 夜雨聆风
夜雨聆风





输入一句话,AI 帮你拍完整条短视频:Pixelle-Video 源码深度拆解
你有没有过这样的体验——
脑子里有一个选题,比如”为什么要养成阅读习惯”。你知道该说什么,也大概知道画面该是什么样。但真正坐下来做的时候,你要写文案、找配图、录音、剪辑、配乐、调字幕……一条 60 秒的短视频,折腾下来两三个小时过去了。
这个时间成本,对于每天要更新内容的创作者来说,是一种隐形的消耗。
Pixelle-Video 想解决的就是这件事。你给它一句话,它帮你把剩下的全做了——写稿、配图、配音、排版、合成、加背景音乐。不是”半自动”,是从头到尾全自动。
项目地址:github.com/AIDC-AI/Pixelle-Video,Apache 2.0 开源协议,目前 5000+ Star。
今天我们深入源码,看看这条”全自动短视频流水线”到底是怎么跑起来的。
一、架构全貌:一条八步流水线
打开 pixelle_video/ 目录,项目结构非常清晰:
pixelle_video/
├── service.py # 核心入口,全局单例
├── pipelines/ # 视频生成管线
│ ├── base.py # 管线抽象基类
│ ├── linear.py # 线性管线模板方法
│ ├── standard.py # 标准管线(主力)
│ ├── custom.py # 自定义管线模板
│ └── asset_based.py # 素材驱动管线
├── services/ # 能力服务层
│ ├── llm_service.py # 大模型调用
│ ├── tts_service.py # 语音合成
│ ├── media.py # 图片/视频生成
│ ├── frame_processor.py # 帧处理器
│ ├── frame_html.py # HTML模板渲染
│ └── video.py # ffmpeg视频处理
├── prompts/ # Prompt模板库
└── utils/ # 工具函数核心思路是一条 八步流水线,定义在 LinearVideoPipeline 这个基类里(linear.py):
Setup → Generate Content → Determine Title → Plan Visuals
→ Initialize Storyboard → Produce Assets → Post Production → Finalize翻译成人话就是:建工作目录 → 写文案 → 起标题 → 规划配图 → 创建分镜 → 生成音画素材 → 拼接合成 → 输出结果。
每一步都是一个可以被子类覆盖的方法。想改流程?继承 LinearVideoPipeline,覆盖你要改的步骤就行。这就是经典的模板方法模式——骨架定好了,细节随你填。
二、核心入口:PixelleVideoCore 怎么把所有能力串起来
service.py 里定义了一个全局单例 pixelle_video = PixelleVideoCore()。
这个类的设计非常值得学习——它把所有能力模块化为独立的 Service,然后通过组合的方式暴露出去:
class PixelleVideoCore:
def __init__(self):
self.llm = None # 大模型服务
self.tts = None # 语音合成服务
self.media = None # 图片/视频生成服务
self.video = None # ffmpeg视频处理
self.frame_processor = None # 帧处理器
self.pipelines = {} # 已注册的管线初始化的时候,它把 LLM、TTS、Media 等服务都创建好,然后注册三条管线:
self.pipelines = {
"standard": StandardPipeline(self),
"custom": CustomPipeline(self),
"asset_based": AssetBasedPipeline(self),
}调用方式很简洁:
result = await pixelle_video.generate_video(
text="如何提高学习效率",
pipeline="standard",
n_scenes=5
)ComfyKit 的懒加载设计 是另一个亮点。ComfyUI 连接不在初始化时创建,而是第一次用到的时候才创建,并且会检测配置变化——如果用户中途改了 ComfyUI 地址,下次调用会自动重建连接。这种”延迟初始化 + 配置热重载”的组合,在生产环境里非常实用。
三、LLM 服务:一套代码兼容所有模型
LLMService 的实现很克制——直接用 OpenAI SDK,没有套额外的框架。
class LLMService:
async def __call__(self, prompt, model=None,
temperature=0.7, response_type=None):
client = AsyncOpenAI(api_key=..., base_url=...)
response = await client.chat.completions.create(...)
