 夜雨聆风
夜雨聆风





第6期:23行Python,标记出Excel销售订单重复行
这是我们常见的销售订单原始数据格式:
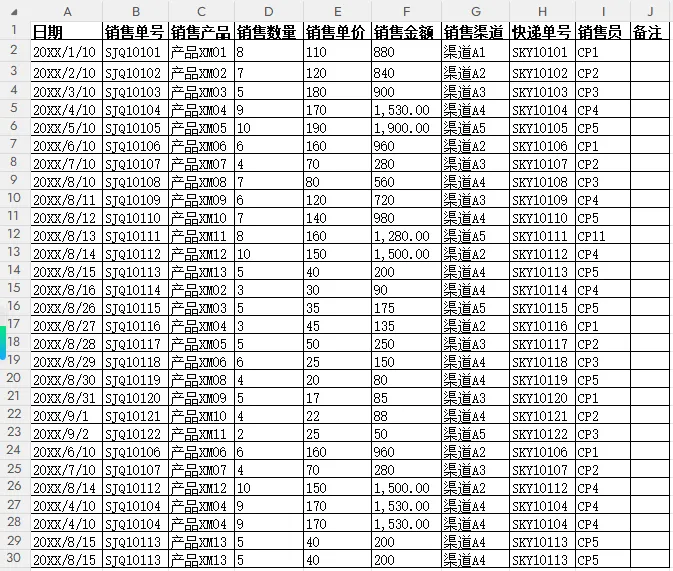
日常工作中,很多朋友都会遇到这种情况:
发货单、订单表、销售记录,一不小心重复录入。
手动核对不仅费眼,还很容易遗漏。
下面分享一段极简 Python 程序,自动帮你完成:
-
找出 Excel里的重复记录 -
给重复行加上 删除线 -
源文件保留,生成新文件 -
简单安全,不破坏数据
本文逐行拆解,零基础也能一次跑通。
📌 适用场景
-
发货单、销售单、出库单等单据查重 -
订单数据重复录入标记 -
财务/仓库/运营人员日常数据核对
🎯 需求分析
以某电商运营平台「销售订单明细表」为例。按销售单号判断重复:
-
按销售单号排序,让重复记录挨在一起,方便核查 -
第一次出现的记录正常显示 -
后续重复的整行自动加上 删除线+ 浅红背景
🛠 着手实现
第1步:准备数据
在D:盘新建文件夹:PythonTest,把待处理的Excel 放进去:
D:\PythonTest\XX电商运营销售订单明细表-20XX.xlsx第2步:安装工具
打开cmd,执行:
pip install pandas openpyxl只需安装一次,后续直接运行脚本即可。
第3步:代码实现
-
在 D:盘新建文件夹:python。 -
在 D:\python文件夹下新建mark_duplicate.py脚本文件。
📜 完整代码(复制即用)
import timeimport pandas as pdfrom openpyxl import load_workbookfrom openpyxl.styles import Font, PatternFill, Border, Sidetimestamp = time.strftime("%Y%m%d%H%M%S")file_input = "D:/PythonTest/XX电商运营销售订单明细表-20XX.xlsx"file_output = f"D:/PythonTest/销售订单明细_标记重复_{timestamp}.xlsx"order_col = "销售单号"# 读取并排序、标记df = pd.read_excel(file_input)df = df.sort_values(by=order_col)df["_重复标记"] = df.duplicated(subset=order_col, keep="first")# 先保存(包含辅助列)df.to_excel(file_output, index=False)# 用 openpyxl 处理格式wb = load_workbook(file_output)ws = wb.active# 定义高亮样式(浅红色背景)highlight_fill = PatternFill(start_color="FFCCCC", end_color="FFCCCC", fill_type="solid")# 定义细边框样式thin_border = Border( left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))# 找到辅助列的列号header_row = list(ws.iter_rows(min_row=1, max_row=1, values_only=True))[0]dup_col_idx = Nonefor idx, col_name in enumerate(header_row, start=1):if col_name == "_重复标记": dup_col_idx = idxbreakif dup_col_idx:# 遍历数据行(从第2行开始)for row in range(2, ws.max_row + 1): cell = ws.cell(row=row, column=dup_col_idx)if cell.value isTrue:# 对该行的所有单元格加删除线 + 高亮背景for col in range(1, ws.max_column + 1):if col != dup_col_idx: # 跳过辅助列本身 target_cell = ws.cell(row=row, column=col) target_cell.font = Font(strike=True) target_cell.fill = highlight_fill# 删除辅助列 ws.delete_cols(dup_col_idx)# 为所有有数据的单元格添加边框(包括表头)max_row = ws.max_rowmax_col = ws.max_columnfor row in ws.iter_rows(min_row=1, max_row=max_row, max_col=max_col):for cell in row: cell.border = thin_borderwb.save(file_output)print(f"✅ 标记完成(删除线+高亮+边框)!已保存为:{file_output}")🔍 代码解析
这段程序包含7个核心步骤,逐步分析:
-
导入依赖库
import timeimport pandas as pdfrom openpyxl import load_workbookfrom openpyxl.styles import Font, PatternFill, Border, Sidetimestamp = time.strftime("%Y%m%d%H%M%S")file_input = "D:/PythonTest/XX电商运营销售订单明细表-20XX.xlsx"file_output = f"D:/PythonTest/销售订单明细_标记重复_{timestamp}.xlsx"order_col = "销售单号"-
pandas:读取、排序、标记重复行。 -
openpyxl:处理Excel格式(字体、填充、边框)。 -
timestamp:生成时间戳,唯一命名输出文件。 -
file_input:输入文件。 -
file_output:输出文件。 -
order_col:定义主键列。
-
读取数据、排序、标记重复
df = pd.read_excel(file_input)df = df.sort_values(by=order_col)df["_重复标记"] = df.duplicated(subset=order_col, keep="first")-
sort_values:按销售单号排序,相同销售单号连续出现,方便后续标记。 -
df.duplicated(subset=order_col, keep="first"): 返回一个布尔型的Series,长度与DataFrame的行数相同。 -
subset=order_col:设置检查重复的列(通常是一个列名或者是一个列名列表)。 -
keep="first":第2次重复出现的行标记为True,其余行标记为False。 -
df["_重复标记"]=……:将返回的Series赋值给DataFrame的新列_重复标记。
最终效果:_重复标记列中,通过True、False关键字,标识出了该行是否为重复行——即标记为True的行,就是需要标记的重复行。
-
临时保存数据
df.to_excel(file_output, index=False)-
将第 2步处理好的数据暂存放于输出文件中。
-
加载工作表,定义样式
wb = load_workbook(file_output)ws = wb.activehighlight_fill = PatternFill(start_color="FFCCCC", end_color="FFCCCC", fill_type="solid")thin_border = Border( left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))-
load_workbook:读取Excel文件。 -
ws = wb.active:获取当前活跃的工作表。 -
PatternFill:设置单元格背景颜色 -
start_color end_color:颜色 -
fill_type="solid":纯色 -
Border:定义单元格边框样式 -
