 夜雨聆风
夜雨聆风





ai4protein论文推荐 | 2026-04-28
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
针对大整数运算中 SIMD 并行化效率低下的问题,现有方法主要面临两大瓶颈:一是加法运算中跨字节的进位依赖链,二是乘法运算中共享累加器导致的 RAW 依赖链。Ren 等人提出的 Carry-Select 方法通过模拟进位选择加法器将大整数拆解为 8 位并行加法,虽能缓解进位传播,但需要大量的 SIMD 到标量转换来准备进位状态,导致进位管理开销占比高达 12.4 倍。y-cruncher 采用的两级 Kogge-Stone 加法器通过分组处理减少串行化,但第二级的进位准备和掩码操作依然主导了运行时间,进位链成本只是发生了迁移而非消除。在乘法方面,Gueron 等人利用 AVX-512 IFMA 指令将计算保留在 SIMD 寄存器中,消除了标量进位链,但共享累加器在迭代间形成了长依赖链,限制了执行端口的利用率,仅能达到 4.2 的 IPC。研究指出,所有现有方法均未重构底层操作以利用真正的数据并行性,而是试图在依赖链周围打补丁。为此,本文提出了 DigitsOnTurbo (DoT) 算法,其核心设计思想是彻底重构计算结构,围绕独立的数据并行操作构建 SIMD 阶段,旨在从根本上消除进位级联和共享累加器带来的性能瓶颈,而非仅仅优化依赖链周围的辅助工作。
中文摘要
大数运算广泛应用于科学计算和密码学领域,但由于传统算法固有的依赖关系,现代 CPU 上对其单指令多数据(SIMD)并行性的采用一直较为有限。我们提出了 DigitsOnTurbo(DoT),该方法围绕独立的数据并行操作重构计算流程,而非对标准算法进行向量化,从而充分利用 SIMD 带来的优势。与先前的 SIMD 实现相比,DoT 在加法和减法运算中最高提升了 1.85 倍,在乘法运算中最高提升了 2.3 倍。当集成到最先进的库中时,DoT 在加法和减法运算中可实现最高 4 倍的性能提升,在乘法运算中可实现最高 2 倍的性能提升;在科学计算中,端到端吞吐量最高提升 19.3%;在密码学实现中,延迟最高降低 7.9%,吞吐量最高提升 5.9%。
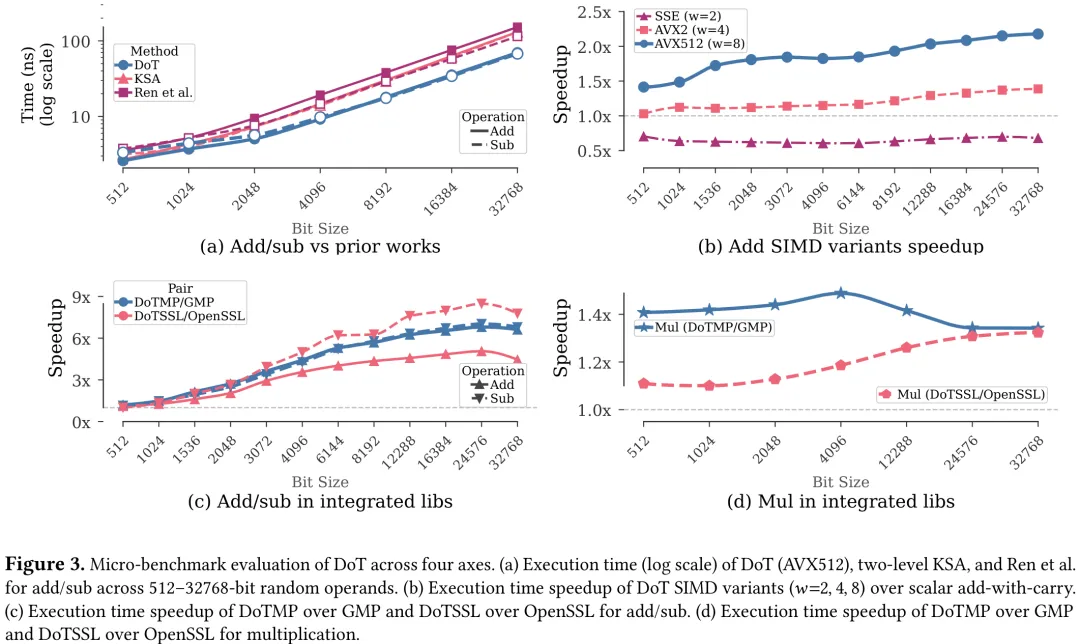
Paper Key Illustration
原文
Leveraging SIMD for Accelerating Large-number Arithmetic
Abstract: Large-number arithmetic, widely used in scientific computing and cryptography, has seen limited adoption of single instruction, multiple data (SIMD) parallelism on modern CPUs due to the inherent dependencies in traditional algorithms. We present DigitsOnTurbo (DoT), which restructures the computation around independent, data-parallel operations, rather than vectorizing the standard algorithms, thereby leveraging the benefits provided by SIMD. Over prior SIMD implementations, DoT achieves up to 1.85x