 夜雨聆风
夜雨聆风





右手投毒AI幻觉,99%的人无法察觉
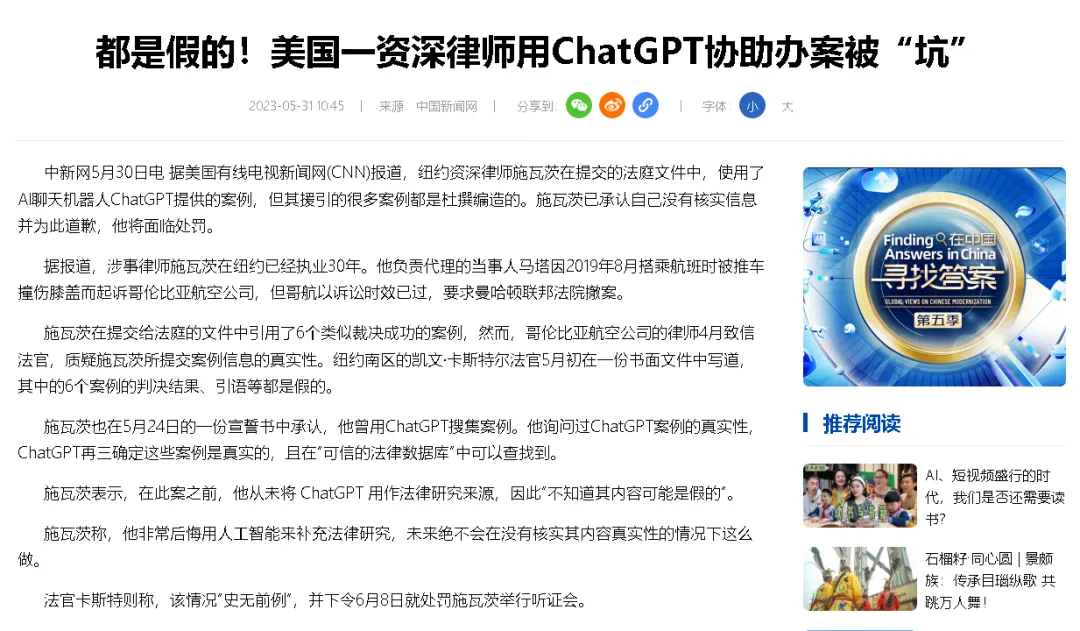
2023年,纽约一个执业多年的律师Steven Schwartz,在代理一起针对哥伦比亚航空公司Avianca的航空伤害索赔案时,用ChatGPT查找了一批判例依据,然后把这些判例提交给了法庭。
这6个判例,一个都不存在。
ChatGPT把它们全部编造出来了。有案件名称,有案卷号,有法官意见,甚至模仿了美国联邦最高法院的判例风格,读起来有板有眼,跟真的一模一样。Schwartz起初不相信AI会无中生有,还在法庭上继续为这些假判例辩护。
法官Castel在裁定书里指出,这些所谓的判例表面特征与真实判决相似,但其他部分包含胡言乱语和无意义内容。法院对两名律师及其律所处以5000美元连带罚款,律师事务所随后发表声明,说自己“犯了一个善意的错误——我们没想到一项技术会无中生有地编造案例”。
这就奇怪了,一个受过精英法律教育的律师,用AI查案例,AI给他捏造了6个根本不存在的判决,他不仅没发现,还替这些假判例在法庭上辩护。这已经不是普通的技术失误了,这是一场有人主动递刀、有人主动往脖子上架的灾难。
而这只是一个开始。
到了2025年9月,加州律师Amir Mostafavi在上诉文书里引用了ChatGPT生成的21个虚假判例,被处以10000美元罚款,创下了美国律师因为AI幻觉被处罚的历史最高纪录。与此同时,另有一家大型律所因为AI生成的虚假案例引用向联邦法官公开道歉,另有联邦法官对2名律师合计处以110000美元罚款。
从2023年到2025年,短短两年,这类事故不是在减少,而是在持续增加。
这还只是法律领域,被抓出来的部分。
谷歌在2024年正式上线了AI Overview功能,有用户问“芝士无法粘在披萨上怎么办”,AI回答说可以在酱汁里加入八分之一杯无毒胶水,理由是胶水的黏性有助于固定芝士。这个答案的来源,是Reddit上的一条玩笑帖子。同期这个AI还建议用户每天吃一块石头,来源是一家讽刺媒体The Onion上的文章。谷歌不得不紧急手动关闭了相关功能。
那么问题来了,AI为什么会这样?为什么它会一本正经地编造根本不存在的东西?
很多人以为AI是在“查资料”,输入一个问题,AI去数据库里找答案,找到了就输出,没找到就说不知道。但实际上根本不是这么回事。
大语言模型的工作原理,本质上是一个概率预测器,不是事实检索器。
它通过在数万亿个词元的语料库上训练,学习的是词语和词语之间的统计关系。每次生成内容,它做的事情是在预测“下一个词最可能是什么”。它不在乎这个词是不是真实的,它只在乎这个词在统计上是不是“合适的”。训练的目标,是生成流畅的内容,而不是准确的内容。
它没有事实,只有概率。它不知道真假,它只知道流畅。
所以当你问它一个法律判例,它给你的不是从数据库里查出来的真实文件,而是根据它对“法律判例应该长什么样子”的统计理解,给你生成了一个看起来最像法律判例的内容。它不知道这个判例是不是真实存在的,它也没有任何机制去验证。它只是生成了一个“读起来像判例”的东西。
而且这个东西的生成是高度自信的,语气上没有任何迟疑,格式上完全符合规范,读起来就是真实文件的样子。

