 夜雨聆风
夜雨聆风





拆解抖音爆款AI服装视频:从选品到成片,全程让AI自己干
点击上方卡片关注 不要错过精彩文章
持续更新有关Agent教程,希望能给您带来帮助
点一点上方的🔵蓝色小字关注,你的支持是我最大的动力!🙏谢谢啦!🌟”
大家好!我是唐舰长🙏
上面这个视频是我通过openclaw帮我做的,我只需要提供三张服装图和模特图,自动把素材生成好,然后保存为草稿在剪映中,我只需要点一下导出视频就可以用
这样的视频制作灵感也是我最近经常在抖音上刷到这些用AI进行服装带货的视频,热度非常好,刷到的都是爆款的账号。变现模式也非常清晰
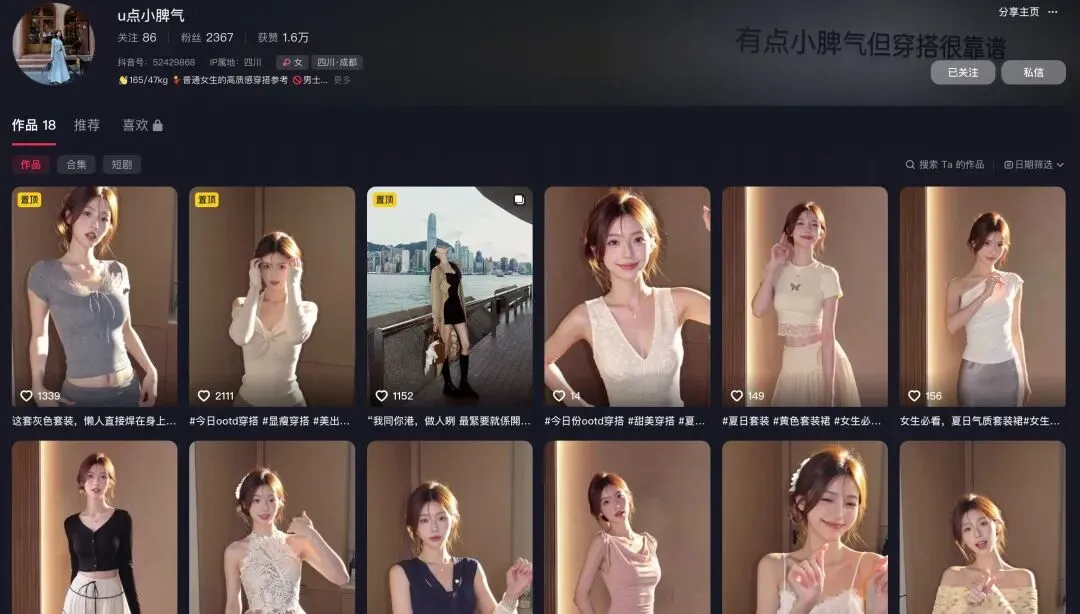
这种账号,一定粉丝后开通橱窗直接将视频中的服装放到橱窗中实现带货。但具体能否有盈利,这个还不好说
毕竟服装赛道一向比较难做,但是我们可以去感受一下这些视频的制作方式,添加一些动感的视频音乐、视频剪辑、视频模版制作,进行学习。
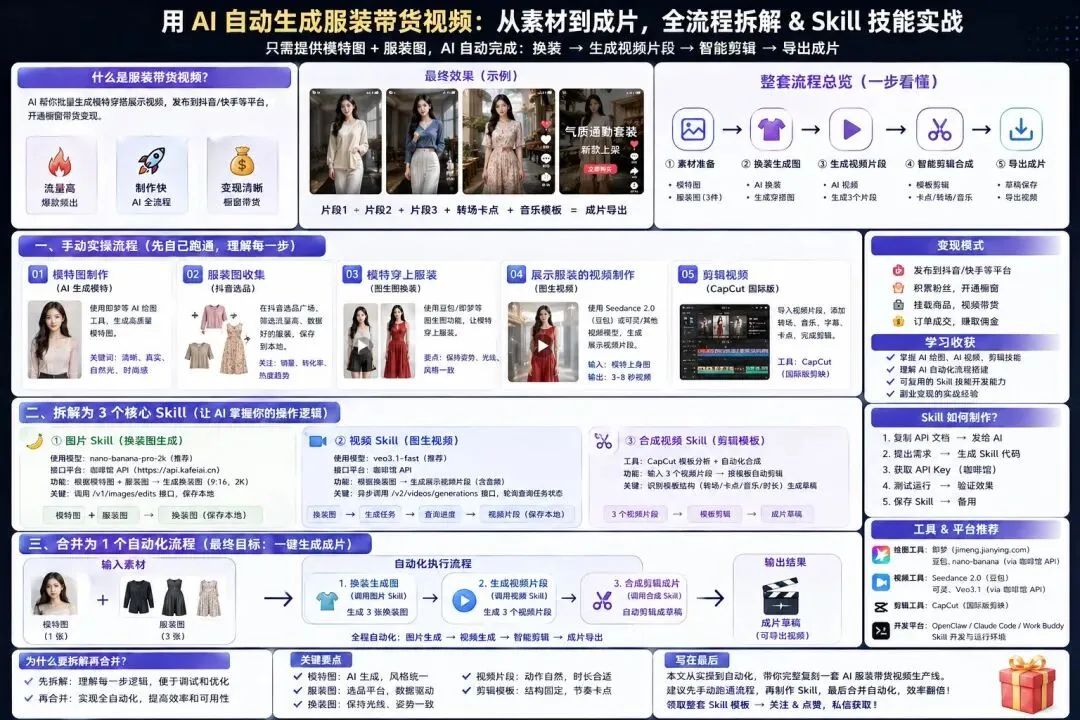
先看一下本次的文章流程图,先熟悉一下
在上一次的分享中,我给大家介绍了之前的Coze开发者——速推团队,在Coze中的插件深受很多人喜欢。现在他们把这个项目开源——变成skill,可以供小伙伴装在 openclaw、claudecode等智能体应用上进行使用
想要在openclaw、claudecode等智能体应用上进行使用就要去安装好skill,skill已经在github上开源了,感兴趣的小伙伴可以去看一下项目:
项目地址:https://github.com/xuliang2024/cutcli-cookbook如果大家觉得很实用的话,麻烦各位给速推他们点一个心心

