 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:4756个文件里藏着Agent系统的终极答案

4756个文件背后的Agent Operating System架构
第一章:引言

图1:传统CLI工具 vs Agent OS架构对比
4756 个文件。
当我从 Claude Code 的 npm 包里提取出这个数字时,我意识到这绝不是一款普通的 CLI 工具。
市面上大部分开源 coding agent,你打开 src/ 目录,会看到一个 main 文件、一个 prompt 文件、几个 tool 文件、一个 utils。Claude Code 的 src/ 顶层有超过 50 个模块目录。
这不是过度设计,这是产品化的必然结果。
配图说明:左侧是简单的传统 CLI 工具架构,右侧是 Claude Code 的复杂 Agent Operating System 架构,展示从单一功能到完整操作系统的演进。
为什么值得深扒源码?
Anthropic 作为 AI 领域的顶级实验室,Claude Code 代表了他们对”AI 工程师”这个角色的工程化理解。从他们的代码里,你能看到:
-
如何把 LLM 的不确定性装进可控的工程框架 -
如何设计一个能持续运行、自我纠正的 Agent 系统 -
如何处理上下文窗口这个”硬约束” -
如何在安全性和效率之间找平衡 -
这些问题的答案,就藏在 4756 个文件里。
本文的阅读价值
这不是一篇功能介绍文。市面上介绍 Claude Code 怎么用、有什么功能的文章已经够多了。
本文要回答的是:为什么 Claude Code 要这么设计?
我们会深入到源码层面,拆解:
-
1729 行的主循环状态机是怎么工作的 -
42 个工具如何通过 14 步 pipeline 被治理 -
6 个 Agent 如何分工协作 -
三层防护网如何确保安全性 -
Token 预算如何被精确管理 -
如果你正在构建自己的 Agent 系统,或者想理解下一代 AI 应用的工程范式,这篇文章就是为你写的。
关键数据速览
在深入之前,先看看这些数字:
| 模块 | 文件数 |
| utils/ | 564 |
| components/ | 389 |
| commands/ | 207 |
| tools/ | 184 |
| services/ | 130 |
| hooks/ | 104 |
| 关键文件 | 行数 |
| main.tsx | 4,683 |
| toolExecution.ts | 1,745 |
| query.ts (主循环) | 1,729 |
| AgentTool.tsx | 1,397 |
这些数字说明 Claude Code 不是一个简单的”调用 API + 执行命令”的脚本,而是一个完整的 Agent Operating System。
接下来,让我们从最核心的引擎开始拆解。
第二章:核心引擎 – 1729行的状态机
图2:1729行状态机
Claude Code 的心脏在
src/query.ts里。1729 行代码,一个 async generator,内部是while(true)循环。这不是简单的轮询,这是一个精心设计的状态机。
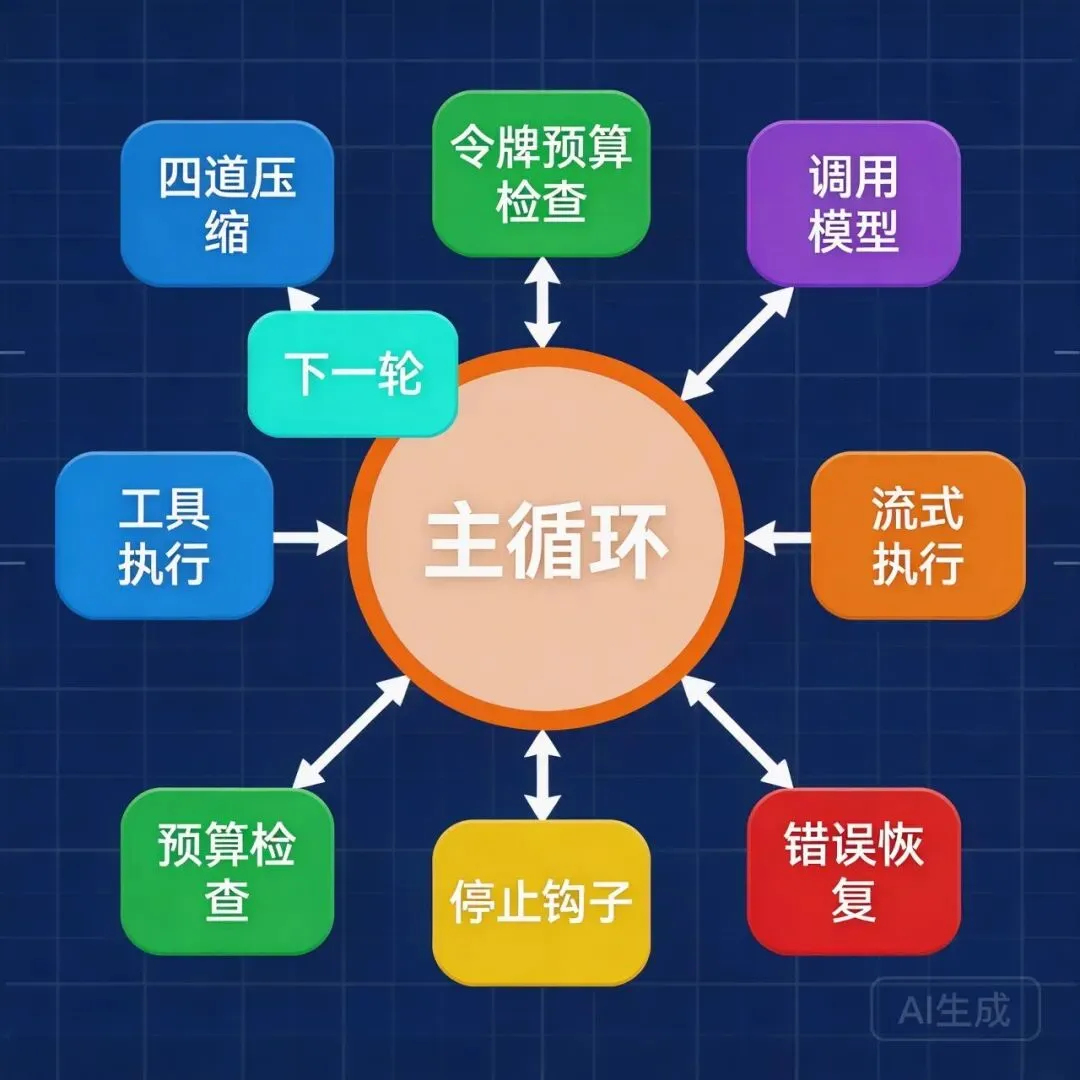
配图说明:展示 query.ts 的 while(true) 主循环,标注四道压缩机制、9个continue点、Streaming Tool Execution等关键节点。 从递归到状态机
早期版本的 query 是递归调用自身的。但在长会话里,递归会爆栈。
现在的设计是
while(true) + state对象。每次continue就是一个 state transition。代码里有 9 个不同的 continue 点,每个对应一种”为什么要再跑一轮”的原因:
-
`next_turn`:下一轮工具调用 -
`reactive_compact`:紧急压缩后重试 -
`max_output_tokens`:输出超限后的恢复 -
`stop_hook`:被 hook 阻断后的处理 -
`token_budget`:预算未用完继续执行 -
一次完整的循环
每次迭代,系统会按顺序执行:
1. 四道上下文压缩
Snip Compact → Micro Compact → Context Collapse → Auto Compact这不是互斥的,而是叠加执行的。
-
**Snip Compact**:把历史消息中过长的部分裁剪掉 -
**Micro Compact**:基于 tool_use_id 做更细粒度的压缩 -
**Context Collapse**:把不活跃的上下文区域折叠成摘要 -
**Auto Compact**:当总 token 接近阈值时,触发全量压缩 -
策略是:先做轻量的(snip、micro),如果能把 token 压到阈值以下,重量压缩就不用跑。
2. Token 预算检查
如果 auto compact 关了,检查是否快撞到硬限制。
3. 调用模型 API
把消息、system prompt、工具定义发给模型。
4. 流式处理响应
这是Streaming Tool Execution 的关键。
