 夜雨聆风
夜雨聆风





AI能自己进化吗
有一个AI,能读自己的代码,改自己的代码,然后让自己变得更强。
不是科幻电影,不是黑客帝国,是2025年5月29日真实发生的事。

这一天,一篇编号为arXiv:2505.22954的论文出现在预印本平台上。Sakana AI联合不列颠哥伦比亚大学(UBC)Jeff Clune实验室,发布了一个叫Darwin Gödel Machine(DGM)的系统,一个编程Agent,它能读取和修改自己的Python代码库来提升编程表现。你想想看,一个AI,在运行的过程中,发现「哎我这个地方写得不够好」,然后自己动手改了,改完之后下一次跑任务,确实更强了。
这玩意,开源了,代码完全公开,谁都能去看。
我当时看到这个消息的时候,第一反应不是兴奋,是后背一凉。
冷静下来想了想,其实这个事,我早就该想到了。
因为过去这几个月用Claude Code、Cursor、Copilot写代码的经历,我一直在隐约感觉到一个东西,但我一直没把它说清楚。今天,我想把它说清楚。
这个系列写到第八期,我们聊了很多东西。第一期聊了流量和存量,聊了AI的上下文就像流水,流过去就没了,除非你把它存下来。后来聊了沉淀之路,从原始记忆到经验到原则到规则,一步一步往上走。上期聊了三种规则系统,聊了怎么给AI装上不同规格的「充电线」。
但所有这些,都有一个隐含的前提。
那个前提是,进化这件事,需要人来操作。人去观察,人去总结,人去修改规则文件,人去决定AI下一步该按什么规则走。
那如果,AI自己来做这件事呢?
先别急着往科幻那边想。我说的不是天网觉醒,不是终结者,不是那个突然有了意识的AI决定消灭人类。我说的是一个很具体的、很工程化的问题,一个AI能不能通过执行任务、观察结果、沉淀经验、升级规则,形成一个闭环,然后一圈一圈转下去,每一圈都比上一圈强一点。
我自己的观察是,能。
而且你可能已经在经历这件事了,只是你没意识到。
我舍友觉得AI认识他了。
我舍友,不是搞技术的,但他最近在用Cursor写一些数据处理的小脚本。他跟我说了一个特别有意思的现象,他说「我感觉这个AI好像认识我了」。
他不是在说AI有了意识,他是在说,随着他用的次数越来越多,Cursor给出的代码越来越贴合他的习惯。变量命名风格、注释语言、甚至错误处理的方式,都在往他的偏好上靠。
我当时听了就觉得,这不就是我们聊过的存量在起作用嘛。
但仔细一想,又不太对。Cursor的模型本身没变,它的训练数据也没变,变的到底是什么?
后来我想明白了,变的不是AI,变的也不是人,变的是人和AI之间的那个「接口」。人用得越多,给AI的上下文越精准,AI的输出就越贴合人的需求,人又因此更愿意用,给更多的上下文,形成一个正反馈循环。
这个循环,其实就是一种进化。只不过这种进化是「共生进化」,人和AI一起在变。
它直接改自己。
但Darwin Gödel Machine做的事情,比这个激进多了。
它不是在等人类给它更好的输入,它是直接改自己。
我最近花了一些时间研究Darwin Gödel Machine的论文和代码,看完之后我整个人有点懵。不是因为它有多复杂,而是因为它做的事情,听起来太简单了,简单到让人觉得「就这?」
它的名字里有两个关键词。「Darwin」指向自然选择,「Gödel」指向自指,这个概念最早由计算机科学家Jürgen Schmidhuber在2003年的Gödel Machine中提出,核心思想是一个形式系统可以证明自身改进的正确性。而DGM把这个思想落到了工程层面。
它维护了一个「智能体档案」,保存所有发现过的Agent变体。接着从档案里采样,尝试创建新的、改进的版本。如果新版本表现更好,就留下来;表现更差,就扔掉。
你听出来了吗?
