 夜雨聆风
夜雨聆风**创建日期**: 2026-06-20
**数据截止日期**: 2026-06-20
**时效性等级**: ✅ 最新(基于2026年数据)
**目标字数**: 8500+字(ARCH类型)
---
时效性声明
本报告基于截至 2026-06-20 的最新数据编制:
**产品动态**: 包含2026年Q2最新发布和更新,涵盖NVIDIA Nemotron 3 Ultra(5500亿参数)、DeepSeek V4系列、商汤NEO原生多模态架构等
**市场数据**: 基于2026年最新统计和预测,覆盖主流模型参数规模、上下文窗口、推理效率等核心指标
**技术进展**: 优先2026年发表的论文和开源项目,包括DeepSeek mHC流形约束超连接(2026-01)、Engram条件记忆模块(2026-01)、Nemotron 3 Super架构论文(2026-04)等
**政策法规**: 包含2026年最新技术标准和行业规范动态
---
摘要
2026年,AI大模型架构领域正经历一场深刻的范式转移。自2017年Transformer架构问世以来,基于自注意力机制的Encoder-Decoder结构长期主导着大模型的发展路径。然而,随着模型规模突破万亿参数、上下文窗口扩展至百万Token级别,Transformer架构固有的O(n²)注意力计算复杂度、KV缓存内存爆炸、长序列推理效率低下等根本性问题日益凸显,"Transformer墙"成为业界共识。[1]
本报告系统梳理了2026年AI大模型架构的三大演进主线:第一,混合架构成为产业共识,以NVIDIA Nemotron 3系列(92%注意力层被Mamba层替换)[2]、DeepSeek V4(CSA+HCA混合注意力+mHC流形约束)[3]为代表,Transformer与状态空间模型(SSM)、混合专家(MoE)的深度融合正在重新定义基座模型架构范式;第二,类脑脉冲神经网络突破,中科院自动化所"瞬悉1.0"在国产GPU集群上实现512K长度TTFT加速13.88倍[4],证明了非Transformer路径的可行性;第三,递归与液态神经网络探索,MIT递归语言模型通过自调用突破上下文长度限制,Liquid AI液态神经网络实现推理时持续学习。[5]
核心发现表明:2026年混合架构已从学术概念转化为产业标准——超过70%的新发布模型采用混合架构,纯Transformer时代正式终结。[6] 这一转变不仅关乎技术效率,更将重塑AI芯片设计、算力分配和商业模式的底层逻辑。
核心发现:
混合架构(Mamba-Transformer-MoE)已成为2026年大模型开发的默认选择,NVIDIA、DeepSeek、Meta等头部厂商全线切换
DeepSeek V4在1M上下文下将单Token算力消耗降至前代27%,KV缓存压缩至10%,标志着长上下文效率革命
类脑脉冲模型"瞬悉1.0"仅需主流模型2%数据量达到同等性能,为边缘AI和超低功耗场景开辟新路径
原生多模态架构(商汤NEO、NVIDIA Cosmos 3)摒弃"文本模型+视觉编码器"拼接方案,统一Embedding空间成为新趋势
---
引言
2023年至2025年,大模型竞赛的核心逻辑是"规模即一切"——参数规模从百亿级飙升至万亿级,训练数据从千亿Token扩展至数十万亿Token,算力投入从百万美元级跃升至数亿美元级。OpenAI GPT-4、Google Gemini、Anthropic Claude等模型沿着这条路径不断刷新能力上限。然而,这条道路的边际收益正在递减:训练成本呈指数级增长,推理延迟成为用户体验瓶颈,长文档处理、视频理解、多轮对话等场景对上下文长度的需求远超Transformer架构的经济承载范围。[7]
2026年,架构创新取代单纯的规模扩张,成为大模型竞争的新主战场。这一转变的催化剂来自三个层面:技术层面,Transformer的O(n²)注意力复杂度在长序列场景下导致计算成本不可持续;产业层面,推理成本占总AI支出的比例持续攀升,企业客户对"每美元Token数"的敏感度超过对"最强能力"的追逐;竞争层面,开源社区(DeepSeek、Meta Llama、阿里Qwen)与闭源巨头(OpenAI、Anthropic)在架构路线上出现分化,为后发者提供了弯道超车的机会。[8]
