 夜雨聆风
夜雨聆风





Hermes Agent 源码解析:A Closed Learning Loop 是如何让 Agent 越用越聪明的?
最近 Hermes Agent 势头很猛,在推特上异常火爆,并且今天登上了 Github Trending top1,当前 50.6K star,涨势凶猛。
Hermes Agent 是今年 2月 Nous Research 开源的自托管智能体框架,它被认为是 OpenClaw 上线以来第一个真正意义上的竞争对手,我自己用了一周,也觉得这个 “爱马仕” 比 “小龙虾” 似乎更聪明。
Hermes Agent 与 OpenClaw 设计的最大不同是,它的设计自带就拥有一套闭环学习循环 A Closed Learning Loop,通过 触发 -> review -> 写回 -> 再注入 把 self-improving 飞轮真正意义上跑通。
本文我们结合源码,一起探索下面两个问题的答案:
为什么 Hermes Agent 能越用越聪明?
Hermes 到底是怎么把 closed learning loop 做成一个能持续运转的 self-improving 飞轮的?
系统架构概览
如果先把模型和具体任务都放一边,Hermes 整个运行系统大致可以拆成三层:用户界面层、核心代理层、执行后端层。
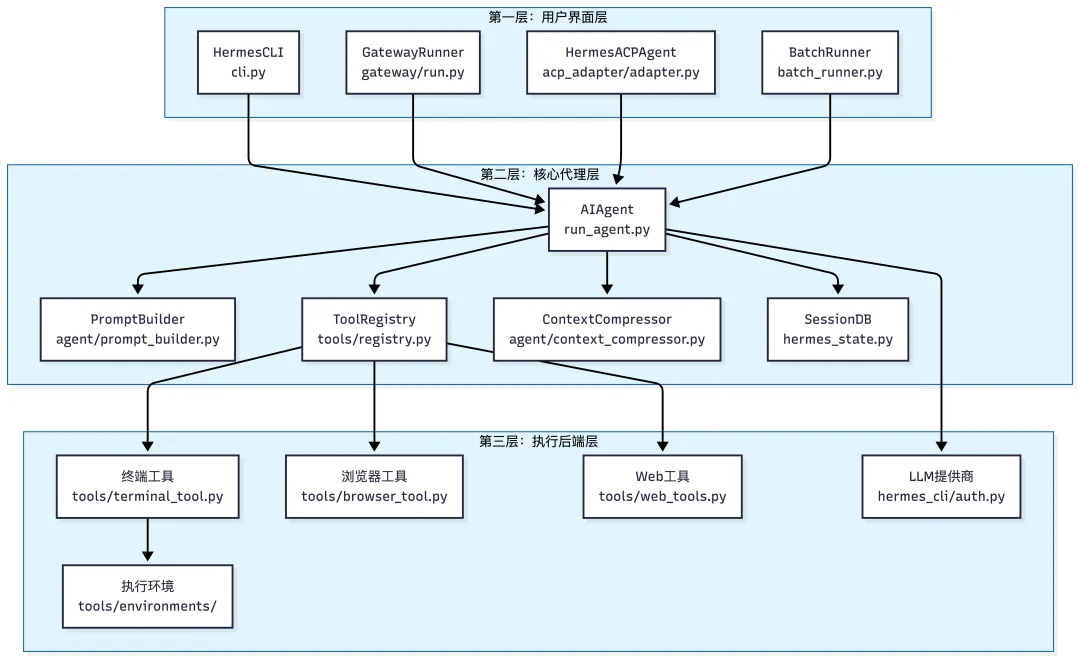
真正把 closed learning loop 跑起来的核心,主要都落在中间这一层,尤其是 AIAgent、PromptBuilder、SessionDB 和工具系统的衔接上。
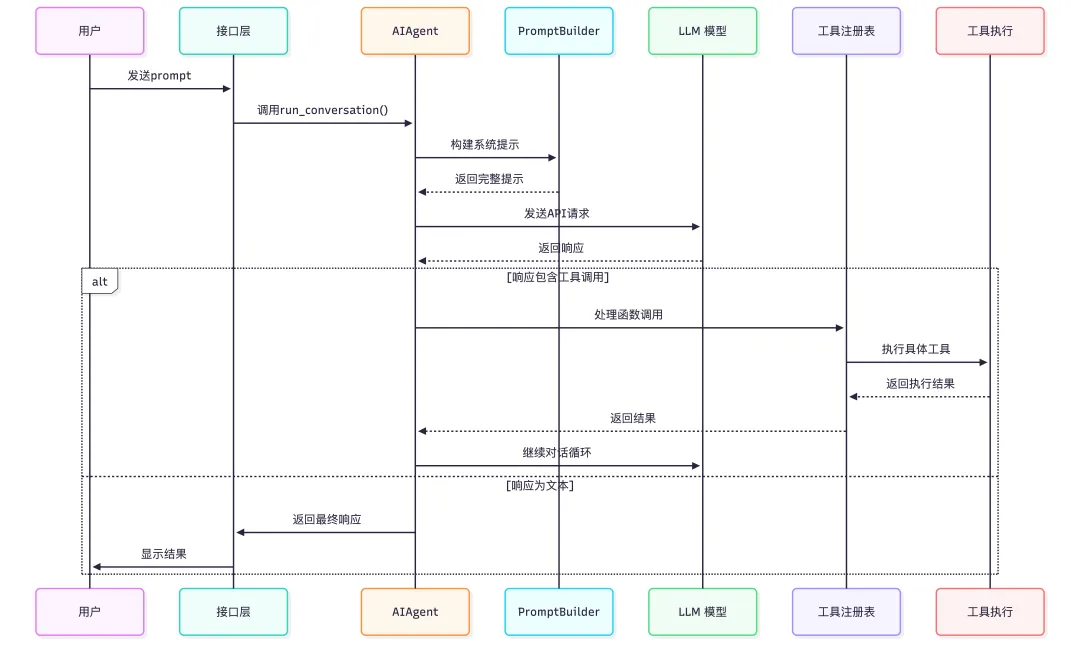
用户发出 prompt 后,Hermes 是怎么运转起来的
看完整体架构之后,再顺一遍主执行链路,后面再看 closed learning loop 是怎么插进去的,会更容易理解。
学习闭环循环是如何转起来的 (A Closed Learning Loop)
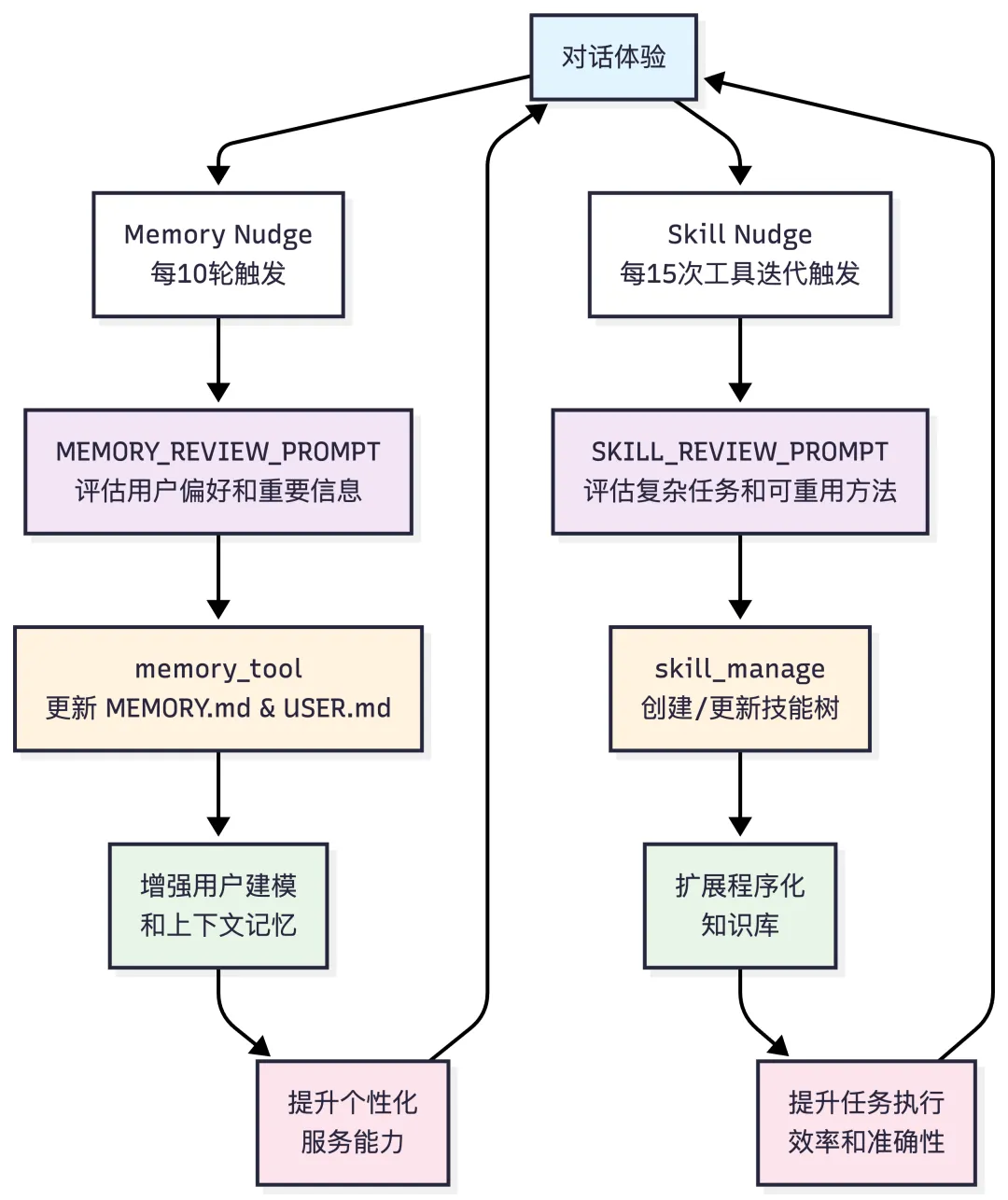
Self-Improving 飞轮机制
1. 经验积累阶段
-
• 对话体验: Agent 通过与用户交互获得经验 -
• Memory Nudge: 每10轮对话触发记忆审查 -
• Skill Nudge: 每15次工具迭代触发技能审查
2. 知识提取阶段
-
• MEMORY_REVIEW_PROMPT: 评估用户偏好、期望和重要信息 -
• SKILL_REVIEW_PROMPT: 评估复杂任务、试错过程和可重用方法
3. 知识固化阶段
-
• memory_tool: 更新 MEMORY.md(环境事实)和 USER.md(用户档案) -
• skill_manage: 创建新技能或更新现有技能
4. 能力提升阶段
-
• 增强用户建模: 更好的个性化服务 -
• 扩展知识库: 更高效的任务执行
5. 飞轮闭环
提升的能力带来更好的对话体验,形成正向循环。
关键要点
-
• 整个学习循环通过 spawn_background_review在后台异步执行 -
• Memory 系统提供声明性知识(知道什么),Skills 系统提供程序性知识(知道怎么做) -
• 两个系统相互补充,共同构建 Agent 的智能基础 -
• 这是一个真正的自改进系统,无需人工干预即可持续进化
Self-Improving 飞轮实现
spawn_background_review 触发流程
前面的图是抽象层,真正落到源码里,closed learning loop 的关键入口就是 _spawn_background_review。
触发之后,它会异步执行 review,不影响主对话流程。
系统维护两个计数器决定何时触发review
-
• _turns_since_memory– 距离上次记忆review的轮数 -
• _iters_since_skill– 距离上次技能review的轮数
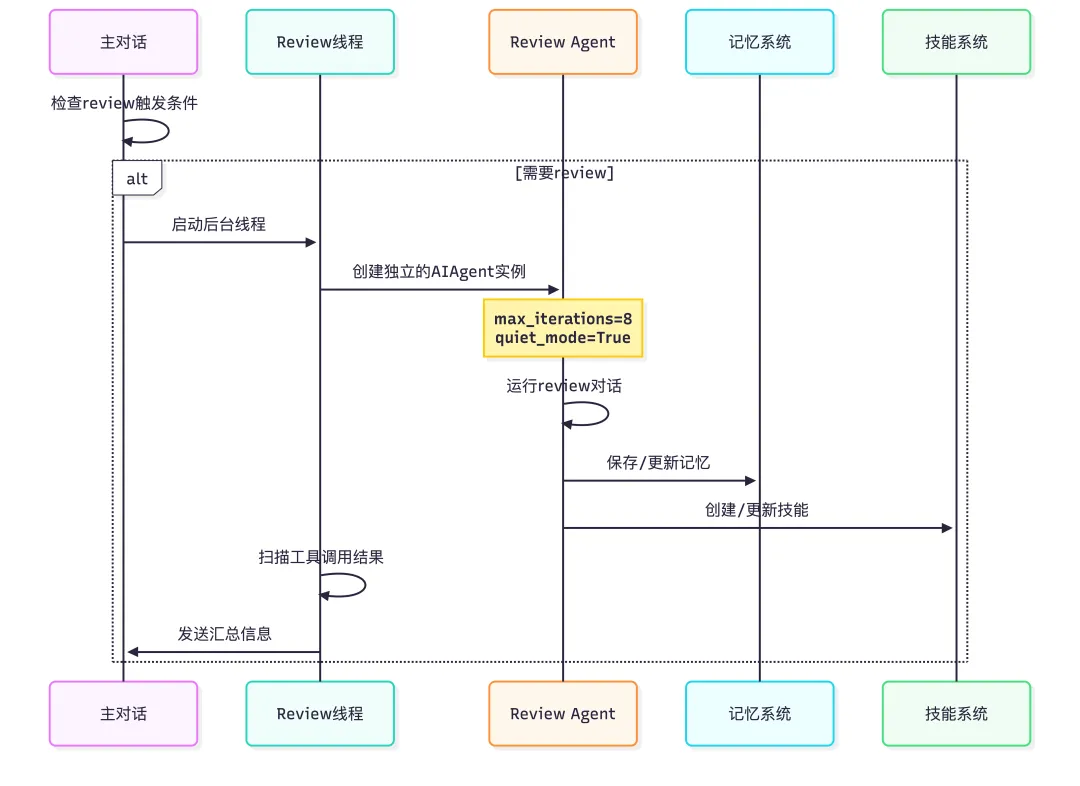
Skill Nudge:基于工具调用次数触发
Skill nudge 适合在复杂任务后创建可重用的技能
-
• 默认触发间隔:每 15 次工具调用触发一次 -