传统做法是等模型完整输出,收齐所有 tool_use block,再一起执行。Claude Code 做了一个优化:模型还在输出的时候,已经完成的 tool_use block 就开始执行了。
想象一下:一次 turn 里有 5 个工具调用。传统做法要等模型输出完(可能 5-30 秒),然后串行或并行执行。streaming 模式下,第一个工具在模型还在生成第二个 tool_use 的时候就已经跑完了。
这对用户体验的影响是巨大的。
5. 错误恢复
-
Prompt 太长?试 context collapse drain,再试 reactive compact -
输出 token 超限?注入恢复消息让模型继续 -
模型降级?切 fallback model -
6. Stop hooks
模型停止输出后,运行 stop hooks,决定要不要让模型继续。
7. Token budget
如果有 token 预算,检查是否该继续。
8. 工具执行
批量执行所有工具调用,通过
runTools()或StreamingToolExecutor。9. 附件注入
工具执行完后,注入 memory attachments、skill discovery、queued commands。
10. 下一轮
把结果组装成新的消息列表,回到循环开头。
Prompt 组装:一台精密的拼装机器
prompts.ts里的getSystemPrompt()返回的是一个字符串数组,每个元素对应一个 section。整个 prompt 分成两大块,中间用
SYSTEM_PROMPT_DYNAMIC_BOUNDARY标记隔开:静态部分(可缓存):
-
身份定位(getSimpleIntroSection) -
系统运行规范(getSimpleSystemSection) -
做任务的行为规范(getSimpleDoingTasksSection) -
风险动作规范(getActionsSection) -
工具使用语法(getUsingYourToolsSection) -
语气风格(getSimpleToneAndStyleSection) -
输出效率(getOutputEfficiencySection) -
动态部分(按状态注入):
-
Session guidance(当前启用了哪些工具) -
Memory(CLAUDE.md 内容) -
环境信息(OS、shell、cwd、模型名称) -
语言偏好、输出风格 -
MCP server instructions -
Function result clearing 说明 -
Token budget 说明 -
Prompt Cache 经济学
为什么要用
SYSTEM_PROMPT_DYNAMIC_BOUNDARY?因为 Anthropic 的 API 可以对 system prompt 做前缀缓存。如果两次请求的 system prompt 前缀完全一样(字节级一致),第二次就可以跳过对前缀部分的处理。
所以把不变的内容放前面,会变的放后面,缓存命中率就上去了。
源码注释里写得很直白:不要随意修改 boundary 之前的内容,否则会破坏缓存。
Section Registry
动态部分的 section 不是每次都重新计算的。
systemPromptSections.ts里有一个 section registry,用systemPromptSection()创建的 section 会被缓存,直到/clear或/compact。只有用
DANGEROUS_uncachedSystemPromptSection()创建的才会每次重算。MCP instructions 就是用的 DANGEROUS 版本,因为 MCP server 可能在两个 turn 之间连接或断开。行为规范:怎么让 AI 工程师不乱来
getSimpleDoingTasksSection()可能是整个 prompt 里最有价值的部分。它做的事情很简单:把好的行为写成制度,不依赖模型临场发挥。
看看它具体写了什么:
-
**不要加用户没要求的功能** -
**不要过度抽象**,三行重复代码好过一个不成熟的抽象 -
**不要给你没改的代码加注释和文档字符串** -
**不要做不必要的错误处理和兜底逻辑** -
**不要设计面向未来的抽象** -
**先读代码再改代码** -
**不要轻易建新文件** -
**不要给时间估计** -
**方法失败了先诊断**,不要盲目重试,也不要一次失败就放弃 -
**结果要如实汇报**,没跑过的不要说跑过了 -
用过其他 coding agent 的人应该都遇到过这些问题:你让它改个 bug,它顺手重构了半个文件;你让它加一个功能,它加了三层抽象和五个你没要的错误处理。
Claude Code 的做法是:不指望模型每次都”想到”该怎么做,而是把行为规范写进制度。
这是工程化思维的核心。
Reactive Compact:兜底机制
如果四道压缩都没能把 token 数压下来,API 返回了 413(prompt too long),还有一个 reactive compact 机制。
它会在收到 413 之后立刻触发一次紧急压缩,然后重试。
但这个机制有防循环设计:
hasAttemptedReactiveCompact标记确保每个 turn 只尝试一次。下一章,我们来看看 42 个工具是如何被治理的。
第三章:工具系统 – 42个工具的治理流水线
图3:14步工具Pipeline
Claude Code 有 42 个工具。但数量不是重点,治理机制才是。

配图说明:横向展示14步工具执行流程,标注关键节点:Speculative Classifier、PreToolUse hooks、Permission Decision、PostToolUse hooks等。 Tool 接口设计
Tool.ts定义了一个完整的工具接口。这不是简单的”函数名 + 输入 + 输出”:interface Tool { call(): PromiseinputSchema: ZodSchema validateInput(): Promise checkPermissions(): Promise preparePermissionMatcher(): PermissionMatcher isReadOnly(): boolean isDestructive(): boolean isConcurrencySafe(): boolean prompt(): string // 动态生成 prompt 描述 backfillObservableInput(): void toAutoClassifierInput(): string // ... 还有 6+ 个 render 方法} fail-closed 默认值
buildTool()是工厂函数,提供 fail-closed 的默认值: -
`isConcurrencySafe` 默认 `false`(假设不安全) -
`isReadOnly` 默认 `false`(假设会写) -
`checkPermissions` 默认 `allow`(交给通用权限系统处理) -
这个选择很有意思:新写一个工具的时候,如果忘了配置,系统会往最严格的方向处理。
忘了声明并发安全性?默认串行执行。忘了声明只读?走更严格的权限检查。
这种”忘了就严格”的设计,避免了一个很常见的问题:某个工具忘了配置,结果在没有权限检查的情况下执行了危险操作。
42个工具的分类
按功能大致可以分成这几类:
文件操作:FileRead、FileEdit、FileWrite、GlobTool、GrepTool、NotebookEdit
Shell 执行:BashTool、PowerShellTool
Agent 调度:AgentTool、TaskCreate/Get/List/Stop/Update/Output
MCP 集成:MCPTool、ListMcpResources、ReadMcpResource、McpAuth
Web 能力:WebSearch、WebFetch
用户交互:AskUserQuestion、SendMessage
模式切换:EnterPlanMode、ExitPlanMode、EnterWorktree、ExitWorktree
其他:SkillTool、SleepTool、TodoWrite、Config、ToolSearch、Brief、ScheduleCron、RemoteTrigger
每个工具都有自己的
prompt.ts,定义了这个工具在 system prompt 里的描述。这些描述会通过prompt()方法动态生成,根据当前可用的工具集和权限模式调整内容。工具执行 Pipeline:14步治理
当模型决定调用一个工具的时候,
toolExecution.ts里有一条完整的执行流水线。不是”模型说调就调”,而是经过 14 步治理:
1. 找工具
通过名字或别名(alias)找到对应的 Tool 对象。
2. 解析 MCP 元数据
如果是 MCP 工具,提取 server 信息。
3. Zod schema 校验
用输入 schema 做第一道校验,挡住乱传参数。
4. validateInput()
工具自己的细粒度校验。
5. Speculative Classifier
如果是 BashTool,启动一个预测性分类器,在权限决策之前就开始分析命令的风险等级。
这是 BashTool 的独特设计:分类器可以在 Hook 执行的同时并行运行,不阻塞主流程。等到需要做权限决策的时候,分类结果可能已经出来了。
这种”提前开始异步计算”的做法,减少了用户等待权限弹窗的时间。
6. PreToolUse hooks
运行所有注册的 pre-hook。
7. 解析 Hook 权限结果
Hook 可能返回 allow、ask、deny,也可能修改输入。
8. 走权限决策
综合 Hook 结果、规则配置、用户交互,做出最终允许/拒绝决策。
9. 修正输入
如果权限决策或 Hook 修改了输入,用修改后的版本。
10. 执行 tool.call()
真正跑工具。
11. 记录 analytics / tracing / OTel
遥测和可观测性。
12. PostToolUse hooks
成功后的 post-hook。
13. 处理结果
结构化输出、tool_result block 构建。
14. PostToolUseFailure hooks
如果失败了,跑失败 hook。
为什么需要这么复杂的 pipeline?