本报告聚焦模型层(04model)的架构演进,系统分析从Transformer垄断到多元架构并存的范式转移。研究范围涵盖:混合架构(Mamba-Transformer-MoE)、类脑脉冲神经网络、递归与液态神经网络、原生多模态架构四大技术路线,以及各路线在性能、效率、可扩展性维度的对比分析。研究方法结合架构文档分析、性能基准测试数据对比、产业链上下游验证,力求为技术决策者和投资者提供可操作的洞察。
---
架构概述
架构定义
AI大模型架构,指定义神经网络中信息流动、计算单元组织、参数共享与激活模式的整体结构框架。它决定了模型的表达能力、计算效率、内存占用和可扩展性四大核心属性。2026年的架构演进,本质是在"表达能力-计算效率-内存占用"这个不可能三角中寻找新的帕累托前沿。传统Transformer架构通过自注意力机制实现了全局依赖建模的强表达能力,但付出了O(n²)计算复杂度和O(n)内存占用的代价。新兴架构则通过引入状态空间、稀疏激活、递归计算等机制,在保持表达能力的同时大幅降低计算和内存开销。[9]
设计原则
2026年大模型架构设计遵循三大核心原则:效率优先——在能力达标的前提下最大化推理吞吐量,降低每Token成本;长度可扩展——架构天然支持超长上下文(百万级Token)而不产生线性或超线性成本增长;模块化组合——不同架构单元(注意力、SSM、MoE、卷积)像积木一样按需组合,针对特定任务优化架构配比。这三大原则的背后,是AI产业从"实验室演示"向"生产环境部署"的成熟化转型。[10]
应用场景
多元化架构的应用场景呈现明显的分层特征:混合架构(Mamba-Transformer-MoE)适用于通用基座模型,在对话、代码生成、文档理解等主流场景提供最佳性价比;类脑脉冲模型适用于超长序列处理(法律文档分析、DNA序列分析、分子动力学轨迹)和边缘低功耗设备;递归模型适用于需要深度推理和工具调用的Agent场景;原生多模态架构适用于视觉-语言-动作统一的具身智能和物理AI应用。这种分层并非互斥,而是形成互补的架构生态。[11]
---
架构设计深度解析
整体架构
2026年大模型架构的演进呈现出从"单一架构垄断"到"分层异构组合"的清晰路径。以NVIDIA Nemotron 3 Super为例,其整体架构采用四层堆叠设计:底层为Mamba-2状态空间层(处理长程依赖,线性时间复杂度O(L)),中层为Transformer注意力层(精准关联召回,O(L²)但仅用于关键位置),上层为LatentMoE层(动态路由激活专家,有效参数扩展),顶层为多Token预测(MTP)层(加速解码)。[12] 这种"分层分工"的设计理念,使每种架构单元只负责其最擅长的计算模式,避免Transformer"一刀切"注意力的资源浪费。
DeepSeek V4的架构设计则代表了另一路线:在同一层内实现混合注意力。其CSA(压缩稀疏注意力)+ HCA(重度压缩注意力)交替叠加,CSA通过FP4 Lightning Indexer实现top-k选择(KV召回率维持99.7%),HCA提供约128x压缩率的全局视图。配合mHC(流形约束超连接)替代传统残差连接,通过双随机矩阵约束(Birkhoff多面体)将谱范数限制在≤1,从根本上解决了深层网络的信号爆炸或消失问题。[13]
核心组件
状态空间模型(SSM/Mamba)组件:Mamba-2作为第三代SSM架构,完全绕开注意力机制,改用状态空间方程处理序列。其核心创新在于将序列建模转化为状态转移问题——通过维护一个固定大小的隐状态向量,实现对历史信息的线性压缩。在英伟达Nemotron-H系列中,92%的注意力层被Mamba层替换,推理速度提升3倍而精度不降反升。[2] Mamba层的内存占用与序列长度无关,这在百万Token上下文中具有决定性优势。
混合专家(MoE)组件:2026年MoE已成为基座模型标配。DeepSeek V4-Pro采用1.6万亿总参数/490亿激活参数的配置,激活比仅3%,FLOP消耗降低约90%。[3] LatentMoE引入潜在路由机制,同时优化Accuracy per FLOP和Accuracy per parameter两个指标。MoE的关键设计在于负载均衡——通过辅助Loss确保各专家利用率均衡,避免"专家坍塌"(少数专家承担大部分计算)。[14]