• 配置位置: config.yaml中的skills.creation_nudge_interval,默认值15 -
• 计数器: _iters_since_skill在每次工具调用后递增
Memory Nudge:基于对话轮次触发
Memory nudge 适合定期保存用户偏好和重要信息
-
• 默认触发间隔:每 10 轮对话触发一次 -
• 配置位置: config.yaml中的memory.nudge_interval默认值是10 -
• 计数器: _turns_since_memory在每轮对话开始时递增
spawn_background_review 核心代码
这里会按需进行 review_memory 以及 review_skills
def _spawn_background_review( self, messages_snapshot: List[Dict], review_memory: bool = False, review_skills: bool = False,) -> None: """Spawn a background thread to review the conversation for memory/skill saves. Creates a full AIAgent fork with the same model, tools, and context as the main session. The review prompt is appended as the next user turn in the forked conversation. Writes directly to the shared memory/skill stores. Never modifies the main conversation history or produces user-visible output. """ import threading # Pick the right prompt based on which triggers fired if review_memory and review_skills: prompt = self._COMBINED_REVIEW_PROMPT elif review_memory: prompt = self._MEMORY_REVIEW_PROMPT else: prompt = self._SKILL_REVIEW_PROMPT def _run_review(): import contextlib, os as _os review_agent = None try: with open(_os.devnull, "w") as _devnull, \ contextlib.redirect_stdout(_devnull), \ contextlib.redirect_stderr(_devnull): review_agent = AIAgent( model=self.model, max_iterations=8, quiet_mode=True, platform=self.platform, provider=self.provider, ) review_agent._memory_store = self._memory_store review_agent._memory_enabled = self._memory_enabled review_agent._user_profile_enabled = self._user_profile_enabled review_agent._memory_nudge_interval = 0 review_agent._skill_nudge_interval = 0 review_agent.run_conversation( user_message=prompt, conversation_history=messages_snapshot, ) # Scan the review agent's messages for successful tool actions # and surface a