:- (keyword:1.5) —— 这个词权重×1.5(让它更突出)- [keyword] —— 降低这个词权重(让它靠边站)- keyword1 : keyword2 —— 强调两者的关联
提醒:不同平台对权重语法的支持并不一致。有些模型会严格解析,有些只是弱理解,甚至完全不支持。尤其是 GPT-Image 系列,对传统 Stable Diffusion 权重语法的执行方式未必相同。权重语法不是万能按钮,它的核心价值始终是:让你明确优先级。
所以与其写一段300字的提示词,不如写80个字,但用权重语法精确控制哪几个元素是关键。这就像你跟团队布置任务——不是写3000字的PRD,而是说"这个项目,用户体验是最重要的,占50%优先级;性能次之,占30%;文档最后,占20%。"

例子对比:
❌ 冗长提示词(300字)——这是很多人会写的:
"A highly detailed cyberpunk cityscape at sunset with backlit silhouettes of buildings and people, wide angle lens, low angle looking up, blue and orange color grading, high contrast cinematic lighting, volumetric fog, neon signs in Chinese and English, flying cars, rain-soaked streets reflecting neon lights, 8K resolution, Unreal Engine 5 render, Octane render, ray tracing, by Syd Mead, by Ridley Scott, Blade Runner 2049 style, cyberpunk 2077 aesthetic, anamorphic lens flare, bokeh, shallow depth of field, rule of thirds composition..."
问题在哪?- 太多艺术家风格冲突(Syd Mead vs Ridley Scott vs Blade Runner 2049——模型不知道听谁的,最后搞出个四不像)- 太多技术参数(8K、UE5、Octane、ray tracing——重复表达同一件事:"我要高质量",说一遍就够了)- 太多描述性形容词稀释核心意图("highly detailed"、"cinematic"、"dramatic"——这些词互相抢权重)
✅ 精简提示词(80字)——Less is more原则的实战:
"(cyberpunk cityscape:1.4), sunset backlight, wide angle, (neon reflections on wet street:1.2), volumetric fog, (blue-orange color contrast:1.3), shallow DOF"
差别在哪?- 核心意图明确:赛博朋克城市、夕阳逆光、广角- 用权重语法强调关键元素:城市景观×1.4权重(这是主角)、霓虹倒影×1.2(这是氛围担当)、色彩对比×1.3(这是情绪基调)- 删掉冲突的艺术家参考(选一个就够了,或者不选——让模型自由发挥)- 删掉重复的技术参数(8K、UE5、Octane 都在说同一件事:"我要高质量",说一遍就行)
上篇到这里。我们聊了"少即是多"从建筑到平面设计的脉络,以及它在AI提示词设计中的理论根基:权重稀释、妥协渲染、核心意图、模型差异、权重控制。
💡 上篇核心启示
提示词必须有主次。少,不是少写;而是少写那些会稀释核心意图、制造方向冲突、让模型进入妥协渲染的内容。
下篇我们进入实战——负面提示词怎么精简、什么是"高信号关键词"、提示词设计的完整操作清单、两个翻车案例对比、为什么大多数人都做反了,以及从"Less is More"到"Just Enough"的迭代方法。
