 夜雨聆风
夜雨聆风开篇:当基础模型遇到现实世界
想象这样一个场景:
你正在用 GPT-4o 写代码,突然想查一下某个内部 API 文档。于是你:
打开浏览器
登录内部文档系统
搜索 API 名称
复制内容
切换回聊天窗口
粘贴给 AI
这一套流程下来,你已经浪费了至少一分钟。
如果有一天你只需要说一句:"帮我看看这个接口的定义",AI 就能自动去文档库里找到答案呢?
这就是 Skill(技能) 要解决的问题——让大模型具备连接真实世界的能力!
一、核心概念:什么是 Skill?
用最简单的话来说:
Skill 就是插在大模型身上的"超能力模块" —— 让模型能做它原本做不到的事情:查询数据库、调用API、操作文件、发送邮件、执行代码……
一个类比理解
把大语言模型想象成一个刚出生的婴儿——
维度 | 原始状态 (LLM) | 装备 Skill 后 |
知识来源 | 训练数据内的静态知识 | 可实时获取最新信息 |
操作能力 | 只会"说话"(生成文本) | 可以"做事"(调用工具) |
信息边界 | 训练截止日期前的数据 | 连接任何可访问的数据源 |
专业性 | 通才样样懂一点 | 通过特定技能成为专家 |
就像一个普通人穿上钢铁侠的战甲后就能飞天遁地一样——
原始 LLM = 普通人 (聪明但只能聊天)
Skill 集合 = 战甲装备库
装上某几个 Skill 的 Agent = 特定领域的超级英雄
Skill 的核心组成要素
每个完整的 Skill 通常包含以下几个部分:
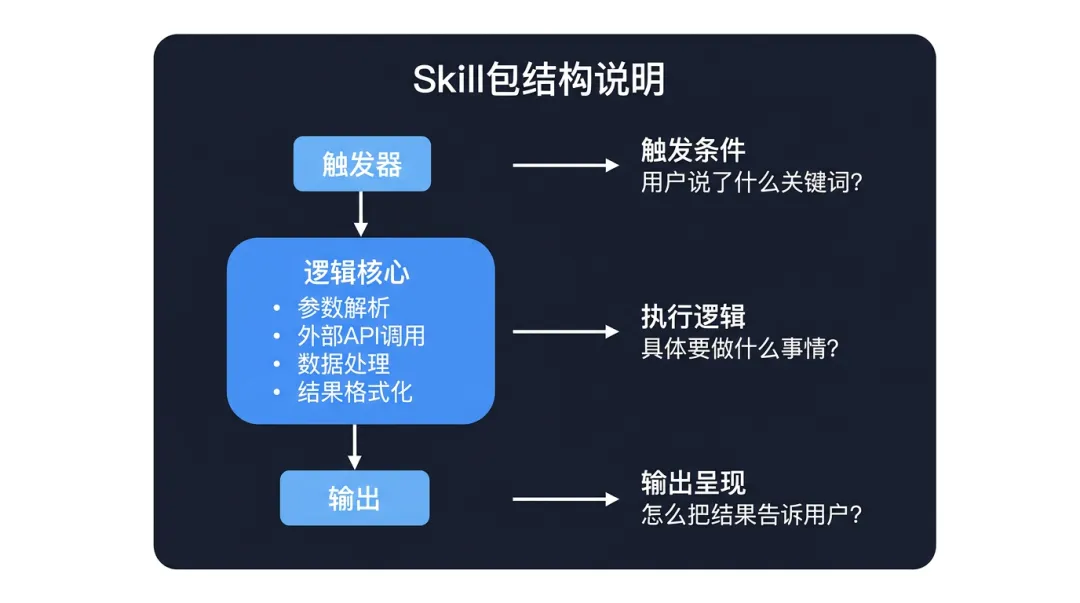
让我们拆解来看每一个部分:
1. Trigger(触发器)
这是决定何时激活该 Skill 的规则集。
# 示例触发配置
triggers:keywords:- "周报"- "写周报"- "我的工作总结"patterns:- regex: "(今天|本周)的工作"- intent: "report_generation"# 更高级的语义匹配semantic_match: truethreshold: 0.85 # 相似度阈值
常见的触发方式有三种:
精确关键词匹配:"邮件"、"日历"、"搜索"
正则表达式模式识别:提取邮箱地址、URL、时间表达式等
意图分类器:通过 NLP 模型判断用户想要做什么类型的事
2. Logic Core(逻辑内核)
这是 Skill 实际干活的部分。
通常由以下几种实现方式之一构成:
类型 | 适用场景 | 示例技术栈 |
脚本型 | 固定流程的操作任务 | Python/Node.js/Shell 脚本 |
工具链型 | 组合多个外部服务 | HTTP Client、Database Driver |
Agent 型 | 复杂的多步决策场景 | LangChain/LlamaIndex 工作流 |
以一个简单的 Python 型 Skill 为例:
class WeatherQuerySkill(Skill):name = "weather_query"description = "实时天气查询助手"def __init__(self, api_key: str):self.client = OpenWeatherMapClient(api_key)def execute(self, city_name: str) -> dict:"""从外部 API 获取天气数据并格式化返回"""raw_data = self.client.get_current_weather(city_name)return {'temperature': f"{raw_data['temp']}°C",'condition': self._translate_condition(raw_data['weather']),'humidity': f"{raw_data['humidity']}%",'wind': f"{raw_data['speed']} m/s",'suggestion': self._generate_advice(raw_data)}def _translate_condition(self, code: int) -> str:"""将气象代码转为中文描述"""mapping = {200: "雷阵雨", 800: "晴朗",# ...更多映射关系...}return mapping.get(code, "未知")def _generate_advice(self, data: dict) -> str:"""根据天气情况给出建议"""if data['temp'] < 10:return "记得多穿件衣服哦~"elif data['rain'] > 0:return出门别忘了带伞!"else:return "今天是个好天气!"