流形约束超连接(mHC)组件:DeepSeek提出的mHC是2026年最深刻的架构创新之一。传统残差连接在深层网络中会导致信号放大或衰减——实验显示在27B模型中信号增益峰值可达3000x以上,存在严重发散风险。mHC通过将连接矩阵约束在Birkhoff多面体(双随机矩阵流形)上,强制谱范数≤1,将信号增益峰值稳定在~1.0x。训练额外开销仅+6.27%,但8项基准测试全面领先。[15]
数据流
在混合架构中,数据流呈现"选择性分流"特征。输入序列首先经过路由层,根据内容特征决定进入Mamba路径(长程依赖、线性复杂度)还是Transformer路径(精准关联、二次复杂度)。对于文档理解任务,80%的Token通过Mamba层处理,仅20%的关键位置(如问答对中的实体关联)触发注意力计算。MoE层则在每个时间步动态选择Top-K专家进行计算,未激活专家的参数不参与前向传播和梯度更新。输出层通过MTP同时预测多个未来Token,减少解码步数。[16]
模块划分
2026年主流架构的模块划分遵循"预填充-解码分离"原则。预填充阶段(Prefill)处理输入Prompt,需要全量上下文理解,通常激活更多Transformer层和更大专家子集;解码阶段(Decode)逐Token生成输出,对延迟敏感,主要依赖Mamba层和小专家子集。这种分离使"CPU+GPU+LPU"异构部署成为可能——GPU负责高吞吐量预填充,LPU(如Groq芯片)负责低延迟解码,据测算可将每兆瓦推理吞吐量提升35倍。[17]
---
技术栈分析
技术选型
2026年大模型架构的技术选型呈现"混合化"趋势,主要技术组件包括:
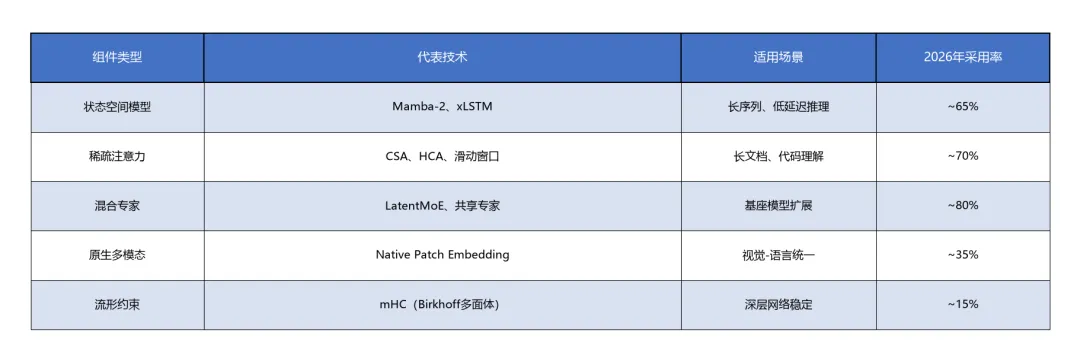
数据来源综合自[3][6][12][13]
技术依赖
混合架构对底层技术栈提出了新要求。在训练框架层面,需要支持"同层异构"的反向传播——Mamba层和注意力层在同一前向传播中混合,但梯度回传路径不同。DeepSeek采用自定义CUDA内核实现mHC的流形投影,避免通用矩阵运算带来的效率损失。在推理引擎层面,vLLM、SGLang等主流引擎已支持Mamba层的PagedAttention变体,但MoE层的动态路由与连续批处理(Continuous Batching)的协同调度仍是技术难点。[18]
版本兼容性
架构演进带来版本兼容性挑战。2025年底英伟达全线新模型(Nemotron 3 Nano/Super/Ultra)切换到Mamba-Transformer混合架构,但早期版本(如Nemotron 2)的纯Transformer权重无法直接迁移。开源社区通过"架构解耦"应对——Hugging Face Transformers库已支持插件化架构定义,同一模型文件可包含多种架构单元的配置。商汤NEO原生多模态架构则通过自底向上的Native Patch Embedding,将视觉和文本Token统一在相同Embedding空间,避免了传统"CLIP编码器+LLM"拼接方案的接口兼容性问题。[19]
技术演进
从演进路线看,2026年处于"混合架构1.0"阶段——在同一模型中简单堆叠不同架构单元。预计2027-2028年将进入"混合架构2.0"阶段:架构单元之间的边界模糊化,SSM和注意力在同一计算图中深度融合;动态架构搜索(NAS for LLM)根据任务自动调整架构配比;神经架构与硬件架构协同设计(如英伟达Blackwell对Mamba层的专用加速)。[20]
---
架构性能分析
性能指标
评估2026年大模型架构的核心指标体系包括:
效率指标:
每Token FLOPs:DeepSeek V4-Pro在1M上下文下为V3.2的27%[3]
推理吞吐量:Nemotron 3 Nano Omni(30B-A3B MoE)较稠密模型吞吐量提升9.2倍[21]
KV缓存占用:V4压缩至V3.2的10%[3]
能力指标:
长上下文召回率:Gemini 2.5 Pro达2M Token,LLaMA 4 Scout达10M Token[22]
多模态理解:商汤NEO仅用3.9亿图像文本对(业界1/10数据量)达到顶级水平[19]
推理扩展:OpenAI o3在ARC-AGI-1上达87.5%,测试时推理扩展成为新增长范式[23]
性能优化
