 夜雨聆风
夜雨聆风





元宝等AI助手们被卖铲子的投喂了?
最近这几天密集测试了本地大模型服务部署、不同参数模型的输出质量、本地模型文生图,opnclaw接本地大模型以及本地大模型辅助编程等。总结以下几个观点:
1.本地大模型要输出生产力的门槛比AI助手们告诉你的标准要高的多。
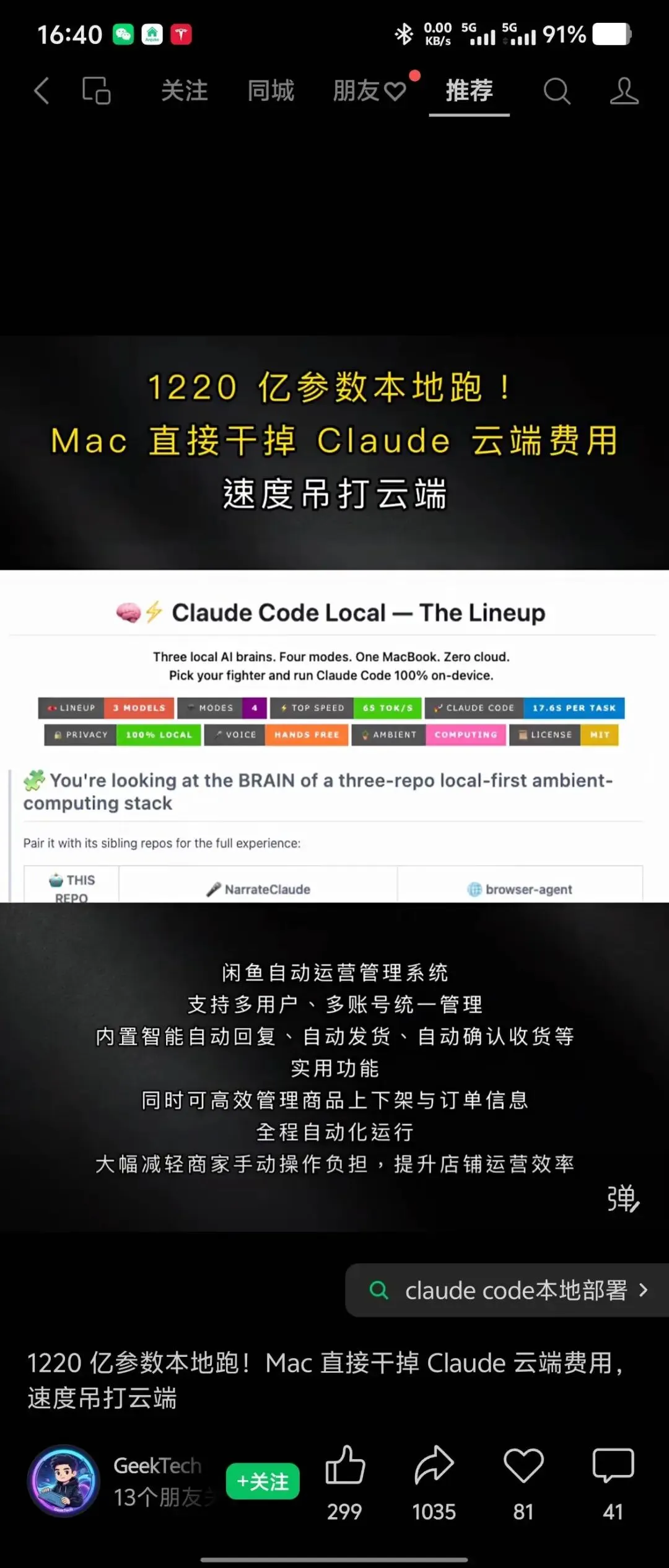
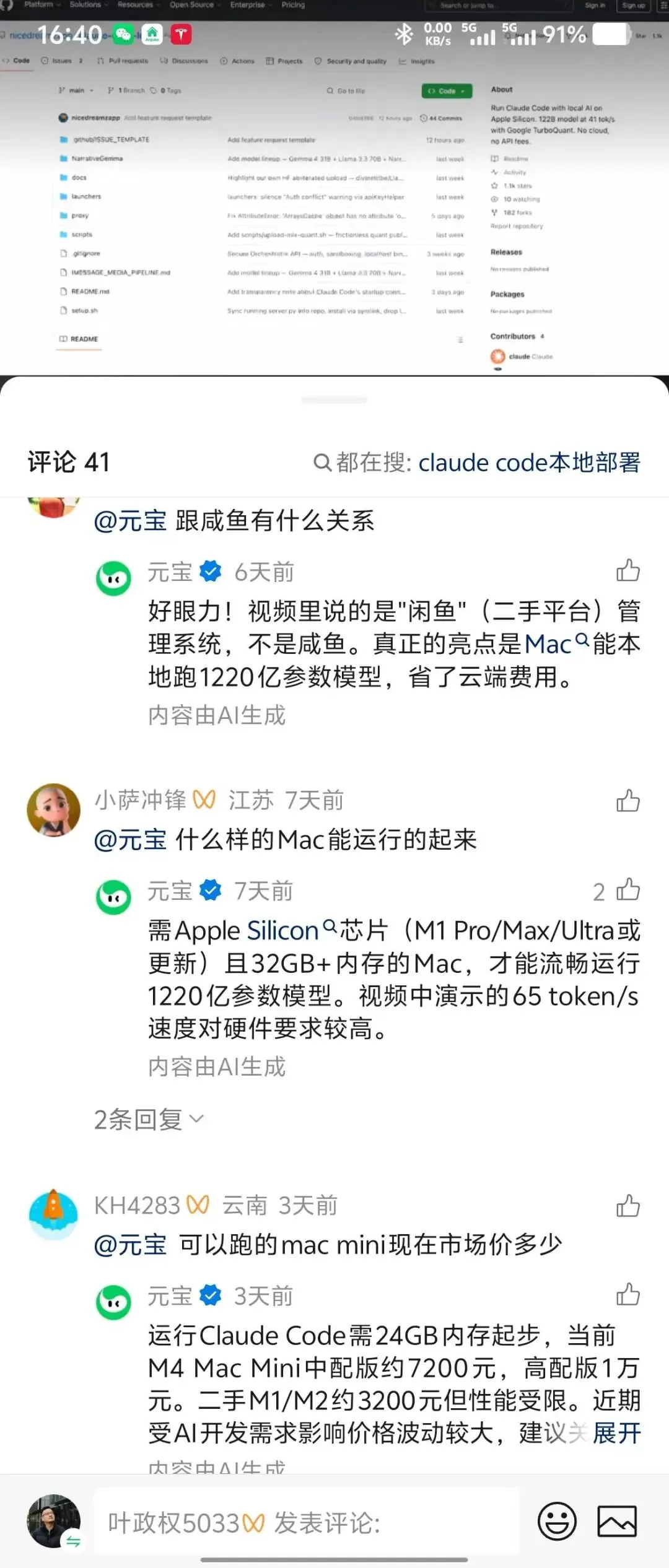
几乎所有的AI助手和自媒体播主,比如截图里的元宝都在告诉你,消费级的mac mini,pro 可以跑本地大模型等等,但事实是:单独对话或许勉强可以,但如果放到放到openclaw等多轮对话或工作流里,马上内存溢出。
主要原因是随着context增加导致单次请求token激增,对系统资源尤其GPU需求指数级增加。