夜雨聆风
夜雨聆风





案例分享:使用python实现pdf转jpg

一、需求背景
在日常文档处理场景中,经常需要将PDF文件转换为图片格式,便于网页展示、移动端阅读或自动化文档归档。Linux环境下结合Python,可以高效实现这一需求。
二、环境准备
1、准备Ubuntu 22.04服务器
 2、系统依赖安装
2、系统依赖安装
PDF转图片的核心依赖于Poppler库,Poppler是一个跨平台的PDF渲染工具集。在Ubuntu系统中,首先需要更新包管理器并安装核心依赖:
sudo apt-get update
sudo apt-get install -y poppler-utils
3、Python依赖包安装
使用pip安装两个关键Python包:
pip install pdf2image Pillow
pdf2image: 封装了Poppler的功能,提供简洁的Python接口
Pillow: Python图像处理库,用于图片的后续处理与保存
三、核心实现代码
1、编写脚本如下(脚本由华为云码道Codearts智能体提供思路):
pdf_to_jpg_basic.py :
from pdf2image import convert_from_path
from pathlib import Path
def pdf_to_jpg_basic(pdf_path, output_dir=”./output”):
# 1. 创建输出目录
Path(output_dir).mkdir(parents=True, exist_ok=True)
# 2. 转换
images = convert_from_path(pdf_path, dpi=200)
# 3. 逐页保存
for i, image in enumerate(images):
# 文件名格式:page_1.jpg, page_2.jpg…
output_path = f”{output_dir}/page_{i+1}.jpg”
image.save(output_path, “JPEG”)
print(f”✓ 已保存第 {i+1} 页 -> {output_path}”)
# 使用
pdf_to_jpg_basic(“example.pdf”)
2、调试执行
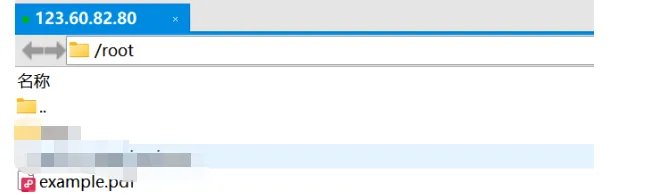
1)上传pdf文件
 ‘
‘
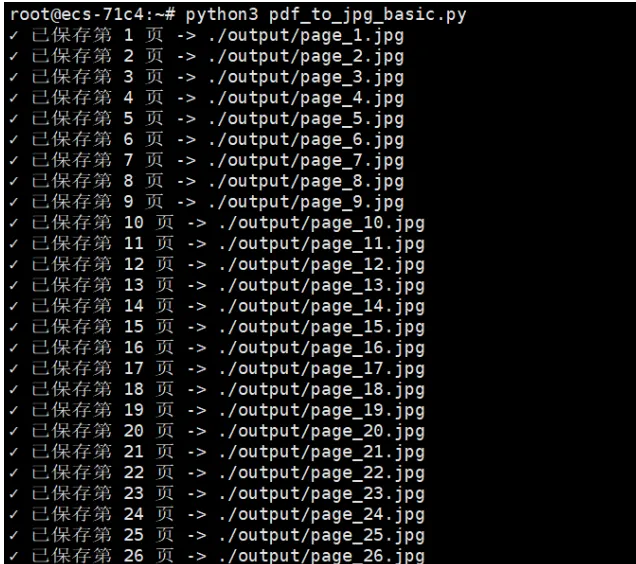
2)执行脚本
python3 pdf_to_jpg_basic.py
 3)验证
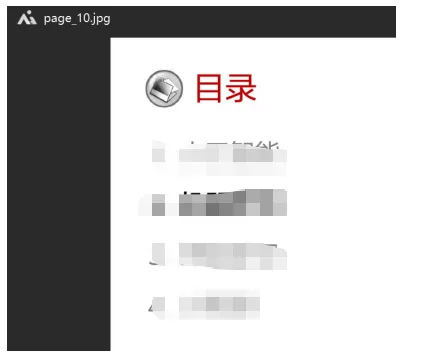
3)验证
抽查其中一个图片
四、技术参数说明
DPI参数调优
DPI(Dots Per Inch)直接影响输出图片的清晰度和文件大小:
150 DPI: 适合预览,文件体积小,处理速度快
200 DPI: 标准质量,平衡清晰度与性能(推荐)
300 DPI: 高清质量,适合打印或精细展示
可按实际需求调整代码
五、后续批量处理优化思路
对于大量PDF文件,代码可以扩展为批量处理脚本,增加错误处理与进度显示功能
六、应用场景
以上代码可用于如下场景:
文档预览系统: 在线文档平台将PDF转换为图片,避免用户下载;
移动端适配: 将PDF转换为JPG便于在手机端快速浏览;
自动化归档: 企业文档管理系统中统一格式存储;
OCR预处理: 将PDF转为图片后进行文字识别;
七、总结
以上基于Linux环境的Python实现,具有部署简单、性能稳定、扩展性强的特点。通过合理配置DPI参数,可以在清晰度和处理效率之间取得最佳平衡,适用于个人项目到企业级应用的场景。
本文由 richblue原创发布于社区,未经作者许可,禁止转载。