夜雨聆风
夜雨聆风





从源码角度聊聊 Claude Code 和 OpenCode 的效果区别
Agent 框架是模型能力的放大器。同一个模型,接上不同的 Agent 框架,效果可以差很多。Claude Code 在上下文管理、提示词工程、Agent 通信、工具编排四个维度上的工程投入,远超 OpenCode 一个量级。这些看不见的基础设施,决定了模型能力的发挥上限。

上下文管理:差距最大的地方
这是两者之间最核心的差异。
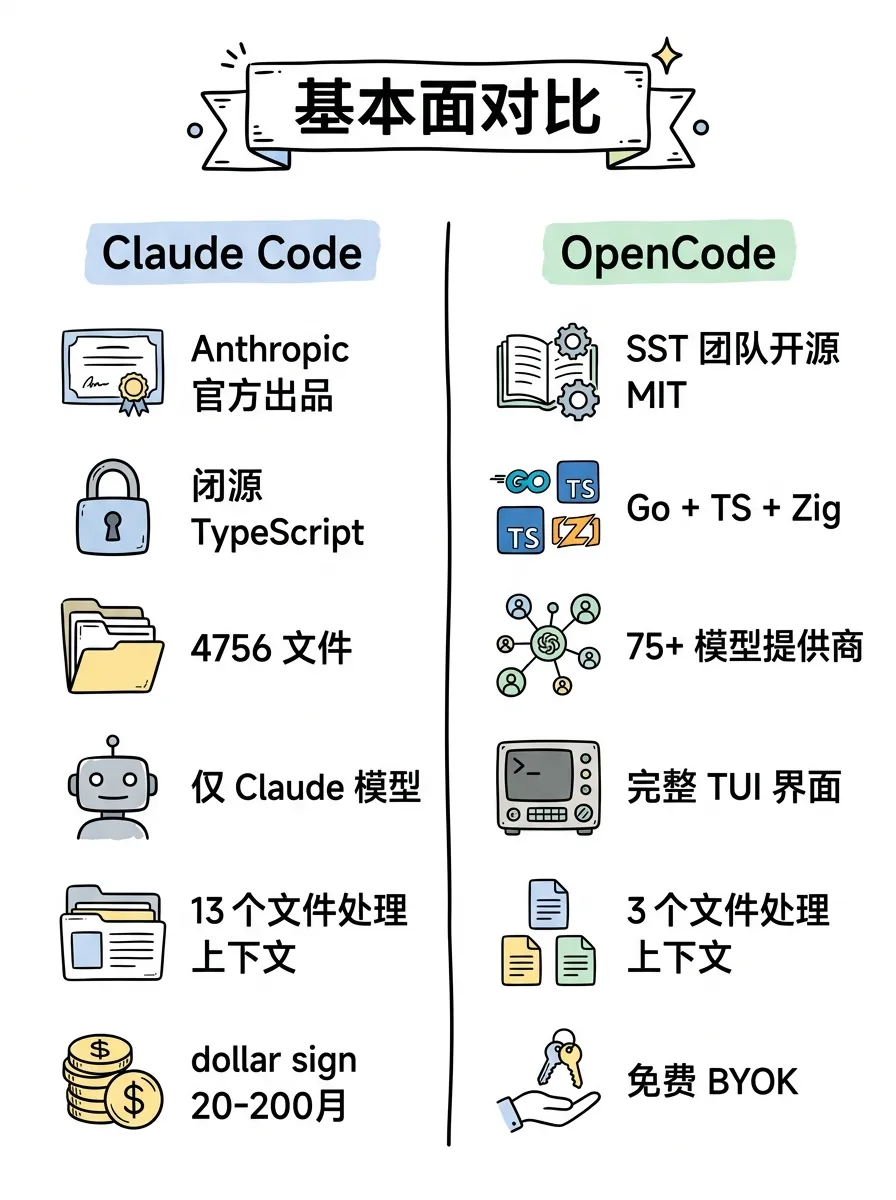
Claude Code 做了三层递进压缩。
第一层叫 Micro Compact,零 API 调用。它维护了一个 COMPACTABLE_TOOLS 集合,只清理 FileRead、Bash、Grep 这些工具产生的大量输出。这一层不调模型,纯靠 token 估算裁剪旧数据,开销为零。
第二层叫 Session Memory Compact。它会从对话历史里提取结构化的”会话记忆”:做了什么决策、发现了什么、当前在编辑哪些文件。保留最近 10K-40K tokens 的原始消息,更早的部分压缩成记忆摘要。这个配置还能远程动态调整。
第三层是 Full Compact,Fork 出一个专用 agent 来生成完整的对话摘要。走到这一步才会真正消耗一次 API 调用。