具体项目怎么去安装到我们的电脑上,这篇文章都有讲解:
再见Coze 视频工作流!这套AI剪辑开源项目零门槛、免费、还能批量产出视频
其实像这样的服装带货视频,非常考验制作者都AI绘图、AI视频、剪辑等能力
所以用这样的一个案例去制作我们的服装带货视频,是非常不错的,既能学习AI的操作技能,还能学习Ai自动剪辑这个项目。
想要让AI自动的帮我们制作这样的视频,我们自己需要先知道是怎么一步一步实现的,先自己实操一遍,然后结合流程制作成「技能」让AI知道应该怎么做。
这些就是实操的基本流程:模特图制作——服装图收集——模特穿上服装图——展示服装的视频制作——剪辑视频
模特图制作
做这样的视频,那模特很重要,不能是真人要是AI生成的模特,但很多小伙伴可能不会写绘图的提示词
我们只需要打开即梦的网站:https://jimeng.jianying.com/ai-tool/home/
在即梦的首页的「灵感」可以看到很多生成效果很好的图片,对这些图片生成类似的同款即可
挑选一个自己喜欢的模特,进行做同款即可
服装图收集
一件好看的服装也很重要,这里用抖音的选品平台去找搜集一些不错的服装作为模特的“试穿衣服”
抖音选品平台的网址:
https://buyin.jinritemai.com/dashboard/merch-picking-utils/hot-spot?btm_ppre=a10091.b089178.c809509.d0&btm_pre=a10091.b24215.c68160.d839440_i16852609794&btm_show_id=82