 夜雨聆风
夜雨聆风
数据是AI的血液!云端海量存储,搞定全域数据沉淀与长效复用
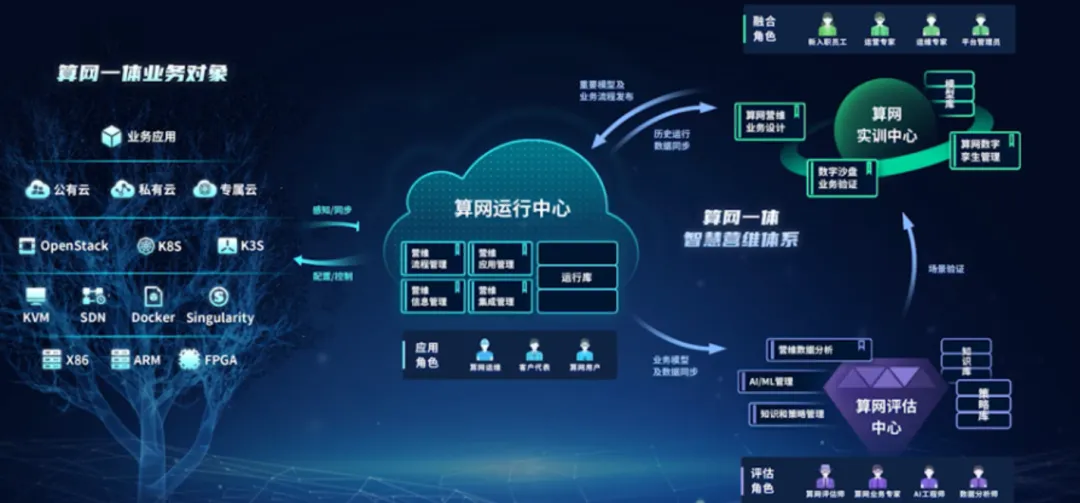
AI产业有一句核心真理:算力决定速度,数据决定精度,存储决定上限。所有智能迭代、模型优化、数据决策的前提,都是海量、完整、长效、高质量的数据沉淀。边缘节点受限于硬件容量、运行场景、算力配置,仅能实现短时、少量数据的本地缓存,无法支撑全域、长期、海量的数据存储需求。而云端凭借超大容量、多源适配、安全可靠、长效留存、弹性扩容的存储能力,成为全域数据沉淀的唯一核心载体,为AI训练、大数据分析、智能迭代筑牢数据底座。
随着万物互联落地,全域终端设备每日产生海量异构数据,工业工况数据、高清视频数据、传感监测数据、用户行为数据、医疗影像数据、交通路况数据体量爆发式增长,单行业年度数据沉淀可达PB甚至ZB级别。这类海量数据种类繁杂、格式多元、时效性不同、价值各异,普通本地存储、边缘存储完全无法承载。边缘存储容量有限,仅能留存短时关键数据,大量原始数据、历史数据、低频数据会被自动清理,导致数据断层、无法溯源、无法长效复用,直接制约AI模型训练精度与大数据分析效果。
云端海量存储彻底解决数据留存难题,构建全域一体化数据存储体系。当下主流云端采用数据湖、数据仓库、湖仓一体架构,可无缝兼容结构化、非结构化、半结构化所有类型数据,无论是文本、数值、图片、视频、音频、日志数据,都可统一接入、统一存储、统一管理。区别于传统分散存储的碎片化问题,云端实现全域数据集中沉淀、统一归档、分类管理,彻底打破数据孤岛,让跨场景、跨设备、跨区域的数据互通与复用成为可能。
云端存储的核心优势不止于容量大,更在于弹性适配与长效可靠。云端存储支持按需扩容,无需硬件改造、无需停机升级,可跟随企业数据增长动态扩充容量,完美适配数据爆发式增长需求,杜绝存储容量不足导致的数据丢失。同时云端采用多副本备份、异地容灾、智能容错机制,数据多节点备份存储,硬件故障、区域波动不会造成数据丢失,数据存储可靠性远超本地与边缘存储,满足政企、工业、金融、医疗等高可靠数据留存需求。
对于AI产业而言,云端长效数据沉淀是模型迭代的核心基础。AI大模型、行业垂类模型的训练与优化,极度依赖海量历史数据、全场景真实数据。短期单点数据只能训练出基础模型,只有依托云端数年积累的全域数据、时序数据、场景数据,才能持续微调模型参数、修正识别偏差、提升决策精度。可以说,云端存储沉淀的海量高质量数据,就是AI智能进化的核心养分,没有云端长效数据积累,AI模型就无法持续迭代优化,智能能力会快速固化落后。
在企业数字化经营中,云端存储实现数据全生命周期价值挖掘。云端不仅负责数据存储,还配套数据分类、归档、检索、溯源、清理一体化能力,可精准区分高价值实时数据、低频历史数据、无效冗余数据,实现数据分层存储、分级管理、按需调用。高频业务数据快速调取使用,低频历史数据长效归档留存,既保障业务响应效率,又节省存储成本,同时为企业大数据复盘、趋势分析、风险溯源、战略规划提供完整数据支撑。
行业数据显示,依托云端湖仓一体存储架构,企业数据存储综合成本可降低30%-50%,数据调取效率提升40%以上,数据丢失率无限趋近于零。相较于边缘短期缓存、本地固定存储,云端存储在容量、可靠性、兼容性、性价比、长效性上具备全方位碾压优势,是全域数据沉淀、AI智能迭代、企业数字化经营的刚需底座。
未来智能产业的竞争,本质是数据资源的竞争,而数据竞争的核心前提是数据留存能力。只有依托云端海量存储体系,完整沉淀全域数据、长效留存场景数据、高效盘活历史数据,才能持续为AI训练、大数据分析赋能,让数据真正转化为企业核心生产力与核心竞争力。

免责声明 :
本文档可能含有预测信息,包括但不限于有关未来的财务、运营、产品系列、新技术等信息。由于实践中存在很多不确定因素,可能导致实际结果与预测信息有很大的差别。因此,本文档信息仅供参考,不构成任何违约或承诺。可能不经通知修改上述信息,恕不另行通知。