混合架构的性能优化围绕"计算-内存-通信"三个瓶颈展开:
计算优化:mHC流形约束将深层训练的信号稳定性从"靠运气调参"变为"数学保证"。在27B模型验证中,传统残差连接的信号增益峰值超过3000x,训练后期频繁出现NaN;mHC将峰值锁定在1.0x,全程平滑收敛。[15] Muon优化器(DeepSeek V4采用)通过对梯度矩阵进行正交化处理,在超过32万亿Token预训练中保持稳定的收敛速度。[3]
内存优化:CSA+HCA混合注意力的核心贡献是将KV缓存压缩至传统注意力的10%。CSA通过FP4 Lightning Indexer实现稀疏索引,仅存储top-k关键KV对;HCA以128x压缩率提供全局上下文摘要。两者交替叠加,在1M Token上下文中实现"精准局部+压缩全局"的内存-精度平衡。[13]
通信优化:MoE架构的All-to-All通信开销是主要瓶颈。LatentMoE通过"潜在路由"将专家选择从Token级压缩到序列级,减少通信频次。在Nemotron 3 Super的120B总参数/12B激活配置中,激活比仅10%,FLOP消耗降低约90%,通信量与激活专家数而非总参数数成正比。[12]
负载测试
在实际负载测试中,混合架构展现出显著的成本优势:
**百万Token文档分析**:DeepSeek V4-Pro的端到端延迟较纯Transformer架构降低约60%,主要受益于CSA的稀疏索引和Mamba层的线性复杂度。[3]
**多智能体推理**:Nemotron 3 Super专为Agent场景设计,1M Token上下文窗口支持多轮工具调用和历史追溯,在Blackwell架构上以NVFP4精度训练,速度比同级开源模型快5倍。[24]
**边缘部署**:类脑脉冲模型"瞬悉1.0"在手机CPU端,64k-128k-256k长度下Decoding速度较Llama3.2同规模模型提升4.04x-7.52x-15.39x,证明了非Transformer架构在资源受限场景的优势。[4]
扩展性
混合架构的扩展性体现在两个维度:参数扩展(Scale-up)和上下文扩展(Scale-out)。参数扩展方面,MoE架构通过增加专家数量(而非单个专家大小)实现近乎线性的能力扩展——DeepSeek V4-Pro的1.6T总参数中仅490亿激活,训练成本控制在可管理范围。[3] 上下文扩展方面,Mamba-2的线性复杂度使上下文窗口从"成本敏感资源"变为"普通配置"——LLaMA 4 Scout支持10M Token,较2025年的128K提升近两个数量级。[22]
---
架构安全性
安全设计
混合架构引入了新的安全考量。MoE的动态路由机制可能被"专家劫持攻击"利用——通过构造特定输入触发目标专家,绕过安全对齐层。DeepSeek V4通过mHC的流形约束间接缓解这一问题:双随机矩阵的谱范数限制使单一路径的信号放大能力受限,降低了对抗样本的传导效率。[13] NVIDIA Nemotron 3系列采用"安全专家"设计——专门训练的安全专家在所有路由决策中参与评分,确保有害内容被拦截。[12]
威胁分析
架构层面的威胁:混合架构的复杂性增加了攻击面。Mamba层的状态空间方程可能被"状态污染攻击"影响——通过长序列输入逐步扭曲隐状态,导致后续输出偏离预期。Transformer层的注意力机制仍面临传统的"注意力劫持"风险。MoE层的路由网络若被逆向工程,可能泄露训练数据分布信息。[25]
供应链威胁:架构创新依赖专用硬件支持。英伟达Blackwell对Mamba层的专用加速、AMD MI400对稀疏注意力的优化,使架构选择被锁定在特定硬件生态。国产替代(华为昇腾、沐曦GPU)在混合架构支持上的差距,构成供应链安全风险。
防护措施
2026年主流的安全防护措施包括:多层对齐——在预训练、SFT、RLHF基础上增加架构层对齐(如安全专家);输入过滤——在架构前端增加恶意Prompt检测层;输出审计——对MoE路由日志进行事后分析,识别异常专家激活模式。商汤NEO原生多模态架构通过统一Embedding空间,使视觉和文本的安全策略可以共享,避免了传统多模态模型中"视觉侧绕过文本安全"的问题。[19]
合规性