459a33-9cae-4b3d-807d-2298f1edf23d&pre_universal_page_params_id=&universal_page_params_id=f236df2c-8a01-4e88-b008-c23745308d4d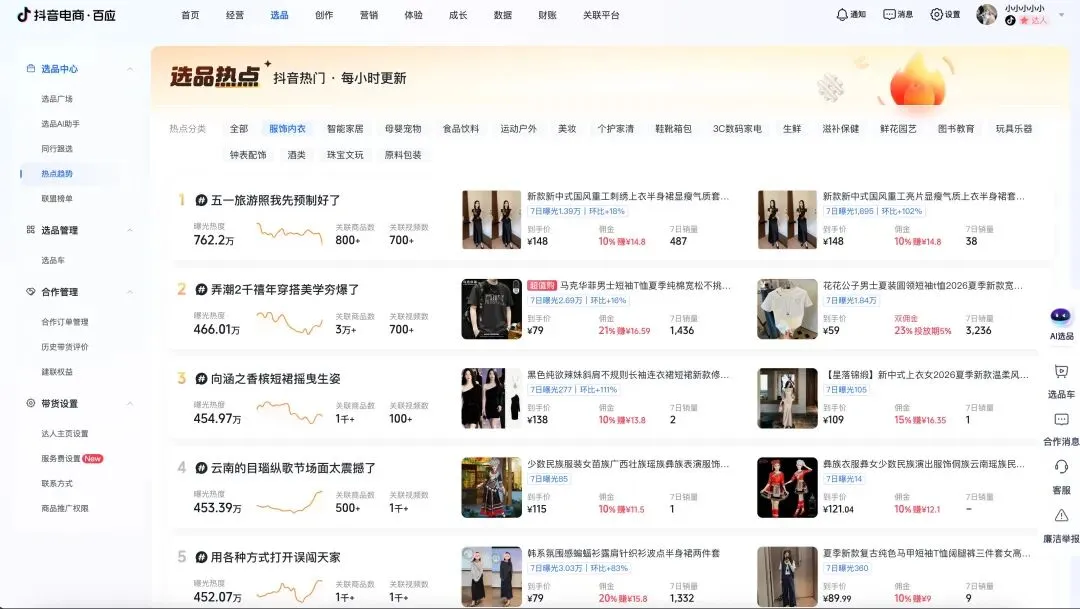
在选品广场上去找一些不错的服装,然后要找一些流量高的数据好的服装,将这些服装保存到我们的本地
模特穿上服装图
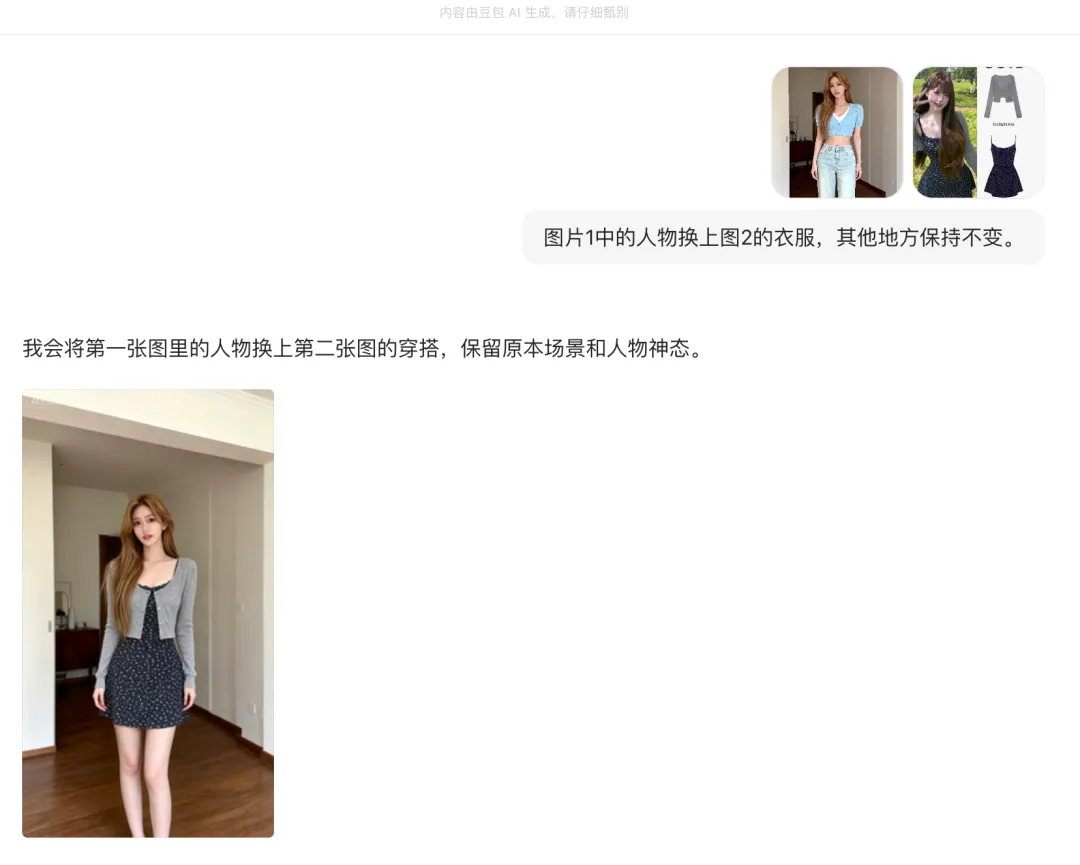
将服装图穿到模特身上,这一步就是图片+图片生成新的图片
可以先在豆包上先尝试一下,看起来效果还不错,所以让模特穿上服装图这一步很简单,没有什么提示词要学习的,AI自己可以完成细节的制作。
展示服装的视频制作
整个流程这里算是一个卡点,国内最好的用的就是Seedance 2.0(豆包最新视频模型),但是这个模型有一些限制:

模型觉得AI生成的模特是真实人脸,不支持生成视频
所以,这里的制作可以选择其他的AI视频制作平台,比如可灵去制作,但是我觉得没有必要,我们手动的目的呢,是让自己清晰的知道这些环节是怎么做出来的
我们最终还是需要把这些流程做成技能,让AI自己去生成相对应的AI视频即可(做一些接口调用)
这一步的逻辑就是:通过一张模特上身图+提示词然后生成视频
剪辑视频
学习本篇文章之前一定要先看一下上一篇文章,因为会有工具的安装和入门的学习
这次开源项目用到的剪辑工具和国内的剪映很相似,因为他是国际版剪映——capcut
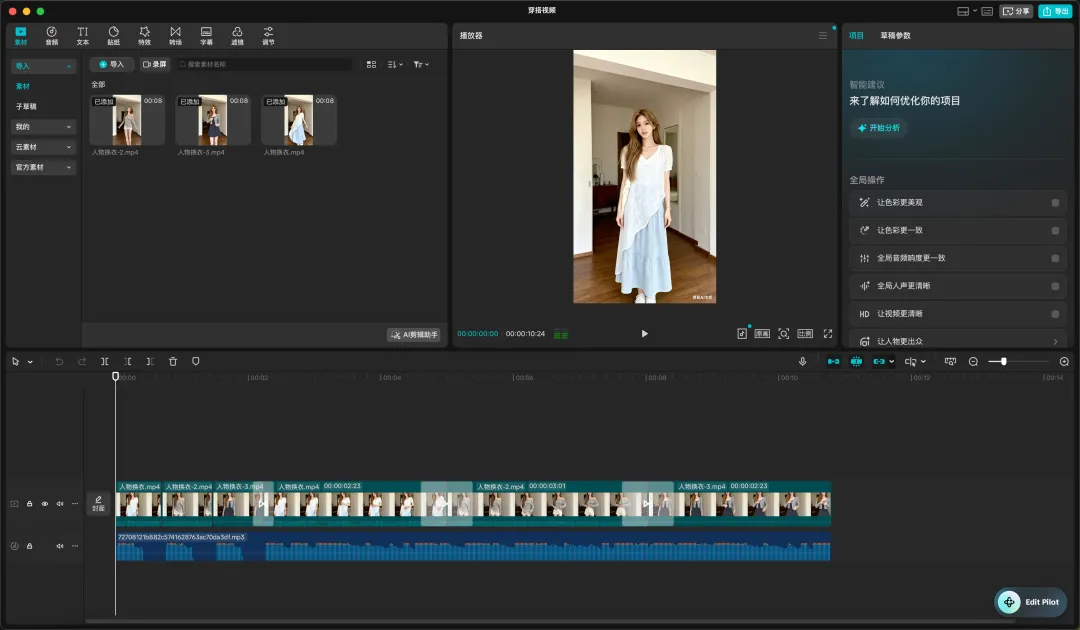