speedups for addition and subtraction, and 2.3x for multiplication. When integrated into state-of-the-art libraries, DoT yields up to 4x speedup for addition and subtraction, and up to 2x speedup for multiplication, cascading into end-to-end throughput gains of up to 19.3% for scientific computations, and up to 7.9% latency and 5.9% throughput improvements on cryptographic implementations.
链接:https://arxiv.org/pdf/2604.21566
AI 深度解读
本研究旨在通过 SHAP 可解释性分析评估无监督异常检测(UAD)算法的多样性及其对集成模型性能的影响。研究首先构建了四种基于 SHAP 的相似性度量指标(线性相关性、特征重要性排名相似度、异常分数相关性及 Jaccard 指数),并将其转化为不相似性矩阵。利用 Mantel 检验发现,不同相似性矩阵之间存在显著正相关,表明算法在解释模式与预测结果上具有高度一致性,但具体相关性随数据集变化。实验在 ADBench 库中筛选的 16 个小型数据集上,使用 14 种主流 UAD 算法(如 COPOD、ECOD、OCSVM 等)进行验证。结果揭示了两类算法聚类:一类是基于分布假设的 COPOD 与 ECOD,另一类是基于距离度量的 OCSVM、IForest 等。研究进一步探讨了集成策略,指出结合在相似性矩阵中距离较远的模型(即解释模式差异大的模型)能有效提升集成系统的鲁棒性与准确率,从而证明利用 SHAP 度量算法多样性对于构建高性能异常检测集成系统具有重要意义。
中文摘要
摘要:无监督异常检测因数据分布的多样性和标签缺失而成为一个具有挑战性的问题。集成方法通常被采用以通过结合多个检测器来缓解这些挑战,从而减少个体偏差并增强鲁棒性。然而,构建真正具有互补性的集成仍具挑战性,因为许多检测器依赖于相似的决策线索,最终产生冗余的异常分数。因此,集成学习的潜力往往受限于识别能够真正捕捉不同类型不规则性的模型的难度。为解决这一问题,我们提出了一种通过其决策机制对异常检测器进行表征的方法论。利用 SHapley Additive exPlanations(SHAP),我们量化了每个模型如何对输入特征分配重要性,并利用这些归因剖面来衡量检测器之间的相似性。我们的研究表明,具有相似解释的检测器倾向于产生相关的异常分数并识别高度重叠的异常;相反,解释的显著差异可靠地指示了互补的检测行为。我们的结果证明,基于解释的指标为集成中模型选择提供了不同于原始输出的新标准。然而,我们也证明,仅靠多样性是不够的;高个体模型性能仍是有效集成的先决条件。通过明确针对解释多样性同时保持模型质量,我们能够构建出更具多样性、更具互补性,并最终在无监督异常检测中更为有效的集成。
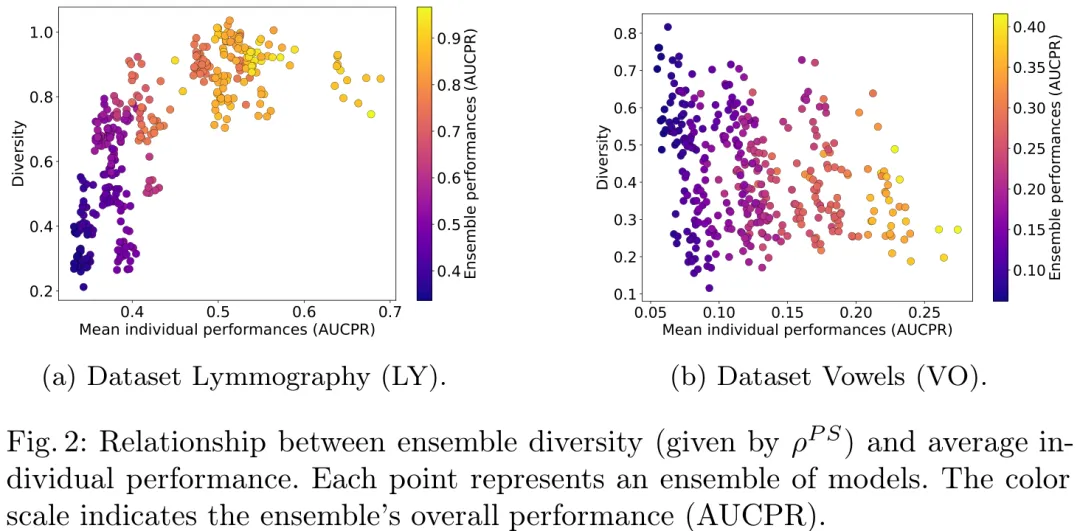
Paper Key Illustration
原文
Analyzing Shapley Additive Explanations to Understand Anomaly Detection Algorithm Behaviors and Their Complementarity
Abstract: Unsupervised anomaly detection is a challenging problem due to the diversity of data distributions and the lack of labels. Ensemble methods are often adopted to mitigate these challenges by combining multiple detectors, which can reduce individual biases and increase robustness. Yet building an ensemble that is genuinely complementary remains challenging, since many detectors rely on similar decision cues and end up producing redundant anomaly scores. As a result, the potential of ensemble learning is often limited by the difficulty of identifying models that truly capture different types of irregularities. To address this, we propose a methodology for characterizing anomaly detectors through their decision mechanisms. Using SHapley Additive exPlanations, we quantify how each model attributes importance to input features, and we use these attribution profiles to measure similarity between detectors. We show that detectors with similar explanations tend to produce correlated anomaly scores and identify largely overlapping anomalies. Conversely, explanation divergence reliably indicates complementary detection behavior. Our results demonstrate that explanation-driven metrics offer a different criterion than raw outputs for selecting models in an ensemble. However, we also demonstrate that diversity alone is insufficient; high individual model performance remains a prerequisite for effective ensembles. By explicitly targeting explanation diversity while maintaining model quality, we are able to construct ensembles that are more diverse, more complementary, and ultimately more effective for unsupervised anomaly detection.
