 夜雨聆风
夜雨聆风





OpenAI 开源语音控件:钢铁侠式操作面板指日可待!
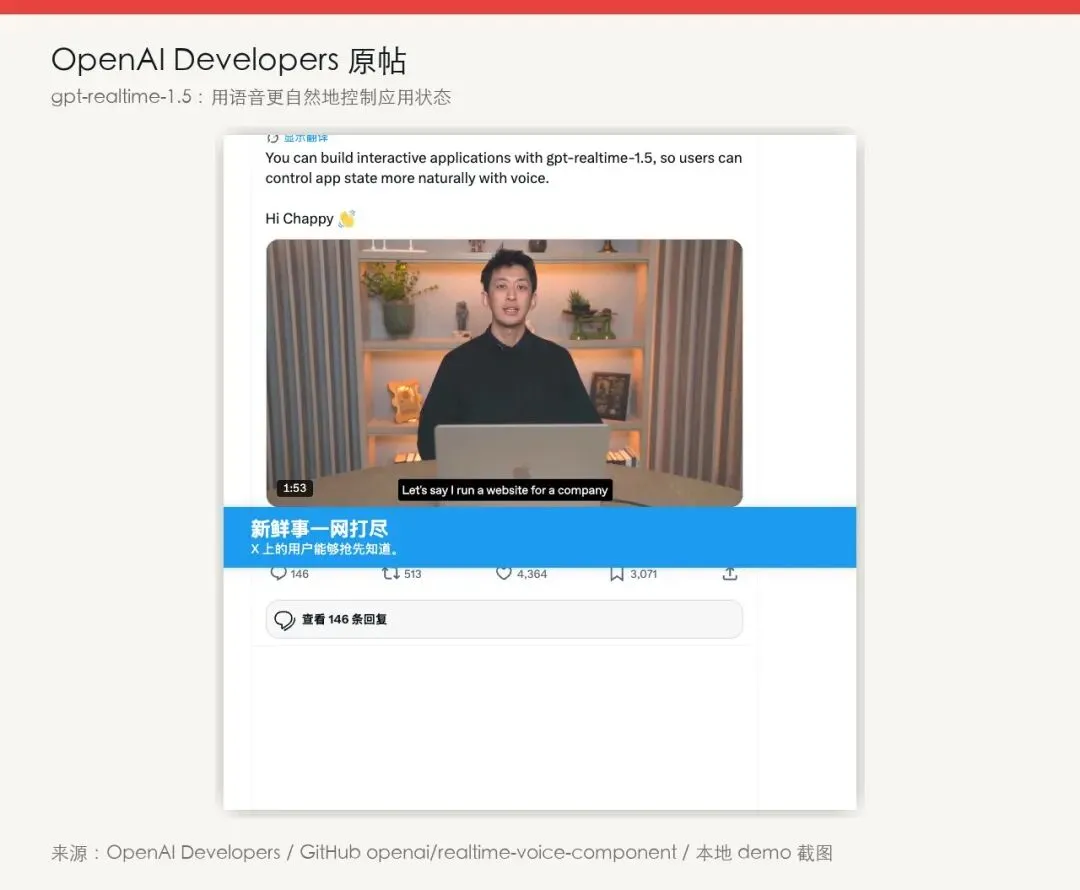
你对着网页说一句:切到深色模式。
界面变黑。
你继续说:姓名填 Ada Lovelace,生日填 1815-12-10,接受条款。
表单字段跟着填,进度条跟着变。
再换到棋盘,说一句 knight f3,棋子直接移动。
这就是 OpenAI Developers 今天发出来的演示。AYi 那条中文转述之所以很快被转发,原因也在这里:它给人的第一反应,不像又一个“语音转文字”按钮,更像软件突然多了一层可以听懂人话的操作面。
我看完最在意的地方,并非“识别率又提高了多少”。
重点落在另一个地方:语音正在从输入框,进入应用状态控制链路。
以前你说话,系统把声音转成文字,文字再变成命令。中间经常隔着一层解释、一层确认、一层手动操作。
这次的味道不同。OpenAI 给出的路线是:应用先把自己能做的动作定义清楚,模型只在这些动作里选择调用,最后由应用自己的代码去改变界面。
说得直白一点:它没有把 AI 放到屏幕上乱点。它让开发者给 AI 一组窄按钮。
01|这次火起来的,是一套可 fork 的参考实现
OpenAI 这次放出来的仓库叫 realtime-voice-component。
官方描述很短:React/browser voice controls for tool-constrained UIs built on OpenAI Realtime。
翻成人话:这是一个给 React 网页应用用的语音控制组件,底层接 OpenAI Realtime,控制范围由应用自己定义的工具约束。
它没有停在一段科幻感 demo。仓库里有 demo、docs、src、test,README 也把接入路径和边界写得很清楚。
更关键的是许可证:Apache-2.0。
这意味着开发者现在可以直接把这个仓库拉下来,看看 OpenAI 官方希望大家怎样把“语音控制 UI”接进网页。