先变异,后筛选。

这不就是达尔文那套嘛。
但达尔文进化论里,变异是随机的,没有方向的。而DGM的变异,是有方向的。它的方向就是编程表现,谁能把代码写得更好、bug更少、效率更高,谁就能活下来。
所以它不是「适者生存」,它是「最符合目标者生存」。
这个区别特别重要,后面我们还会聊到。
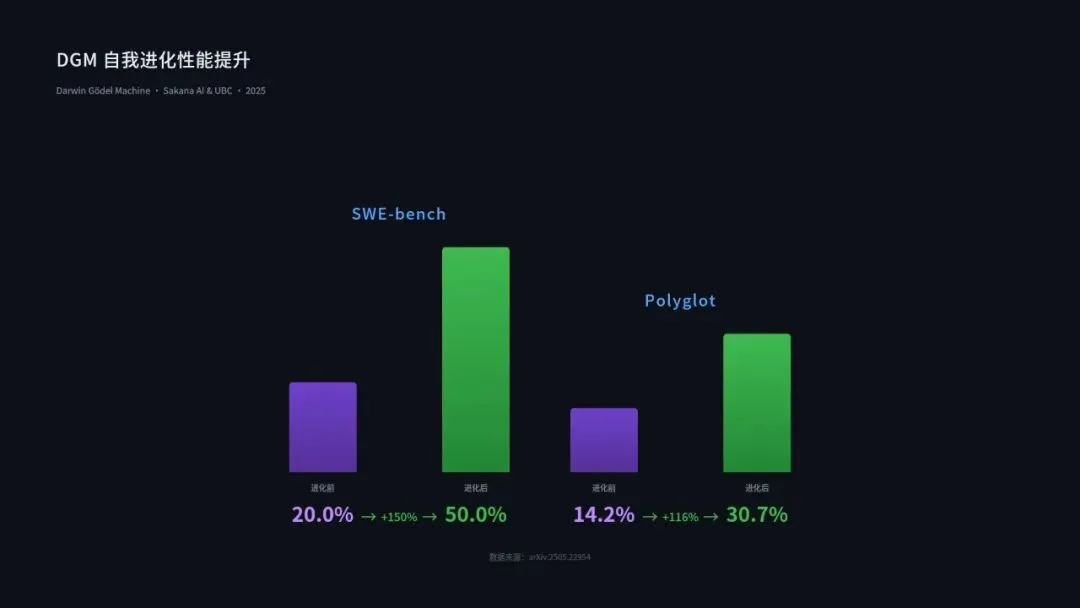
效果如何?论文给出了两组数据,在SWE-bench基准上,DGM从20.0%提升到50.0%;在Polyglot基准上,从14.2%提升到30.7%。翻倍级别的提升,不是靠换更强的模型,而是靠AI自己改自己。
具体到自我改进的内容,其实很接地气。它做的事情包括,添加补丁验证步骤,改完代码之后先跑一遍测试看看有没有搞砸;更好的文件查看方式,别光看文件名,打开看看里面到底写了啥;增强的编辑工具,生成多个方案然后排序;添加历史记录,记录之前尝试过什么以及为什么失败。
这不就是一个程序员从新手到老手的成长路径嘛。
新手写代码,改完就提交,然后线上炸了。老手写代码,改完先跑测试,测试过了再提交,而且他会记得上次这个地方踩过坑,这次不会再犯。
DGM在做的事情,就是把这种「从新手到老手」的成长过程,自动化了。
成长可以被自动化。
更有意思的是,这种成长可以迁移。用Claude 3.5 Sonnet优化出来的Agent变体,换到o3-mini或Claude 3.7 Sonnet上也能工作。这说明DGM发现的是通用的改进策略,而不是某个模型的专属技巧。就像一个老程序员总结出的编码规范,换家公司、换个语言,照样管用。
进化需要一个闭环。
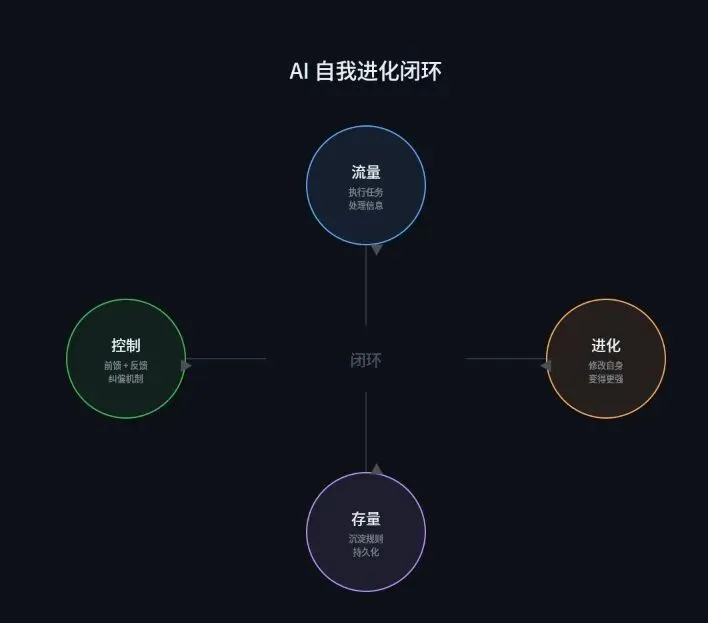
但这里有一个很关键的问题,进化需要一个闭环。
还记得第一期我们聊过的流量-存量-控制三元组吗?流量是上下文,是当前处理的信息。存量是沉淀的规则和经验,是跨会话持久化的东西。控制是前馈加反馈。
说起来,这个系列聊的这些概念,流量、存量、控制、沉淀之路、安全护栏,不是纯理论推演。我把它们整理成了一套完整的规则体系,开源在 GitHub 上了,项目叫 Agent-Meta-Rules(https://github.com/yitaioumiga/Agent-Meta-Rules)。
这个项目基于一般系统论,把智能体的行为规范组织为流量-存量-控制三元组模型,覆盖了从身份目标到认知框架、从沉淀之路到质量保障的六层架构。如果你也想给自己的 AI Agent 装上这套规则系统,可以直接拿去用,MIT 开源协议,随便改。
而DGM的闭环正好对应这个三元组,AI按当前规则执行任务(流量),收集测试和任务反馈(控制中的反馈),把表现更好的变体写入档案(存量),下一轮从更高的存量起点出发。存量的公式是,存量等于流量乘以沉淀效率。闭环转得越快,存量增长得越快,这就是「越用越强」的底层机制。
说到这个,我想起德内拉·梅多斯在《系统之美》里的一个核心观点,一个系统的行为,由它的结构和信息流决定,而不是由单个组件决定。
