 夜雨聆风
夜雨聆风





AI 硬件的终局:光子时代如何打破算力瓶颈?
AI 时代颠覆了我们的认知
几年前,科技界的共识非常明确:软件为王,硬件只是商品。这个观点在当时非常有说服力,因为云计算正处于爆发期,人们只需从 AWS 或 Google 租用计算时间。大家认为真正的价值在于算法、应用和平台,而不是运行它们的物理机器。
但 ChatGPT 的出现改变了一切。
随后,DeepSeek、Gemini 和 Claude 等大语言模型(LLM)紧随其后。现在,人们意识到训练和运行 LLM 已成为最高优先级,更重要的是,这一过程对功耗、内存和原始算力的需求极其惊人。而这些需求的落脚点全部在硬件上。AI 模型越聪明,需要处理的数据就越多,数据传输的速度就必须越快。突然之间,硬件不再是廉价的商品,而成了最大的瓶颈。
市场迅速做出了反应。NVIDIA 在 2024 年超越微软和苹果,成为全球市值最高的公司。埃隆·马斯克宣布在田纳西州孟菲斯建立一个巨大的 AI 数据中心——“计算超级工厂”,据报道将部署 10 万块 NVIDIA H100 GPU。Meta、微软、谷歌和亚马逊在 2025 年一年的 AI 基础设施预算合计超过 3000 亿美元。这些不是对软件的投资,而是对硬件的豪赌。
那么,瓶颈究竟在哪里?对于 AI 模型而言,数据处理量正在大幅增加。数据处理的逻辑是:内存向处理器(GPU 和 CPU)提供数据,处理器进行计算。现代 GPU 的计算能力已经足够强大,但问题在于,GPU 浪费了大量时间在等待内存等设备传输数据。换句话说,瓶颈在于通信——设备之间数据传输的速度。
这种情况还将进一步恶化。随着 AI 模型规模的扩大和集群的增加,数据传输的距离(芯片到芯片、GPU 到 GPU、机架到机架)不断增加。连接的 GPU 越多,每个 GPU 等待数据的时间就越长。而正如后文将讨论的,铜线在 AI 所要求的速度下,无法支撑这种传输距离。而解决这个问题的答案就是:光。
背景简述:晶体管的故事
要理解为什么这至关重要,首先需要了解计算速度是如何提升的。简单来说:晶体管变得更小了。
在每个处理器(CPU 和 GPU)内部,有数十亿个被称为晶体管的微小开关。晶体管通过在“开”和“关”状态之间极速切换来执行计算(计算基于二进制语言,“开”和“关”分别代表 1 和 0)。晶体管的切换速度由 RC 时间(电阻 R 和电容 C 的乘积)决定。晶体管越小,沟道长度越短(R 降低)且面积越小(C 降低),RC 乘积越小,切换速度就越快。
这就是为什么三星、SK 海力士、台积电和英特尔等领先的半导体公司花费数十年时间及数千亿美元,致力于晶体管的极致微缩。从 20 世纪 70 年代的 10 微米,到 2017 年的 10 纳米,再到今天的 3 纳米,以及即将到来的 2 纳米。每一代微缩都意味着芯片速度更快、能效更高,且能在相同面积内集成更多晶体管。这一趋势由戈登·摩尔在 1965 年预测,即著名的“摩尔定律”,它驱动了过去 60 年的计算革命。
但问题在于:缩小晶体管解决了“计算”问题,这正是现代 GPU 如此强大的原因。然而,它并没有解决“通信”问题。晶体管的进步与数据传输速度实际上是两个独立的问题。在 AI 时代,通信才是主要的瓶颈。
现代 AI 的两大核心瓶颈:内存与互连