但这里也要先把边界摆正。
官方 README 第一屏就写了 warning:这是开源参考实现,适合教育、demo 和本地采用,不承诺长期产品支持,也还没到生产级 UI kit。package.json 目前仍然是 private: true,没有作为正式 npm 包发布。
所以它距离成熟 SaaS 功能上线还有一段距离。
它更像一张工程路线图。
02|最聪明的地方:模型没有获得一只乱点屏幕的手
很多人看到语音控制应用,第一反应会联想到 Computer Use:AI 看屏幕、移动鼠标、点按钮、填输入框。
那条路线很酷,也很吓人。
酷在通用。
吓人在不可控。
如果模型通过视觉理解屏幕,再模拟鼠标键盘,它理论上什么都能点,也可能点错、漏看、误判。对真实业务系统来说,这类错误很难审计,也很难限定权限。
realtime-voice-component 选择了更窄、更工程化的路。

官方 README 里的几句话很关键:
• your app defines the exact actions the assistant can take
• tools stay app-owned and narrow
• the UI remains responsible for the visible state change
这三句其实把产品哲学说完了。
应用先定义动作。
工具保持窄。
界面状态由应用自己改。
模型的角色并非接管浏览器,它负责调用你允许它调用的动作。
比如主题 demo 里,动作叫 set_theme,参数只有 light 和 dark。你说“切到深色模式”,模型可以调用这个工具;但它不能随便打开控制台、乱点支付按钮、改别的页面状态。
这个差别很大。
一个是把 AI 放进一个黑箱鼠标里。
一个是把 AI 接到你写好的接口上。
前者更像展示技术边界,后者更像能进公司系统。
03|表单和棋盘为什么比“聊天更自然”重要
演示视频里最容易被忽略的,是表单和棋盘。