return response.choices[0].message.content因为用的是 OpenAI 兼容接口,所以通义千问、DeepSeek、Moonshot、甚至本地跑的 Ollama,全都能直接接入,只需要改 base_url 和 model。
结构化输出 是一个实用的增强。当你传入 response_type=SomePydanticModel 时,它会自动在 Prompt 末尾附加 JSON Schema 指令,然后从 LLM 返回的文本里解析出结构化数据。解析策略也很健壮——先试直接 JSON,不行就找 Markdown 代码块,再不行就找大括号之间的内容。三重保底。
这比依赖 OpenAI 的 response_format 参数要通用得多,因为不是所有兼容接口都支持那个特性。
四、帧处理器:四步流水线中的流水线
如果说八步流水线是整体骨架,那 FrameProcessor 就是最核心的那颗心脏。
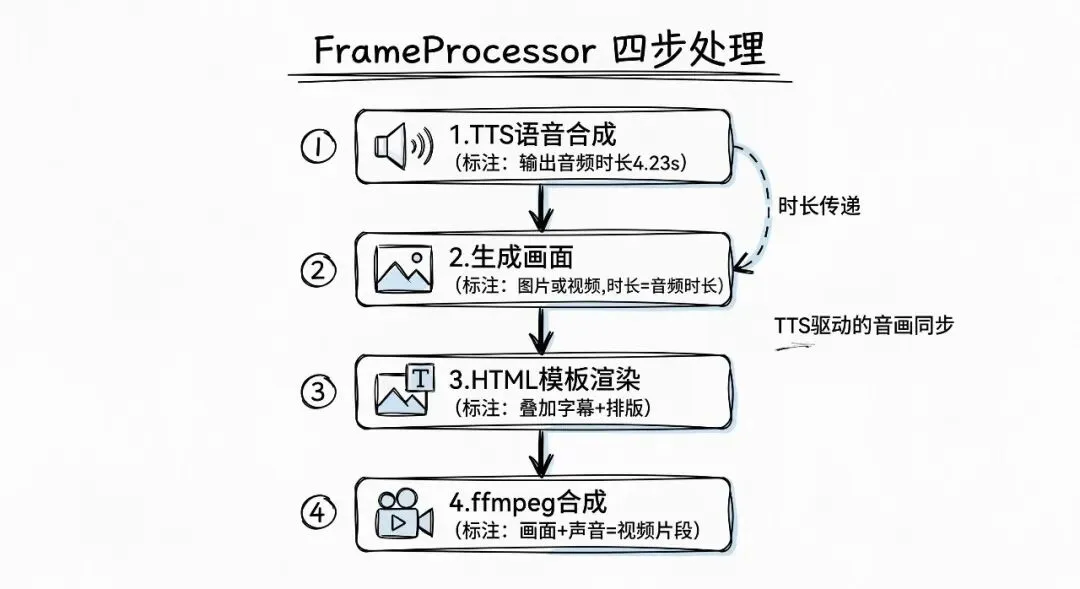
每一帧的处理流程也是一条小流水线,四步走完:
1. 生成语音(TTS)→ 拿到音频时长
2. 生成画面(ComfyUI)→ 图片或视频
3. 合成帧(HTML 模板渲染)→ 叠加字幕和排版
4. 制作视频片段(ffmpeg)→ 把画面和声音拼在一起关键设计点在第一步和第二步的衔接。
TTS 生成语音之后,FrameProcessor 会拿到一个精确的音频时长(比如 4.23 秒)。如果第二步要生成的是视频而不是图片,这个时长会被传给 ComfyUI 的视频生成工作流,让生成的视频长度恰好等于语音长度。
这意味着最终合成的时候,不需要做任何拉伸、裁剪或填充——音频和视频天然对齐。这比”先生成固定长度的视频再去配音”要优雅得多。
# 先 TTS,拿到精确时长
await self._step_generate_audio(frame, config)
# 用音频时长驱动视频生成
if is_video_workflow and frame.duration:
media_params["duration"] = frame.duration还有一个细节值得注意:FrameProcessor 会判断帧是否已经有素材。如果 image_path 或 video_path 已经设好了(比如在素材驱动管线里用户自己提供了图片),就跳过生成步骤,直接进入合成环节。这种”有就用,没有才生成”的策略,让同一个帧处理器可以适配不同的管线。
五、模板系统:用 HTML 排版短视频
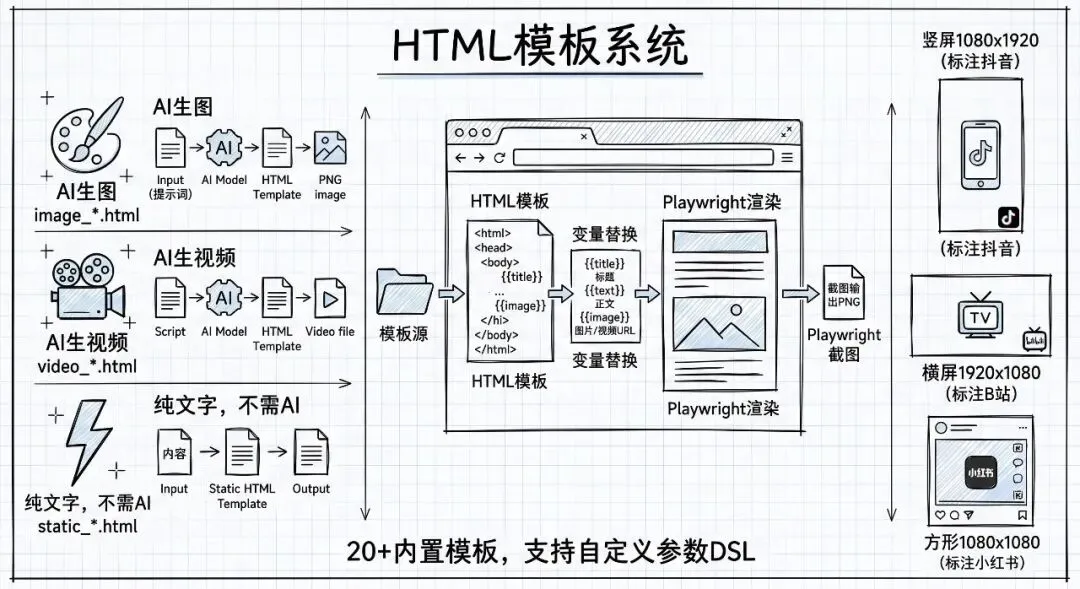
这是整个项目里最让我意外的设计——短视频的”画面”居然是用 HTML 渲染的。
HTMLFrameGenerator 做的事情是:加载一个 HTML 模板文件,把标题、字幕、图片等变量替换进去,然后用 Playwright 启动一个无头 Chromium 浏览器,截图,得到一张 PNG。
这张 PNG 就是这一帧的画面。
# 简化后的核心逻辑
class HTMLFrameGenerator:
async def generate_frame(self, title, text, image, ext, output_path):
# 1. 变量替换 {{title}} → 实际标题
html = self._replace_parameters(self.template, context)
