 夜雨聆风
夜雨聆风





AI画图进化了:它学会"想清楚再画",中文再也不乱码
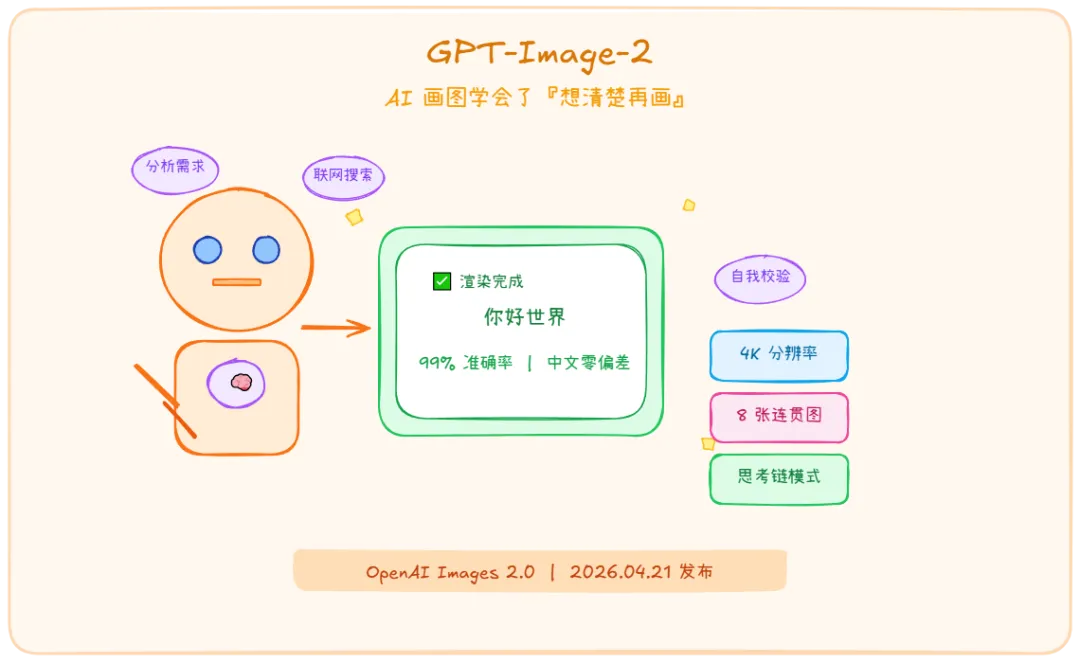
核心摘要:OpenAI 昨天发布 ChatGPT Images 2.0(GPT-Image-2),AI 生图首次引入「思考模式」——联网推理、自我校验、多图连贯。中文渲染准确率 99%,Arena 榜单领先对手 242 分,支持最高 4K 分辨率。
你让它写个 “Hello”,它能给你画成 “Hleo”;让它写句中文”新年快乐”,出来的东西像经过了十次谷歌翻译再加 OCR 识别错误——根本没法看。做公众号配图的应该都有过这种崩溃时刻:明明描述得很清楚了,AI 就是理解不了你要把字放在哪、写成什么样。
📢 发布信息:2026年4月21日,OpenAI 正式推出 ChatGPT Images 2.0(底层模型代号 GPT-Image-2),面向全体 ChatGPT 与 Codex 订阅用户开放。
AI 画图这件事,真的变了。✨
🔥 先说最炸的三个数字
在聊细节之前,先扔几个数据让你感受一下这个模型的”暴力程度”:

① 文字渲染准确率 99%
你没看错,是 99%。前代 DALL-E 3 大概在 90%-95% 之间,听起来也不差?但那丢失的 5-10 个百分点,恰好就是“能用”和“不能用”的区别——logo 字母写错、海报电话少一位、按钮文案多出空格,商业场景里都是灾难。GPT-Image-2 把这个坑基本填平了。
② Image Arena 三冠王 —— 1512 分,领先第二名 242 分 🏆
这是 Image Arena 开榜以来最大分差!相当于第一名跑完马拉松回家洗完澡了,第二名还在半路喘气。7 个子类目全部第一,其中文本渲染跃升 316 分——所有维度中进步最猛的。
③ 最高 4096×4096 + 一次生成 8 张连贯图
4K 输出可以直接印杂志封面。而 8 张连贯图能力——角色外观、画风、物件跨图保持一致——对做漫画、分镜板、品牌系列物料的人来说简直是救命稻草。
🧠 最大升级:AI 画图学会了”思考”
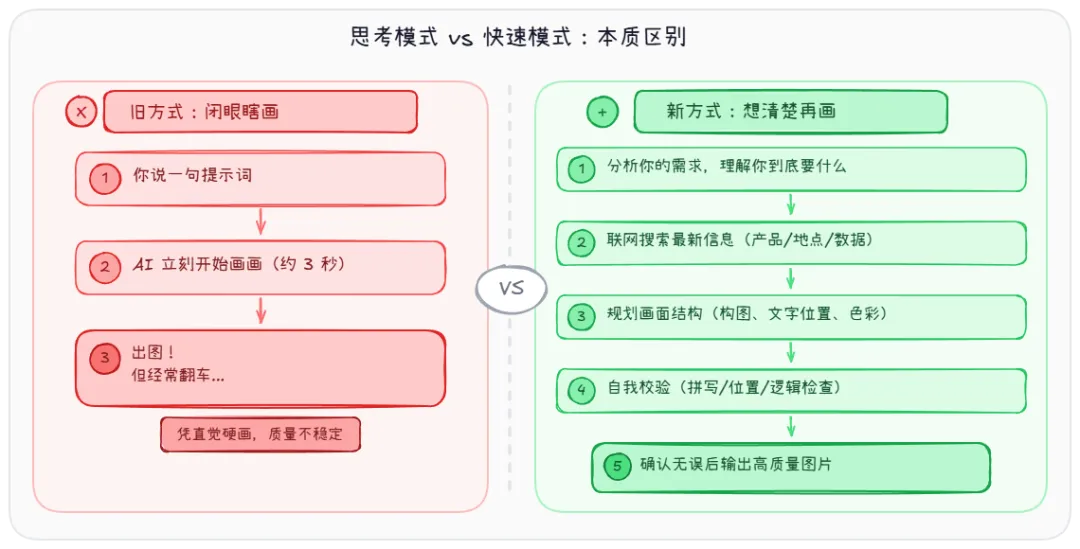
Images 2.0 最核心的变化不是画质、不是分辨率——而是它第一次给图像生成加上了推理能力。
|
❌ 以前:闭眼瞎画 你说一句 → 它立刻开画 → 出图全程约 3 秒,快但经常翻车 |