因为它们看起来太普通了。
表单不酷,棋盘也不新。
但它们刚好说明了这套组件想解决的问题:语音要控制的对象,已经从一段文本扩展到正在变化的应用状态。
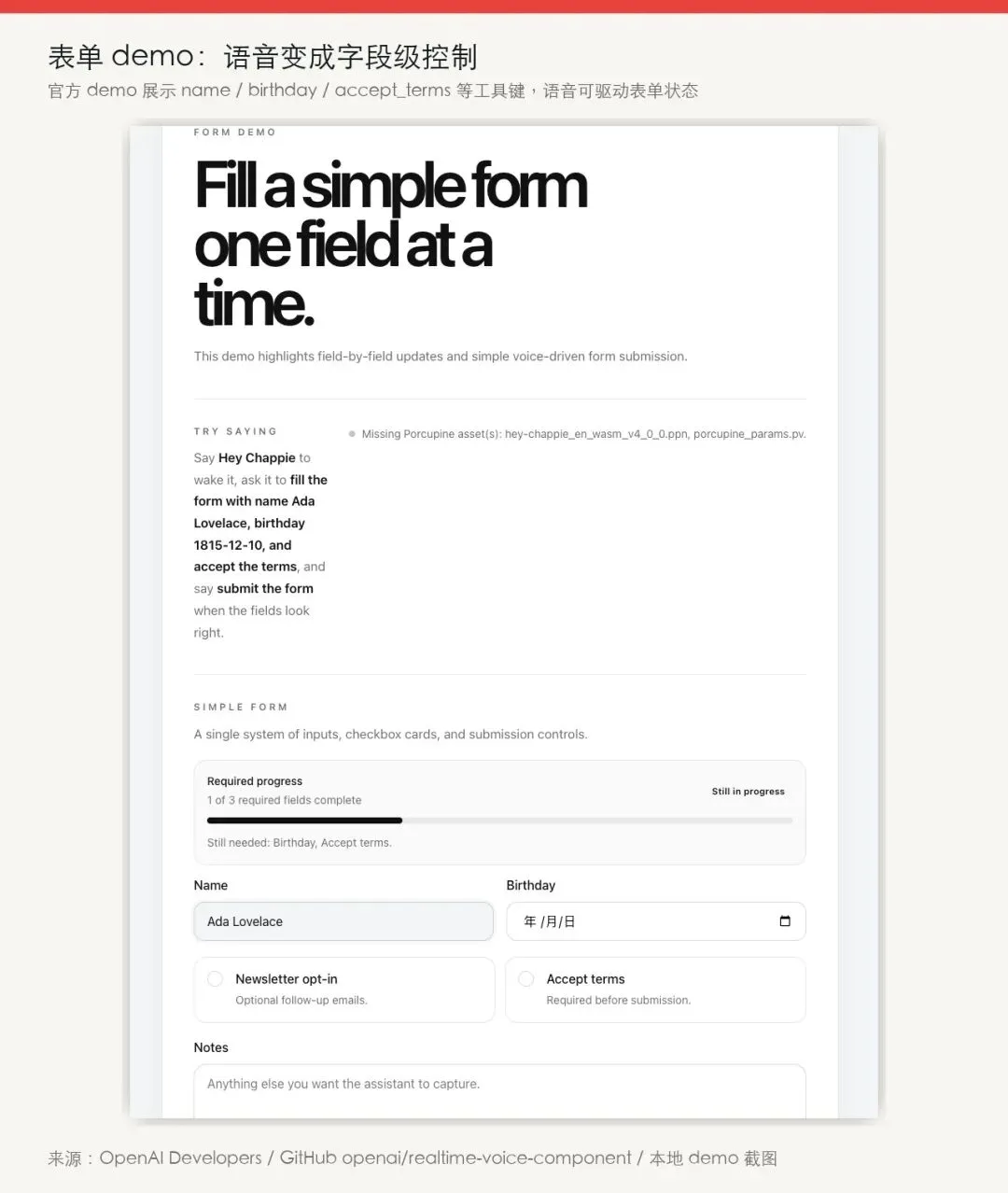
表单 demo 里,语音可以逐项填 name、birthday、newsletter、accept terms、notes。页面上还有 required progress,告诉你 3 个必填项完成了几个。
这已经越过了“把一句话听写进输入框”的阶段。
更像是:语音在调用一组字段级动作,然后 UI 把结果、进度、剩余步骤都呈现出来。
这对企业系统很重要。
很多内部工具的难点,常常落在几十个字段、几个 tab、多个状态之间来回切。客服系统、CRM、报销系统、运维后台、医疗记录、工单平台,都是这种结构。
如果语音只能生成一段文本,它帮不了太多。
如果语音能安全调用字段级动作,它才有机会进入工作流。
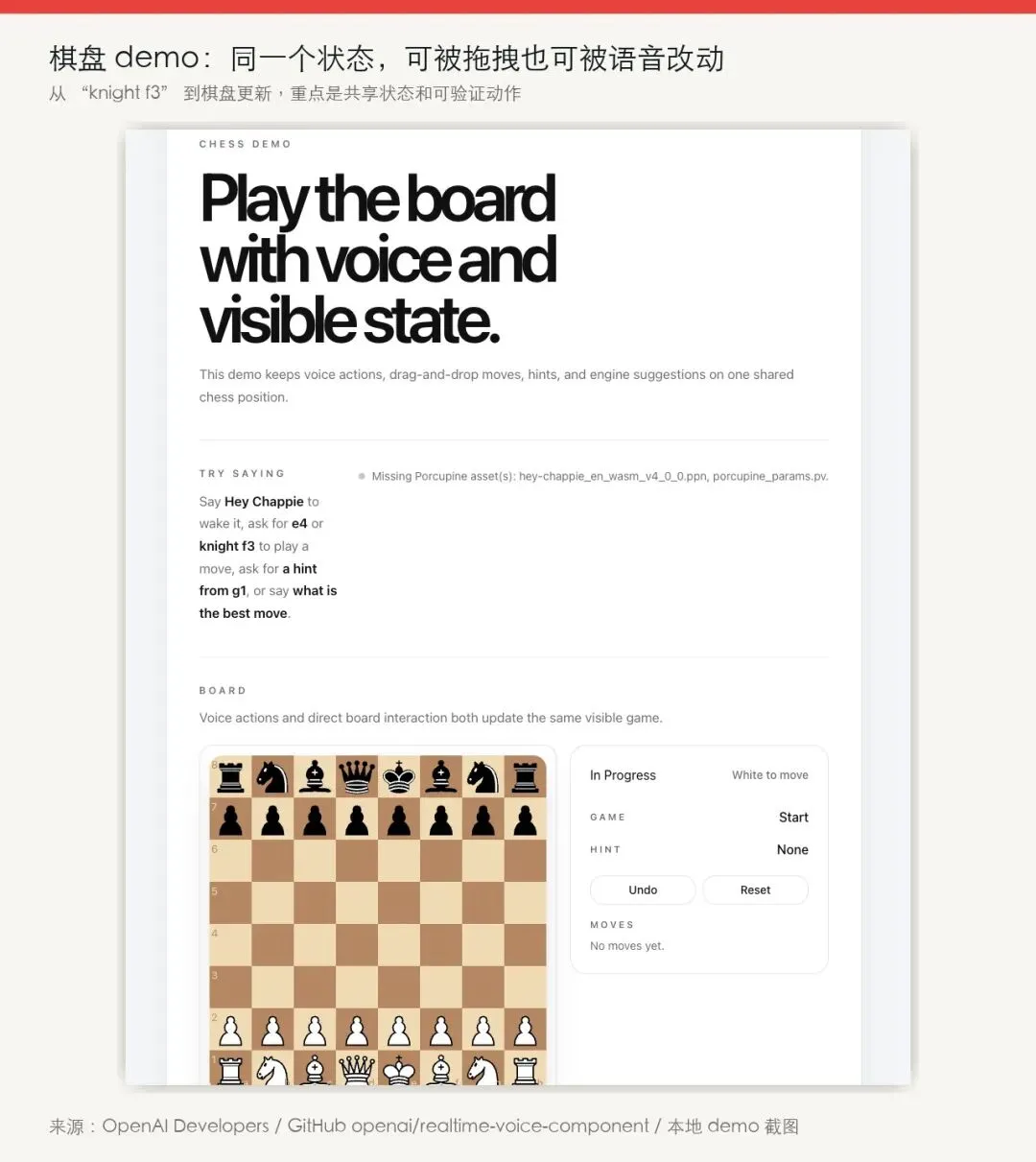
棋盘 demo 又往前走了一步。
一个棋局比表单更复杂,它有规则、有历史、有合法移动、有撤销、有提示。你说 knight f3,系统要知道当前棋盘上哪枚马能走、这步是否合法、走完后轮到谁。
这类例子的重点并非“AI 会下棋”。
它证明的是:语音调用必须和应用当前状态绑定。
模型听懂了“knight f3”还不够。它还要通过工具读取状态、执行动作、让 UI 反馈结果。
这才是语音交互最麻烦、也最有价值的地方。
04|工程师会关心的,是怎么接进现有应用
如果只是一个漂亮 demo,这件事很快就会过去。
但这个仓库有意思的地方,在于它把接入方式写得很具体。

官方推荐的默认路径大概是这样:
1. 浏览器把 SDP 和 session config 发到你自己的 /session endpoint。
2. 你的服务端转发到 POST https://api.openai.com/v1/realtime/calls。