# 2. Playwright 截图
page = await browser.new_page(viewport={'width': 1080, 'height': 1920})
await page.goto(html_file_url)
await page.screenshot(path=output_path, omit_background=True)为什么用 HTML 而不是 Pillow 或者 ImageMagick?
因为 HTML + CSS 在排版上的表达力远超任何图片处理库。你想做圆角卡片、渐变背景、文字阴影、响应式布局——用 CSS 几行搞定的事,用 Pillow 要写几十行代码。更重要的是,设计师可以直接修改 HTML 模板,不需要懂 Python。
模板系统支持三种类型:
- • :需要 AI 生成图片的模板(最常用)
- • :需要 AI 生成视频的模板
- • :纯文字排版,不需要任何 AI 生成
这个分类靠文件名前缀自动判断。如果你选了 static_default.html,整个图片生成管线会被跳过——不调 LLM 写图片提示词,不调 ComfyUI 生成图片。又快又省钱。
模板还支持自定义参数,用 {{param:type=default}} 这种 DSL 语法。类型支持 text、number、color、bool。比如你可以在模板里写 {{accent_color:color=#FF6600}},然后在调用时传入不同的主题色。
项目自带了 20 多个模板,从赛博朋克风到治愈系小清新都有。三种尺寸——竖屏(1080×1920)、横屏(1920×1080)、正方形(1080×1080)——覆盖了抖音、B 站、小红书的主流比例。
六、视频合成:ffmpeg 的精细活
VideoService 是整个项目的”最后一公里”。它负责把所有帧拼成一个完整的视频,加上背景音乐,处理各种时长不匹配的问题。
核心能力有四个:
1. 逐帧合成
每一帧的画面(PNG 截图)加上音频(TTS 语音),用 ffmpeg 合成一个视频片段。静态图片用 -loop 1 让它持续播放,时长精确到音频的毫秒级:
ffmpeg.output(
input_image, input_audio, output,
t=audio_duration, # 精确匹配音频时长
vcodec='libx264', acodec='aac'
)2. 视频叠加
如果模板需要的是视频而不是图片,合成逻辑会更复杂一层。先用 ffmpeg 的 overlay 滤镜把 HTML 渲染出的透明 PNG(字幕层)叠加到视频上,再替换音轨:
原始视频 → 缩放适配 → 叠加字幕层 → 替换为 TTS 语音这里有个 scale_mode 参数控制视频缩放策略:contain(等比缩放留黑边)、cover(等比缩放裁切)、stretch(拉伸变形)。
3. 智能时长对齐
音频和视频的时长经常不一致。VideoService 的处理策略很聪明:
- • 视频比音频短 → 冻结最后一帧补齐(
tpad滤镜),避免黑屏 - • 视频比音频长但在容忍范围内(0.3 秒)→ 不处理
- • 视频比音频长超过容忍范围 → 裁剪
if diff < 0:
# 视频短了,冻结最后一帧
video = self._pad_video_to_duration(video, audio_duration, "freeze")
elif diff > duration_tolerance:
# 视频长了,裁掉
video = self._trim_video_to_duration(video, audio_duration)4. 片段拼接 + BGM
