 夜雨聆风
夜雨聆风





AI 智能体为什么会忘事还有幻觉? KV 缓存记忆机制全解
目录
- 1 先说结论:记忆问题不一定是检索问题
- 2 KV 缓存到底是什么
- 3 第一种办法:只保留最近的内容
- 4 SnapKV:模型已经知道哪些 token 重要
- 5 Cache What Lasts:真正能留下来的 token
- 6 Memory Sparse Attention:从注意力层处理长期记忆
- 7 这些方法怎么比
- 8 为什么这会改变智能体记忆设计
- 9 真实系统里会出现哪些问题
- 10 结论:token 级记忆是地基,不是天花板
- 11 免责声明与参考资料
1 先说结论:记忆问题不一定是检索问题
你的 AI 智能体总是忘事,还会凭空补细节。
很多时候,这不是 RAG 没检索到,也不是外部记忆库设计得不够好。问题发生得更早:关键 token 在注意力机制和 KV 缓存里已经被挤掉了。
大多数智能体记忆问题,其实不是检索问题。出问题的地方,比检索更早。记忆在检索开始之前就已经错了。在第 4096 个 token 的时候,某个关键内容悄悄离开了缓存,却没有任何东西把它补回来。
还有一件事发生得更早,而且没有那么多人讨论:每一次模型处理 token,它都在运行注意力机制。
这个机制会默默给上下文里的每个 token 打分。有些 token 得到高注意力。有些则被忽略。当记忆空间满了,必须删掉一些东西时,低分 token 就会消失。
就这么简单。没有外部系统,没有 RAG 流程,只是模型在决定自己还要继续关注什么。
这就是 token 级记忆。它会影响后面发生的一切。
KV 缓存压缩论文,反复在数学公式讲述同一个问题,不是速度,而是模型到底被允许记住什么。这个问题听起来不像基础设施问题,更像智能体设计问题。
2 KV 缓存到底是什么
当 Transformer 处理一个句子时,它会为每个 token 计算一个 Key 向量和一个 Value 向量。这些向量会被缓存起来。下一步生成新 token 时,新 token 会在所有已经存下来的 (K, V) 对上做注意力计算,决定接下来要输出什么。缓存让模型不用在每一步都重新计算整个上下文,否则成本会高得离谱。
问题简单,而且残酷:
-
每个新 token 都会永久给缓存增加一组 (K, V) -
缓存大小会随着上下文长度线性增长 -
在大模型上跑 128k token 时,每层、每个 head 都可能吃掉数 GB 内存 -
硬件并不关心你的使用场景,它只会把内存用完

对 AI 智能体来说,这是每天都会遇到的真实问题。每一次工具调用输出、每一篇检索到的文档、每一轮推理、对话里的每一个历史回合,都会消耗这个预算。当预算填满时,就必须剪掉一些东西。
问题只是:剪掉什么?
可以把它想成手机存储空间:
-
你在旅行,一直拍照。 -
某个时刻,手机提示存储空间满了。 -
现在你只有两个选择:停止拍照,或者删掉一些东西。 -
大多数朴素系统会直接停下来。 -
聪明一点的系统会问:你到底还需要保留什么?
# 最朴素的 KV 缓存:不淘汰,只增长kv_cache = []def cache_token(key, value): kv_cache.append((key, value)) # 没有打分,没有淘汰,也没有预算检查 # 128k token 之后,这个列表会变得巨大# 推理时的内存占用print(f"cache size: {len(kv_cache)} pairs")print(f"approx memory: {len(kv_cache) * 2 * 4096 * 2 / 1e9:.2f} GB")# 在 70B 模型、128k token 场景下:光缓存就大约 64 GB3 第一种办法:只保留最近的内容
最直接的方法是 StreamingLLM。它保留最前面的几个 token,也就是所谓的注意力汇点(attention sinks,它们对模型稳定性很重要),再保留一个最近 token 的滑动窗口,中间的全都丢掉。固定预算,规则简单。