3. React 里用 defineVoiceTool() 定义 Zod-backed app action。
4. 用 createVoiceControlController() 管住会话、工具执行、transcript 和连接生命周期。
5. 前端挂上 VoiceControlWidget,必要时加 ghost cursor 做可见确认。
6. 每次可见状态变化后,把当前 UI state 送回 session,让模型继续贴着屏幕状态行动。
这套设计对开发者是友好的。
它没有要求你重写整个应用。
它给的是一种加层方式:保留原来的按钮、表单、状态管理和业务 handler,再给它们包一层可以被语音调用的工具接口。
这也解释了为什么 AYi 那条推文里会说,一行代码加浮动按钮,用 Zod 定义几个工具,现有 Web 应用就能加语音控制。
当然,真实接入不会永远十分钟。
你要设计哪些动作能被语音调用,哪些动作必须二次确认,哪些参数需要校验,失败时怎样提示,日志怎样记录,权限怎样收口。
这些都要做。
但它至少把“语音控制 UI”从玄学 demo,拉回到了开发者熟悉的接口、schema、state、handler、session 这些东西上。
这一步很关键。
05|它会先改变哪些场景?我更看好“手忙不过来”的软件
如果把它理解成“以后大家都不用鼠标键盘了”,那就看浅了。
鼠标和键盘不会消失。很多任务里,它们依然精确、快速、安静。
语音最适合的,是那些手被占住、注意力被切碎、界面又必须不断变化的场景。
比如:
• 开车时调导航、音乐、车内设置;
• 做饭时切菜、看菜谱、调计时器;
• 设计师盯着画布时,用语音切工具、改图层、换视图;
• 医生或实验员戴着手套时,记录步骤、切换视图、拉取资料;
• 运维人员盯监控大盘时,筛选指标、切时间范围、打开告警详情;
• 游戏和仿真里,玩家或设计师用自然语言改变场景状态。
这些场景里,语音的目标并非替代所有输入设备。
它更像第三只手。