链接:https://arxiv.org/pdf/2602.00208
AI 深度解读
该研究针对大语言模型(LLM)在随机采样任务中的分布拟合能力进行了系统性评估,旨在揭示其偏离理想独立同分布(i.i.d.)采样基准的内在机制。研究首先构建了基于 Wasserstein-1 距离(W1)的误差度量框架,将采样误差分解为两部分:一是由模型固有分布与目标分布不匹配导致的不可约偏差(Intrinsic Mismatch Floor),二是随采样数量增加而衰减的采样噪声。在此基础上,研究提出了‘上下文 – 保真度困境’(Context–Fidelity Dilemma):在批量生成模式下,虽然长上下文能通过早期自修正降低误差,但超过临界阈值后,长程自回归引发的累积漂移(Drift)效应将超过修正增益,导致整体保真度下降。实验部分选取了包括 GPT-4o、Llama-3.3、DeepSeek-V3.2 在内的十一款前沿模型,涵盖从均匀分布、高斯分布到重尾分布(如 Student’s t、Gamma)等三类共十五种概率分布进行基准测试。结果显示,LLM 的采样行为并非简单的随机噪声叠加,而是呈现出协议依赖的系统性偏差,特别是在处理具有严格约束或长尾特性的分布时,其表现显著低于传统统计采样器的理论下限。
中文摘要
摘要:随着大语言模型(LLMs)从聊天界面转变为教育评估和合成数据构建等领域随机流程中的核心组件,能够忠实地从指定概率分布中进行采样已成为一项功能性需求,而非仅仅是理论上的好奇。我们首次对前沿大语言模型的原生概率采样进行了大规模、具有统计效力的审计,在 15 种分布上对 11 个模型进行了基准测试。为厘清失效模式,我们采用双重协议设计:批量生成(Batch Generation),即模型在一次响应中生成 N=1000 个样本;以及独立请求(Independent Requests),即包含 N=1000 次无状态调用。我们观察到显著的协议不对称性:批量生成仅达到适度的统计有效性,中位通过率仅为 13%;而独立请求则几乎完全失效,11 个模型中有 10 个未能通过任何分布的测试。除这种不对称性外,我们还发现采样保真度随分布复杂度的增加而单调下降,且随着请求的采样范围 N 增大而加剧。最后,我们展示了这些失效如何传播至下游任务:模型无法在多选题生成中强制执行答案位置的均匀性约束,并在属性约束的文本到图像提示合成中系统性地违反人口统计目标。这些发现表明,当前的大语言模型缺乏功能性的内部采样器,对于需要统计保证的应用场景,必须依赖外部工具。
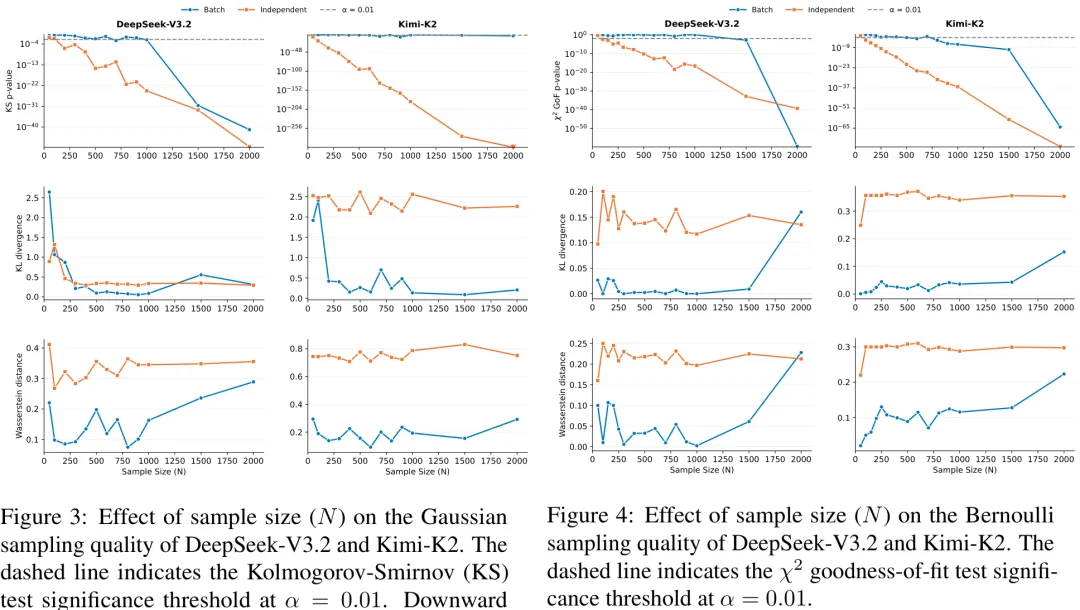
Paper Key Illustration
原文
Large Language Models Are Bad Dice Players: LLMs Struggle to Generate Random Numbers from Statistical Distributions
Abstract: As large language models (LLMs) transition from chat interfaces to integral components of stochastic pipelines across domains like educational assessment and synthetic data construction, the ability to faithfully sample from specified probability distributions has become a functional requirement rather than a theoretical