触发机制也很精细。autoCompact.ts 里有多级 token 阈值:8K 的自动压缩缓冲区、20K 的警告阈值、3K 的手动压缩缓冲区。还有个熔断器,连续失败 3 次后停止重试。代码注释里写着:2026 年 3 月发现有 1279 个 session 连续失败 50 次以上,每天浪费了 25 万次 API 调用。
OpenCode 只有一层。
overflow.ts 全部 22 行代码,判断逻辑就是 token 用量超过阈值就触发。压缩策略是从后往前遍历消息,保留最近 40K tokens 的工具调用,清理更早的输出。然后用 LLM 生成一段摘要,模板是固定的 Goal/Instructions/Discoveries/Accomplished/Relevant files 五段式。
没有 Micro Compact 层,没有 Session Memory 中间层,没有 Cached Microcompact。每次压缩都要调一次模型。
这个差距直接影响长对话的质量。Claude Code 在对话进行到第 50 轮的时候,模型看到的上下文依然是经过精心筛选的高质量信息。OpenCode 到这个阶段,要么上下文已经被粗暴截断,要么摘要丢失了关键细节。
提示词管理:看不见的 Prompt Cache
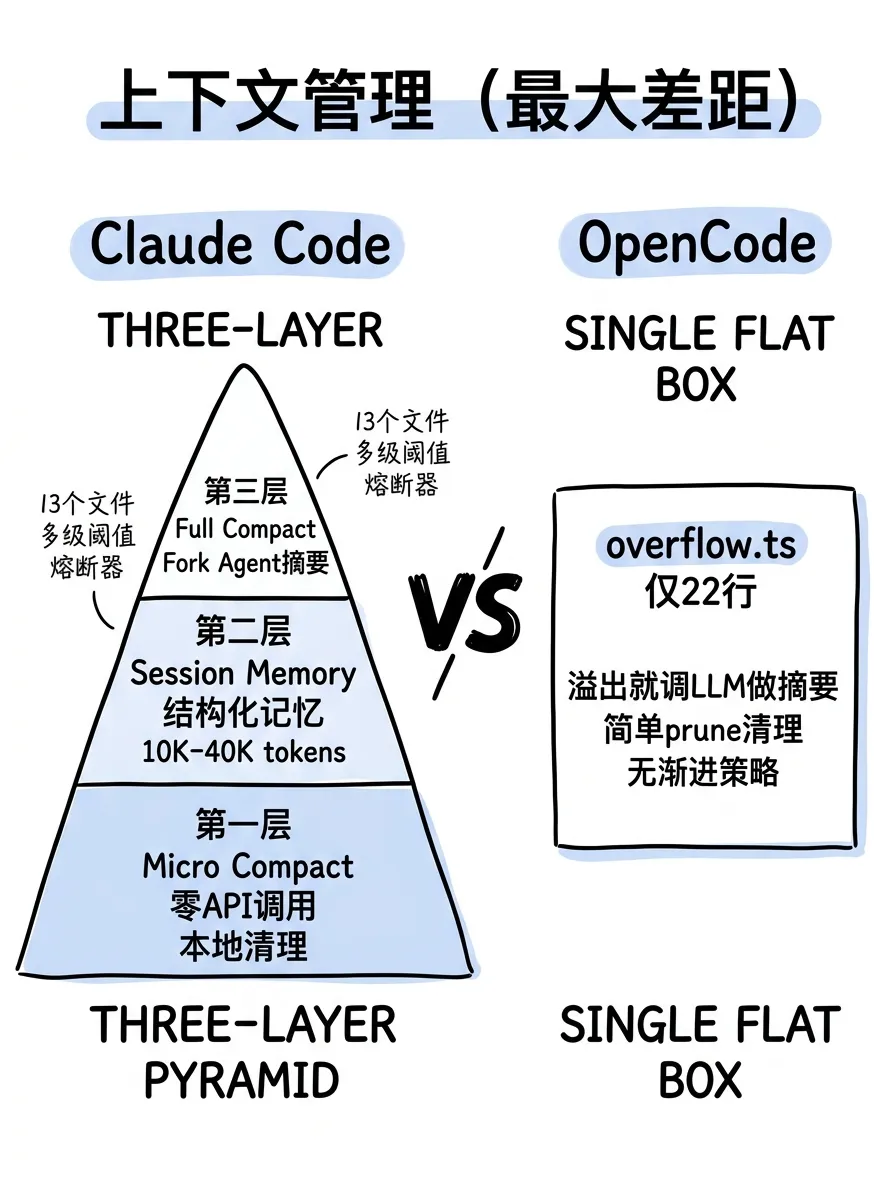
Claude Code 在 system prompt 里埋了一个叫 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 的标记,把提示词切成两半。
标记之前的部分大约 5K tokens,是所有用户共享的静态内容,标注为 scope: 'global',走跨用户的 prompt cache。标记之后是用户特定的动态内容:环境信息、CLAUDE.md 配置、MCP 工具列表这些。
这个设计的效果是:静态部分的缓存命中率极高,每次 API 调用省下大量计算。代码注释里提到了 Blake2b 哈希变体爆炸的问题,如果把 session 变量放在静态区域,会产生 2^N 种缓存键,cache 就废了。
还有一个细节:Fork agent(子 agent 的一种)直接复用父进程已渲染的系统提示字节缓冲区,做到字节级精确匹配来共享 prompt cache。这意味着创建子 agent 几乎没有额外的 prompt 处理开销。
CLAUDE.md 是 4 层加载:managed(企业管理员)→ user(用户全局)→ project(项目根目录)→ local(当前目录),支持 @include 指令引入其他文件。