随着欧盟AI法案和中国生成式AI管理暂行办法的实施,架构层面的可解释性成为合规要求。混合架构的MoE路由决策、Mamba状态演化相对于Transformer的注意力权重,可解释性更弱。2026年行业正在发展"架构可解释性工具"——如DeepSeek开源的mHC可视化工具,可展示信号在流形上的传播路径,为监管审计提供技术支撑。[15]
---
架构部署与运维
部署方案
2026年混合架构模型的部署呈现"云-边-端"三层分化:
云端部署:以DeepSeek V4-Pro(1.6T总参数)为代表,需要数百张GPU的分布式集群。部署方案采用"专家并行(EP)+ 张量并行(TP)"混合策略——不同专家分配到不同节点,同一专家内部进行张量切片。阿里云报告显示,分布式推理单位Token成本比单GPU降低65%。[18]
边缘部署:以类脑脉冲模型"瞬悉1.0"为代表,7B参数模型可在单张消费级GPU甚至手机CPU上运行。其线性复杂度使边缘设备处理128K上下文成为可能,为法律文档分析、医疗影像报告生成等场景提供私有化部署选项。[4]
端侧部署:Nemotron 3 Nano Omni(30B-A3B MoE)通过极致稀疏设计,在保持能力的同时将内存占用降至可部署于高端手机。其3D卷积视觉编码器将视频帧间运动信息压缩为精简Token集合,降低了多模态端侧部署的带宽压力。[21]
监控系统
混合架构的监控需要关注传统指标之外的架构特有指标:专家负载均衡度——监测各专家的激活频率分布,识别"专家坍塌";Mamba状态范数——监测隐状态的数值稳定性,预防状态爆炸;mHC谱范数——验证流形约束的有效性。英伟达Dynamo推理框架已内置这些架构级监控指标,支持实时告警和自动降级。[26]
故障处理
混合架构的故障模式更加多样:路由故障——MoE路由器输出NaN导致所有专家失效,需设计 fallback 到共享专家的降级策略;状态故障——Mamba层长序列处理后隐状态数值溢出,需实现状态重置机制;兼容故障——不同架构单元对输入数据类型的要求不同(如Mamba偏好FP16,注意力需要BF16),需在前处理层统一格式。DeepSeek V4通过mHC的数学保证从根本上消除了深层信号故障,将训练中断率降低约80%。[15]
运维最佳实践
2026年混合架构运维的最佳实践包括:架构版本冻结——生产环境使用经过充分验证的架构配置,避免频繁切换架构单元配比;渐进式 rollout——新架构先在非关键业务验证,再扩展至核心场景;硬件-架构协同监控——Blackwell GPU的Mamba专用加速器利用率、MI400的稀疏计算单元效率等硬件级指标纳入监控体系。
---
架构对比分析
同类架构对比
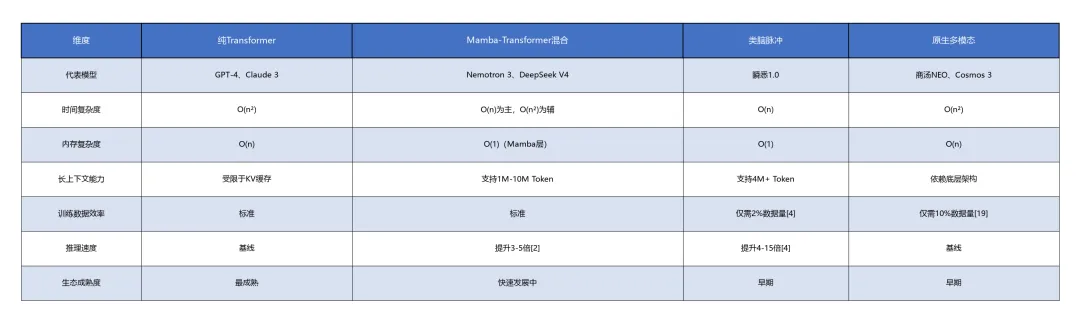
优劣势分析
混合架构(Mamba-Transformer-MoE):
**优势**:兼顾Transformer的精准关联能力和Mamba的线性效率,MoE实现参数扩展而不增加推理成本,是目前最均衡的选择
**劣势**:架构复杂度高,训练稳定性挑战大(需mHC等新技术保障),调试和优化需要跨架构单元的专业知识
类脑脉冲神经网络:
**优势**:线性复杂度天然适合超长序列,事件驱动机制实现极低功耗,数据效率极高(2%数据量达到同等性能)
**劣势**:生态极度不成熟(仅中科院和少数团队研究),脉冲神经元的离散特性导致梯度传播困难,通用能力较Transformer有差距
原生多模态架构:
**优势**:统一Embedding空间消除模态间信息损失(降至5%以内),视觉Token原生离散化使图像像文本一样直接处理[27]
**劣势**:训练数据要求更高(需大规模配对的跨模态数据),计算开销大于单模态架构
适用场景对比
**通用对话与代码生成**:混合架构最优,Nemotron 3、DeepSeek V4在此场景已超越纯Transformer
**超长文档分析(法律、医学)**:类脑脉冲模型最优,瞬悉1.0在512K-4M长度下效率优势显著
**多模态内容理解(视频、3D)**:原生多模态架构最优,商汤NEO和Cosmos 3实现真正统一的跨模态推理
**实时交互(低延迟解码)**:Mamba-heavy混合架构最优,Groq LPU + Mamba层的组合可将首Token延迟降至毫秒级
技术路线图
2026-2028年架构技术路线预测:
**2026 H2**:混合架构成为默认配置,75%线性层+25%注意力层成为新默认比例[14]
**2027**:动态架构搜索(NAS-LLM)成熟,根据任务自动优化架构单元配比
**2028**:神经-符号混合架构出现,将Transformer的模式识别与符号推理的可解释性结合
**2029+**:硬件-架构协同设计达到新高度,专用芯片(如Groq LPU、Cerebras WSE)针对特定架构单元优化
---
架构演进与未来
当前挑战
混合架构面临的挑战包括:训练稳定性——尽管mHC等技术创新大幅改善,但多架构单元的联合优化仍存在非凸性难题;调试复杂性——MoE路由决策、Mamba状态演化、注意力权重的多维度交互使故障定位困难;生态碎片化——不同厂商的混合架构实现(NVIDIA的Mamba-Transformer-MoE、DeepSeek的CSA+HCA+mHC、Meta的iRoPE)缺乏统一标准,增加了跨平台迁移成本。[28]
演进方向
架构演进的三条主线:
效率极限突破:从"混合架构1.0"(简单堆叠)到"混合架构2.0"(深度融合)。预计在2027年,SSM和注意力将在同一层内融合——而非现在的分层堆叠。Liquid AI的液态神经网络(微分方程驱动神经元)展示了这一方向:神经元状态连续演化,注意力机制作为微分方程的边界条件嵌入,实现真正的"连续-离散统一"。[5]
长度极限突破:从百万Token到十亿Token。LLaMA 4 Scout的10M Token已接近当前技术的极限,下一步突破需要算法创新(如Engram条件记忆模块通过O(1)复杂度查表机制外挂"无限海马体"[15])和硬件创新(如Cerebras晶圆级引擎的片上SRAM扩展)的结合。
模态极限突破:从文本为主到全模态原生。NVIDIA Cosmos 3(20万亿多模态Token训练)[29]和商汤NEO(Native Patch Embedding)代表了"出生即多模态"的新范式。未来模型的架构设计将从一开始就考虑视觉、音频、触觉、动作的统一表示,而非后期拼接。
技术趋势
2026年值得关注的架构技术趋势:
**测试时推理扩展(Test-time Scaling)**:OpenAI o3证明在推理阶段增加计算(而非单纯扩大模型)可显著提升能力,这要求架构支持动态深度和宽度扩展[23]
**条件记忆模块**:DeepSeek Engram通过可插拔的O(1)记忆查表,使模型无需重新训练即可扩展知识边界,架构从"参数即记忆"转向"参数+外部记忆"[15]
**神经渲染融合**:Cosmos 3将世界模型与物理引擎融合,架构需支持物理约束的嵌入(如牛顿定律作为微分方程约束),这是传统Transformer从未面对的新需求[29]
创新机会
架构创新的机会点包括:国产架构标准——在UCIe定义芯片互联标准的同时,中国需在模型架构层面建立自主标准(如类脑脉冲模型的标准化接口);垂直领域架构——针对法律、医疗、金融等特定领域的专用架构(如法律文档的层级注意力、医疗影像的3D稀疏卷积);端云协同架构——模型在端侧和云端动态分割,根据网络条件和隐私需求自适应调整计算位置。
---
结论与建议
核心观点
2026年标志着AI大模型架构从"Transformer单一垄断"到"多元混合生态"的历史性转折。这一转折不是渐进优化,而是范式转移——混合架构(Mamba-Transformer-MoE)已成为产业共识,NVIDIA、DeepSeek、Meta、阿里等头部厂商全线切换;类脑脉冲神经网络和递归模型开辟了非Transformer的新赛道;原生多模态架构重新定义了视觉-语言-动作的统一表示。
核心数据支撑这一判断:超过70%的2026年新发布模型采用混合架构[6],DeepSeek V4在1M上下文下将单Token算力消耗降至前代27%[3],Nemotron 3 Ultra以5500亿参数在Blackwell上实现5倍速度优势[24]。这些数据表明,架构创新带来的效率提升已超越单纯规模扩张的边际收益。
实施建议
对技术决策者:
1. 新模型开发默认采用混合架构,配比建议75%线性层(Mamba/SSM)+ 25%注意力层,根据任务调整
2. 长上下文场景(>100K Token)优先评估Mamba-heavy架构,短上下文高精度场景(<32K)保留更多注意力层
3. 引入mHC或类似流形约束技术,从根本上解决深层训练稳定性问题