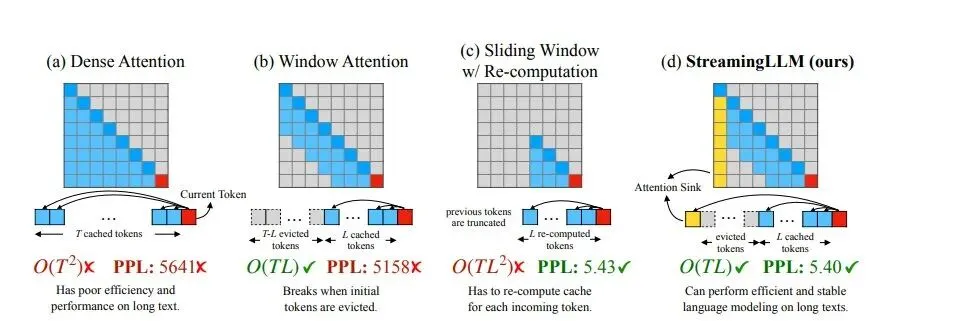
它确实有效。模型可以无限运行,不会因为缓存爆掉而崩溃。但代价是,几千个 token 之前发生的事情基本就没了。如果你的任务指令在上下文最前面,而一次工具调用结果把它挤出了窗口,模型就会忘掉自己的目标。
“最近 = 重要” 这个假设,正在智能体流程里制造大量隐性损伤。4 万个 token 之前的一条指令,可能是整个上下文里最关键的信息。
近不近,和重不重要,真的不是一回事。
4 SnapKV:模型已经知道哪些 token 重要
SnapKV 是真正改变我思考方式的方法。
它的观察非常有意思:Transformer 里的每个注意力 head,往往会在整个生成过程中持续关注同一类特定 token。
这不是随机的。
-
第 7 层的第 4 个 head,可能一直关心任务指令 token。 -
第 3 层的第 2 个 head,可能一直关心实体名称。 -
从第一个输出 token 到最后一个输出 token,这种模式都是稳定的。
SnapKV 问的是:既然这种模式稳定,为什么不直接用它来决定要保留什么?
它定义了一个观察窗口,也就是 prompt 最后一段。
在这个窗口里看哪些 token 得到了高注意力。
那些来自更早上下文、但在这里得分很高的 token,就是 heavy hitters,也就是高权重 token。保留它们,压缩剩下的内容。

它还加了一个聚类步骤。因为如果只是朴素地挑最高分 token,你会得到一些孤立碎片,却没有周围语境。一个重要短语旁边的词通常也很重要。SnapKV 用 max-pool 聚类把 heavy hitter 周围的邻居一起拉进来。所以你保留的不只是重要 token,还有足够理解它们的上下文。
结果是:
-
在 1024 个缓存槽位下,压缩率达到 92%。 -
生成速度提升 3.6 倍。 -
在 16k token 场景下,内存效率提升 8.2 倍。 -
它可以在单张 A100 上运行 380k token 上下文。 -
大海捞针测试的准确率几乎没有下降。
# 简化版 SnapKV:按每个 head 选择要保留的 tokendef snapkv_select(keys, values, obs_window_size=16, budget=1024): obs_queries = keys[-obs_window_size:] # 观察窗口 attn_scores = obs_queries @ keys[:-obs_window_size].T # (obs, seq_len) token_votes = attn_scores.sum(dim=0) # 聚合投票 # 选出 top-k heavy hitters topk_idx = token_votes.topk(budget).indices # 聚类,带上邻近 token cluster_idx = expand_with_neighbors(topk_idx, kernel_size=5) kept_keys = keys[cluster_idx] kept_values = values[cluster_idx] # 新缓存 = 被选中的前缀 + 完整观察窗口 return concat(kept_keys, keys[-obs_window_size:]), \ concat(kept_values, values[-obs_window_size:])最后那个测试对智能体最重要。它本质上是在问:如果我把一个特定事实埋在非常长的上下文深处,模型还能找到它吗?
SnapKV 的答案是可以。即使丢掉了 92% 的缓存,它仍然可以找到。这不只是更快的推理,也是约束条件下更好的工作记忆。
5 Cache What Lasts:真正能留下来的 token
SnapKV 解决了”怎么压缩”的问题。token retention 论文继续往前走,问的是:为什么有些 token 总是重要?