在训练 AI 模型时,GPU 需要不断地从内存中获取数据、进行计算、将结果发送到其他地方,然后再次获取数据。这意味着 GPU 现在的大量时间被浪费在等待数据到达上。只有在数据供应足够快的情况下,GPU 的原始算力才能得到充分发挥。这产生了两种不同的瓶颈:GPU 与内存之间的通信,以及设备与设备之间(如 GPU 到 GPU、芯片到芯片、机架到机架)的通信。前者的传输距离极短,而后者则长得多。
瓶颈 #1:内存带宽与 HBM 革命
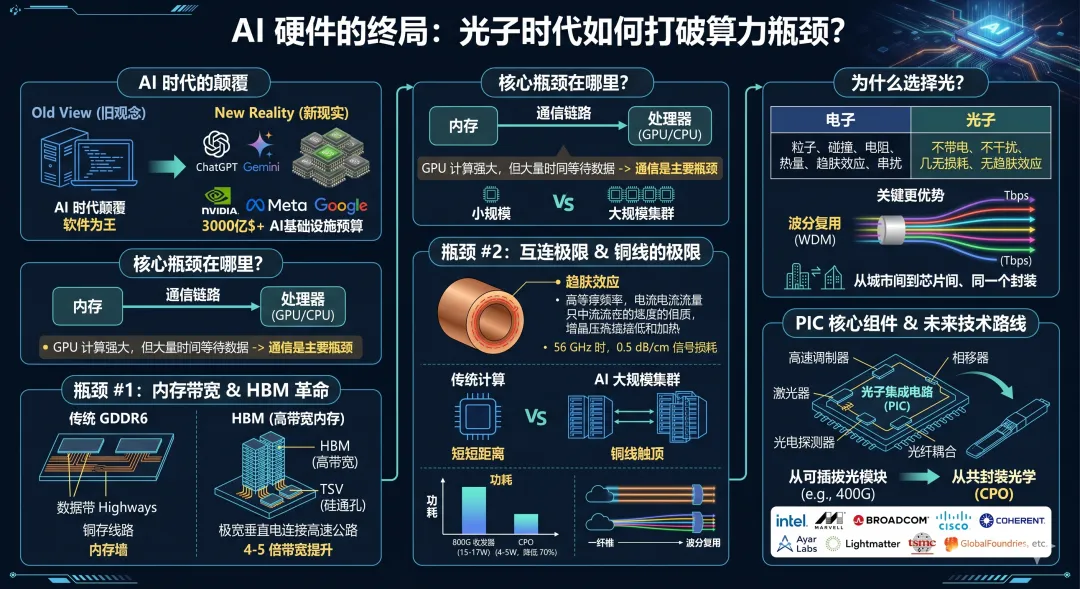
第一个瓶颈存在于 GPU 及其内存之间。多年来,内存的速度一直无法跟上 GPU 的需求,这个差距被称为“内存墙”(Memory Wall),自 20 世纪 90 年代以来一直是计算机架构中的已知问题。
近年来出现且被广泛采用的解决方案是高带宽内存(HBM)。为了理解其原理,可以将 GPU 与内存之间的数据连接想象成一条高速公路。传统的内存(如 GDDR6)位于主板的较远位置,通过一条相对狭窄的高速公路(200-400 条铜线宽)与 GPU 连接。而 HBM 采取了完全不同的方式:(1) 将多个内存芯片像摩天大楼一样垂直堆叠,(2) 将整个堆栈直接放置在与 GPU 相同的封装内。这种近距离布局允许在 GPU 和内存堆栈之间形成数千个微小的垂直电连接,称为硅通孔(TSV),从而构建出一条极宽的高速公路(最高 4096 条线宽)。线宽增加意味着更多数据可以并行传输,从而实现更高的带宽(带宽与传输速度成正比)。
效果非常显著。NVIDIA 的 H100 GPU 集成了 80 GB 的 HBM3,内存带宽达到 3.35 TB/s,约为传统 GDDR6 内存的 4 到 5 倍。虽然 HBM 没有完全消除内存墙,但它为行业赢得了重要的喘息空间。
瓶颈 #2:互连——铜线的极限
第二个瓶颈是本文系列讨论的核心:芯片到芯片、设备到设备,甚至是机架到机架的通信。机架是指数据中心中存放服务器和芯片的物理机柜。随着 AI 集群的扩大,芯片不仅需要在单个机架内通信,还需要在多个机架之间通信。成千上万个 GPU 需要协同工作,不断交换数据。这就是互连问题。
几十年来,这些互连主要依赖于印刷电路板(PCB)上的铜线走线或服务器之间的铜缆。铜线曾服务良好,但在 AI 时代,所需的数据速度已经超过了铜线的承载极限。原因如下:
问题 1:铜线不适合高速、远距离通信 根本问题在于一种被称为“趋肤效应”(Skin Effect)的现象。在高频(信号速度)下,电流不再均匀分布在铜线的整个截面上,而是越来越集中在表面(即“皮肤”)。随着频率增加,有效导电面积缩小,电阻上升,信号功率被吸收并转化为热量。频率越高,这种效应越严重。
具体来看:在 56 GHz 的频率下,标准铜线每厘米约损失 10% 的信号(0.5 dB/cm)。服务器板上的芯片间连接跨度为 20 到 50 厘米,这意味着信号只剩下 10% 到 0.3%;而机架间的连接跨度为 1 到 5 米,信号几乎无法传输。在这种频率下,信号在传输几十厘米后就会弱到需要昂贵且高功耗的放大和均衡电路才能恢复。
问题 2:传统计算不需要长距离、高频通信 过去这并不是问题,因为传统计算主要涉及单块主板上、距离仅几厘米的 CPU、GPU 和内存之间的快速通信。铜线在短距离、少量芯片通信且频率可控的情况下表现完美。
AI 改变了这一切。训练大语言模型需要部署在众多服务器和机架上的数十万个 GPU 持续交换数据。距离更长,通信芯片数量更多,所需速度更高。铜线的设计初衷并非为了应对这种场景。