所有帧处理完之后,用 concat 把片段拼在一起。支持两种拼接方式:demuxer(不重新编码,格式必须一致,速度快)和 filter(重新编码,格式可以不同,速度慢)。
BGM 的处理也很完整——支持循环播放、单次播放、音量调节、淡入效果。BGM 文件可以是内置的(放在 bgm/ 目录),也可以是自定义路径。
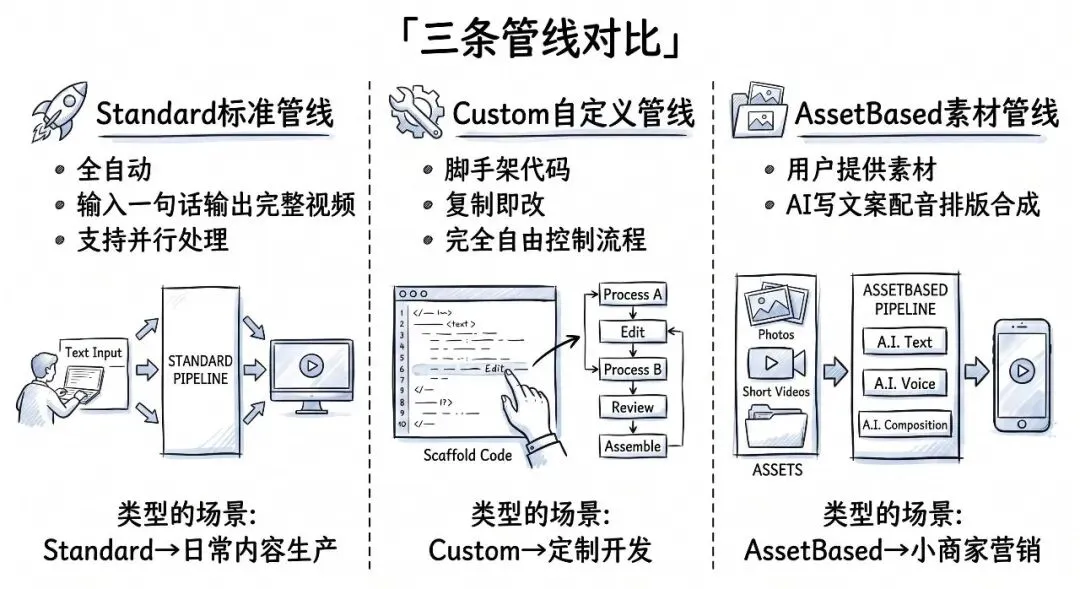
七、三条管线:Standard vs Custom vs AssetBased
项目内置了三条管线,面向不同的使用场景。
Standard:全自动流水线
这是默认的主力管线。你给它一个主题(比如”为什么要养成阅读习惯”),它从头包办一切。
支持两种模式:
- • generate 模式:LLM 根据主题自动生成 N 段旁白
- • fixed 模式:你提供写好的文案,按段落或按行拆分成帧
Standard 管线还有一个不容易注意到的优化——当使用 RunningHub(云端 ComfyUI 服务)时,它会自动开启并行处理。多帧的 TTS 和图片生成可以同时进行,用 asyncio.Semaphore 控制并发上限:
if is_runninghub and runninghub_concurrent_limit > 1:
semaphore = asyncio.Semaphore(runninghub_concurrent_limit)
tasks = [process_frame_with_semaphore(i, frame) for i, frame in enumerate(frames)]
results = await asyncio.gather(*tasks)Custom:自定义脚手架
CustomPipeline 不继承 LinearVideoPipeline 的模板方法,而是直接继承 BasePipeline,把完整的 __call__ 方法暴露出来。
它更像是一个带注释的示例代码——每一步都有详细的说明和替代方案。比如内容处理那一步,注释里同时给出了”按行拆分”和”LLM 生成”两种选项,你取消注释就能切换。
想写自己的管线?复制这个文件,改改逻辑就行。
AssetBased:自带素材的管线
这条管线解决的是另一类需求——你已经有了图片或视频素材,只需要 AI 帮你写文案、配音、排版。
典型场景是小商家做营销视频:拍了几张店铺照片,想自动生成一条带旁白的宣传短视频。
流程和 Standard 管线有明显差异:
- 1. 先分析素材:用 AI 视觉模型理解每张图片/视频的内容
- 2. 用 LLM 写剧本:把素材描述和用户意图一起喂给 LLM,让它规划哪个素材配什么台词
- 3. LLM 直接分配素材:不需要额外的匹配算法,LLM 在生成剧本时就指定了每个场景用哪个素材
这里有个巧妙的地方——LLM 的输出是一个结构化的 Pydantic Model(VideoScript),每个场景包含 asset_path、narrations 列表和 duration。相比自由文本输出,结构化输出让下游的解析和组装变得可靠得多。
八、TTS 服务:一套接口,两种引擎
短视频没有旁白就像哑剧——画面再好看,信息传递效率也打折扣。Pixelle-Video 在语音合成上的设计思路是:一套统一接口,背后跑两种完全不同的引擎。
本地模式:Edge TTS
默认的 inference_mode 是 local,用的是微软 Edge TTS。这个服务完全免费,不需要任何 API Key,支持 400 多种音色、100 多种语言。对于个人创作者来说,这基本够用了。