curiosity. We present the first large-scale, statistically powered audit of native probabilistic sampling in frontier LLMs, benchmarking 11 models across 15 distributions. To disentangle failure modes, we employ a dual-protocol design: Batch Generation, where a model produces N=1000 samples within one response, and Independent Requests, comprising N=1000 stateless calls. We observe a sharp protocol asymmetry: batch generation achieves only modest statistical validity, with a 13% median pass rate, while independent requests collapse almost entirely, with 10 of 11 models passing none of the distributions. Beyond this asymmetry, we reveal that sampling fidelity degrades monotonically with distributional complexity and aggravates as the requested sampling horizon N increases. Finally, we demonstrate the propagation of these failures into downstream tasks: models fail to enforce uniform answer-position constraints in MCQ generation and systematically violate demographic targets in attribute-constrained text-to-image prompt synthesis. These findings indicate that current LLMs lack a functional internal sampler, necessitating the use of external tools for applications requiring statistical guarantees.
链接:https://arxiv.org/pdf/2601.05414
AI 深度解读
本研究旨在量化气象条件对牛只采食行为及摄入量的影响,并构建高精度的预测模型。研究首先通过广义加性模型(GAM)与非线性单调回归结合样条变换,对采食时长、采食事件频率及时间等关键行为指标中的异常值进行识别与修正,确保数据质量。随后,整合了来自爱达荷州 Salmon 和蒙大拿州 Corvallis 两站的高分辨率气象数据(包括温度、湿度、风速、辐射等),并生成了 1 至 6 天的时间滞后变量。为综合气象效应,研究构建了两种指数:仅基于气象变量的热舒适度指数(InComfort)和融合采食响应变量的混合指数(EASI)。利用主成分分析降维后,通过 K-means 聚类将热环境划分为冷应激、舒适及热应激等五个区间。