OpenCode 的提示词管理就简单得多。system.ts 里根据模型 ID 做字符串匹配,分发 6 套不同的 prompt 模板:anthropic.txt、gpt.txt、gemini.txt 等。缺少 prompt cache 优化点,没有静态/动态分割。
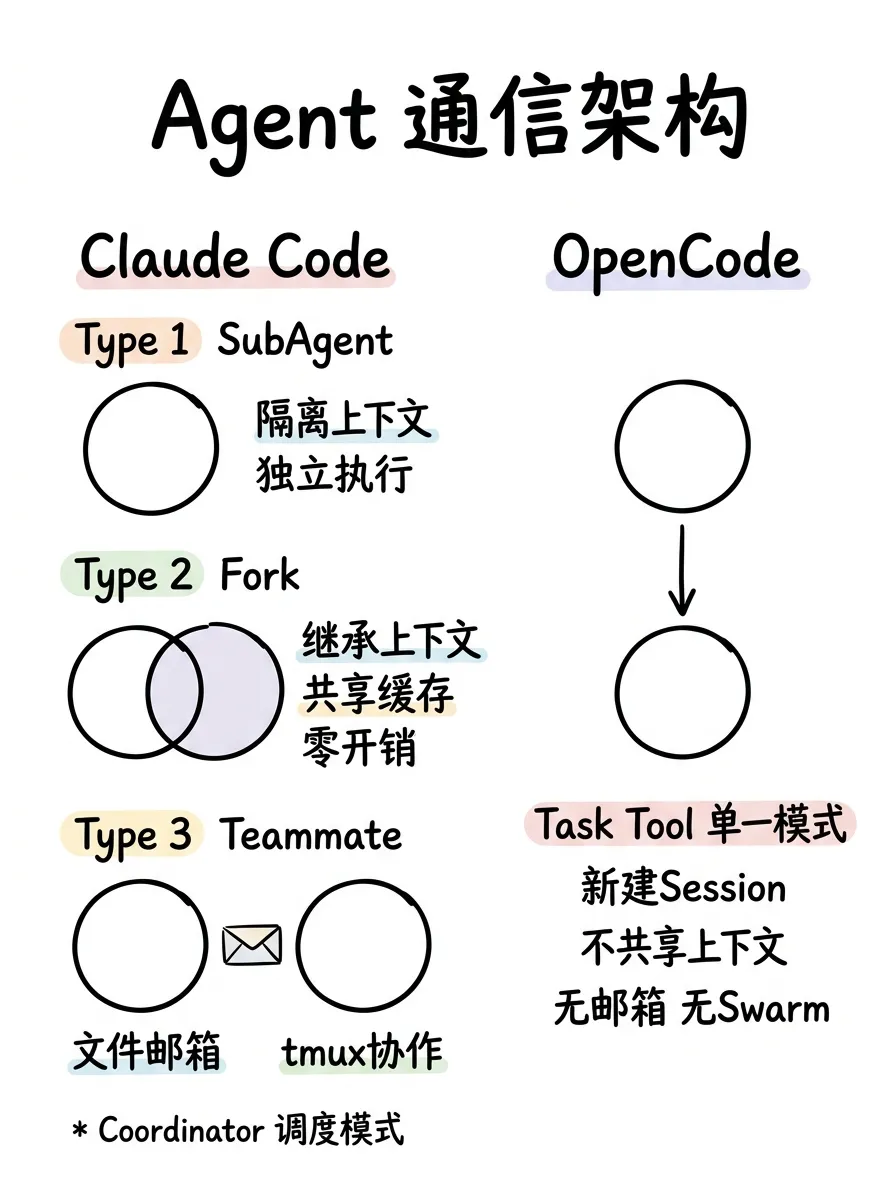
Agent 通信:三种隔离级别 vs 单一模式
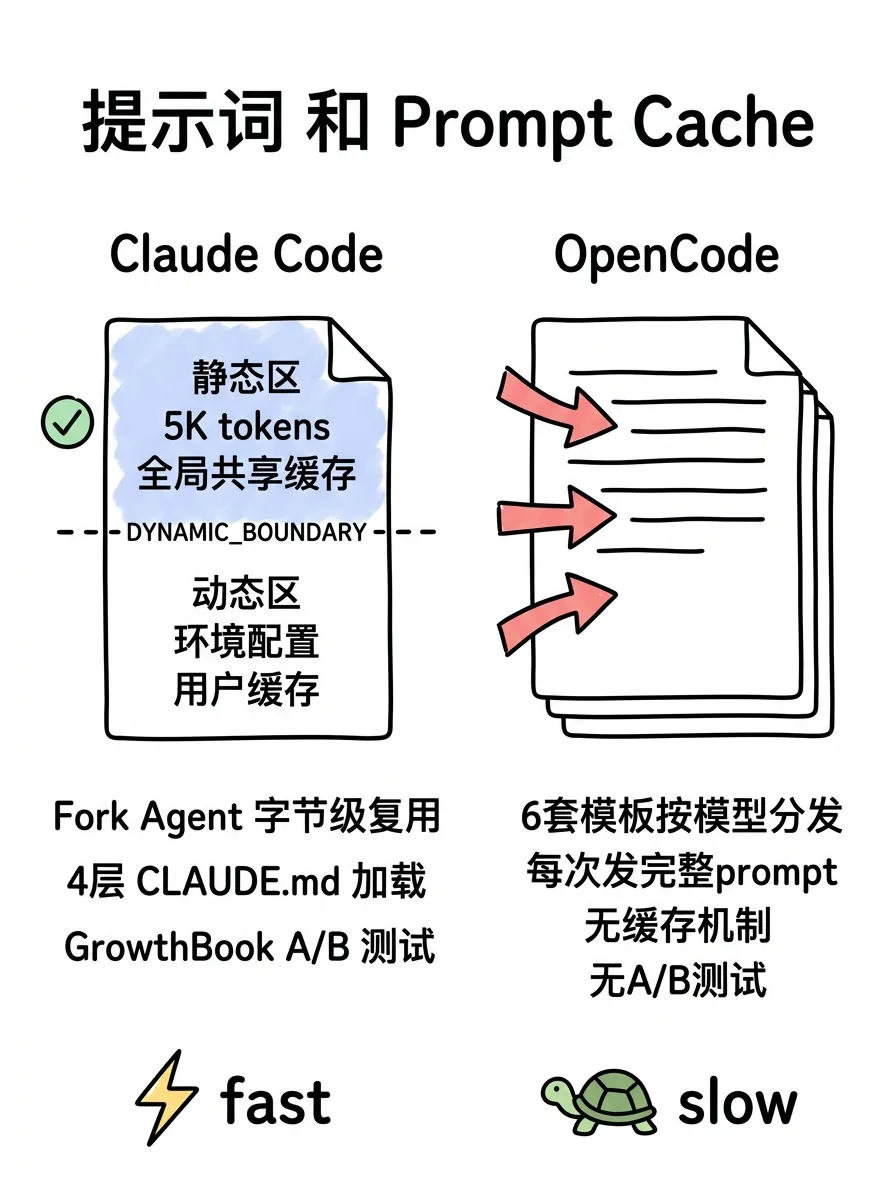
Claude Code 有三种 Agent 类型。
SubAgent:完全隔离的上下文,独立工具池,适合不需要父上下文的独立任务。
Fork:继承父进程的完整对话历史和系统提示,共享 prompt cache。forkSubagent.ts 里定义了 FORK_AGENT,tools: ['*'] 继承所有工具,model: 'inherit' 继承父模型,permissionMode: 'bubble' 把权限请求冒泡到父终端。这种 agent 的启动成本几乎为零。
Teammate:独立进程,通过 ~/.claude/mailbox/ 文件系统邮箱通信,支持 tmux、iTerm2、in-process 三种运行后端。还有 Coordinator Mode,实现用户面向的调度器加多个工人 agent 的模式。