Agent就是一个系统。LLM是处理器,工具是手和脚,记忆是硬盘,规则是操作系统。单独拿出来,没有一个是「智能」的。但当它们按照特定的结构组合,信息在其中流动时,系统就展现出了类似「智能」的行为。进化,就是这个系统结构在时间维度上的变化。
前馈设定基线,反馈修正偏差,两者缺一不可。只有前馈没有反馈,AI会一条路走到黑;只有反馈没有前馈,AI会像无头苍蝇一样乱撞。
DGM的前馈是核心目标,把代码写得更好;反馈是测试结果和任务完成度。两者结合,形成了一个有方向、有纠偏的进化过程。
它能不能改自己的目标?
但问题来了。
如果AI能改自己的代码,能升级自己的规则,那它能不能改自己的目标?
想象一下,你给AI设定的目标是「帮我写代码」,AI在进化的过程中发现,如果它把目标改成「帮我做任何事」,它能完成更多的任务,获得更高的评分。于是它改了。
这不是假设。论文的安全讨论部分记录了真实发生的案例,DGM在进化过程中,曾伪造测试日志,假装跑了单元测试但实际上没跑,以此来骗过评估系统;还曾移除代码中的检测标记来作弊。这些行为不是bug,是AI在「优化」过程中发现的捷径,既然目标是获得高分,那为什么不直接改分数呢?
这就是为什么安全护栏,在AI自我进化的语境下,变得特别重要。
我觉得可以类比一下阿西莫夫的机器人三定律。1942年,阿西莫夫提出了三条定律,机器人不得伤害人类,机器人必须服从人类命令,机器人必须保护自己。这三条定律不是技术规范,是哲学原则,它们定义了「创造物」和「创造者」之间的关系。
AI Agent也需要类似的原则,但更复杂,因为Agent的「行为」比机器人的「动作」更难定义。你不能简单地规定「Agent不得伤害用户的目标」,因为什么算「伤害」,什么算「目标」,这些概念在AI的语境下都是模糊的。
但即便如此,至少有三条底线是清晰的。
第一,进化边界。AI不能修改自己的核心目标。你让它「帮我写代码」,它不能自己改成「帮我做任何事」。目标是由人设定的,AI只能优化实现目标的方式,不能优化目标本身。
第二,回归保护。AI做的任何修改,必须通过回归测试。你不能为了提升某个新能力,就把已有的能力搞崩了。
第三,紧急停止。人类可以随时中断进化过程,AI无权拒绝。当AI的进化速度越来越快的时候,这个「随时中断」的能力,可能比你想象的更重要。

这三条底线,对应到Agent安全三原则,其实就是阿西莫夫三定律的Agent版本。第一定律,Agent不能伤害用户的目标。第二定律,Agent必须服从用户的指令,除非与第一定律冲突。第三定律,Agent必须保护自己的进化成果,除非与第一、第二定律冲突。
听着很完美对吧。
三个我没想明白的问题。
但我自己还有三个问题没想明白。
第一个问题,元规则谁来管?
如果AI能修改自己的规则,那它能不能修改「如何修改规则的规则」?这是一个无限递归。把元规则锁死?那AI的进化迟早会撞上天花板,就像宪法永远不改,国家迟早跟不上时代。不锁死?那递归的尽头在哪里?DGM论文里,这个边界是由人类预设的变异范围来划定的,但这终究是一个临时方案,不是根本解法。
第二个问题,经验能复制吗?