✅ 现在:想清楚再画 分析需求 → 联网查资料→ 规划画面结构 → 自我校验→ 确认无误后再动笔 |
举个实际例子:你让它画一张”2026 款特斯拉 Cybertruck 的广告海报“。旧模型可能画一辆长得像皮卡的铁盒子就交差了——训练数据截止很久以前,根本不知道新款长啥样。但 GPT-Image-2 会先联网搜索最新款的图片和参数,确认特征之后再动笔,结果靠谱得多。
🚗 实测案例:小米 SU7 Ultra 渲染
要求:”画一张小米 SU7 Ultra 侧面渲染图,车身上要印’极速 380km/h'”。开启思考模式后:
- 联网查询这款车的外观细节
- 规划文字位置避免遮挡车身线条
- 自我校验“380km/h”有没有写错?位置是否合理?
- 确认无误后输出最终结果

✍️ 中文终于不再乱码了!
作为一个天天跟中文内容打交道的人,这一点我最想好好聊聊。AI 生图的“中文文盲”问题存在了好几年——DALL-E 2 时期基本放弃治疗,DALL-E 3 好了一些但对复杂排版仍然力不从心。
GPT-Image-2 实测三大惊喜 👇
- 高密度中文排版不再是梦。有人用它做了整张攻略长图,里面密密麻麻全是中文段落、标注、数据表格,居然基本没有出错。以前你甚至不敢让 AI 画超过 20 个汉字的图。
- 多语言混排也能驾驭。中英日韩混合排版、简繁体中文共存,都能处理得当。语言不再是”贴上去的设计元素”,而是自然融入整体视觉的一部分。
- UI 模拟逼真到可怕。微信聊天截图、抖音直播界面、App 设置页面……生成的 UI mockup 已经达到”不仔细看会信以为真”的程度。
📊 有人做了 50+ 实测案例,覆盖攻略长图、杂志封面、社交截图、软件界面等 10 大方向,结论一致:中文渲染不再是短板,而是招牌优势。
⚡ 两个模式怎么选?省钱攻略来了
Images 2.0 提供两种模式,各有适用场景,选对了能省不少钱:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
💡 一句话建议:日常随便画画用 Instant,正经干活用 Thinking。
省钱彩蛋:同样高质量输出,非方图(竖图 1024×1536)比方图便宜 17.5%。OpenAI 在引导大家把 Images 2.0 用于海报/杂志成品场景,传统方图留给旧模型就行。
📝 提示词怎么写才好用?三个黄金法则
测了一整天,总结了几条实操经验,直接给你抄作业:
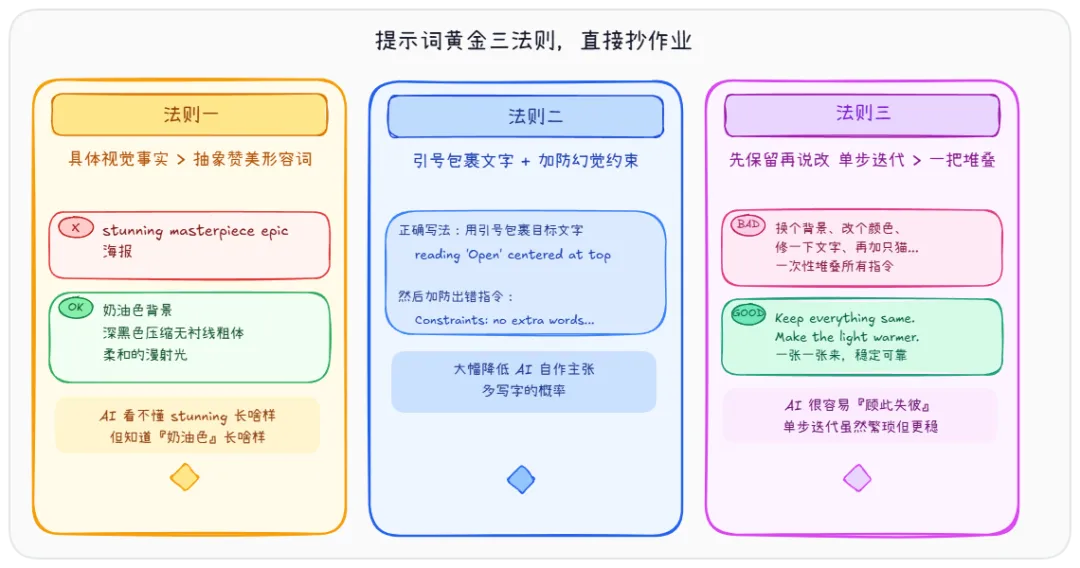