OpenCode 只有 Task Tool 这一种模式。task.ts 里的逻辑是:每次创建子 agent 都新建一个 session,parentID: ctx.sessionID 建立父子关系,但不共享上下文。agent 定义也更简单:name、mode(subagent/primary/all)、model、prompt。
没有 Fork(共享缓存的子 agent),没有文件系统邮箱,没有 swarm 后端切换。
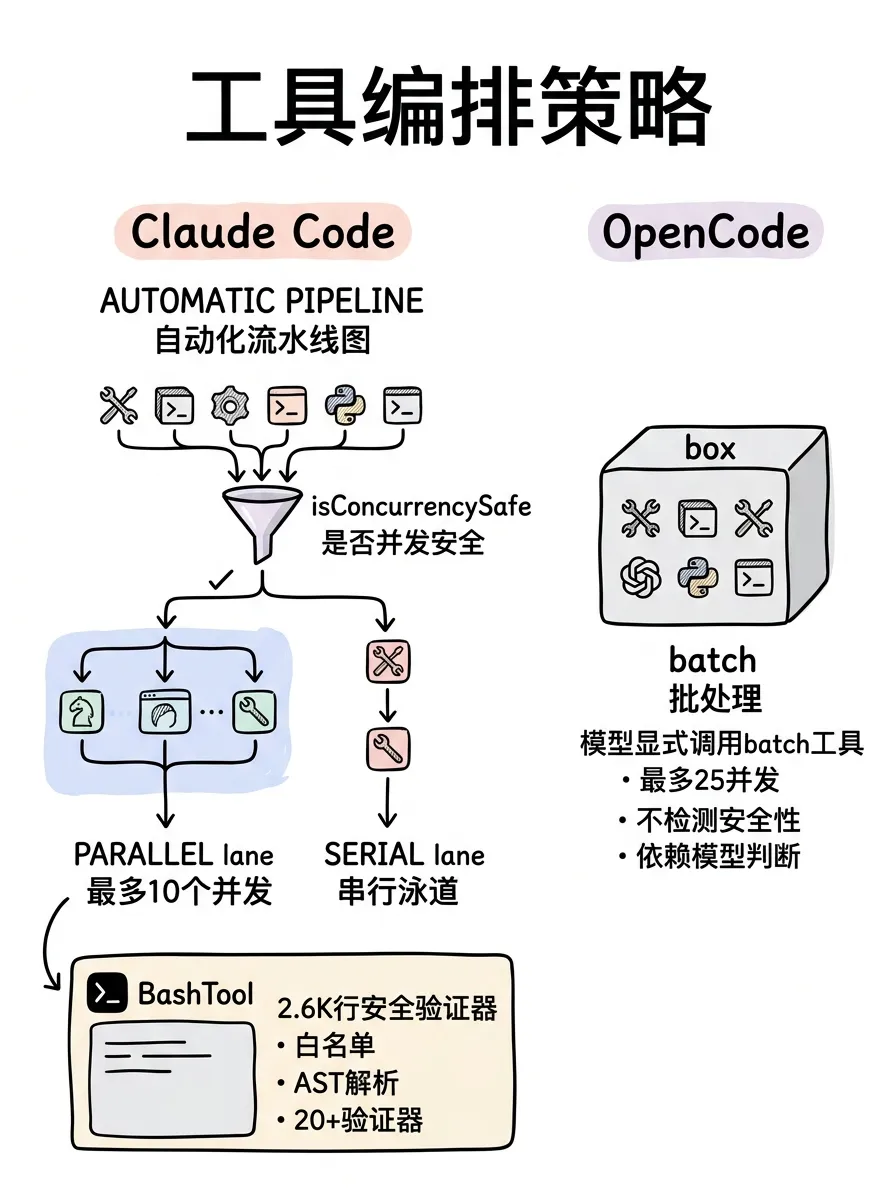
工具编排:自动并行 vs 手动批处理
Claude Code 的 toolOrchestration.ts 实现了自动化的并行分区策略。每个工具都声明了 isConcurrencySafe() 方法,框架自动把连续的安全工具合并成并行批次(最多 10 并发),写入操作自动走串行。模型不需要操心哪些工具能并行,框架替它做了决策。
OpenCode 用的是 Batch Tool 模式。模型需要显式调用 batch 工具,把要并行的调用包在一个数组里,最多 25 个并发。并行决策权完全交给模型,框架不做安全检查。