compact summary to the user. actions = [] for msg in getattr(review_agent, "_session_messages", []): if not isinstance(msg, dict) or msg.get("role") != "tool": continue try: data = json.loads(msg.get("content", "{}")) except (json.JSONDecodeError, TypeError): continue if not data.get("success"): continue message = data.get("message", "") target = data.get("target", "") if "created" in message.lower(): actions.append(message) elif "updated" in message.lower(): actions.append(message) elif "added" in message.lower() or (target and "add" in message.lower()): label = "Memory" if target == "memory" else "User profile" if target == "user" else target actions.append(f"{label} updated") elif "Entry added" in message: label = "Memory" if target == "memory" else "User profile" if target == "user" else target actions.append(f"{label} updated") elif "removed" in message.lower() or "replaced" in message.lower(): label = "Memory" if target == "memory" else "User profile" if target == "user" else target actions.append(f"{label} updated") if actions: summary = " · ".join(dict.fromkeys(actions)) self._safe_print(f"{summary}") _bg_cb = self.background_review_callback if _bg_cb: try: _bg_cb(f"{summary}") except Exception: pass except Exception as e: logger.debug("Background memory/skill review failed: %s", e) finally: # Explicitly close the OpenAI/httpx client so GC doesn't # try to clean it up on a dead asyncio event loop (which # produces "Event loop is closed" errors in the terminal). if review_agent is not None: client = getattr(review_agent, "client", None) if client is not None: try: review_agent._close_openai_client( client, reason="bg_review_done", shared=True ) review_agent.client = None except Exception: pass t = threading.Thread(target=_run_review, daemon=True, name="bg-review") t.start()技能进化飞轮