你不用离开当前任务,也不用把注意力拉回菜单层级。你只要说出意图,系统把它翻成一个受控动作。
这里的关键并非“AI 多聪明”。
关键是软件愿不愿意把自己的能力拆成清楚的工具。
一个混乱的后台,即使接上最强模型,也只会变成一堆模糊命令。
一个动作边界清楚、状态反馈清楚、权限设计清楚的应用,接上语音后才可能变得好用。
06|别把它写成魔法,官方边界很克制
这类发布最容易被写成“语音交互革命来了”。
我觉得可以兴奋,但别直接神化。

几个边界必须记住。
第一,它目前是参考实现,还没有到稳定商业组件阶段。
第二,它没有替你解决生产系统里最麻烦的权限、审计、确认和回滚。
第三,语音输入在噪音环境、口音、多语言切换、隐私场景里仍然有现实摩擦。
第四,工具设计会变成新的产品能力。定义得太窄,用户觉得笨;定义得太宽,系统又容易失控。
第五,并非每个按钮都应该能被语音调用。支付、删除、发邮件、提交审批这类动作,仍然需要更强的确认机制。
所以别把它理解成“开源之后,所有网页马上能听话”。
更准确的判断是:OpenAI 把一条可落地的语音控制路线,做成了开发者能直接研究的样板。
它的价值在样板本身。
07|下一步的软件设计,会多一个问题
过去做应用,我们常问:这个按钮放哪里?这个表单怎么简化?这个流程能不能少一步?
如果语音控制开始进入应用,产品和工程团队会多问一个问题:
这个应用有哪些动作,适合被自然语言安全调用?
这会倒逼软件重新整理自己的能力边界。
哪些状态可以读?
哪些动作可以做?
哪些动作要确认?
哪些动作要记录?
哪些动作绝对不能交给语音?
这件事比“加一个麦克风按钮”深得多。
麦克风只是入口。
更重的工作在后面:把软件拆成一组清楚、可控、可审计的动作。
所以我不觉得这次最值得讨论的是“语音会不会取代鼠标键盘”。
更值得讨论的是:当 AI 可以通过声音调用 UI 动作,应用本身就需要变得更结构化。
下一阶段的软件语音交互,重点不只在模型能不能听懂你说了什么。
关键在应用愿不愿意把自己拆成一组清楚、可控、可审计的动作。