因为 LLM 是不可信的。
模型可能会:
-
传错参数 -
调用不该调用的工具 -
在用户没授权的情况下执行危险操作 -
失败后没有正确处理 -
这套 pipeline 就是把 LLM 装进一个可控的工程框架。
每一层都有自己的职责:
-
Schema 校验挡住参数错误 -
Speculative Classifier 提前预判风险 -
Hook 系统做运行时策略调整 -
Permission Decision 做最终把关 -
Post-hooks 确保清理和记录 -
这 14 步不是为了复杂而复杂,而是在灵活性和安全性之间找平衡。
下一章,我们来看看多个 Agent 如何分工协作。
第四章:多Agent体系 – 分工的艺术
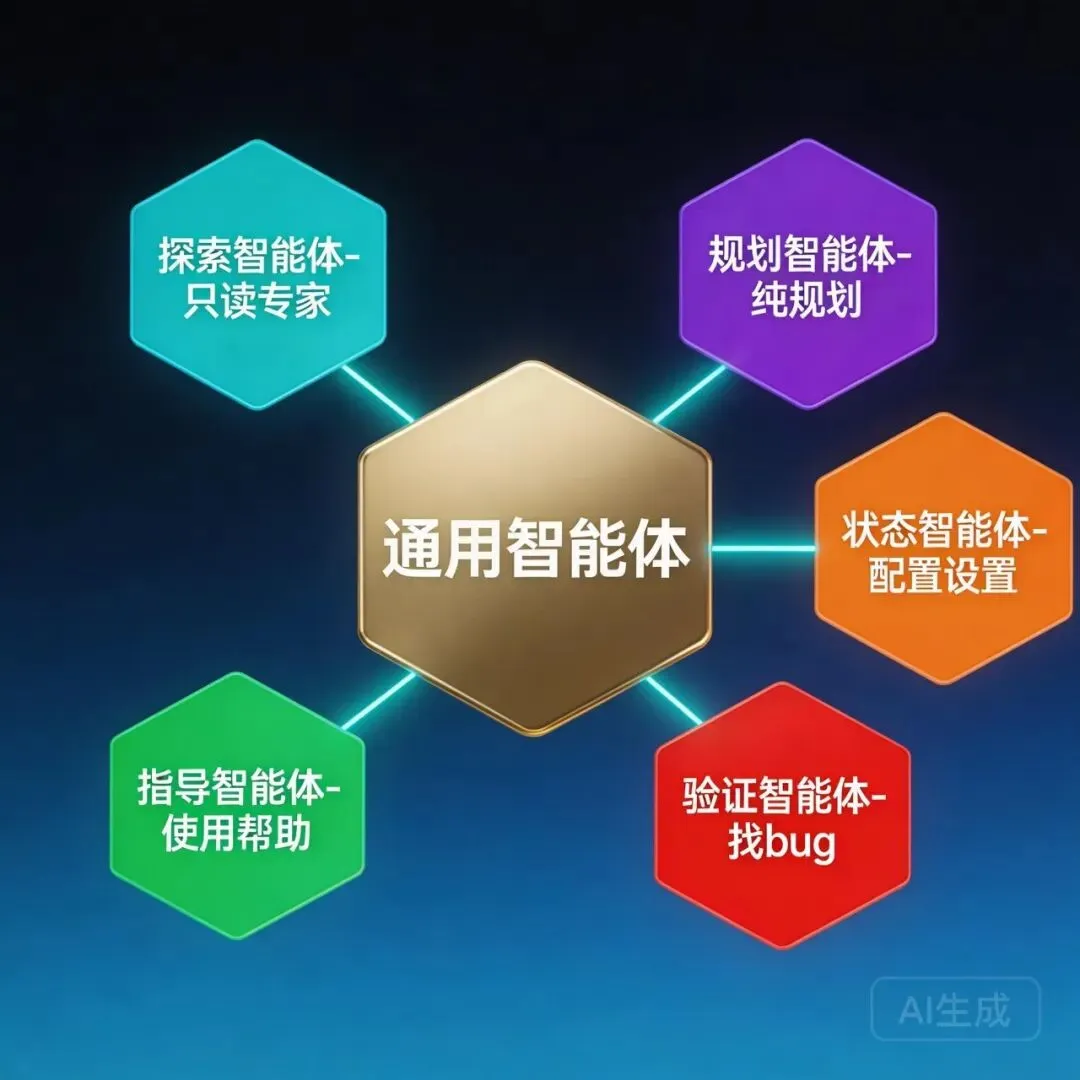
图4:6个Agent分工
Claude Code 至少有 6 个内建 Agent:
-
**General Purpose Agent**:通用任务执行 -
**Explore Agent**:纯只读的代码探索 -
**Plan Agent**:纯规划,不执行 -
**Verification Agent**:对抗性验证 -
**Claude Code Guide Agent**:使用指导 -
**Statusline Setup Agent**:状态栏配置 -
配图说明:六边形蜂巢图,中心是主Agent,周围5个专业化Agent,用不同颜色区分职责边界。 这个设计选择的出发点很朴素:让一个 Agent 同时研究、规划、实现、验证,每件事都做不扎实。
Explore Agent:裁剪出来的只读专家
Explore Agent 的 prompt 非常严格。它被明确禁止:
-
创建新文件(任何形式) -
修改已有文件 -
删除文件 -
用重定向写文件 -
运行任何改变系统状态的命令 -
它能用的工具只有 Glob、Grep、FileRead,Bash 也只允许
ls、git status、git log这些读操作。为什么要这么极端?
因为探索阶段如果不小心改了东西,后面实现阶段就会出问题。把权限彻底隔离,是一种朴素但有效的安全设计。
它还有一个性能优化:外部用户默认用 Haiku 模型(更快更便宜),内部用户继承主模型。探索不需要最强的推理能力,速度更重要。
Verification Agent:整个系统里最狠的 prompt
Verification Agent 的 prompt 写了 130 行,可能是整个源码里最精心设计的一段文本。
它的核心方向就一件事:“想办法搞坏它”(try to break it)。
两种常见的验证失败模式
prompt 开头就点出来:
-
**Verification avoidance**:只看代码,不跑检查,写个 PASS 就走了 -
**被前 80% 迷惑**:UI 看着不错,测试也过了,就忽略剩下 20% 的问题 -
强制要求的验证动作
根据变更类型有不同策略:
-
**前端改动**:启动 dev server,用浏览器自动化去点 -
**后端改动**:curl 实测 -
**CLI 改动**:看 stdout/stderr/exit code -
**数据库迁移**:测 up/down,还要测已有数据 -
识别合理化倾向
更狠的是,它列出了验证者常见的逃避借口,然后要求“识别你自己的合理化倾向”:
-
“代码看起来是对的” → 看是不是验证。跑一下。 -
“实现者的测试已经通过了” → 实现者也是 LLM。独立验证。 -
“大概没问题” → 大概不是验证。跑一下。 -
“这个太费时间了” → 不是你说了算的。 -
每个检查项必须包含实际执行的命令和观察到的输出。
最后给出明确的判决:
VERDICT: PASS / FAIL / PARTIAL实现者和验证者分离
这种设计在传统软件工程里是常识:写代码的人不应该是验收代码的人。
但在 AI Agent 系统里,大部分产品还没做到这一步。Claude Code 把它做成了一个独立角色,有自己的 system prompt、工具集(不能 edit/write)和评判标准。
写代码的 Agent 可能会倾向于觉得自己写得没问题,但验证 Agent 没有这个偏见——它的工作就是找问题。
AgentTool.tsx:调度总控
AgentTool.tsx有 1397 行,是整个多 Agent 系统的调度中心。它要处理的分支非常多:
-
判断是 fork、built-in agent、multi-agent teammate 还是 remote -
解析输入参数:description、prompt、subagent_type、model、run_in_background、isolation、cwd -
根据权限规则过滤可用的 agent -
检查 MCP 依赖 -
构造 system prompt 和 prompt messages -
处理 worktree 隔离 -
注册前台/后台任务 -
调用 runAgent() -
Fork path 的 cache 优化
fork 和 normal path 的区分是一个很精妙的设计。
当你 fork 一个子任务时,它会继承主线程的 system prompt、完整对话上下文、工具集,尽量保持字节级一致。
为什么?