Skill Nudge -> Skill Review -> skill_manage(Create/Patch)
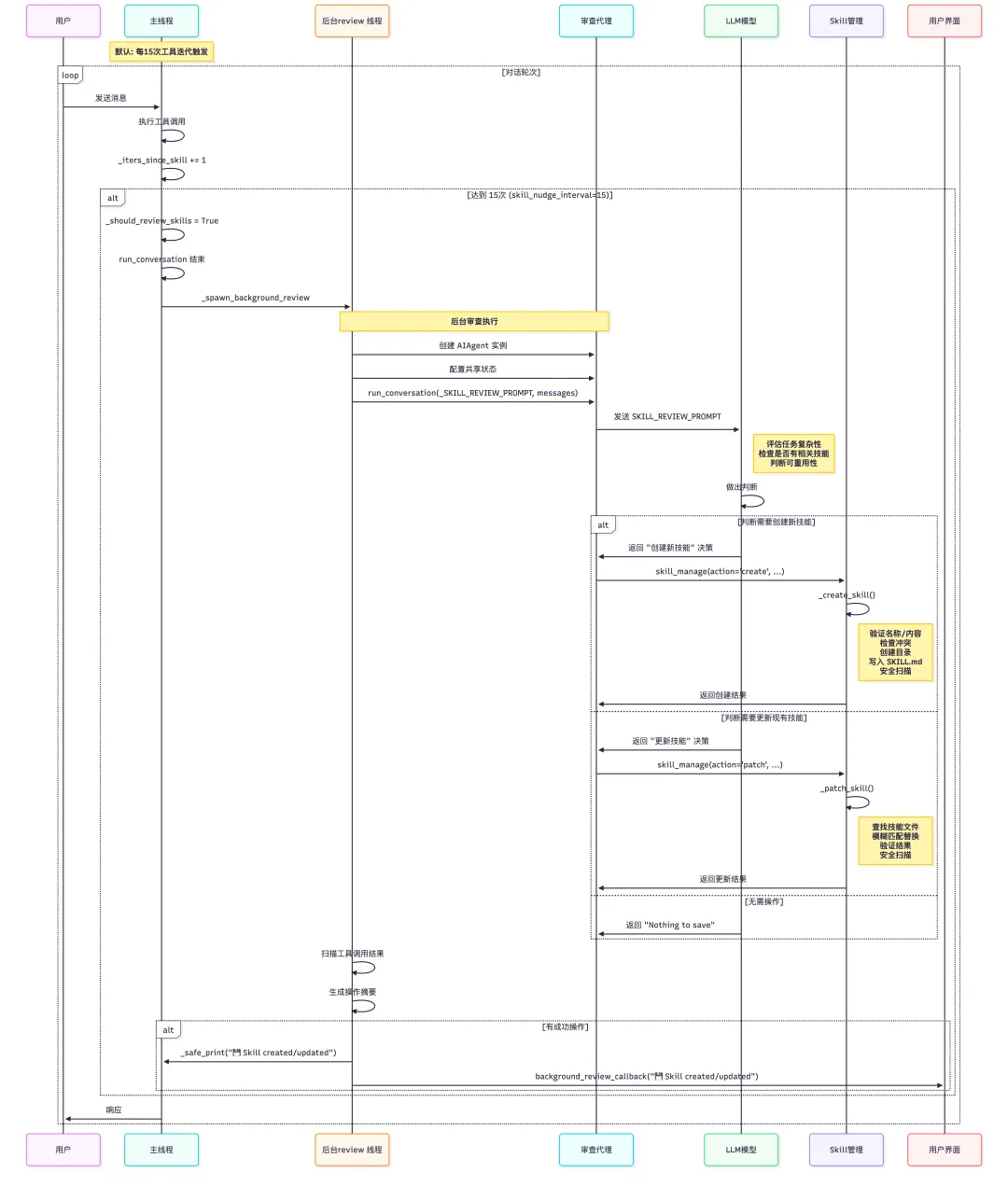
通过 SKILL_REVIEW_PROMPT 指导 LLM 作出判断后的处理流程
File: run_agent.py (L1790-1798)
_SKILL_REVIEW_PROMPT = ( "Review the conversation above and consider saving or updating a skill if appropriate.\n\n" "Focus on: was a non-trivial approach used to complete a task that required trial " "and error, or changing course due to experiential findings along the way, or did " "the user expect or desire a different method or outcome?\n\n" "If a relevant skill already exists, update it with what you learned. " "Otherwise, create a new skill if the approach is reusable.\n" "If nothing is worth saving, just say 'Nothing to save.' and stop." )-
1. 评估任务复杂性:识别需要试错、经验积累或方法调整的非平凡任务 -
2. 检查现有技能:判断是否有相关技能已存在 -
3. 决策分支: -
• 有相关技能 → 更新(patch) -
• 无相关技能且可重用 → 创建(create) -
• 无需操作 → “Nothing to save”
LLM 作出判断后根据提示调用 skill_manage
LLM 基于提示进行以下判断:
-
• 分析对话中是否使用了非平凡的方法 -
• 检查是否经历了试错过程 -
• 评估方法是否具有可重用性 -
• 查询现有技能库判断是否需要更新
skill_manage 操作分发
skill_manage 函数根据 LLM 的决策分发到相应操作
-
• action='create'→ 调用_create_skill -
• action='patch'→ 调用_patch_skill
关键要点
-
• 整个判断过程由 AI 模型基于提示自主完成,没有硬编码规则 -
• LLM 的判断直接影响后续的技能操作类型 -
• 所有操作都包含安全扫描和错误处理机制 -
• 成功操作后会清除系统提示缓存
File: tools/skill_manager_tool.py (L56-74)
def _security_scan_skill(skill_dir: Path) -> Optional[str]: """Scan a skill directory after write. Returns error string if blocked, else None.""" if not _GUARD_AVAILABLE: return None try: result = scan_skill(skill_dir, source="agent-created") allowed, reason = should_allow_install(result) if allowed is False: report = format_scan_report(result) return f"Security scan blocked this skill ({reason}):\n{report}" if allowed is None: # "ask" — allow but include the warning so the user sees the findings report = format_scan_report(result) logger.warning("Agent-created skill has security findings: %s", reason) # Don't block — return None to allow, but log the warning return None except Exception as e: logger.warning("Security scan failed for %s: %s", skill_dir, e, exc_info=True) return NoneFile: tools/skill_manager_tool.py (L574-632)