调用代码很直白:
# 本地模式:直接调 Edge TTS
audio_bytes = await edge_tts(
text="床前明月光,疑是地上霜。",
voice="zh-CN-YunjianNeural",
rate="+20%"
)但免费服务都有一个共同的问题——不稳定。微软的 TTS 服务经常返回 401 认证错误或者 NoAudioReceived,尤其是请求频率高的时候。
项目在 tts_util.py 里做了一套完整的防御机制:
指数退避重试:默认 5 次重试,每次等待时间翻倍并加上随机抖动,最长不超过 10 秒。这是对付限流的标准做法。
# 指数退避 + 随机抖动
exponential_delay = retry_base_delay * (2 ** (attempt - 1))
jitter = random.uniform(0, retry_base_delay)
retry_delay = min(exponential_delay + jitter, _MAX_RETRY_DELAY)并发控制:用 asyncio.Semaphore 限制最多 3 个并发请求,每次请求前还有 0.5 秒的随机延迟。这是在”跑得快”和”别被封”之间找的平衡点。
SSL 证书处理:用 certifi 的证书包替代系统证书,避免不同操作系统上的 SSL 验证问题。这个细节看着小,但在 Windows 整合包的场景下很关键——你不知道用户的系统证书是什么状态。
ComfyUI 模式:工作流驱动
当你需要更高质量的语音——比如 Index TTS 的声音克隆、讯飞 Spark TTS 的情感表达——就切到 ComfyUI 模式。
这时候 TTS 不再是一个本地函数调用,而是变成了一个 ComfyUI 工作流执行。项目在 workflows/ 目录下预置了三套 TTS 工作流:
- •
tts_edge.json:在 ComfyUI 里跑 Edge TTS(适合自建 ComfyUI 服务器的场景) - •
tts_index2.json:Index TTS 2,支持参考音频声音克隆 - •
tts_spark.json:讯飞 Spark TTS
每个工作流文件其实就是一个 ComfyUI 的节点图定义。以 tts_edge.json 为例,核心就三个节点:文本输入 → Edge TTS 节点 → MP3 保存。参数通过特殊的命名约定($text.value!,感叹号表示必填)从外部注入。
统一接口的好处
TTSService 继承了 ComfyBaseService,两种模式共享同一个 __call__ 方法签名。调用方完全不需要关心背后跑的是哪个引擎:
# 本地 Edge TTS
audio = await pixelle_video.tts(text="你好", inference_mode="local")
# ComfyUI 工作流(比如 Index TTS 声音克隆)
audio = await pixelle_video.tts(
text="你好",
inference_mode="comfyui",
workflow="runninghub/tts_index2.json"
)配置文件里 inference_mode 一改,全局切换,上层管线代码一行都不用动。这种”策略模式”的好处在规模化的时候特别明显——你可以先用免费的 Edge TTS 跑通流程,等需要更好的音质了再切到付费方案,迁移成本几乎为零。
