 夜雨聆风
夜雨聆风





「无容器」训练AI软件工程师爆了!SWE‑MiniSandbox用namespaces+chroot狂砍95%磁盘,环境准备快75%?
Docker 镜像把训练 SWE Agent 的磁盘和启动时间拖成噩梦。SWE‑MiniSandbox 用namespaces + chroot + bind mount做内核级隔离 + 预缓存:磁盘占用约 5%(≈省 95%)、环境准备约 25%(≈快 75%),评测效果仍接近 Docker 基线。
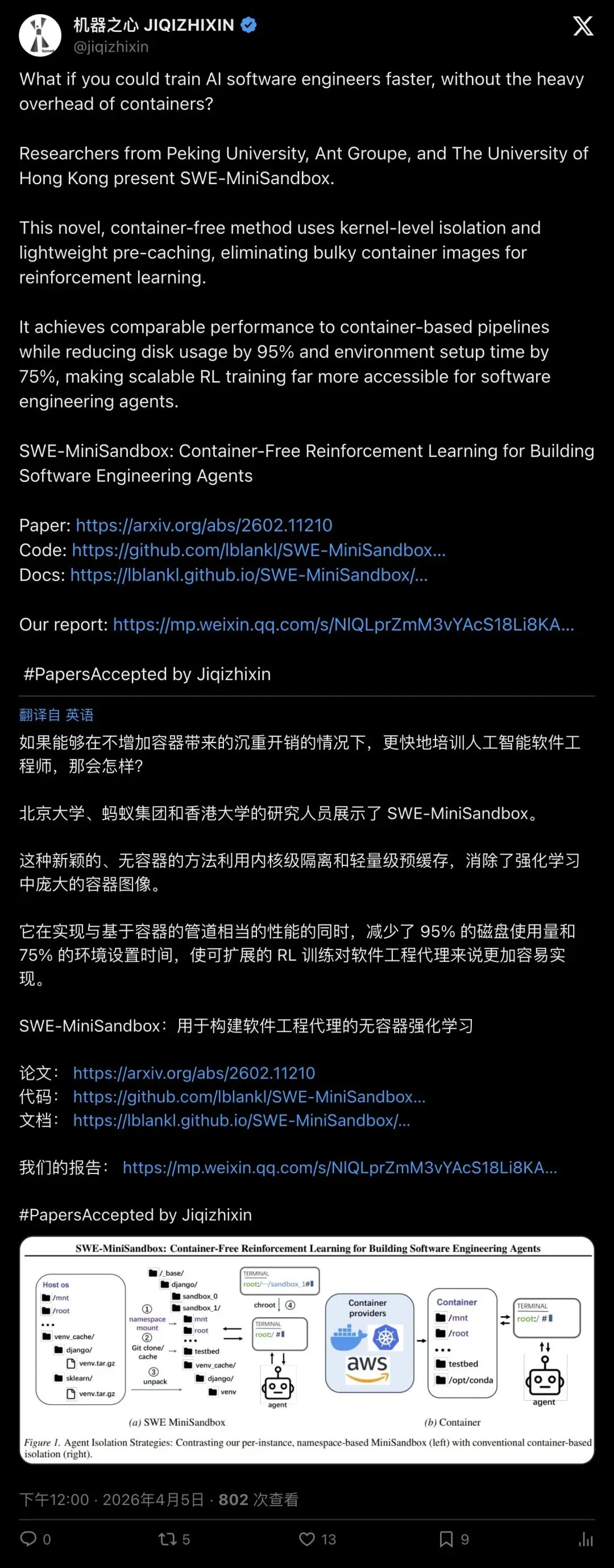
▲ X 上的传播节点总结了最抓眼球的两行:95% disk reduction / 75% setup time reduction(后文会落到论文硬数据)。
🔥 Docker 没拖慢训练,它在“吃掉你的世界”
做 SWE‑bench / SWE‑agent 这类任务,Agent 写完代码还不算完,还要在真实 repo 上反复:checkout → 安装依赖 → 跑测试 → 改代码 → 再跑。
为了避免互相污染,行业惯性会把每个任务关进 Docker。问题在 RL 训练规模化时会变得非常具体:
“At scale, pre-built container images incur substantial storage overhead, slow environment setup, and require container-management privileges.”