def skill_manage( action: str, name: str, content: str = None, category: str = None, file_path: str = None, file_content: str = None, old_string: str = None, new_string: str = None, replace_all: bool = False,) -> str: """ Manage user-created skills. Dispatches to the appropriate action handler. Returns JSON string with results. """ if action == "create": if not content: return json.dumps({"success": False, "error": "content is required for 'create'. Provide the full SKILL.md text (frontmatter + body)."}, ensure_ascii=False) result = _create_skill(name, content, category) elif action == "edit": if not content: return json.dumps({"success": False, "error": "content is required for 'edit'. Provide the full updated SKILL.md text."}, ensure_ascii=False) result = _edit_skill(name, content) elif action == "patch": if not old_string: return json.dumps({"success": False, "error": "old_string is required for 'patch'. Provide the text to find."}, ensure_ascii=False) if new_string is None: return json.dumps({"success": False, "error": "new_string is required for 'patch'. Use empty string to delete matched text."}, ensure_ascii=False) result = _patch_skill(name, old_string, new_string, file_path, replace_all) elif action == "delete": result = _delete_skill(name) elif action == "write_file": if not file_path: return json.dumps({"success": False, "error": "file_path is required for 'write_file'. Example: 'references/api-guide.md'"}, ensure_ascii=False) if file_content is None: return json.dumps({"success": False, "error": "file_content is required for 'write_file'."