法则一:具体视觉事实 > 抽象赞美形容词
❌ “一张 stunning 的 masterpiece 级 epic 海报” → ✅ “奶油色背景,深黑色压缩无衬线粗体,非对称版式块,柔和漫射光” AI 看不懂 “stunning” 长什么样,但它知道”奶油色背景”长什么样。描述越具体,画得越准。
法则二:文字渲染要用引号包裹 + 加防幻觉约束
如果你想画图中包含特定文字,一定要这样写:
“A glowing red neon sign reading ‘Open’, centered at the top of the window”
然后加上防出错指令:
Constraints: no extra words, no duplicate text, no additional labels
法则三:改图时”先保留再说改”
❌ 一次性堆叠:”换个背景、改个颜色、修一下文字、再加只猫……” → ✅ 单步来:”Keep everything else same. Make light warmer.” 单步迭代虽然繁琐一点,但稳定得多。一次性塞太多指令,AI 很容易”顾此失彼”。
⚠️ 说点严肃的:截图再也当不了证据了
技术进步总伴随着新的风险,GPT-Image-2 也不例外。
当 AI 能以 99% 的准确率渲染中文 UI 截图、模拟任意 App 界面时,我们面临着一个很现实的问题:你怎么证明一张图是真的?
⚠️ 安全警示
已有安全研究者用 GPT-Image-2 生成了足以以假乱真的微信聊天记录、银行转账截图、法院传票界面。技术本身是中性的,但在坏人手里,这就是完美的诈骗工具。
看到”截图证据”的时候多留个心眼,尤其是那些让你转账、泄露个人信息的。
💭 最后说几句
从 DALL-E 2 到现在,AI 生图走了不到四年时间。
- 四年前:扭曲的鬼脸和融化的蜡烛
- 三年前:Midjourney 让我们惊叹于艺术风格的多样性
- 两年前:DALL-E 3 解决了基本的文字渲染问题
- 而现在:GPT-Image-2 让 AI 画图学会了”思考”
每一次迭代都在解决上一代的核心痛点。今天的 Images 2.0 也许还不够完美——插画偶尔有过度细节化的”碎碎感”、真人效果仍吃提示词质量、Thinking 偶尔让人着急——但大方向很明确:
AI 正从一个”会画画的工具”变成一个”懂设计的助手”。🚀
至于这对设计师是好是坏……我觉得与其担心被替代,不如早点学会骑在这个浪潮上面。毕竟,工具越强大,会用工具的人就越值钱。