「当规模扩大时,预构建容器镜像会带来巨大的存储开销、拖慢环境启动,还要求容器管理权限。」
上面这句来自论文摘要(arXiv:2602.11210)。作者给出的解决思路很直接:把“隔离”交回 Linux 内核,把“镜像”变成缓存。
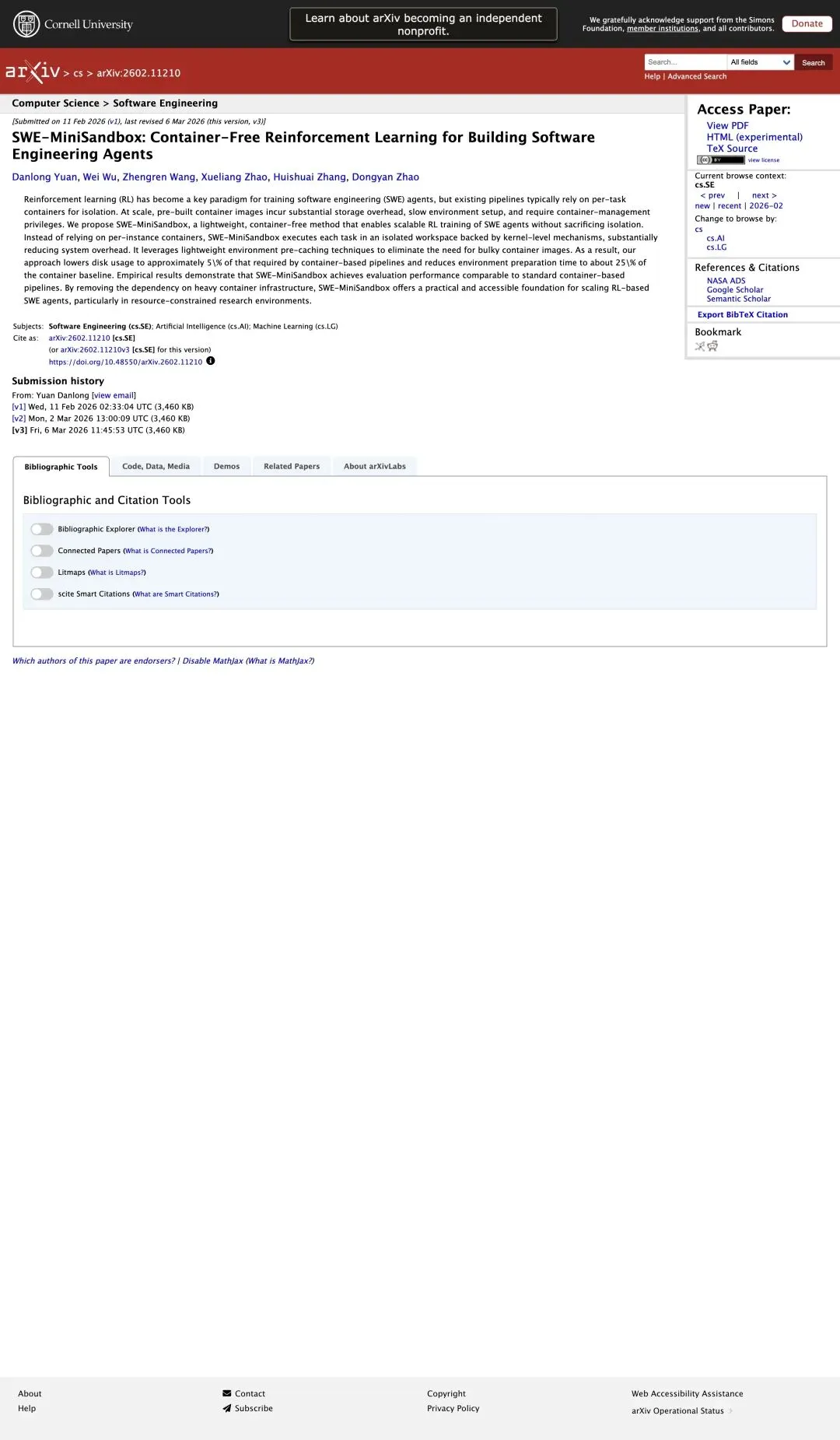
▲ 论文摘要页:直接写明 disk usage ≈5%,env prepare time ≈25%。
🧩 SWE‑MiniSandbox 到底做了什么?三件武器:namespaces + chroot + bind mount
SWE‑MiniSandbox 自己在 README 里把底层方案写得很清楚:
“The framework relies on Linux namespaces, `chroot`, and bind mounts … while remaining isolated from one another.”
「框架依赖 Linux 命名空间(namespaces)、`chroot` 与 bind mount,在保证彼此隔离的同时提供高效环境。」
它的“无容器”并不等于“无隔离”,而是绕开了重量级镜像分发与运行时编排:
- namespaces
:隔离资源视图(尤其 mount namespace 等) - chroot
:把进程根目录切到任务工作区(让实例“看不到”宿主其它路径) - bind mount
:把必须的系统目录按需挂载进来,共享而不拷贝

▲ GitHub README:明确点名Linux namespaces / chroot / bind mounts。
📉 295GB → 13.5GB:为什么说“省 95% 磁盘”不是标题党?