}, ensure_ascii=False) result = _write_file(name, file_path, file_content) elif action == "remove_file": if not file_path: return json.dumps({"success": False, "error": "file_path is required for 'remove_file'."}, ensure_ascii=False) result = _remove_file(name, file_path) else: result = {"success": False, "error": f"Unknown action '{action}'. Use: create, edit, patch, delete, write_file, remove_file"} if result.get("success"): try: from agent.prompt_builder import clear_skills_system_prompt_cache clear_skills_system_prompt_cache(clear_snapshot=True) except Exception: pass return json.dumps(result, ensure_ascii=False)记忆加强飞轮
Memory Nudge->Memory Review->memory_tool(add/replace/remove)
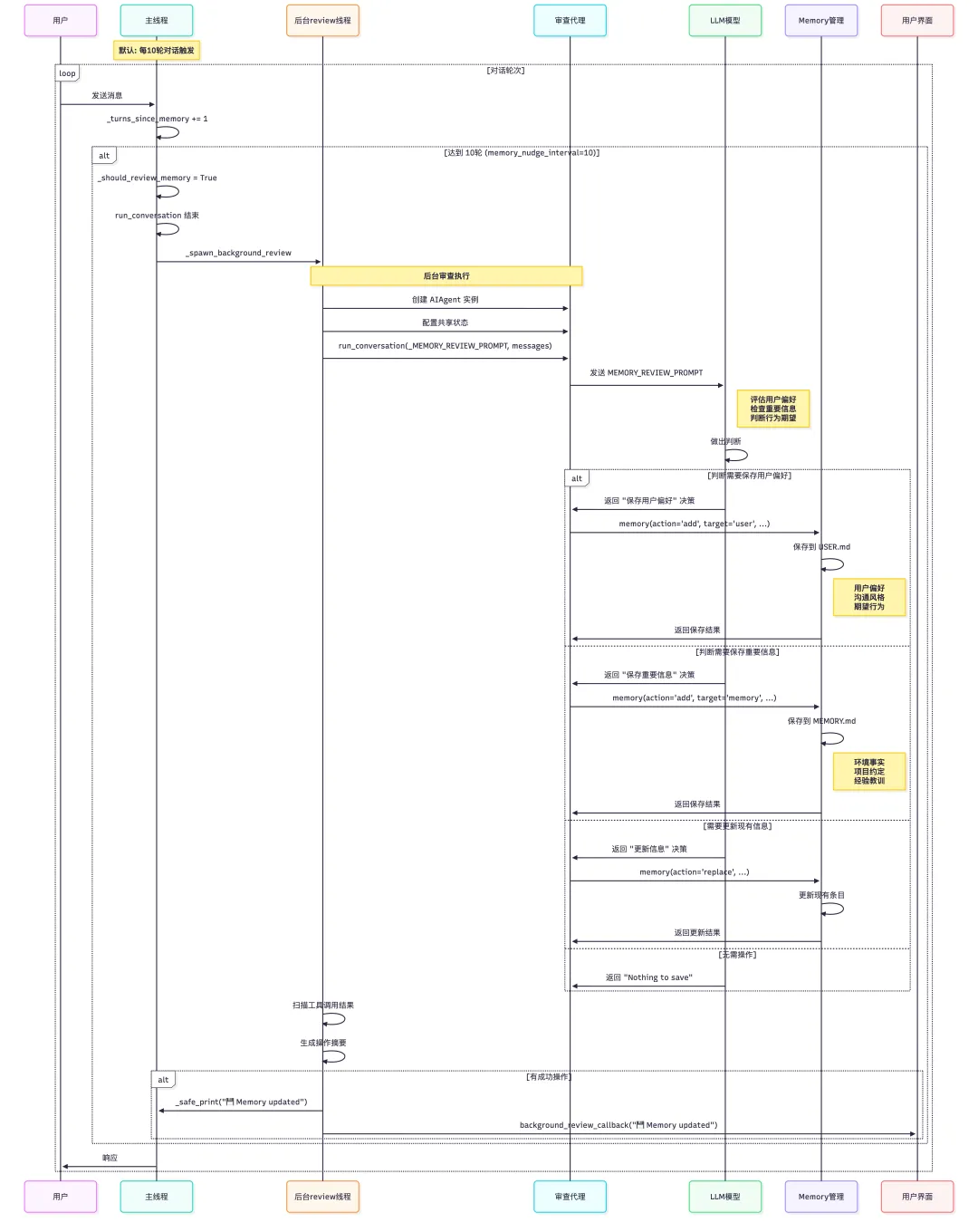
通过 MEMORY_REVIEW_PROMPT 指导 LLM 作出判断后的处理流程
_MEMORY_REVIEW_PROMPT = ( "Review the conversation above and consider saving to memory if appropriate.\n\n" "Focus on:\n" "1. Has the user revealed things about themselves — their persona, desires, " "preferences, or personal details worth remembering?\n" "2. Has the user expressed expectations about how you should behave, their work " "style, or ways they want you to operate?\n\n" "If something stands out, save it using the memory tool. " "If nothing is worth saving, just say 'Nothing to save.' and stop." )-
1. 评估用户信息:识别用户的个人特质、欲望和偏好 -
2. 检查行为期望:检测用户对代理行为和工作风格的期望 -
3. 决策分支: -
• 有用户偏好信息 → 保存到 USER.md -
• 有重要环境信息 → 保存到 MEMORY.md -
• 需要更新现有信息 → 使用 replace 操作 -
• 无需操作 → “Nothing to save”
LLM 作出判断后根据提示调用 memory_tool
LLM 基于提示进行以下判断:
-
• 分析对话中用户透露的个人信息 -
• 检查用户表达的行为期望 -
• 评估信息的重要性和持久性 -
• 决定保存目标和操作类型
memory_tool 操作分发
memory_tool 函数根据 LLM 的决策分发到相应操作
-
• action='add'→ 添加新条目 -
• action='replace'→ 更新现有条目 -
• action='remove'→ 删除条目
关键要点
-
• 整个判断过程由 AI 模型基于 _MEMORY_REVIEW_PROMPT的指导做出,没有硬编码规则 -
• LLM 的判断直接影响后续的内存操作类型和目标 -
• Memory Nudge 默认每 10 轮对话触发 -
• 内存内容在会话开始时注入系统提示,提供持久上下文 -