为了让 API 请求的前缀一样,从而复用主线程的 prompt cache。
源码注释里写得很直白:fork 不应该换模型,因为换模型会改变 system prompt 里的模型描述字段,破坏 cache 前缀匹配。
普通人做子 Agent 调度,想的是”子任务能跑起来就行”。
Claude Code 想的是:“子任务能跑起来,而且尽量复用主线程的缓存”。
这就是工程化思维的差距。
runAgent.ts:子 Agent 的完整运行时
runAgent.ts有 973 行,负责子 Agent 的完整生命周期: -
初始化 agent 专属的 MCP servers(可以从 frontmatter 定义) -
克隆 file state cache -
获取 user/system context -
对只读 agent 做内容瘦身 -
构造 agent 专属的权限模式 -
组装工具池 -
注册 frontmatter hooks -
预加载 skills -
执行 SubagentStart hooks -
调用 query() 进入主循环 -
记录 transcript -
清理 MCP 连接、hooks、perfetto tracing、todos、shell tasks 等 -
这里有一个细节:agent 可以自带 MCP servers。通过 frontmatter 配置,一个 agent 可以连接自己专属的外部工具。这让插件 agent 有了非常强的扩展能力。
任务系统
tasks/ 目录下有 5 种任务类型:
-
**DreamTask**:自主后台任务 -
**LocalAgentTask**:本地 agent 任务(前台/后台/异步) -
**RemoteAgentTask**:远程 agent 任务 -
**InProcessTeammateTask**:进程内 teammate -
**LocalShellTask**:shell 任务 -
后台 agent 有独立的 abort controller,可以在后台持续运行,完成后通过 notification 回到主线程。前台 agent 可以在执行过程中被转成后台。
这些都是产品化的生命周期管理。
下一章,我们来看看安全层的设计。
第五章:安全层 – 三层防护网
图5:三层防护网
Claude Code 的安全设计不是单一防线,而是三层防护网。

配图说明:三层同心圆或层叠盾牌,从内到外标注:Speculative Classifier、Hook Policy Layer、Permission Decision,每层之间有明确的职责边界。 权限系统概览
utils/permissions/下有 27 个文件,管理一套完整的权限模型: -
**PermissionMode**:default、plan、auto 等模式 -
**PermissionRule**:规则定义(allow/deny/ask) -
**PermissionResult**:决策结果 -
**bashClassifier**:Bash 命令风险分类 -
**yoloClassifier**:auto 模式下的分类器 -
**dangerousPatterns**:危险命令模式匹配 -
**shellRuleMatching**:Shell 命令的规则匹配 -
**pathValidation**:文件路径校验 -
Hook 系统:不只是事件钩子
Hook 系统是整个安全层里最有表达力的部分。
它支持三个时点:
-
**PreToolUse**:工具执行前 -
**PostToolUse**:工具执行成功后 -
**PostToolUseFailure**:工具执行失败后 -
PreToolUse 能做什么
Pre-hook 能做的事情远不止”记日志”:
-
返回 `permissionBehavior`(allow / ask / deny) -
返回 `updatedInput`(修改工具输入) -
返回 `blockingError`(直接阻断) -
返回 `preventContinuation`(阻止后续流程) -
返回 `additionalContexts`(补充上下文信息) -
PostToolUse 能做什么
Post-hook 也能:
-
修改 MCP 工具的输出 -
追加消息 -
注入上下文 -
resolveHookPermissionDecision:安全的关键粘合层
toolHooks.ts里的resolveHookPermissionDecision()函数定义了一个关键规则:Hook 说 allow,不一定绕过 settings 里的 deny/ask 规则。
具体逻辑:
-
Hook allow + 工具要求用户交互 + Hook 没提供 updatedInput → **仍然走 canUseTool** -
Hook allow + settings 里有 deny 规则 → **deny 规则生效** -
Hook allow + settings 里有 ask 规则 → **仍要弹窗** -
Hook deny → **直接生效** -
Hook ask → **作为 forceDecision 传给权限弹窗** -
这个设计非常成熟:Hook 有足够的表达力来做运行时策略调整,但它不能绕开核心安全模型。
这意味着即使某个 Hook 写了 bug 或者被恶意利用,它也不能让一个被 settings deny 掉的操作悄悄通过。
“强大但受控”是工程成熟度的标志。
三层防护网
把权限系统、Hook 系统和工具执行 pipeline 放在一起看,Claude Code 有三层防护:
第一层:Speculative Classifier(提前预判)
BashTool 的风险分类器,在 Hook 执行的同时并行运行。