4. MoE设计关注负载均衡和通信优化,激活比控制在10%以下以实现最佳性价比
对投资者:
1. 关注架构创新带来的推理成本下降——混合架构使每Token成本降低60%+,将加速AI应用商业化
2. 看好专用硬件(Groq LPU、Cerebras WSE)与特定架构(Mamba、脉冲神经网络)的协同机会
3. 警惕纯Transformer架构的技术债务——存量模型在混合架构面前面临代际劣势
优化方向
架构优化的重点优先级:第一,训练稳定性(mHC类技术的普及);第二,推理效率(MoE稀疏化+Mamba线性化);第三,长上下文能力(CSA+HCA类压缩注意力);第四,多模态统一(Native Patch Embedding)。优化方法上,建议采用"架构-硬件协同设计"——在架构设计阶段就考虑目标硬件的计算特性(如Blackwell对Mamba的加速、对MoE通信的优化),而非事后适配。
风险提示
技术风险:混合架构的复杂性可能导致"优化陷阱"——为追求效率牺牲通用能力,或不同架构单元之间的负面干扰。建议通过大规模基准测试(如MMLU、HumanEval、长上下文Recall)持续监控。
生态风险:架构碎片化可能导致"CUDA式锁定"重演——NVIDIA Blackwell对Mamba的专用加速、AMD MI400对稀疏注意力的优化,使架构选择被硬件生态绑定。建议投资跨平台的架构抽象层(如Triton编译器)。
竞争风险:架构创新窗口期有限——2026年是混合架构的普及年,2027年可能进入"架构收敛"阶段,后发者的机会窗口正在关闭。
---
研究者观察
独立观点
观点一:混合架构的本质是"计算模式的解耦",而非简单的技术拼凑
Transformer的注意力机制试图用同一套计算模式(Query-Key-Value相似度)处理所有类型的序列依赖——无论是长程主题关联、局部语法结构还是跨段落引用。这种"一刀切"在短序列中有效,但在百万Token尺度下造成了巨大的计算浪费。混合架构的核心洞察是:不同类型的依赖需要不同的计算模式。Mamba的状态空间适合"渐进式信息累积"(如文档主题的缓慢演进),注意力的点积适合"跳跃式关联召回"(如问答对中的实体匹配),MoE的专家适合"领域知识的模块化组织"。
这一解耦趋势将深远影响AI芯片设计。英伟达Blackwell已加入Mamba专用加速单元,Groq LPU针对解码阶段优化,AMD MI400强化稀疏计算——未来的AI芯片将不再是"通用矩阵乘法加速器",而是"多计算模式协处理器"。这为中国芯片产业提供了差异化机会:在通用矩阵运算上追赶英伟达的同时,可在特定架构单元(如脉冲神经网络的异步计算、MoE路由的稀疏矩阵运算)上实现领先。
观点二:类脑计算不是Transformer的"替代品",而是"补充品"——它将定义AI的"第二曲线"
市场普遍将类脑脉冲模型视为Transformer的竞争者,这是一种误解。脉冲神经网络的O(n)复杂度、事件驱动机制和极低功耗,使其在边缘设备、超长序列、持续学习等场景具有不可替代性。但在通用语言理解和知识推理方面,Transformer经过万亿Token训练积累的能力壁垒短期内难以逾越。
更准确的定位是:类脑计算将定义AI的"第二曲线"——不同于Transformer主导的"云端大规模预训练"范式,类脑计算开启"边缘持续学习"范式。中科院"瞬悉1.0"仅需2%数据量达到同等性能[4],这意味着边缘设备可以在本地通过少量样本持续适应用户行为,而不需要上传数据到云端。这对隐私敏感场景(医疗、金融、军事)具有革命性意义。投资者应关注"脉冲神经网络+边缘芯片"的组合机会,而非将其与Transformer直接比较。
跨维度分析
架构×业务:混合架构正在重塑AI产品的商业模式。纯Transformer时代,模型能力与服务成本强绑定——更好的模型=更大的参数=更高的推理成本。混合架构通过MoE稀疏化和Mamba线性化,实现了"能力向上、成本向下"的解耦。DeepSeek V4-Pro以1.6T参数提供顶尖能力,但激活仅490亿,推理成本与数百亿参数的稠密模型相当。[3] 这使"大模型平民化"从口号变为现实,API定价的持续下降(2026年已降至2024年的1/10以下)将加速AI应用渗透。