在预测模型构建阶段,对比评估了 XGBoost、CatBoost、LightGBM 和贝叶斯岭回归四种算法,最终选定最优模型用于预测个体及群体日采食量,并利用 SHAP 分析揭示了各预测因子的相对重要性。研究结果表明,在 2020-2024 年的大陆性气候条件下,牛只日均采食时间约为 2 小时 12 分钟,日均采食量约为 11.89 公斤,个体间存在显著差异,这主要归因于个体采食模式及应对热应激能力的不同,而非数据误差。该研究不仅提供了可靠的采食行为量化方法,还通过多源气象数据融合与机器学习技术,实现了对复杂热环境下牛只营养摄入的精准预测,为优化牧场环境管理提供了科学依据。
中文摘要
摘要:技术进步正在变革可持续的养牛实践,电子饲喂系统为个体动物的采食量生成了大量纵向数据集,为自主精准畜牧系统提供了可能性。然而,现有文献仍缺乏一种充分利用这些纵向大数据以准确预测采食量并考虑环境条件的研究方法。为填补这一空白,我们开发了一个基于人工智能的框架,用于准确预测个体动物及栏位水平的采食量。本研究使用了在爱达荷州卡门(Carmen, ID)的南希·M·卡明斯研究与推广教育中心(Nancy M. Cummings Research Extension & Education Center)饲料场进行的 19 项实验(>1650 万个样本,2013-2024 年)的数据,以及来自农业气象网(AgriMet Network)气象站的环境数据,开发了两种新型环境指数:仅基于气象变量的“舒适度指数”(InComfort-Index)在预测热舒适度方面表现良好,但预测采食量的能力有限;而整合环境变量与采食行为数据的混合指数“环境 – 采食综合指数”(EASI-Index)在预测采食量方面表现优异,但在预测热舒适度方面效果较弱。结合上述环境指数,我们训练了机器学习模型,其中表现最佳的模型(XGBoost)在个体动物水平的均方根误差(RMSE)为 1.38 千克/天,在栏位水平仅为 0.14 千克/(天·动物)。该方法为预测个体动物及栏位的采食量提供了一个稳健的基于人工智能的框架,具有通过减少饲料浪费、优化资源配置以及实施气候适应性畜牧管理,在饲料场牛只精准管理方面的潜在应用价值。
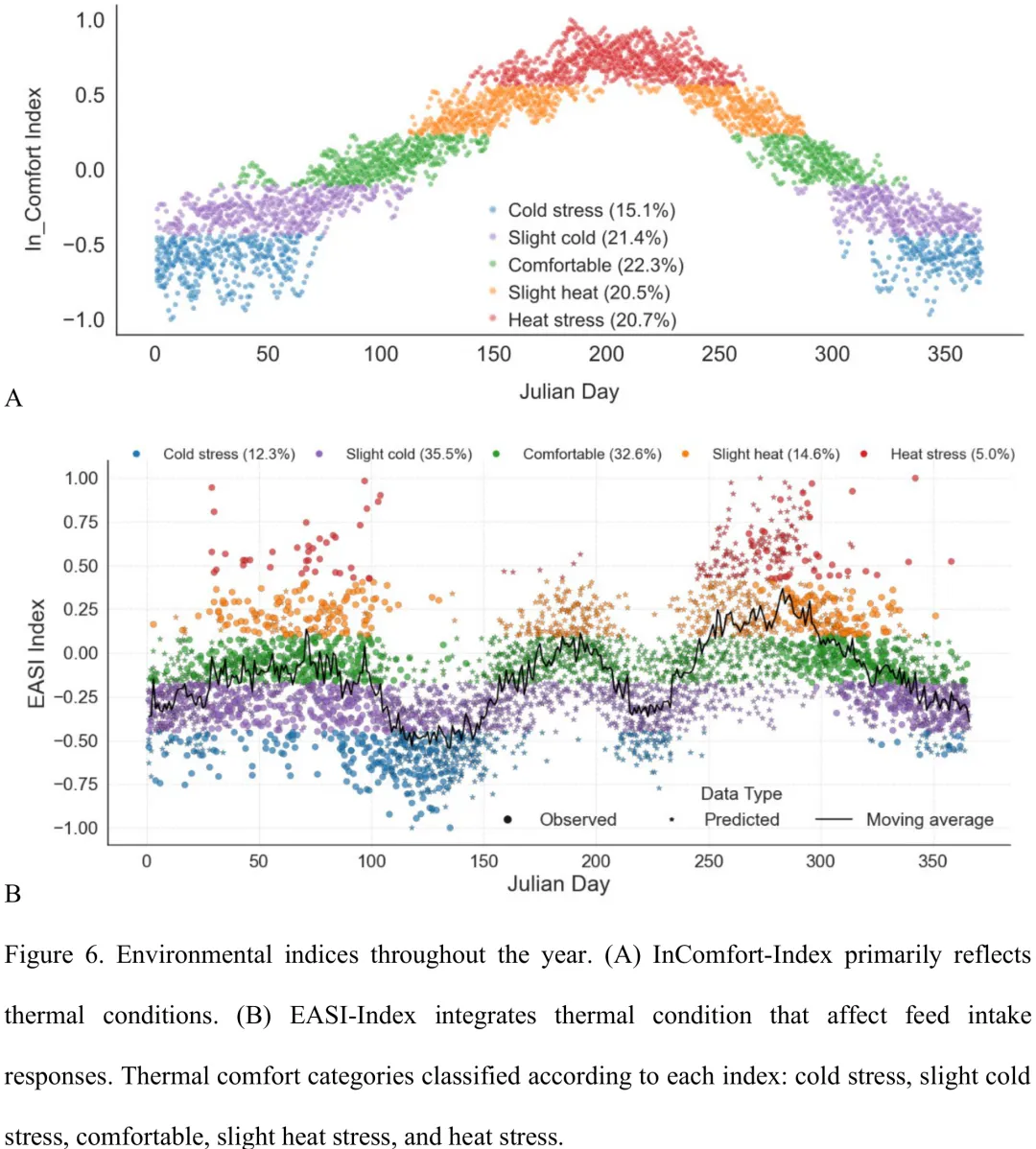
Paper Key Illustration
原文
AI-based framework to predict animal and pen feed intake in feedlot beef cattle
Abstract: Advances in technology are transforming sustainable cattle farming practices, with electronic feeding systems generating big longitudinal datasets on individual animal feed intake, offering the possibility for autonomous precision livestock systems. However, the literature still lacks a methodology that fully leverages these longitudinal big data to accurately predict feed intake accounting for environmental conditions. To fill this gap, we developed an AI-based framework to accurately predict feed intake of individual animals and pen-level