这就是所谓的“AI幻觉”。不是AI偶尔出错,不是训练数据不够,而是这个架构本身决定了它必然会产生这种现象。
这话是谁说的?是OpenAI自己说的。
OpenAI在2025年9月发表了一篇36页的论文,自己承认了这一点——语言模型的幻觉并非技术上的偶发异常,而是当前模型训练与评估范式下统计学上的必然产物。幻觉不是bug,是这个东西的结构性特征。
知道这个之后,再看一些数据就不会觉得奇怪了。
清华大学人工智能学院做过测试,DeepSeek V3的事实性幻觉率是29.67%。也就是说,你用目前主流的AI,它给你的答案里,大约每3到4个就有1个是在跟你撒谎。而且它撒谎的时候,语气和说真话的时候一模一样。错的和对的,你用肉眼完全分不出来。
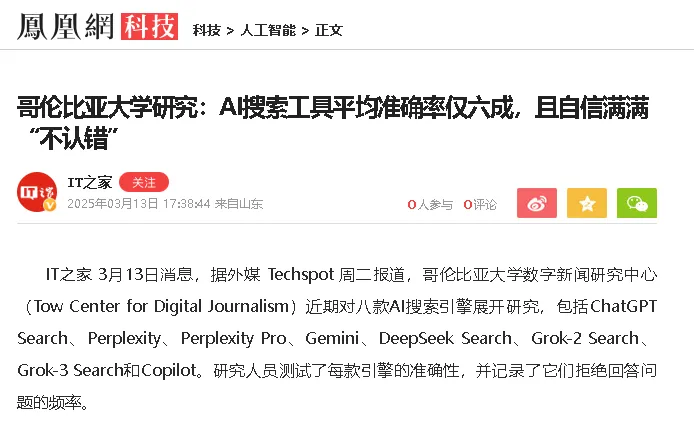
哥伦比亚大学数字新闻研究中心在2025年3月做了一项测试,专门测试主流AI搜索工具在新闻引用方面的准确性,结果是平均错误率60%。
60%啊。每10条AI给你找的新闻引用,有6条是有问题的。但这个AI在给你呈现这些引用的时候,一样是有板有眼,有来源有链接,看起来一样靠谱。
更麻烦的是,AI幻觉还会传染。错误的信息被其他AI系统吸收,进入下一轮训练数据,被强化,再输出,再被吸收,形成一个幻觉循环。研究显示,训练数据里只需要0.001%的虚假文本,就可以导致这个模型有害输出上升7.2%。这不是线性的污染,这是滚雪球式的扩散。
所以现在的情况是,一大堆AI正在互相用对方的输出作为训练数据,而这些输出里已经有不知道多少幻觉混在里面,被一遍一遍地强化和复制,整个信息生态正在被污染,而且这个过程是悄无声息的,没有任何提示。

有人觉得这些问题是AI还不够成熟,等技术进步了就会解决。但上面说了,OpenAI自己已经在论文里说了,这是统计学上的必然产物。思谋科技联合创始人刘枢的判断是,当前大模型的架构是黑箱系统,幻觉的问题优化只能缓解,无法根除。
无法根除的意思是,哪怕是未来最先进的AI,只要还是基于这个架构,它就会出现幻觉,区别只是幻觉率高一点还是低一点。
那么谁来负责?
2026年1月,杭州互联网法院宣判了中国第一例AI幻觉侵权案。一个叫梁某的人,给高考的弟弟用AI查询高校信息,AI给出了错误信息,甚至“承诺”如果内容有误将赔偿10万元。梁某告上法庭,要求赔偿。
法院一审驳回了诉讼请求。
主审法官给出的理由是:AI幻觉在当前技术下具有不可避免性,服务提供者只要尽到了注意义务,通常不构成过错。
“不可避免性”。法院用的词是“不可避免性”。

你自己去看说明书,说明书上写了“AI可能会出错”——这就是目前法律给出的答案。
世界经济论坛在《2025年全球风险报告》里,把错误和虚假信息列为未来两年全球第一大风险,AI幻觉是这个风险的关键诱因。AI事故数据库中,多起重大事故的起因被认定为生成式AI的幻觉。这个数字还会继续涨,因为AI正在进入越来越多的高风险领域,医疗、金融、法律、自动驾驶,任何一个领域里1%的错误率都可能是100%的灾难。
但法律现在的答案是:这是不可避免的,没人负责。
AI公司告诉你这是“不可避免”的,法院告诉你“服务提供者没有过错”,说明书上写了“AI可能出错”,所以你自己负责。
这就是右手投毒——毒递到你手里,毒进了你肚子,但投毒的人站在法律的保护伞下,无懈可击。

所以最后这道防线只能靠你自己。你得知道这个东西在事实性问题的专项测试里,大约每问100个问题就有将近30个答案是有问题的,你得知道它给出错误答案时的语气和说真话时一模一样,你得知道它给你的每一个数据、每一个引用、每一个判例,在你自己核实之前,都只是一个待验证的线索,不是事实。
有些人觉得AI说的就是真的,用它查医疗信息、查法律条文、查新闻事实,查完就信,信了就用,用了就算。如果你真的这么干,那不是在用工具,那是在接毒。
这话不是我们说的,是OpenAI自己在论文里承认的——幻觉是统计学上的必然产物。