此外还有功耗问题。被铜线吸收的信号能量会变成热量。现代数据中心消耗的电力惊人,其中很大一部分用于在铜线上传输数据而非计算。一个先进的 800G 可插拔光模块每端口功耗约为 15-17 瓦。而本文稍后将讨论的共封装光学(CPO)方案可将其降至 4-5 瓦,降低了约 70%。在拥有数万个端口的大型 AI 集群中,这种差距意味着数兆瓦的电力消耗。
因此,铜线在现代 AI 基础设施的需求面前已经触顶。行业需要一种根本性的改变,那就是“光”。
光学互连:为什么“光”是答案?
既然铜线难以支撑,替代方案是什么?行业正趋向于使用光——通过光脉冲而非电流来传输数据的光学互连。
为什么选择光?直观来看:电子是物理粒子,在导体中流动时会与晶格中的原子碰撞,损失能量并产生热量(即电阻)。在高频下,它们会堆积在表面(趋肤效应),且与相邻导线中的电子产生电磁干扰(串扰)。速度越快,这些副作用越严重。
而光子(光的粒子)的行为截然不同。光子不带电,因此不会相互干扰,也不会与它们经过的波导材料原子发生作用(假设材料是透明的)。光子在精心设计的光学波导或光纤中传输时,几乎没有电阻损耗,不产生传播热量,且与相邻光学信号之间没有串扰。无论运行频率是 1 GHz 还是 1,000 GHz,这些特性都保持不变,因为光没有“趋肤效应”。
最强大的优势在于:你可以在同一根物理波导中,利用不同波长(颜色)的光同时传输多个完全独立的并行数据流。这被称为波分复用(WDM),它让单根光纤能够承载每秒太比特(Tbps)级别的数据。这是铜线永远无法实现的。
正因如此,光纤几十年来一直是全球互联网和电信网络的骨干:低损耗(低至 0.17 dB/km)、高带宽且免疫电磁干扰。最近的变化在于,光子技术正被微缩到半导体芯片上(称为光子集成电路,PIC),使得光学互连不仅能用于城市之间,还能用于同一电路板上的芯片之间,甚至在同一个封装内部。
这就是本系列文章的主题:将光引入芯片的技术、科学及其背后的产业,以及为什么这可能是 AI 时代最重要的硬件进展。
未来路线图
在深入探讨之前,这里是对本系列将讨论的光子集成电路(PIC)核心组件的预告:
- 高速调制器(High-speed Modulators):
将激光束转化为数字数据的组件。我们将探讨硅、铌酸锂、钛酸钡、有机混合物、磷化铟和聚合物等不同技术,分析它们在速度、电压和集成度方面的权衡。 - 激光器(Lasers):
硅本身无法产生光。将激光源集成到硅芯片上是该领域的核心挑战之一,目前已出现多种巧妙的解决方案。 - 相移器(Phase Shifters):
精确控制光相位的组件。 - 光电探测器(Photodetectors):
接收端组件,将光脉冲还原为电信号。 - 光纤到芯片耦合(Fiber-to-Chip Coupling):
如何将光引导进入波导仅有数百纳米宽的芯片?这是一个极具挑战的工程问题。 - 光收发机与共封装光学(CPO):
完整的系统集成。从目前数据中心使用的 400G 可插拔模块,到将定义下一代 AI 网络硬件的共封装光学(CPO)。
在此过程中,我们将把技术与实际构建它的公司联系起来,包括 Intel, Marvell, Broadcom, Cisco, Coherent, Ayar Labs, Lightmatter, HyperLight, TSMC, GlobalFoundries,以及一批你可能还未听说但应当关注的初创公司。
让我们从基础开始。