3. Output Formatter(输出格式化器)
如何将 Skill 返回的结果自然地融入对话中?
常见策略包括:
直接注入式:直接替换回复中的占位符
摘要提炼式:从大量结果中抽取关键点
交互引导式:提供选项让用户进一步选择
二、技术架构视角下的 Skill 系统
单体 vs 分布式设计
【单体部署】所有 Skill 都在同一个进程中运行优点:性能好、无网络开销、调试方便缺点:扩展难、故障影响面广、资源隔离差【分布式部署】Skill 作为独立微服务运行优点:弹性伸缩、独立升级、资源按需分配缺点:引入网络延迟、需要注册中心和服务发现机制
主流平台大多采用混合方案:
核心高频 Skill 本地化部署(如代码补全)
低频或重量级 Skill 远程服务化(如数据分析报表)
数据流全景图
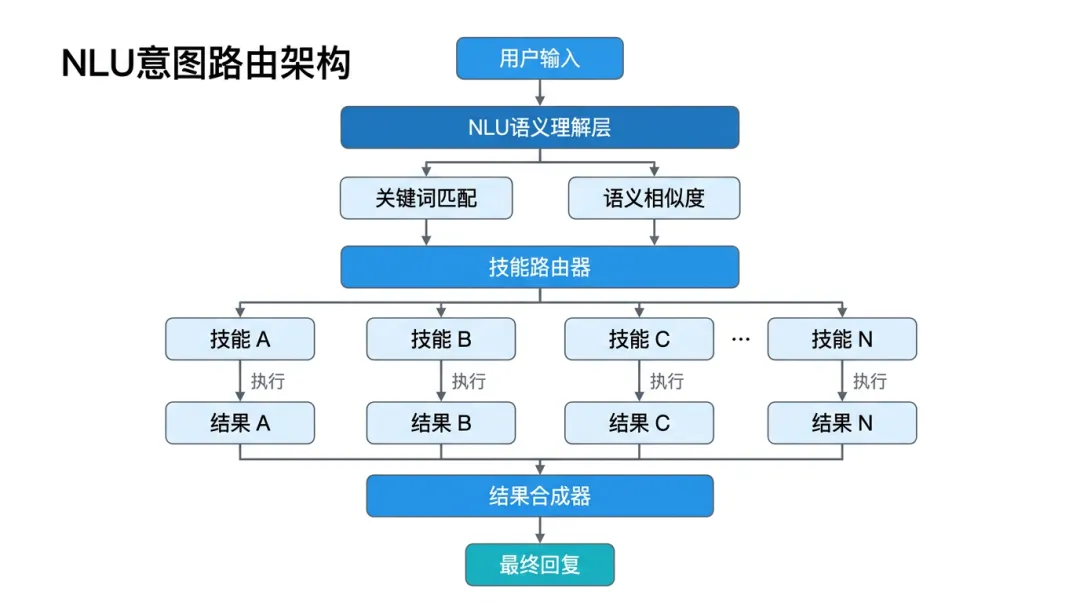
关键组件说明:
NLP Understanding Layer: 自然语言理解层,负责解析用户输入的真实含义
Intent Classifier: 将用户的请求映射到预定义的意图类别上
Skill Router: 决定激活哪些 Skill 来完成当前请求的核心引擎
Response Synthesizer: 整合多个 Skill 的输出形成连贯的自然语言回复
三、如何判断是否需要一个新 Skill?
并不是每件事都需要开发专门的 Skill!以下是一些决策原则:
应该创建 Skill 的情况
✅ 该操作会被多次重复使用✅ 有明确清晰的输入输出接口定义✅ 涉及复杂的外部系统集成逻辑✅ 存在一定的业务价值且值得投入维护成本
示例:
定期拉取团队周报并做趋势分析
监控生产环境告警并自动派单
解析非结构化的会议纪要提取行动项
不应该创建 Skill 的情况
❌ 只是偶尔用到一次性的小动作❌ 用简单的 Prompt 就能让现有模型完成的任务❌ 维护成本远高于收益的场景❌ 已有类似功能的现成可用 Skill
示例:
问一句当前几点钟(内置函数即可)
把一段文字翻译成英文(GPT 自己就会)
统计一篇文档的字数(本地命令 wc 即可)
总结
Skill 是大模型的扩展器官 —— 它弥补了纯文本生成与现实世界之间的鸿沟,让智能体真正变得"有用"起来。
好的 Skill 设计要做到三个统一 —— 输入输出规范统一、错误处理策略统一、日志监控标准统一;这样才能保证整体系统的稳定性。
不要过度工程化 —— 很多时候简单的 Prompt Engineering 配合一两个轻量级 Script 已经足够解决问题了。
生态共享是未来方向 —— 当大家都贡献出自己开发的优质 Skill 时,整个社区的生产力都会得到指数级提升。
安全永远是第一位的 —— 既然赋予了 Skill 接触真实系统的权限就要做好严格的权限控制和审计追踪防止被恶意利用。
今日行动建议
🎯 入门级实践打开你的对话界面尝试触发不同类型的 Skill 观察 AI 是如何在恰当的时候自动调起它们的感受一下那种无缝衔接的用户体验。
📈 进阶挑战思考一下你自己日常工作中有哪些重复性的跨系统操作可以抽象成 Skill 动手写个简单的设计草稿吧不需要写完整代码只要列出输入输出和处理流程即可。
🌟 高阶思考题如果你是公司内部的 AI 平台产品经理你会如何制定一套 Skill 开发的标准化规范确保所有人贡献出来的都能顺畅地集成到主系统中?