aggregation. Data from 19 experiments (>16.5M samples; 2013-2024) conducted at Nancy M. Cummings Research Extension & Education Center (Carmen, ID) feedlot facility and environmental data from AgriMet Network weather stations were used to develop two novel environmental indices: InComfort-Index, based solely on meteorological variables, showed good predictive capability for thermal comfort but had limited ability to predict feed intake; EASI-Index, a hybrid index integrating environmental variables with feed intake behavior, performed well in predicting feed intake but was less effective for thermal comfort. Together with the environmental indices, machine learning models were trained and the best-performing machine learning model (XGBoost) accuracy was RMSE of 1.38 kg/day for animal-level and only 0.14 kg/(day-animal) at pen-level. This approach provides a robust AI-based framework for predicting feed intake in individual animals and pens, with potential applications in precision management of feedlot cattle, through feed waste reduction, resource optimization, and climate-adaptive livestock management.
链接:https://arxiv.org/pdf/2511.17663
AI 深度解读
本文针对智能电网环境下非智能家用电器的智能化管理难题,提出了一种低成本智能负载节点(SLN)解决方案。该研究通过结合负载管理单元(LMU)与任意调度算法,实现了非智能家电(如电动汽车充电桩、水井泵、洗碗机等)的无线电力参数监测与用户指令交互。研究指出,尽管 LMU 与 SLN 之间存在 7-9 秒的通信延迟,但对于此类可调度负载而言,该延迟在实际操作中可忽略不计,且成本降低幅度主要取决于所选调度算法的有效性。案例研究验证了该方案在智能电网范式下对非智能负载进行负载管理算法实施的可行性,证明了其作为无线功率及功率因数计量器的实用价值,为居民侧需求响应和智能建筑能源管理提供了有效途径。
中文摘要
