 夜雨聆风
夜雨聆风





你的笔记软件,正在成为第二个垃圾堆,用Karpathy 的AI 知识库LLM Wiki,把碎片信息变成认知资产
— 创业者如何用 LLM Wiki 把碎片信息变成认知资产 —
太多初次创业者的知识管理状态:
Notion 里 500 个未整理的页面。
Obsidian 里密密麻麻的双链,打开了不知道从哪里找。
浏览器开了 80 个 tabs,收藏夹里 2000 条链接,上一次打开是半年前。
有增长。◆ 01
01
为什么你的知识管理系统在骗你?
Andrej Karpathy——OpenAI 联合创始人之一,特斯拉前 AI 负责人——曾提出一个他自己使用的知识管理框架,叫 LLM Wiki。
当我第一次了解这个系统时,直接改变了我对”笔记”这件事的认知。
大多数人对知识管理的理解是:记录更多东西。但 Karpathy 的答案完全相反——
真正有价值的,不是”记了多少”,而是你有没有能力把混乱的信息,变成结构化的认知。
你每天面对的信息量是普通人的数倍:行业动态、竞品分析、技术文章、播客、投资人反馈、用户访谈……输入量极大,但如果没有一套机制把这些东西转化成判断力,再多的信息也只是噪音。
02
LLM Wiki 解决了哪三个核心问题?
📥 信息太多,但没有结构
看了 100 个视频、收藏了无数文章,脑子里却是碎片。
收藏≠懂了,两者之间差了一整个世界。
→ 把信息变成可导航的知识地图
♻️ AI 输出很多,但不可复用
今天和 Claude 聊了一个很深刻的问题,随着聊天内容增加难以检索复用,明天还得重新解释背景,重新问一遍。每次对话成果难以复利,都在归零。
→ 把 AI 输出沉淀成长期认知资产
🔗 知识无法”连接”
你知道很多点,但它们彼此孤立。A 和 B 之间本来有一条关键联系,但你永远想不到要把它们放在一起。
→ 核心是”链接”,而不是”记录”
03
LLM Wiki 的结构长什么样?
LLM WIKI 知识架构分为三大核心文件和三大核心操作:
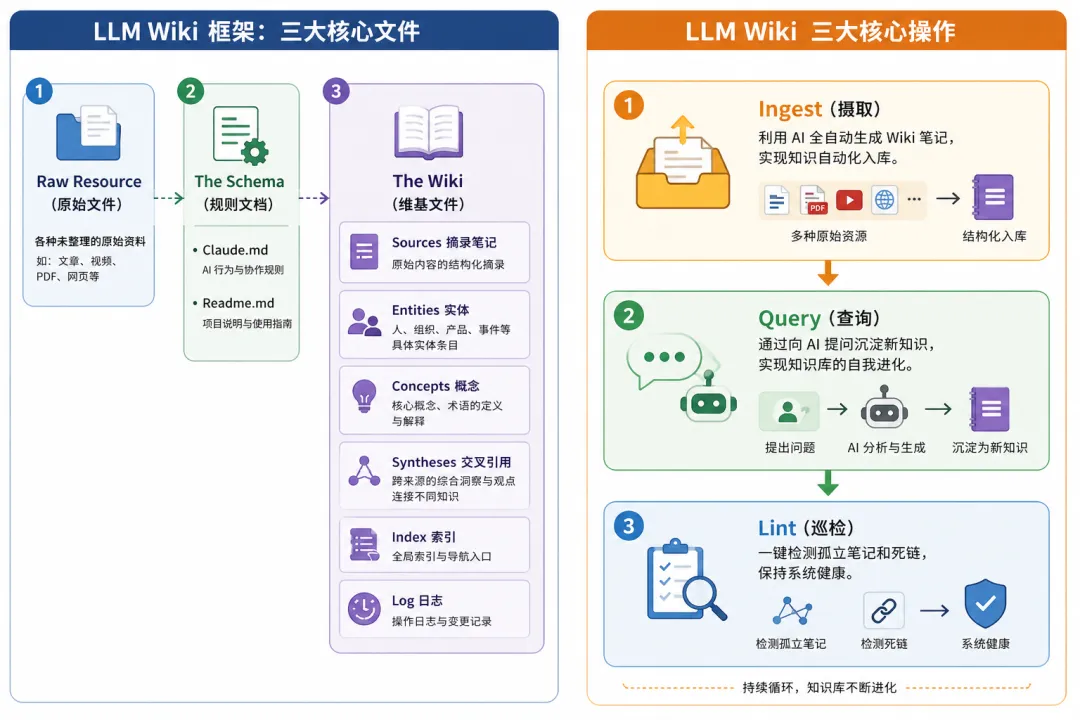
Raw:原始材料,视频 / 文章 / 播客 / 对话记录,还没思考,只是收集
The Schema:给智能体设立的运行规则。
The Wiki:
|
|
|
|
|
|
|
|
|
|
|
|
而 Index 和 Log 是让 AI 记录、读取,方便后期 Query查询的工具。
举个例子:你读了五篇关于 AI Agent 的文章(Sources)→ 抽取出”Agent”这个概念节点(Concepts)→ 整合五种视角,写下自己对 Agent 本质的综合洞察与理解(Syntheses)。这个 Syntheses,才是你的认知。
04
创业者的五个真实使用场景
场景 1 | 看行业内容不再白看
|
以前 看完播客或视频,做了一堆笔记,三天后想不起来,一年后根本找不到 |