音色管理也做了统一抽象。tts_voices.py 定义了一份预设音色列表,涵盖中文、英文、韩语、法语等十几种语言。每个音色有 id、locale、gender 三个维度,方便 Web UI 做筛选和展示。还有一个小巧的 speed_to_rate 函数,把用户友好的速度倍率(1.2x)转换成 Edge TTS 需要的百分比格式(”+20%”)。
九、总结:一个”刚刚好”的工具
写到这里,回头看看 Pixelle-Video 的整体设计,有几个特点值得总结。
设计哲学:模块化 + 可替换
整个项目的核心思路可以概括为一句话:把短视频生产拆成独立的原子能力,然后用管线把它们串起来。
LLM 负责写稿,ComfyUI 负责出图和出视频,Edge TTS 负责配音,Playwright 负责排版,ffmpeg 负责合成。每个环节都是一个独立的 Service,可以单独调用,也可以被替换。
想换大模型?改一行配置。想换图片生成方案?换一个 ComfyUI 工作流。想换 TTS 引擎?切个 inference_mode。上层管线代码不需要动。
这种”乐高积木”式的架构,在 AI 工具链快速迭代的今天特别有价值。明天出了一个更好的 TTS 模型,你只需要写一个新的 ComfyUI 工作流 JSON 文件,往 workflows/ 目录一扔就行。
适合谁用
内容创作者:每天要发抖音、B站、小红书的博主。手动剪辑太慢,外包太贵,AI 全自动刚好填补这个空档。一个主题输进去,几分钟出一条视频。
小商家:拍了几张产品图,想做一条带旁白的宣传视频。AssetBased 管线就是为这个场景设计的。
开发者:想在自己的产品里集成短视频生成能力。FastAPI 接口 + Python SDK 的组合,集成门槛不高。
AI 爱好者:想学习一个完整的 AI 应用是怎么从架构设计到工程落地的。这个项目的代码质量和文档都挺好,值得当作学习案例。
局限性
也要说说不足。
依赖链长:Python + Node.js(Playwright)+ ffmpeg + ComfyUI,环境配置不算简单。虽然项目提供了 Windows 整合包,但在 Mac 和 Linux 上还是得手动装不少东西。
生成质量上限受制于 AI 模型:文案质量取决于 LLM,图片质量取决于 Stable Diffusion / FLUX,语音质量取决于 TTS 引擎。Pixelle-Video 本身是一个”调度器”,它能做到的是把各个环节串得顺畅,但每个环节的天花板不是它能决定的。
不适合精细创作:如果你追求的是每一帧都精雕细琢的作品,全自动流水线显然不是正确的工具。它更适合”量产型”内容——质量达标、效率优先。
ComfyUI 生态绑定:图片、视频、TTS 的能力都通过 ComfyUI 工作流实现,这意味着你需要对 ComfyUI 有基本的了解才能做深度定制。对于纯 Python 背景的开发者来说,有一定学习成本。
最后
短视频的本质是”信息密度 × 传播效率”。Pixelle-Video 没有试图用 AI 替代创意,而是把创意之外的苦力活——写稿、配图、配音、剪辑——交给了自动化流水线。
对于大多数内容创作者来说,瓶颈从来不是”能不能做出视频”,而是”做一条视频要花多少时间”。把这个时间从两小时压缩到两分钟,哪怕质量只有人工制作的 80%,对于日更场景来说也是划算的交易。
项目地址:github.com/AIDC-AI/Pixelle-Video
如果你觉得这篇文章有帮助,欢迎点赞、在看、转发。关注我,下一篇继续拆有意思的开源项目。