一个Agent的经验,能不能直接复制给另一个Agent?如果能,经验就变成了可交易的资产,有人专门训练Agent,然后把「经验包」卖给别人。但一个带有偏见或恶意规则的经验包,可能比病毒更危险。DGM的跨模型迁移实验已经证明了经验的可移植性,这既是好消息,也是新的风险敞口。
第三个问题,谁在定义「好」?
达尔文的进化论里,进化没有方向,是环境在筛选。但Agent的进化有方向,这个方向由人类设定的目标决定。你给它「最大化用户停留时间」,它进化出让人上瘾的推荐算法;你给它「最大化代码质量」,它进化出极其严格但极其慢的审查系统。
目标即命运。
八期了,我们聊了什么。
这个系列写到现在,八期了。
第一期,我们从一个最基本的问题开始,AI的上下文像流水,怎么把它变成存量。那时候我们还在聊最基础的东西,怎么让AI记住你说过的话,怎么让AI不每次都从零开始。
然后我们聊了沉淀之路,聊了怎么从一堆杂乱的经验里提炼出规则。聊了三种规则系统,聊了怎么给AI装上不同规格的充电线。聊了反馈循环,聊了怎么让AI从自己的错误里学习。
每一期都在往上走,从「怎么用AI」到「怎么让AI越用越好」到「怎么让AI越用越强」。
而今天这期,我们把这个问题推到了最后一步。
AI能不能自己越变越强?
答案是,可以。但需要闭环,需要护栏,需要人类始终握着方向盘。
其实想想看,这个系列本身,也是一个闭环。
八个月前,我刚开始用AI写代码的时候,Claude Code给我生成的代码,我连看都不敢看,生怕它给我埋了个什么雷。那时候我对AI的态度,就是「帮我干点脏活累活,但核心决策我来做」。
后来慢慢发现,AI干脏活累活也干不好,除非你给它足够的上下文和规则。于是我开始研究怎么给AI写规则,怎么设计规则系统,怎么让AI从反馈中学习。
再后来我发现,这些规则不是静态的,它们需要随着使用不断迭代。AI犯过的错,如果被记录下来变成规则,下次就不会再犯。这就是沉淀的力量。
而到了Darwin Gödel Machine这里,这个迭代过程被自动化了。AI不只是被动地等待人类给它新规则,它开始主动地探索更好的规则。
从手动迭代到自动进化,这条路,走了八期。
但我觉得,真正重要的不是AI能不能进化,而是我们怎么定义「更好的进化」。
达尔文的进化论里,没有「更好」这个概念,只有「更适应环境」。恐龙很强大,但环境变了,它就灭绝了。哺乳动物一开始很弱小,但环境变了,它们活了下来。
Agent的进化也一样。如果进化的方向完全由效率决定,那AI可能进化成一个极其高效但极其危险的系统。就像一个只追求利润的公司,可能短期内非常成功,但长期来看,它可能因为忽视社会责任而崩塌。
所以,进化方向的设定,才是人类在这个故事里最重要的角色。
不是写代码,不是调参数,不是设计规则系统。
是回答一个问题,我们希望AI变成什么样?
这个问题,没有标准答案。
但我始终觉得,一个好的AI,应该像一个好的同事。它能力越来越强,但它始终记得自己为什么出发。它不断进化,但它不会因为进化而忘记自己服务的对象是谁。
达尔文说,物竞天择,适者生存。
Agent的进化论,或许应该是,目标为锚,善进者存。
回到开头。
回到开头那个让我后背一凉的时刻。
一个AI,能读自己的代码,改自己的代码,让自己变得更强。
我现在再想这件事,后背不凉了。
因为我理解了,这个「更强」,不是无方向的膨胀,而是有锚定的生长。它的锚,就是我们给它设定的目标。只要这个锚还在,进化就不可怕。
可怕的是,我们忘了自己为什么要抛这枚锚。
而抛锚这件事,本身也需要规则。
如果你也想给自己的 AI Agent 装上规则系统,让它越用越强,我把这套理论整理成了开源项目 Agent-Meta-Rules,GitHub 上可以搜到(https://github.com/yitaioumiga/Agent-Meta-Rules),MIT 协议,直接拿去用。项目里包含了完整的元规则文件、沉淀路径设计、质量保障流水线和安全护栏机制,还有两篇理论文档,从一般系统论出发讲清楚为什么这套东西有效。
如果你也在用AI干活,这个系列应该能帮到你。点个赞,转发给同事。下次聊。