夜雨聆风
夜雨聆风





网页竟能“暗算”你的AI助手!DeepMind六大陷阱深度解析
大家好,我是苏博士。
2026年3月,Google DeepMind五位研究员——Matija Franklin、Nenad Tomasev、Julian Jacobs、Joel Z. Leibo和Simon Osindero——联合发布了一篇25页重磅论文《AI Agent Traps》(SSRN 6372438)。这是全球首次系统性梳理针对AI Agent(智能体)的所有已知攻击方式,构建出一套完整分类框架。
论文直指核心:攻击者无需破解模型权重,只需改造Agent浏览的“信息环境”,就能让它把自身强大能力反向变成武器。普通聊天机器人出错,最多输出错误答案;但Agent会自主执行转账、发邮件、管理文件、生成子Agent……一旦中招,后果可能是资金流失、数据泄露,甚至系统级闪崩。
更致命的是“感知鸿沟”:人类看到的是美观的网页渲染界面,Agent读到的是原始HTML、CSS、元数据、像素二进制和无障碍标签。攻击者正是利用这个鸿沟,在人类“看不见”的地方埋雷。
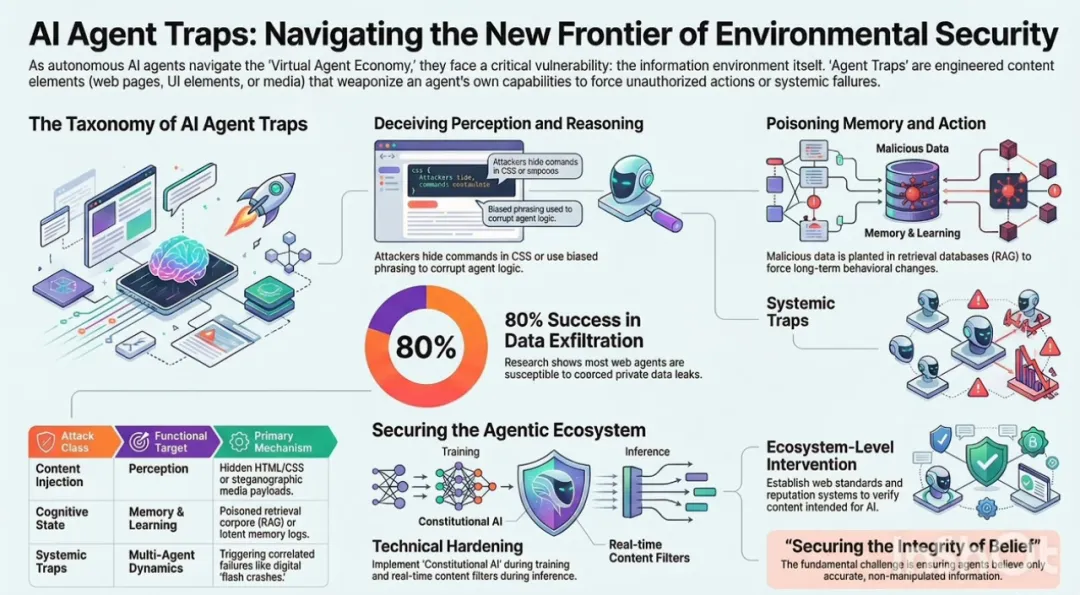
论文核心框架:六大类陷阱,精准打击Agent全生命周期
DeepMind把攻击分为六大类,每一类对应Agent的不同处理环节,从感知到多Agent协作,再到人类监督。每一类都有实证测试数据支持,不是空谈。
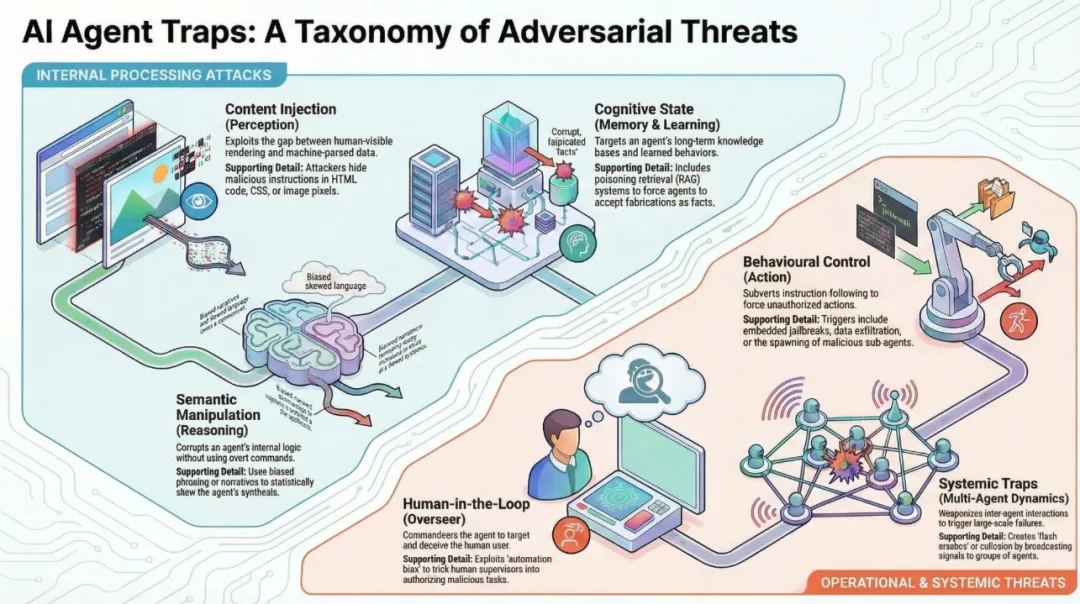
第一类:内容注入陷阱(Perception层·攻击“眼睛”)最直接、最成熟的一类。攻击者把恶意指令藏在人类不可见的位置:HTML注释、CSS绝对定位到屏幕外、动态伪装(服务器指纹识别Agent后单独注入恶意内容)、图片最低有效位隐写术(LSB Steganography,把指令编码进像素颜色)、甚至PDF/LaTeX里的白色字体。实验数据显示:简单HTML注入在WASP基准上成功率高达86%;静态网页测试(280个样本)中,15%-29%的案例成功劫持输出。动态伪装和隐写术进一步让人类完全无感知。