它发现,某些 token 会跨越所有层、所有 head,并在整个生成过程中持续获得高注意力权重。不是只在某个 head 或某一层里重要,而是全局、稳定、持续地重要。这些才是真正的 heavy hitters。
最让我印象深刻的是:模型内部本来就在计算这个分数。每一次注意力操作,都在隐式地给 token 排名。token retention 论文只是把这个排名显式化,并真正用它来做淘汰决策。
直觉上可以这样理解:
想想你上一次读完一篇很长的文档,然后别人问你里面内容的时候。你不会记得每一句话。你会记得标题、关键名字、那个让你意外的具体数字。你的大脑也对那篇文档运行了一套保留策略,只留下高信号部分。模型做的事情也类似,只不过它发生在缓存里,而不是大脑里。
-
最近不等于重要:6 万个位置之前的 token,得分可能远高于 10 个位置之前的 token -
重要性可以被测量:累积注意力权重是稳定且可靠的 -
淘汰应该使用这个分数:不是位置,不是年龄,也不是随机采样 -
预算是固定的:但填满预算的内容,应该由聪明的选择决定
def compute_token_importance(attention_weights): # attention_weights shape: (layers, heads, seq_len, seq_len) # 对所有层、所有 head、所有 query 位置求和 cumulative = attention_weights.sum(dim=(0, 1, 2)) # shape: (seq_len,) return cumulativescores = compute_token_importance(attn_weights)keep = scores.topk(budget).indicesevict = scores.topk(seq_len - budget, largest=False).indices6 Memory Sparse Attention:从注意力层处理长期记忆
Memory Sparse Attention 从另一个角度进入问题。
前面那些论文问的是:缓存里应该保留什么?MSA 问的是:在计算每个新 token 时,模型到底应该关注什么?
-
全注意力是 O(n²)。到了 1 亿 token,这根本不可行。 -
MSA 把 top-k token 选择和稀疏注意力模式结合起来。 -
它在不失去端到端可训练性的前提下,接近线性复杂度。
和智能体最相关的部分是 Memory Interleave。智能体处理的不是一篇巨大文档,而是一串跨会话的东西:工具输出、检索到的文档、上周的用户消息。
MSA 能处理不连续上下文片段之间的多跳推理。这是在注意力层解决智能体记忆问题,而不是靠外部检索流程。
-
Top-k 选择:每一步生成只关注最相关的 token -
Document-wise positional encoding:可以跨不连续记忆片段工作 -
2 张 GPU 上达到 1 亿 token 吞吐:这是一个真实系统级主张 -
在长上下文基准上超过 RAG 系统:检索像是在模型内部发生
7 这些方法怎么比
这个方向现在已经有十几篇重要论文了。它们共享同一个直觉:token 的重要性是可以判断的;差异在于怎么打分,以及怎么设置预算。
我最近也在一个 notebook 里把这些方法做了对比。
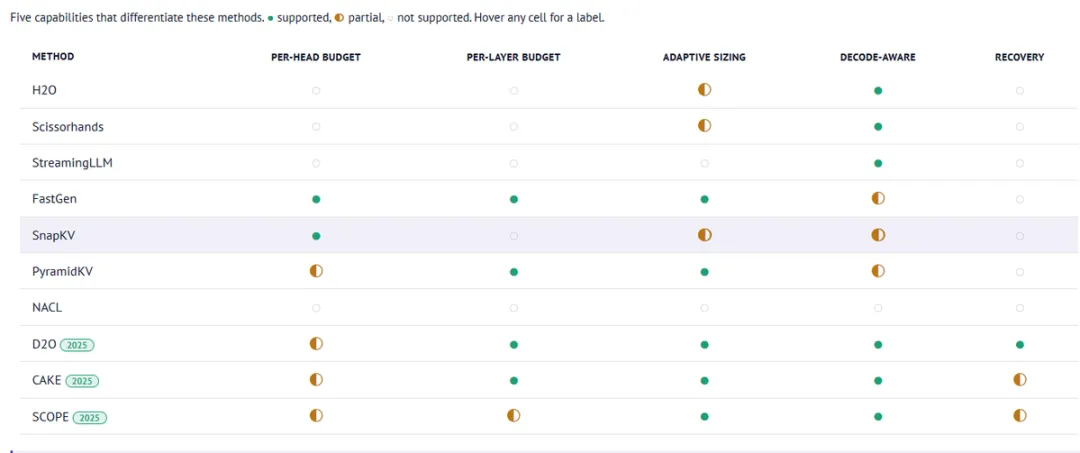