Side(style='thin'):分别指定左、右、上、下四条边的样式。style='thin'表示细实线边框。 -
thin_border:可以赋值给单元格的border属性,为该单元格添加四周的细边框。
-
标记重复行
header_row = list(ws.iter_rows(min_row=1, max_row=1, values_only=True))[0]dup_col_idx = Nonefor idx, col_name in enumerate(header_row, start=1):if col_name == "_重复标记": dup_col_idx = idxbreakif dup_col_idx:for row in range(2, ws.max_row + 1): cell = ws.cell(row=row, column=dup_col_idx)if cell.value isTrue:for col in range(1, ws.max_column + 1):if col != dup_col_idx: target_cell = ws.cell(row=row, column=col) target_cell.font = Font(strike=True) target_cell.fill = highlight_fill ws.delete_cols(dup_col_idx)总体思路:将重复标记转为样式标记(删除线+背景色)并删除辅助列。
-
ws.iter_rows(min_row=1, max_row=1, values_only=True):获取表头行,返回一个迭代器。 -
list()[0]:将迭代器转为列表,并取第一个元素(即表头行,是一个元组)。 -
values_only=True:只取单元格的值(默认False时返回单元格Cell对象)。 -
遍历表头,找到 _重复标记列的索引(列号)。 -
遍历数据行(从第 2行开始): -
cell = ws.cell(row=row, column=dup_col_idx):获取当前行辅助列单元格。 -
如果该单元格的值为 True(表示是重复记录),则遍历当前行的所有列(跳过辅助列本身),为每个单元格添加删除线和背景色。 -
最后,删除辅助列 _重复标记,使输出文件保持干净。
-
添加边框
max_row = ws.max_rowmax_col = ws.max_columnfor row in ws.iter_rows(min_row=1, max_row=max_row, max_col=max_col):for cell in row: cell.border = thin_border-
遍历所有单元格,添加边框。
-
保存结果
wb.save(file_output)print(f"✅ 标记完成(删除线+高亮+边框)!已保存为:{file_output}")-
保存最终文件,并在控制台输出完成信息。
提示:核心代码
23行(不含导入依赖包、文件路径配置、边框美化等辅助代码)。
第4步:运行
cmd中执行:
python D:\python\mark_duplicate.py看到
标记完成=搞定
第5步:查看效果
打开生成的新文件,即可看到:
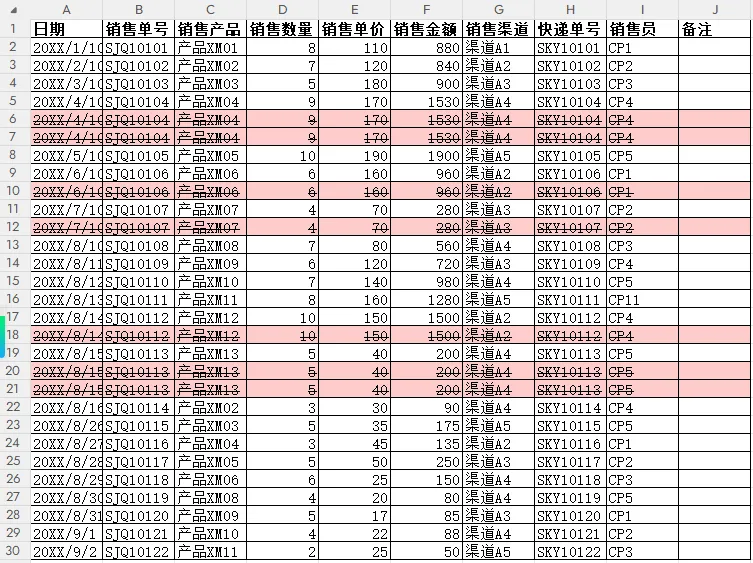
-
重复销售单号挨在一起 -
第一条正常显示 -
后续重复行自动 删除线+ 浅红高亮
扩展思路
-
一键去重:使用
df.drop_duplicates(subset="销售单号", keep="first", inplace=True)-
多列联合:
subset=["销售单号", "客户名称"]为什么用 Python 而不是 Excel 手动?
Excel排序+条件格式也能标记重复行,为何还要用Python程序?
|
|
|
|
|---|---|---|
| 操作成本 |
|
|
| 数据量 |
|
|
| 复用性 |
|
|
| 扩展性 |
|
|
用Python,不是解决一次问题,而是建立一套自动化工作流。
🔗 本系列连载
-
🗂️ 合集:极简编程 -
📖 预告:第7期:Excel数据分列,15行Python一键拆分