现在 内容 → Raw → Source → 抽取 Concepts,每一条内容都沉淀进知识库 |
场景 2 | AI 对话不再消失
|
以前 和 AI 聊了一个深度问题,得到了很好的框架,关掉窗口就消失了 |
现在 有价值的 AI 对话 → 整理进 Source 或 Syntheses,成为可被引用的长期资产 |
场景 3 | 竞品研究形成体系
|
以前 零散地关注竞品,脑子里有感觉但说不清楚,每次复盘都要重新梳理 |
现在 竞品 → Entities;对比分析 → Syntheses,市场判断越来越清晰 |
场景 4 | 招聘和管理输出标准
|
以前 很多管理方法论都在创始人脑子里,新人进来只能靠口传,效率极低 |
现在 方法论沉淀进 Concepts + Syntheses,团队知识库有了共同语言 |
场景 5 | 构建 AI Agent 的长期记忆
|
以前 公司内部 AI 工具每次都要重新输入背景,没有”公司记忆”可以调用 |
现在 LLM Wiki 直接成为 AI Agent 的知识中枢,决策记录、规则沉淀全部接入 |
05
怎么开始?三步上手
第一步:先建目录结构,不要一次性完善在 Obsidian 或 Notion 里建好两个文件夹:Raw / Wiki,其中 Wiki 文件夹再建立四个子文件夹Sources / Concepts / Entities / Syntheses。不要花超过 30 分钟。结构是服务于内容的,不是目的本身。
第二步:挑一个你最近在深度研究的主题开始不要试图迁移所有旧笔记。从本周关注最多的话题入手,走完一次完整的 Raw → Source → Concepts 流程,找到手感。
第三步:用 AI 加速整理,但 Syntheses 必须自己写用 Claude 或 GPT 帮你把原始内容整理成 Source 格式,(编写The Schema,即智能体运行规则,是关键难点所在,后续我会写笔记更新具体操作)提取关键概念。但 Syntheses——你自己的判断——一定要亲手写。这是整个系统价值的核心所在。
LLM Wiki 的本质,不是记录知识,而是把信息 → 结构 → 认知变成一种可以持续运转的系统。
最后
⚠ 系统落地
LLM Wiki 很强大,但它需要你真正坐下来思考,而不只是粘贴和收藏。 它训练的其实是一种能力:把混乱的世界,强行整理成结构的能力。这件事本身是反人性的。但对创业者来说,这恰恰是你和大多数人拉开差距的地方。真正的认知优势,从来不来自”看了更多内容”,而来自”比别人更清楚地知道自己在想什么”。
LLM Wiki的概念不难理解,难的是将它搭建起来,并投入长期使用、维护。下一篇,我会分享我自己是怎么解决这个问题的——怎么在不疯狂烧 tokens 的情况下,让强大的 AI 个人知识库 LLM wiki真正运转起来。