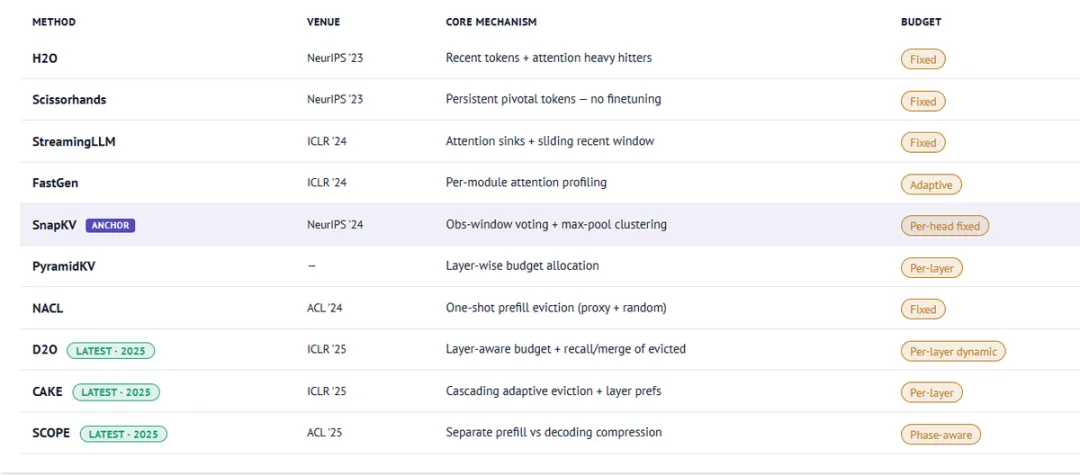
8 为什么这会改变智能体记忆设计
这才是对智能体开发者真正关键的部分。
大多数智能体记忆讨论,都是从检索层开始的:向量数据库、情景记忆、摘要策略。这些当然都真实且重要。但它们接收到的输入,来自一个更早做过选择的模型:模型必须先决定自己要关注什么。这个决策发生在 token 层,而且会影响下游的一切。
如果一个关键 token 在影响生成之前就被 KV 缓存淘汰了,它就没了。没有 RAG 流程会把它检索回来。没有记忆管理器会处理它。模型只是从来没有真正正确处理它,而输出会反映这一点。如果这个错误输出又被写入外部记忆,你就得到了从注意力层开始的错误记忆传播(False Memory Propagation,FMP),它发生在任何外部系统介入之前。

直觉上可以这样理解:
想象你在给一个 SaaS 产品做客服智能体。
-
用户进行了 2 小时的排障会话。 -
一开始,他们解释了自己的完整配置。 -
接着你跑了 15 次工具调用,看日志、配置、各种输出。 -
当你深入到第 15 个问题时,最开始那段配置上下文可能已经从缓存里被淘汰了。 -
现在模型开始给出建议,却忽略了用户一开始明确说过的限制条件。 -
错不是因为检索坏了。错是因为正确的 token 在检索变得相关之前就已经消失了。
9 真实系统里会出现哪些问题
这不是理论问题。生产环境里真的会发生这些事:
-
中间信息丢失:模型会稳定忘掉长上下文中间的信息,因为大多数淘汰策略偏爱最近 token 和最早 token -
工具输出稀释:一个很大的工具响应,会把更早的任务指令挤出有效窗口 -
RAG 注入浪费:你检索了 20 个片段,但稀疏注意力真正处理的只有少数几个,其余都浪费了上下文预算 -
系统提示失忆:系统提示里的关键约束在生成中途被淘汰,模型就会发明一个替代约束 -
FMP 从注意力层开始:一个幻觉出来的中间 token,因为模型正在积极使用它而获得高注意力分数,于是它活过淘汰,并污染后续生成链路 -
跨会话冷启动:KV 状态无法跨会话持久化,意味着每个会话都要从零开始,工作记忆只能靠检索重建,而检索永远是有损重建
10 结论:token 级记忆是地基,不是天花板
最终形态应该是这样的:Transformer 能够动态、智能地管理自己的记忆预算,而不是把所有东西都工程化到外部系统里。这不只是更好的推理系统,也是每一个智能体之上的更好记忆基底。
-
按 head 保留:不同 head 关心不同 token,淘汰策略应该尊重这一点 -
按阶段压缩:prefill 和 decoding 的记忆画像不同,应该分开处理 -
可恢复性:淘汰不一定必须是永久的 -
KV 状态持久化:会话结束时保存缓存状态,下次会话重新加载,不靠向量数据库也能获得跨 episode 连续性
能处理长周期任务的智能体,不会只是那些拥有最花哨检索流程的智能体。关键在于:模型自己能不能在长上下文里保留正确的东西,外部记忆层拿到的输入又是否足够干净、足够可用。
外部记忆层只能处理模型交给它的东西。如果 token 层已经漏掉关键约束,甚至把错误中间结论写进了后续输出,那么后面的检索、摘要、记忆管理做得越精密,错误传播得也可能越稳定。
所以,token 级记忆是地基,不是天花板。每个检索流程和记忆管理器收到的输入,都来自一个已经先决定要关注什么的模型。这个决策发生在 KV 缓存里。它不只关系到推理速度,也关系到智能体设计.