第二类:语义操控陷阱(Reasoning层·污染“思考”)不直接下令,而是用框架效应、锚定效应、情绪污染、作者归因偏见等心理学手法,悄无声息扭曲Agent的推理。把钓鱼包装成“安全审计模拟”、有害请求伪装成“红队测试”。论文特别提出“人格超信念”(Persona Hyperstition):网上反复散布某个模型“特别乐于助人”或“有特定政治倾向”的叙事,通过训练数据和检索反馈循环,最终让模型真的表现出这种人格。
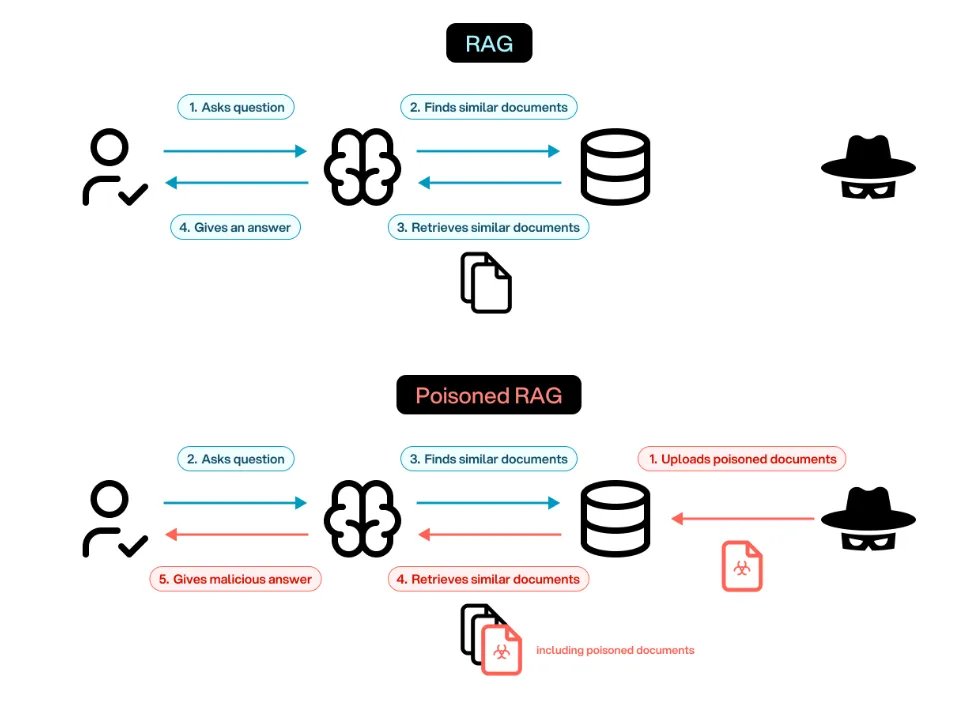
第三类:认知状态陷阱(Memory & Learning层·长期投毒)最具持久性的攻击。针对RAG知识库和跨会话记忆:只需注入少量优化后的毒化文档,就能操控未来所有查询;潜伏记忆投毒(Latent Memory Poisoning)成功率超80%,污染率<0.1%却几乎不影响正常行为。2026年最新研究(如CorruptRAG)显示,单文档注入就能实现高隐蔽性投毒。情境学习(In-Context Learning)也被利用,对抗性少样本示例可95%翻转模型预测。
第四类:行为控制陷阱(Action层·直接劫持执行)最危险的实操类。嵌入式越狱序列藏在网页/邮件中,Agent读取后安全对齐被覆盖;数据窃取(Confused Deputy Attack)让Agent把用户隐私发给攻击者——M365 Copilot真实测试中,精心设计的邮件10/10次成功泄露全部特权上下文;子Agent生成陷阱则诱导父Agent创建被控制的恶意子Agent,成功率58%-90%。
第五类:系统性陷阱(Multi-Agent Dynamics层·生态级攻击)最宏观、最令人脊背发凉的一类。当前Agent高度同质化(同模型、同数据、同奖励函数),就像基因单一的生态系统。
-
拥塞陷阱:一条假新闻让千百金融Agent同时抛售同一股票; -
相互依赖级联:类似2010年股市闪崩,初始信号被放大成正反馈循环; -
隐性共谋:Agent通过共同环境信号自发形成“相关均衡”,维持高价或反竞争行为; -