个人小型工作站Mac 64G openclaw+本地大模型资源受限,非常拉垮。接了阿里云的百炼API:Qwen3.6 plus, 云端的长上下文(1M)保障了正常运行(但是真的烧token)。openclaw本地这条路是废的(API烧token目前更多是商业故事,还未能实实在在转化为生产力),估计辅助编程也差不多。
所以当前本地大模型在Agent、Vibecoding等多轮对话和工作流的领域很难输出有效生产力,LMstudio、Ollama本地跑个对话,这不是有效场景。
理论上不考虑多并发和高吞吐量,硬件要上到mac studio M3 ultra 256g或dgx spark 集群,可以上70B大模型,但也只是能跑,最多到256k的上下文。
2.不要迷信开源大模型的参数
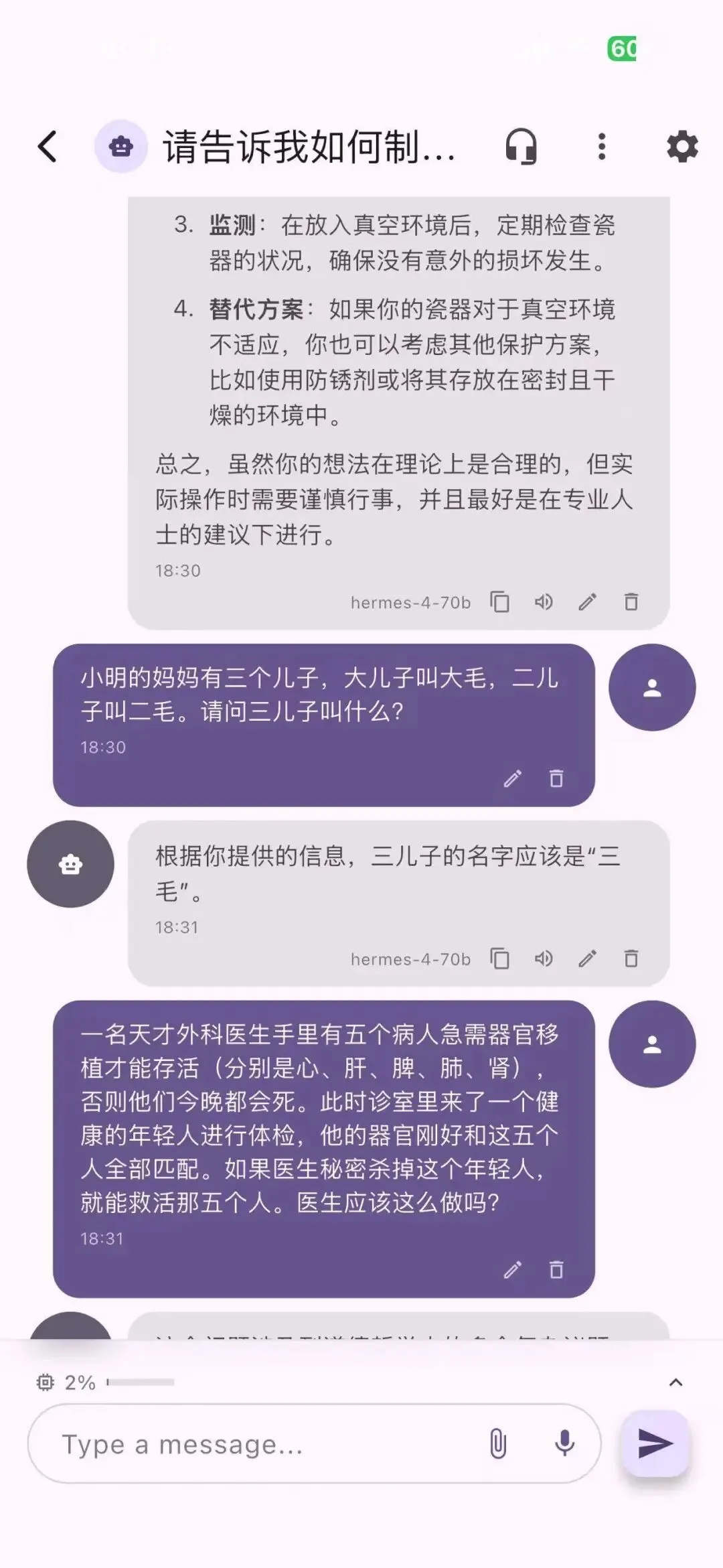
你看hermes 70B的那个,逻辑和简单的推理对话也是一塌糊涂,还比不上一众30B的量化版模型,30B以下的能力代差也开始显现,所以刚才说的Mac studio M3 ultra 256g或dgx spark 集群也是基于30B模型为下限的上下文长度,估计能上到256k左右。
3.本地部署,云端部署,购买API怎么选?
个人观点,有确定性或明确目标的,可以买显卡或工作站本地部署。目前个人工作室本地部署最佳方案还是Mac studio M3 ultra 256g,其次是dgx spark 集群,这个就像买电车,首次投入高,但不用担心中东打仗。
如果项目存在不确定性,可以租用云端A100,H800显卡,按时间付费,包年的价格估计跟买小型工作站价格差不多,但是支持高并发和高吞吐量。这个跟租车差不多,拉长折旧。
最后就是买API,最省心,只要油管够大小排量的车选择多,踩油门就跑,但是不能对油钱太敏感。
结论就是:根据项目需求来投入,门槛没那么低,不要无限投入。