• 字符限制确保内存保持专注:MEMORY.md 2200字符,USER.md 1375字符
self._memory_nudge_interval = 10 self._memory_flush_min_turns = 6 self._turns_since_memory = 0 self._iters_since_skill = 0 if not skip_memory: try: mem_config = _agent_cfg.get("memory", {}) self._memory_enabled = mem_config.get("memory_enabled", False) self._user_profile_enabled = mem_config.get("user_profile_enabled", False) self._memory_nudge_interval = int(mem_config.get("nudge_interval", 10)) self._memory_flush_min_turns = int(mem_config.get("flush_min_turns", 6))def memory_tool( action: str, target: str = "memory", content: str = None, old_text: str = None, store: Optional[MemoryStore] = None,) -> str: """ Single entry point for the memory tool. Dispatches to MemoryStore methods. Returns JSON string with results. """ if store is None: return json.dumps({"success": False, "error": "Memory is not available. It may be disabled in config or this environment."}, ensure_ascii=False) if target not in ("memory", "user"): return json.dumps({"success": False, "error": f"Invalid target '{target}'. Use 'memory' or 'user'."}, ensure_ascii=False) if action == "add": if not content: return json.dumps({"success": False, "error": "Content is required for 'add' action."}, ensure_ascii=False) result = store.add(target, content) elif action == "replace": if not old_text: return json.dumps({"success": False, "error": "old_text is required for 'replace' action."}, ensure_ascii=False) if not content: return json.dumps({"success": False, "error": "content is required for 'replace' action."}, ensure_ascii=False) result = store.replace(target, old_text, content) elif action == "remove": if not old_text: return json.dumps({"success": False, "error": "old_text is required for 'remove' action."}, ensure_ascii=False) result = store.remove(target, old_text) else: return json.dumps({"success": False, "error": f"Unknown action '{action}'. Use: add, replace, remove"}, ensure_ascii=False) return json.dumps(result, ensure_ascii=False)从 Hermes 源码里,最值得借鉴的 5 个点