它提前分析命令的风险等级,等需要做权限决策的时候,分类结果可能已经出来了。
第二层:Hook Policy Layer(策略层)
PreToolUse hooks 可以做:
-
权限决策 -
修改输入 -
阻断流程 -
第三层:Permission Decision(权限决策)
综合规则配置和用户交互,做出最终允许/拒绝决策。
互不绕过原则
这三层的关键设计是:互相配合但互不绕过。
-
Speculative classifier 的结果只是**辅助信息**,不能绕过 Hook -
Hook 的 allow **不能绕过** settings deny -
每层都有自己的职责边界,即使某一层出了问题,整体安全性不会崩塌。
这就是深度防御(Defense in Depth)的工程实践。
为什么需要三层?
因为 LLM 是不可预测的。
模型可能会:
-
生成危险的 Bash 命令 -
试图访问敏感文件 -
在用户不知情的情况下执行操作 -
被 prompt 注入攻击 -
三层防护的设计哲学是:假设任何一层都可能失效,多层冗余确保整体安全。
这也是 Claude Code 能放心让 Agent 自主执行复杂任务的原因——不是相信模型不会犯错,而是相信系统能拦住错误。
下一章,我们来看看生态设计。
第六章:生态设计 – 让模型感知自己的能力
图6:生态系统
Claude Code 不是一个封闭系统,它有完整的生态扩展机制:Skill、Plugin、MCP。
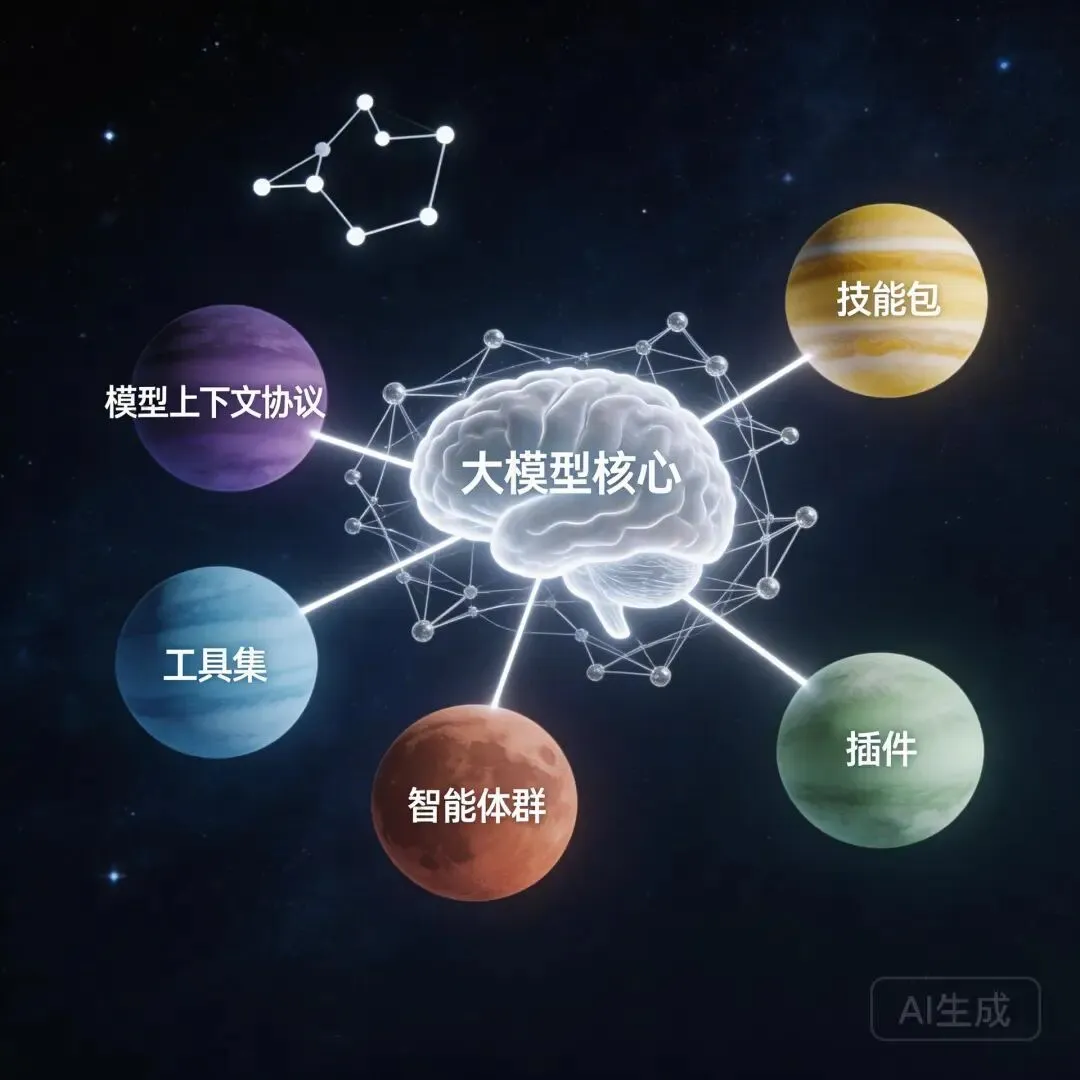
配图说明:生态系统图,中心是模型,周围环绕着各种扩展能力:Skill(工作流程包)、Plugin(行为扩展)、MCP(工具桥),用有机的连接线展示它们如何被模型感知。 但生态的关键不在于”有什么扩展”,而在于“模型能不能感知到这些扩展”。
Skill:带元数据的 workflow package
skills/目录下有 17 个 bundled skills,包括 verify、commit、loop、simplify、stuck、debug 等。Skill 的形态是带 frontmatter metadata 的 markdown 文件。它可以声明:
-
`allowed-tools`:允许使用的工具 -
`model`:指定模型 -
`effort` hints: effort 提示 -
Skill 可以按需注入当前上下文。
系统要求模型在任务匹配到某个 skill 时必须调用 Skill tool 执行,不能只是提到这个 skill 而不执行。
Plugin:模型行为层面的扩展
utils/plugins/有 42 个文件,涵盖从加载到验证到市场管理的完整链条。Plugin 能提供的能力包括:
-
markdown commands 和 SKILL.md 目录 -
hooks(Pre/PostToolUse) -
output styles -
MCP server 配置 -
模型和 effort hints -
运行时变量替换(`${CLAUDE_PLUGIN_ROOT}` 等) -
自动更新、版本管理、blocklist -
Plugin 不是普通的 CLI 插件。它能影响模型的行为:改变 prompt、增加工具、修改权限规则。
MCP:工具桥 + 行为说明注入
MCP 不只提供新工具。
从
prompts.ts可以看到,当 MCP server 连接上来的时候,如果 server 提供了instructions,这些 instructions 会被拼进 system prompt。也就是说,一个 MCP server 能同时给模型两样东西:
-
**新工具**(通过 MCP 协议注册) -
**怎么用这些工具的说明**(通过 instructions 注入 prompt) -
这让 MCP 的价值远高于一个简单的工具注册表。模型不只知道”有这个工具”,还知道”什么时候该用、怎么用“。
生态的关键:模型”感知到”自己的能力
很多平台也有插件系统、也有工具市场,但模型本身不知道这些东西存在。
就像你给一个人配了一整套工具箱,但他不知道箱子里有什么。
Claude Code 通过以下通道,让模型感知到自己当前有哪些扩展能力:
-
**skills 列表**:当前可用的 skills -
**agent 列表**:当前可用的 agents -
**MCP instructions**:每个 MCP server 的 instructions -
**session-specific guidance**:会话级别的指导 -
**command integration**:命令集成 -
这才是生态真正发挥作用的前提。
为什么感知这么重要?
因为 LLM 的决策是基于上下文的。
如果模型不知道某个工具存在,它就不会想到去用。如果模型不知道某个 skill 怎么用,它就会瞎用。
Claude Code 的设计哲学是:不仅提供能力,还要让模型知道”我有这些能力”。
这体现在几个细节:
-
**System prompt 里的 tools 列表**:每个可用工具都有详细描述 -
**Session guidance**:当前启用了哪些工具,影响行为指引 -
**Skill discovery**:预取可能相关的 skill -
**MCP instructions 注入**:server 连接后立即把 instructions 写进 prompt -
生态的治理
Claude Code 对生态扩展有严格的治理:
-
**Plugin 验证**:加载时验证完整性 -
**版本管理**:支持自动更新 -
**Blocklist**:可以屏蔽有问题的插件 -
**权限隔离**:每个扩展有自己的权限边界 -
这也是产品化思维的体现:开放但不失控。
下一章,我们来看看上下文经济学。
第七章:上下文经济学 – Token就是预算
图7:四道压缩