论文在方法部分的 Table 1 直接给了“最适合当爆点”的对比:
- SWE‑smith(50k tasks)
-
容器镜像(image reuse 基线):295 GB -
MiniSandbox 环境缓存(ours):13.5 GB -
约5%(也就是“省掉约 95%”)
并且作者在正文里把结论写成一句话:
“… cutting the environment cache size to roughly 5% (13.5 GB vs. 295 GB) …”
「把环境缓存规模压到容器方案的大约 5%(13.5GB 对 295GB)。」
很多人第一次看到这个数字会以为是“魔法”。其实它的核心是:不再保存完整 OS/镜像层,而是保存更轻量、可复用的任务环境产物。
⏱ 88.86 秒 → 23.62 秒:环境准备时间只剩四分之一
“快 75%”同样不是口嗨。
Table 2 给的平均环境准备时间(Env Prepare Time)很扎眼:
-
3B‑docker:88.86s -
3B‑MiniSandbox:23.62s
换算一下:23.62 / 88.86 ≈26.6%,和摘要里“about 25% baseline”高度一致。
“… reduces environment preparation time to about 25% of the container baseline.”
「环境准备时间降低到容器基线的大约 25%。」

▲ 一位研究者在 X 上把这事总结成一句话:用Linux namespaces + chroot替换 Docker,存储降到 5%,setup time 降 75%。
🧠 真正的“关键缓存”在 Python venv:他们刻意避开 Conda env
这篇工作有个非常工程化、但决定成败的选择:用 venv 做隔离与复用。
“We deliberately use Python venv for environment isolation rather than Conda environments. Conda environments are significantly larger and more complex … In contrast, a typical venv for our tasks requires only about 100 MB …”
「他们刻意用 Python venv 做环境隔离,而不选 Conda env;因为 Conda 更大更复杂,会引入巨量 I/O。相对地,这些任务的 venv 通常只要约 100MB。」
一句话理解:Docker 镜像里“最肥”的部分被抛弃后,真正需要复用的长期产物往往就是Python 依赖环境 + repo 工作区。
🚧 去了容器也会被 I/O 卡住:他们用 Ray 做“并发限流”
作者并没有把故事讲成“从此天下太平”。他们在 4.2.2 直接承认:预缓存之后,创建沙盒主要成本会变成解压/复制的 I/O,并发一高,磁盘照样会被打爆。
他们的解法是给环境准备阶段做“有界窗口(bounded window)”:
-
用Ray resource tags+semaphore控制同时解压的数量 -
用一个简化的 I/O budget 模型(∑ b_j ≤ B)解释为什么需要限流
这类系统工程味道,是很多“只写模型分数”的论文里见不到的。
⚔️ 路线之争来了:去容器派 vs 压缩容器派
有意思的是,社区里也有人追问:收益到底来自“去容器”,还是来自“把环境做得更聪明”?
在一个 GitHub issue 讨论里,有人建议把 LogicStar 这类“压缩容器到极致”的方案加入对照。
▲ Issues 里出现了“系统基线对照”的讨论:大家都想知道 MiniSandbox 的收益来源。
LogicStar 的路线非常硬核:保留容器,但把 SWE‑Bench Verified 的镜像体系“瘦身”到离谱:
“… shrank SWE-Bench Verified from 240 GiB to just 5 GiB. Now it downloads in under a minute …”
「把 SWE‑Bench Verified 从 240GiB 压到 5GiB,现在一分钟内就能下载完成。」
同一个终点(更便宜、更快的可执行环境),两条路:
-
MiniSandbox:内核隔离 + 轻量缓存 -
LogicStar:容器分层/打包/压缩工程到极限
接下来谁会赢?很可能取决于你的需求:你更在意“无需容器权限、部署更轻”,还是更在意“生态兼容、依然走 OCI”。
⚠️ 别把“无容器”当成“无风险”:隔离强度要讲清楚
写到这里必须泼一盆冷水:MiniSandbox 依然是同一台宿主机、同一个 kernel上跑不可信代码。
它能大幅减少镜像与启动开销,但如果你的 threat model 是“对抗性代码/逃逸攻击”,容器、gVisor、微虚拟机(microVM)等方案仍然有讨论空间。
更准确的表述应该是:它把训练/评测的工程瓶颈从“镜像地狱”挪回了“内核隔离 + I/O 调度”这个更轻的底座。
结尾:AI 软件工程师的“下一道门槛”,正在从模型变成系统
过去两年大家盯着模型参数、上下文长度、工具调用。
这篇工作提醒我们:当你真去训练一个能在 repo 里跑来跑去的 SWE Agent,系统层的效率会决定你能不能把实验做成、能不能把 RL 跑起来。
省下的 95% 磁盘、快出来的 75% 准备时间,看起来像“工程优化”。
可当它把一套训练从“只有少数大厂/大实验室能跑”拉到“普通研究者也能跑”,这就是下一轮 SWE Agent 竞赛的入场券。
— END —