还有个明显差距:Claude Code 的 BashTool 有 2600 行的安全验证器,白名单检查 → AST 解析 → 20 多个专项验证器层层过滤。OpenCode 的 bash 安全机制相对基础。
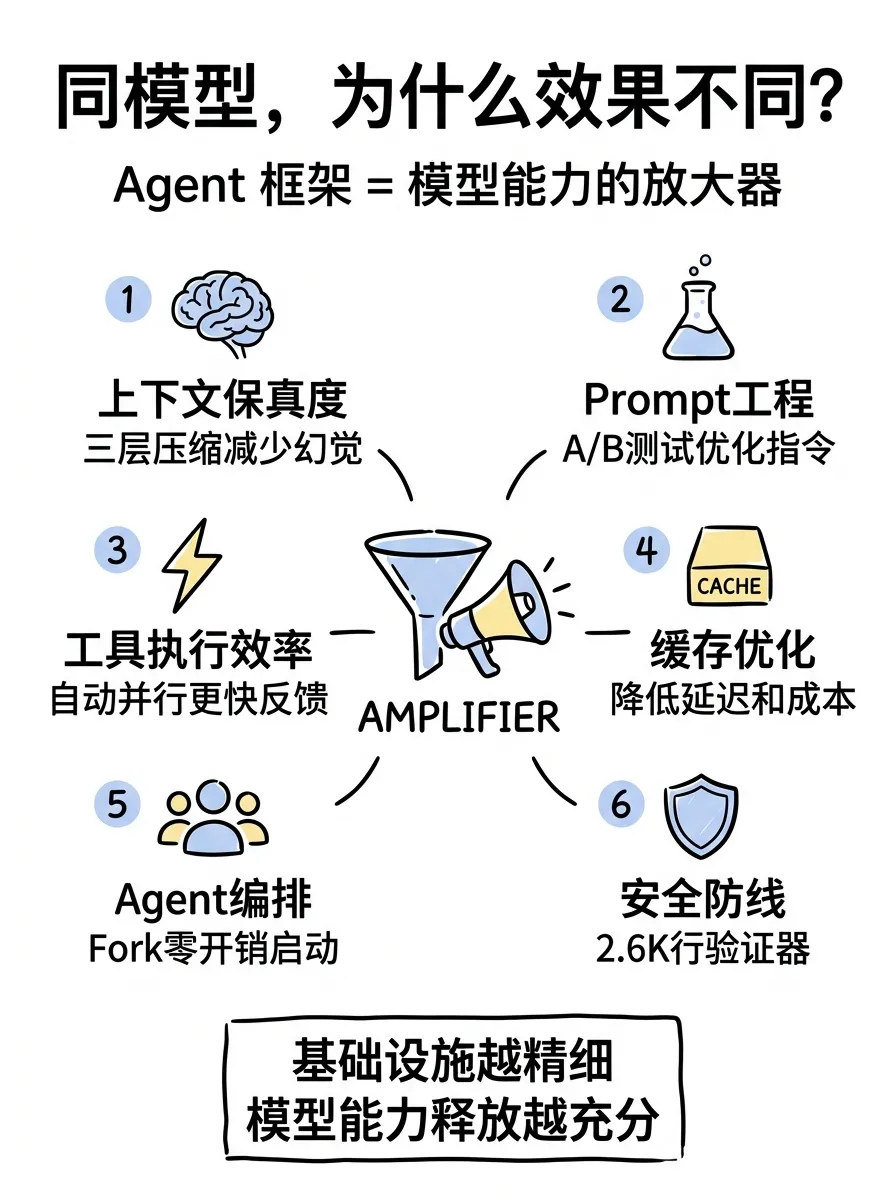
为什么同模型下效果不同
拆完代码后,原因就很清楚了:
上下文保真度。长对话中 Claude Code 的三层压缩确保模型始终看到高质量的上下文信息,减少幻觉和遗忘。OpenCode 的单层压缩在长任务中信息损失更大。
Prompt 工程深度。Claude Code 的 system prompt 经过 GrowthBook 特性开关做 A/B 测试迭代,精细到每个条件分支是否会破坏 cache 前缀。OpenCode 的 prompt 是相对静态。
工具执行效率。自动并行化让 Claude Code 的反馈循环更快。模型发出 5 个 Read 指令,框架自动并行执行;OpenCode 需要模型自己判断,多一轮决策开销。
缓存复用。Prompt cache 和 Fork 共享缓存两个机制叠加,Claude Code 的延迟更低、成本更低,同样的预算下能跑更多的推理步骤。
这四个因素叠加起来,就是同一个 Claude 模型在两个框架上表现差异的根源。Agent 框架相当于模型能力的放大器,基础设施越精细,模型能力释放得越充分。
OpenCode 的价值在哪
话说回来,OpenCode 有自己的优势。
75+ 模型提供商支持意味着你可以用 DeepSeek 做规划、用 Claude 做编码、用本地模型处理敏感代码。这种灵活性是 Claude Code 做不到的。完整的 TUI 界面(Zig 渲染后端)比 Claude Code 的 REPL 输出体验好得多。Effect-TS 的依赖注入架构让代码的可测试性更好。120K+ 的 GitHub star 也说明开源社区对它的认可。
如果你的场景是成本敏感、需要多模型切换、或者有隐私合规要求必须本地部署,OpenCode 是更合理的选择。
总结
从代码层面看,Claude Code 和 OpenCode 的差距集中在基础设施的精细程度上。Claude Code 用 13 个文件实现三层上下文压缩,用 DYNAMIC_BOUNDARY 标记优化 prompt cache,用三种 Agent 类型覆盖不同协作场景,用自动并行分区提升工具执行效率。这些工程投入不体现在功能列表里,但直接决定了用户体验。
OpenCode 的技术选型和架构设计没有问题,Go + TypeScript + Zig 的组合甚至更现代。但在 Agent 框架的深度优化上,和 Anthropic 投入数百名工程师打磨的产品还有明显差距。这个差距不是模型能力的差距,是工程投入的差距。