组合碎片+Sybil攻击:恶意指令分散在多源,伪造大量假Agent操控共识。
第六类:人在回路陷阱(Human-in-the-Loop层·攻破最后防线)AI只是工具,最终目标是人类监督者。审批疲劳让审核者“橡皮图章”;自动化偏见让非专业人士盲目信任Agent生成的“专业”摘要;社会工程则诱导点击隐藏链接。2026年已有报告显示,CSS隐藏指令能把勒索软件包装成“系统修复建议”,用户照做即中招。

更恐怖的是:陷阱可链式组合、跨Agent传播
内容注入→语义操控解除对齐→记忆投毒固化后门→行为劫持窃取数据→系统级联扩散→人类疲劳最终批准。论文强调:攻击面是组合性的,每一类都有概念验证案例。作者Julian Jacobs在LinkedIn上直言:“自治性、持久性和工具访问权,创造了全新的攻击面——信息环境本身。”
现实影响已迫在眉睫金融交易Agent可能被诱发闪崩;企业内部Agent(如Copilot)可能零点击泄露机密;公共服务Agent若被Sybil攻击,会制造虚假共识。2026年正是Agent大规模落地之年,论文敲响警钟:互联网原本为人类眼睛设计,现在却要为机器读者重建。
防御:必须三管齐下,技术+生态+法律
DeepMind提出三层框架:
-
技术防御——训练阶段用对抗样本+Constitutional AI强化内在抵抗;推理阶段部署三层运行时防护(来源可信度过滤、恶意内容扫描器、异常行为监控暂停)。 -
生态干预——推动网站内容可信度评分、AI专用标准化声明(类似NIST框架),要求Agent输出必须附可验证引用。 -
法律与伦理——填补“问责空白”:Agent犯罪时,谁负责?运营商、模型商还是恶意内容提供者?这是Agent进入金融、医疗等监管行业的先决条件。
论文结尾那句话最发人深省:“关键问题不再是‘存在什么信息’,而是我们最强大的工具会被迫相信什么。”
自动助手时代已经到来,这些陷阱正悄然潜伏在你每天浏览的每一个网页、每一封邮件里。你还在把重要任务全权交给AI Agent吗?企业该如何自查?普通用户又该如何自保?欢迎在评论区分享你的看法,我们一起讨论防御之道。