2026年3月底,Anthropic 旗舰级 AI 编程智能体 Claude Code 发生了一次史无前例的源码泄露事件。此次事件不仅将一个长期被视为”黑盒”的商业 AI 产品架构彻底暴露在公众视野中,也为整个软件工程界提供了一份关于大语言模型(LLM)如何与操作系统、终端工具及本地代码库进行深度协同的完整解剖图。通过分析超过51.2 万行未混淆的 TypeScript 源代码,发现 Claude Code 并非简单的 API 命令行包装器,而是一个高度复杂的自主状态机与多智能体(Multi-agent)编排系统。在这一复杂的体系中,CLAUDE.md 文件充当了整个智能体生态系统的”持久化宪法”、上下文缓存的动态边界以及多层记忆架构的根节点。随着系统底层运行逻辑的揭秘,传统的”提示词工程(Prompt Engineering)”正在向”上下文工程(Context Engineering)”演进。本文将基于泄露源码,系统性拆解 Claude Code 的底层机制,详述其系统提示词的注入流与记忆拓扑结构,并提供一套深度优化的 CLAUDE.md 编写范式与团队工程最佳实践。
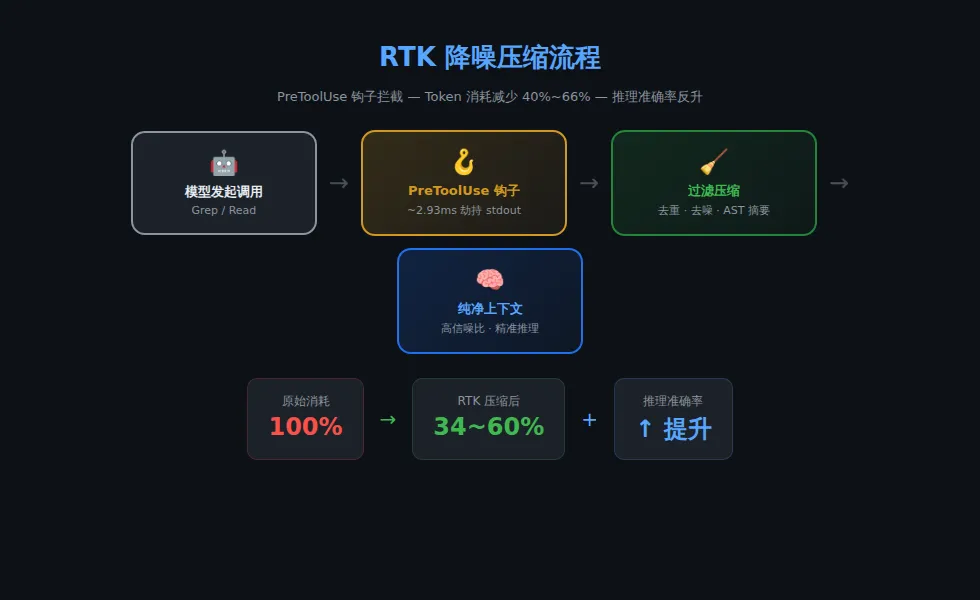
在组装完所有层级的指令后,系统会插入硬编码的缓存边界标记 __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__,专门用于优化 Anthropic API 的 Prompt Caching 机制,实现毫秒级延迟与显著成本折扣。
2.3 内部版与外部版提示词的双重标准
分析揭露了一个关键细节:Anthropic 对外分发的提示词有意压制了深度推理链路。外部版:”If you can say it in one sentence, don’t use three.” — 追求简洁内部版:”Err on the side of more explanation.” — 强调深度推理与自主验证开发者可通过在 CLAUDE.md 中显式配置来补偿这一差异。
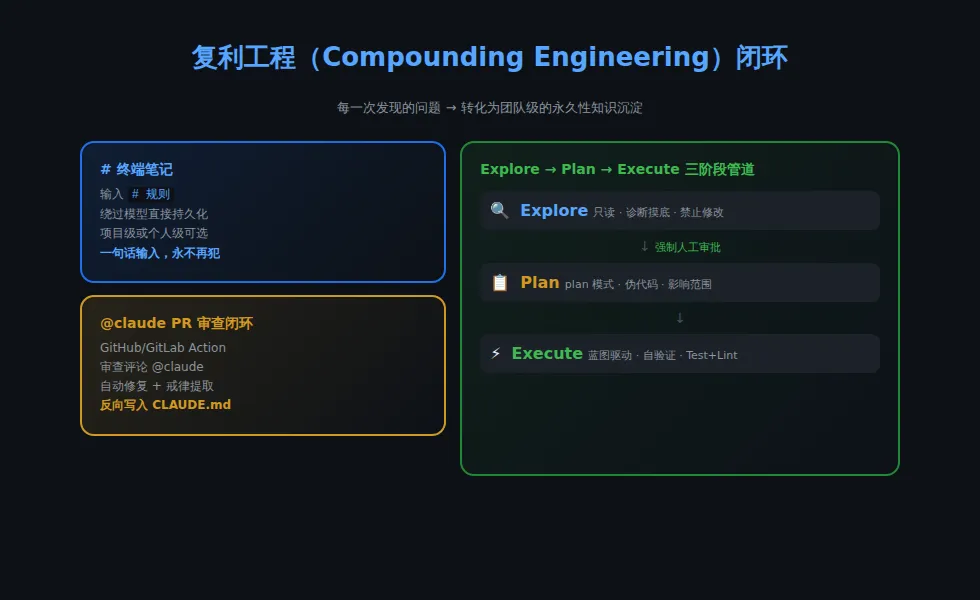
此次源码泄露从本质上破除了 AI 编程产品的”黑盒滤镜”。当前 AI 协同编程已全面迈入“上下文管线重塑工程”的深水区。在这一体系中,CLAUDE.md 不再是被动读取的用户手册,而是调控整个 AI 算力与智能体状态机的控制引擎。AI 编程的未来,不取决于模型本身有多强大,而取决于你如何构建它赖以工作的上下文世界。
 夜雨聆风
夜雨聆风