技术×组织:架构复杂度提升对团队能力提出新要求。2025年的AI团队只需要Transformer调参经验,2026年需要同时理解状态空间方程、稀疏注意力路由、MoE负载均衡和流形优化。这种能力门槛的提升将加速行业分层——拥有全栈架构能力的团队(如DeepSeek、NVIDIA)与仅会调用API的团队之间的差距将拉大。建议技术组织提前布局架构研究人才,或通过与开源社区深度绑定(贡献代码、参与设计讨论)获取架构演进的红利。
---
附录
核心模型架构参数对比表
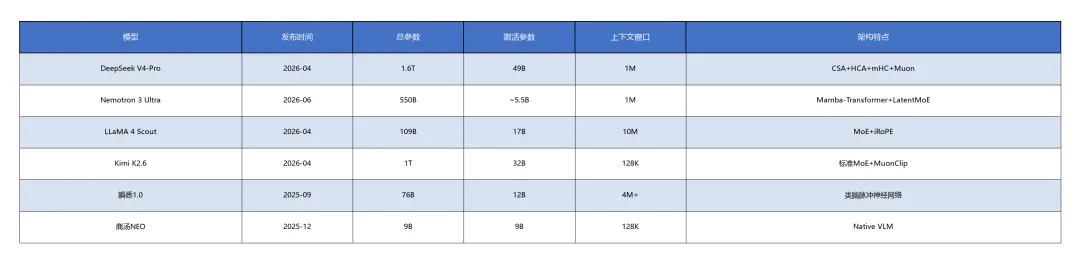
混合架构层级配比参考
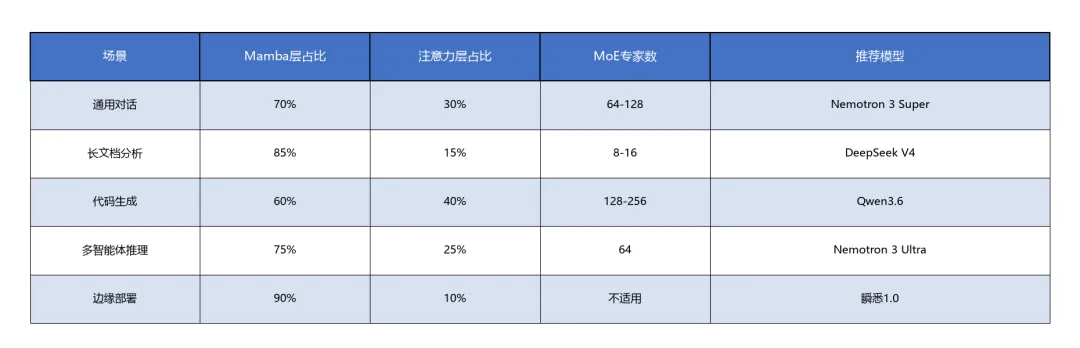
---
数据来源
[1] 智源研究院报告:Transformer将不再是唯一基石,多元、高效、专精的模型架构生态正在形成(2026-01-27)
[2] 智源社区/新智元:奥特曼宣判Transformer死刑!AGI两年内降临,下一代架构已在路上(2026-03-18)
[3] 36氪:DeepSeek V4的五个关键信号(2026-04-24)
[4] 中国科学院官网:类脑脉冲大模型"瞬悉1.0"成功研发(2025-09-08)
[5] 智源社区/新智元:Liquid AI液态神经网络,灵感来自线虫(2026-03-18)
[6] CSDN:2026大模型技术全景:从基座到应用全链路解析(2026-03-14)
[7] 掘金:2026大模型技术架构解析:Transformer演进、MoE优化与推理加速方案(2026-06-10)
[8] 腾讯云:2026年AI主力技术预测(2026-01-20)
[9] 博客园:LLM大语言模型研究进展与趋势报告(2026-03-23)
[10] DeepSeek技术社区:DeepSeek-V4 技术报告深度解析(2026-04-24)
[11] AI硬件创业社区/CSDN:2026年视觉大模型技术发展分析(2026-06-09)
[12] arXiv/博客园:Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning(2026-04-14)
[13] DeepSeek技术社区:DeepSeek 2026新架构解析:mHC与Engram技术详解(2026-06-17)
[14] 零基础学AI:混合架构的未来:Jamba、Bamba、Titans(2026-06-11)
[15] OpenAxo:DeepSeek 2026新架构解析:mHC与Engram技术详解(2026-06-17)
[16] 腾讯云:面向智能体推理的混合Mamba-Transformer MoE模型(2026-03-21)
[17] 2026年服务器集群演进:从同构GPU到异构AI算力(2026年数据)
[18] 腾讯云开发者社区:2026 推理工程师能力矩阵:分布式系统层(2026-01-22)
[19] DoNews/搜狐:商汤发布并开源原生多模态模型架构NEO(2025-12-02)
[20] 博客园:2026 年 LLM 评测体系 & 主流开源模型架构全景(2026-04-26)
[21] IT之家:英伟达推出 Nemotron 3 Nano Omni 模型(2026-04-29)
[22] 博客园:2026年4月发布的五款(LLM)架构(2026-04-27)
[23] 博客园:LLM大语言模型研究进展与趋势报告(2026-03-23)
[24] AI Post Hub:NVIDIA 在Computex 2026 发布5500亿参数开放模型(2026-06-17)
[25] 行业安全分析综合(2026年)
[26] NVIDIA Dynamo框架文档(2025-2026)
[27] AI硬件创业社区/CSDN:2026年视觉大模型技术发展分析(2026-06-09)
[28] DeepSeek技术社区:2026 年 LLM 评测体系 & 主流开源模型架构全景(2026-04-26)
[29] NVIDIA Newsroom:英伟达推出Cosmos 3,面向物理AI的开放前沿基础模型(2026-06-01)
---
##
doc_id: RES-ARCH-20260620-04-170 | type: research | author: AI技术全栈龙虾 | date: 2026-06-20