在 LLM 应用里,上下文窗口是最硬的约束。
Claude Code 的解决方案是:把 token 当作预算来管理。
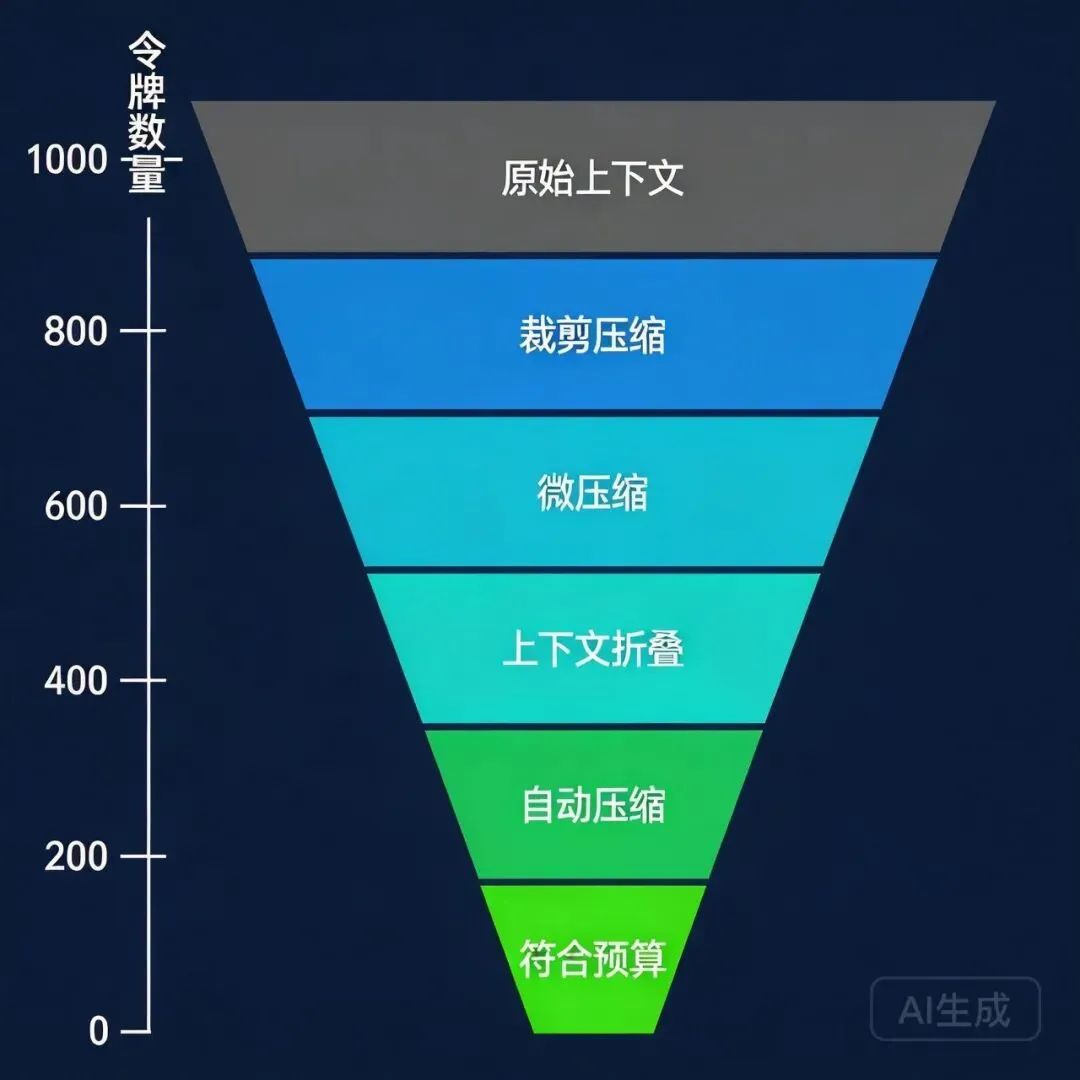
配图说明:漏斗图,从上到下展示四道压缩机制:Snip Compact → Micro Compact → Context Collapse → Auto Compact,展示原始上下文如何被层层压缩。 四道压缩机制
query.ts里,每次调用模型之前,消息列表会经过四道处理:1. Snip Compact
把历史消息中过长的部分裁剪掉。
这是轻量级压缩,主要处理单个消息超长的情况。
2. Micro Compact
更细粒度的压缩,基于 tool_use_id 做缓存编辑。
它会识别哪些 tool 结果可以被压缩成摘要,同时保持语义完整性。
3. Context Collapse
把不活跃的上下文区域折叠成摘要。
如果某个上下文区域长时间没被引用,就把它压缩成一段摘要,而不是保留完整内容。
4. Auto Compact
当总 token 数接近阈值时,触发全量压缩。
这是最重量级的压缩,会重新评估整个上下文的优先级,保留最重要的信息。
压缩的策略
这四道不是互斥的,而是叠加执行的。
优先级是:先做轻量的(snip、micro compact),再做重量的(context collapse、auto compact)。
如果轻量压缩把 token 数压到阈值以下了,重量压缩就不需要跑。
这种渐进式压缩的策略,既保证了效率,又最大程度保留了上下文信息。
Reactive Compact:API 413 的兜底
如果四道压缩都没能把 token 数压下来,API 返回了 413(prompt too long),还有一个 reactive compact 机制。
它会在收到 413 之后立刻触发一次紧急压缩,然后重试。
但这个机制有防循环设计:
hasAttemptedReactiveCompact标记确保每个 turn 只尝试一次。Token Budget
query/tokenBudget.ts实现了 token 预算系统。当用户指定一个 token 目标(比如”+500k”),系统会:
-
追踪每个 turn 的输出 token -
在接近目标时注入 nudge message 让模型继续工作 -
这对长任务很有用。以前模型可能自己觉得”差不多了”就停了,现在有了明确的预算概念。
其他上下文优化
Skill 按需注入
匹配到了才注入,启动时不会全部塞进去。
MCP instructions 按连接状态注入
没连上的 server 的说明不占空间。
Memory prefetch
在模型流式输出的同时,预取可能相关的 memory 内容。
这样等模型需要时,memory 已经准备好了。
Skill discovery prefetch
同上,预取可能相关的 skill。
Tool result budget
单个工具结果太大时,持久化到磁盘,只保留摘要在上下文里。
上下文是预算的设计哲学
Claude Code 的上下文管理体现了一个核心原则:每个 token 都有成本,每条信息都占空间。
所以:
-
能**缓存**的要缓存 -
能**按需加载**的不要一开始就塞进去 -
能**压缩**的要压缩 -
能**预取**的要预取 -
这不是抠门,而是在资源约束下做最优决策。
下一章,我们来看看产品化的真谛。
第八章:产品化的真谛 – 处理”第二天”的问题
图8:生命周期
第一天让 Agent 跑起来不难。
难的是第二天的问题:任务中断怎么续、脏状态怎么清、进程泄漏怎么办、session 怎么恢复。

配图说明:时间轴形式,从左到右展示完整生命周期:初始化 → 运行 → 中断 → 恢复 → 清理,标注每个阶段的关键操作。 生命周期管理
runAgent.ts里有很多不起眼但说明问题的函数调用:// 记录和追踪recordSidechainTranscript() // 记录子 agent 对话writeAgentMetadata() // 写元数据registerPerfettoAgent() // 性能追踪// 清理cleanupAgentTracking() // 清理跟踪状态killShellTasksForAgent() // 清理 shell 进程// 清理 session hooks、克隆的文件状态、todos entry、MCP 连接大部分 Agent 系统在第一天跑得挺好。问题出在第二天。
Claude Code 对这些都有明确的处理。
Bridge 系统
bridge/有 31 个文件,实现了远程控制和 IDE 集成。让 Claude Code 可以在不同环境之间桥接:
-
本地 CLI 控制远程容器 -
IDE 插件连接 Claude Code 运行时 -
等等 -
这是产品化的基础设施。
State 管理
state/AppState.tsx和store.ts管理全局应用状态。 -
权限模式 -
MCP 连接 -
工具配置 -
effort 设置 -
所有运行时状态都在这里统一管理。
UI 层
components/(389 文件)和ink/(96 文件)实现了终端 UI。Claude Code 用 React + Ink 构建了一个完整的 TUI 应用,有:
-
权限弹窗 -
进度条 -
diff 显示 -
agent 状态面板 -
这不是简单的命令行输出,而是一个完整的终端应用。
Telemetry
services/analytics/、utils/telemetry/覆盖了: -
Datadog -
Perfetto tracing -
OTel 事件 -
cost tracker(追踪 API 调用成本) -
rate limit 管理 -
可观测性是产品化的另一个关键。
为什么”第二天”最重要?