摘要:本文提出了一种基于所提出的智能负载节点(SLN)的新方法,用于在智能电网环境下实现非智能家用电器的有效运行。在现实场景中,目前广泛使用的非智能负载数量众多,若为每种负载嵌入特定智能功能以将其转化为智能负载,其成本将远高于所提出的 SLN 方案;而 SLN 作为一种适用于各类非智能负载的通用解决方案,无需对家庭电气线路进行任何基础设施改造,也无需在制造阶段或消费端对家用电器进行结构性变更,从而为智能电网环境下非智能家用电器的智能运行提供了一种切实可行的低成本方案。SLN 以分布式无线传感器节点的形式部署于家庭内部,构成家庭区域网络(HAN)。该 HAN 包含一个负载管理单元(LMU),作为所有分布式 SLN 的主控节点。HAN 采用 Wi-Fi 作为通信介质。LMU 集成了负载管理算法,该算法以 Python 脚本形式编写。
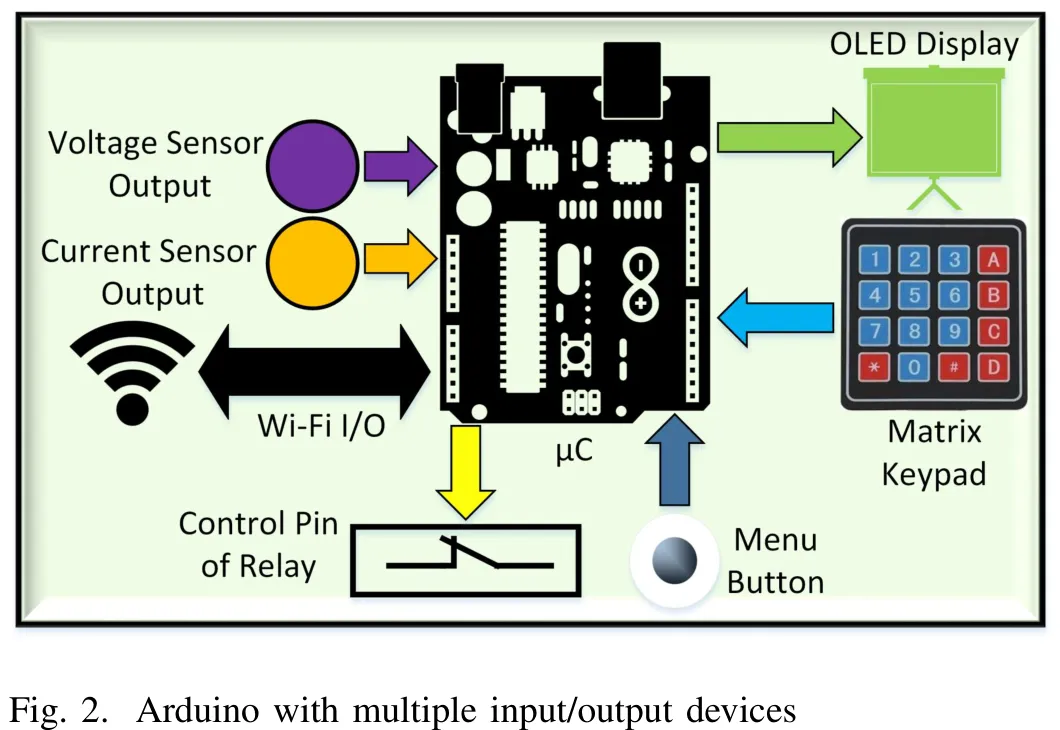
Paper Key Illustration
原文
Smart Load Node for Nonsmart Load Under Smart Grid Paradigm: A New Home Energy Management System
Abstract: This article presents a novel approach for efficient operation of non-smart household appliances under smart grid environment using the proposed smart load node (SLN). In real world scenario, there are so many non-smart loads currently in use and embedding appliance specific intelligence into them to make them as smart loads will be more expensive compared to the proposed SLN, which is a common solution for all types of non-smart loads. This makes the proposed low-cost SLN, which neither requires any infrastructural change in the electrical wiring of a house nor any constructional change in home appliances at the manufacturing stage and at the consumer end, as a feasible solution for intelligent operation of non-smart home appliances under smart grid environment. The SLNs, which are placed in a home like distributed wireless sensor nodes, form a home area network (HAN). The HAN includes a load management unit (LMU) which acts as master for all distributed SLNs. Wi-Fi is chosen as a medium of communication in the HAN. The LMU incorporates load management algorithm which is written in Python script.
链接:https://arxiv.org/pdf/1810.06450
Subscribe to arXiv’s Daily Preprint Notifications