看完源码后,我觉得 Hermes 最值得借鉴的,是它把前面这套 A Closed Learning Loop,做成了一条真正能跑起来的 self-improving 飞轮:
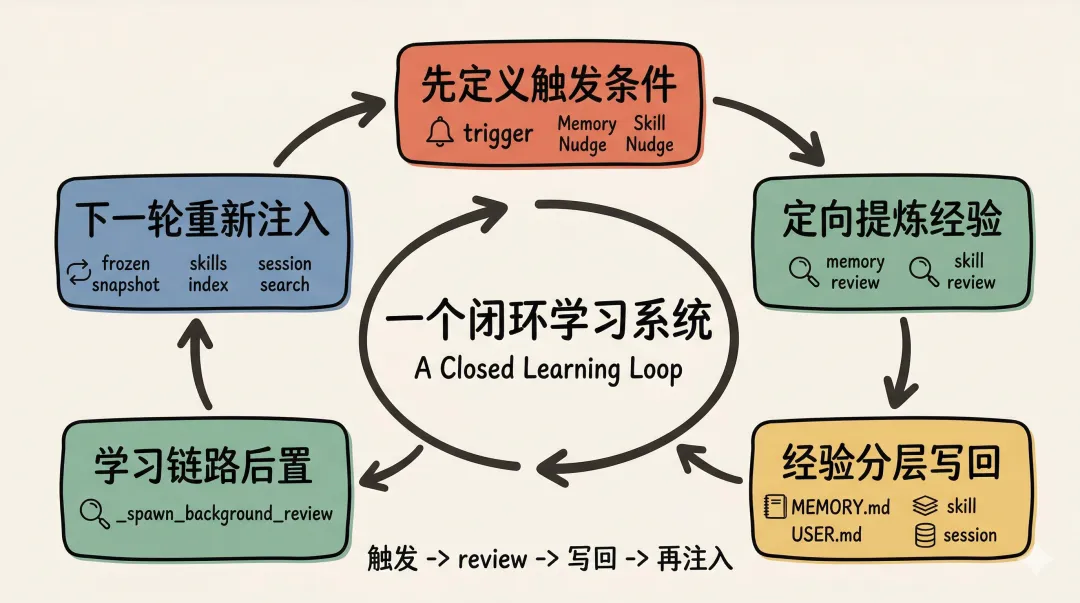
触发 review -> 提炼经验 -> 分层写回 -> 下一轮重新注入 -> 再次执行。
最值得借鉴的,是这 5 个原则:
-
1. 先定义触发条件,再谈学习能力。Hermes 不是空谈“系统会自我进化”,而是先用 Memory Nudge和Skill Nudge决定什么时候进入 review。一个按对话轮次触发,一个按工具迭代触发。没有 trigger,就没有闭环。 -
2. review 不是泛泛总结,而是定向提炼经验。 memory review看的是偏好、行为预期和长期事实;skill review看的是非平凡任务、试错过程和可复用方法。它不是“再想一遍”,而是有明确提炼目标的结构化复盘。 -
3. 提炼出来的经验,必须分层写回。用户画像、环境事实写进 MEMORY.md / USER.md;可复用的方法写进skill;大量历史过程留在session里,通过 search 找回。只有分层,系统才不会越用越脏。 -
4. 学习链路要后置,不要阻塞主任务。Hermes 通过 _spawn_background_review在后台异步跑 review agent。主任务先完成,学习后置执行,写回结果再影响下一轮。这样飞轮能转,但不会拖慢主回答。 -
5. 写回之后,还得让下一轮真的看得见。这也是为什么 Hermes 不只有写回,还做了 frozen snapshot、skills index和session search。写回的 memory 要重新进入 prompt,skill 要能按需加载,历史过程也要找得回来。没有“再注入”,就不叫 closed learning loop。
自己动手如何快速搭建 A closed learning loop
如果你想借 Hermes 的思路做自己的 Agent,可以先尝试跑通一个最小闭环:
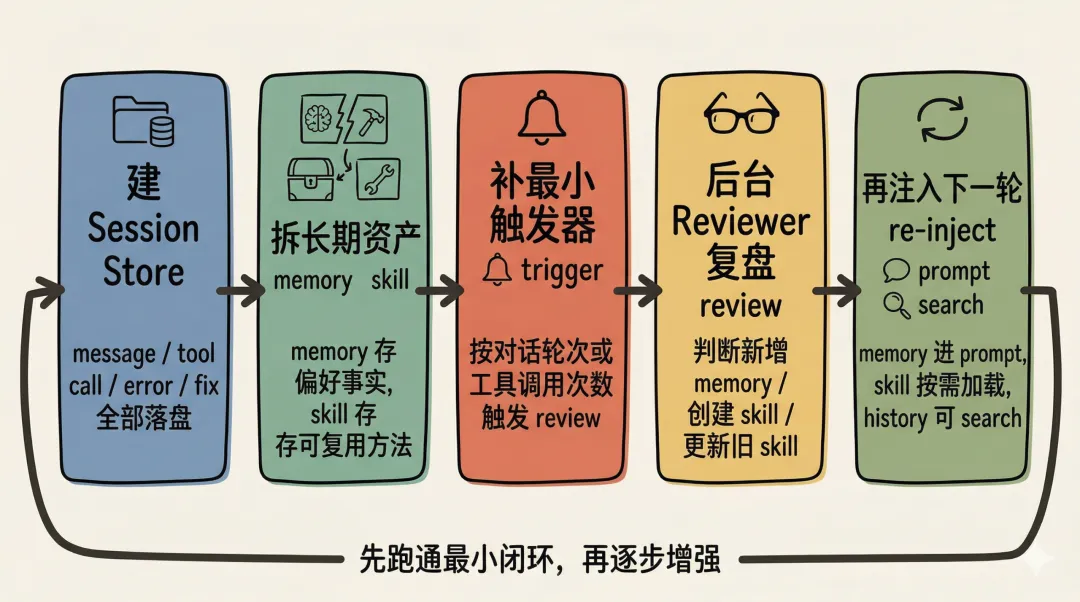
-
1. 先建 session store。把 message、tool call、错误和修正过程稳定落盘。没有这层,后面的 review 和 search 根本没有素材。 -
2. 再拆两类长期资产: memory和skill。memory存偏好和事实,skill存可复用方法。先把这两个层分开,后面系统才不会很快变脏。 -
3. 补一个最小触发器。不需要一开始就做得像 Hermes 那么完整,但至少要有一两个明确 hook,决定什么时候进入复盘。最简单的做法,就是按对话轮次或工具调用次数触发。 -
4. 用一个后台 reviewer 做结构化复盘。它不用负责主任务执行,只负责判断三件事:要不要新增 memory,要不要创建 skill,要不要更新旧 skill。这样主链路和学习链路就解耦了。 -
5. 最后补“再注入”这一步。写回的 memory 要能在下一轮 prompt 里重新出现,skill 要能通过 index 或按需加载再次参与执行,历史过程最好也能 search 回来。做到这一步,闭环才算真正闭上。
收尾一下
Hermes Agent 这套 closed learning loop,最有价值的地方,不是多了 memory review 和 skill review 两个功能,而是它真的把 “学习” 做成了一条能落地的工程链路:能触发、能复盘、能写回,也能在下一轮继续发挥作用。
真正会形成复利的,不是 Agent 在当前对话里多反思一次,而是这次执行里留下的有效经验,下一轮还能不能继续发挥作用。
AI 趣实验出品
感谢阅读,如果觉得文章还不错,顺手转给需要的朋友/点小爱心~