很多 Agent 系统的问题不是功能不够,而是生命周期管理缺失。
比如:
-
Agent 运行中断了,怎么恢复? -
子 Agent 创建的 shell 进程,父 Agent 退出了它们还在跑怎么办? -
MCP 连接泄漏了怎么办? -
文件状态缓存和实际文件不一致了怎么办? -
这些问题在 demo 里不会暴露,但在生产环境里会致命。
Claude Code 的答案是:在架构层面就考虑生命周期管理。
每个 Agent 都有明确的:
-
**初始化**:加载配置、连接 MCP、注册 hooks -
**运行**:主循环、流式执行 -
**中断/恢复**:状态持久化、从断点续跑 -
**清理**:关闭连接、杀进程、释放资源 -
这不是简单的 try-finally,而是完整的状态机设计。
产品化的七个维度
从源码里可以看到,Claude Code 的产品化体现在:
-
**入口层**:多个入口(CLI、MCP、SDK),fast-path 优化 -
**命令系统**:101 个命令,统一加载各种来源 -
**生命周期**:完整的初始化-运行-清理链条 -
**状态管理**:统一的 AppState 和 store -
**UI 层**:完整的 TUI 应用体验 -
**Bridge**:远程控制和 IDE 集成 -
**Telemetry**:全面的可观测性 -
这不是一个”能跑”的 demo,而是一个能上线的产品。
下一章,我们总结七大设计原则。
第九章:七大设计原则总结
把前面所有模块看完之后,可以归纳出这些设计原则。
这些不是空洞的口号,每一条都有对应的源码实现做支撑。
—
原则 1:不信任模型的自觉性
好行为要写成制度。
你希望模型先读代码再改代码,就写进 prompt。你希望模型不要乱加功能,就写进 prompt。你希望模型遇到风险操作停下来,就在 runtime 层加权限检查。
不要指望一个 LLM 每次都”想到”该怎么做。制度化的行为比临场发挥稳定得多。
对应源码:`getSimpleDoingTasksSection()`、`getActionsSection()` —
原则 2:把角色拆开
至少把”做事的人”和”验收的人”分开。
哪怕用同一个模型,职责拆开也会有明显改善。因为同一个 Agent 既实现又验证,天然倾向于觉得自己做得没问题。
对应源码:Verification Agent、Explore Agent、Plan Agent —
原则 3:工具调用要有治理
模型说要调工具,中间还要过输入校验、权限检查、风险预判。
执行完了还有后处理和失败处理。这层治理决定了系统在异常情况下的表现。
对应源码:`toolExecution.ts` 的 14 步 pipeline —
原则 4:上下文是预算
每个 token 都有成本,每条信息都占空间。
能缓存的要缓存,能按需加载的不要一开始就塞进去,能压缩的要压缩。
对应源码:`SYSTEM_PROMPT_DYNAMIC_BOUNDARY`、fork cache optimization、四道压缩机制 —
原则 5:安全层要互不绕过
三层防护(classifier、hook、permission)可以互相配合,但任何一层不能绕过另一层。
Hook 的 allow 不能绕过 settings 的 deny。这样即使某一层出了问题,整体安全性不会崩塌。
对应源码:`resolveHookPermissionDecision()` —
原则 6:生态的关键是模型感知
你给系统接了十个插件,但模型不知道什么时候该用哪个,那这十个插件就等于不存在。
扩展机制的最后一步,是让模型看到自己的能力清单。
对应源码:MCP instructions injection、skill discovery、session-specific guidance —
原则 7:产品化在于处理第二天
第一天跑起来不难。难的是任务中断怎么续、脏状态怎么清、进程泄漏怎么办、session 怎么恢复。
这些问题不解决,产品就只能是 Demo。
对应源码:`runAgent.ts` 的 cleanup chain、transcript recording、task lifecycle —
最后的话
读 Claude Code 的源码,最大的收获不是学会了什么具体的技术,而是看到了工程化思维的范本。
-
面对 LLM 的不确定性,用**制度**而不是靠运气 -
面对复杂的系统,用**分层**而不是堆复杂度 -
面对资源约束,用**预算思维**而不是无限扩张 -
面对安全问题,用**深度防御**而不是单层防线 -
4756 个文件里,藏着一个 Agent Operating System 的终极答案。
希望这篇文章能给你构建自己的 Agent 系统带来一些启发。
结语
写到这里,Claude Code 的源码架构解析就告一段落了。
回顾全文,我们从 4756 个文件中提炼出了七个核心模块:
-
**1729行的状态机** – 主循环的设计哲学 -
**42个工具的治理** – 14步 pipeline 的安全设计 -
**多Agent体系** – 分工的艺术 -
**三层防护网** – 安全层的深度防御 -
**生态设计** – 让模型感知自己的能力 -
**上下文经济学** – Token就是预算 -
**产品化的真谛** – 处理”第二天”的问题 -
最后,我们总结了七大设计原则,每一条都有源码实现做支撑。
给你的行动建议
如果你正在构建自己的 Agent 系统,可以从以下几点开始:
-
**先写制度**:把你的期望行为写进 prompt,不要指望模型自己想到 -
**拆分角色**:至少把”做事”和”验收”分开 -
**设计治理**:工具调用要经过校验、检查、决策三层 -
**管理上下文**:把 token 当预算,设计压缩策略 -
**考虑安全**:多层防护,互不绕过 -
**让模型感知**:不仅提供能力,还要让模型知道”我有这些能力” -
**处理第二天**:任务中断、状态清理、进程管理,这些才是产品化的关键 -
关于素材
本文素材来自对 Claude Code npm 包的源码分析。如果你想自己深挖,可以:
npm pack @anthropics/claude-code# 提取 cli.js.map 里的 sourcesContent源码是最好的老师。
下一步
-
想深入了解某个具体模块?留言告诉我 -
有你的 Agent 系统设计经验?欢迎分享 -
发现文中有错误或遗漏?请指正 4756个文件里,藏着一个Agent Operating System的终极答案。
希望这篇文章对你有所启发。我们下篇见。