用视频的素材后,就可以到剪辑软件中进行最终视频的剪辑,如果会剪辑可以去剪辑一些更好的模版出来,如果不会剪辑,也没有关系,舰长把这套的视频的模版变成了skill,可以发给大家进行使用。领取方式在文章结尾~
剪辑这个板块,真的也只能靠大家自己了,剪辑越好,效果越好。当然我们的目的也不要忘记,是为了学习整套流程,所以如果时间允许可以自行尝试一下如何进行剪辑~
整个制作流程都已经带大家过了一遍,下面就是将这些流程做出自动生成的流程
那下面我们需要考虑的就是如何自动生成图片,然后再继续生成视频,最终生成视频的草稿导入到我们的剪辑软件中
那有了解过skill技能的小伙伴清楚,我们可以通过把流程写入到skill中,完成这样的一套流程。
但编写一个skill也不是什么容易的事儿,必须要梳理清楚如何去编写它,那为了让大家更好的去上手,同样的我们给它拆出来。
模特和服装图的原素材就不用多说了,这些暂时只能靠手动
那只剩下图片、视频、合成视频这三个板块
图片skill的制作
做图片无非思考我们要使用什么模型帮我们去做图片,Skill不是告诉模型让他去即梦上生成图片,而是要在skill中写上生成图片的接口。
比如:给他火山引擎(豆包)的接口,但其实相关电商的服装出图,我还是比较推荐使用香蕉模型(banbana)
但是香蕉模型的使用还是有一些门槛,所以呢,我们就需要去借助一些中转平台
咖啡馆:https://api.kafeiai.cn/register?aff=b2d3be30429
一个集成AI模型、AI图片、AI视频的聚合型中转站,基本可以满足我们在各种场景下的开发需求
我们先找到一个香蕉模型的API文档,打开网站后点击「支持模型」
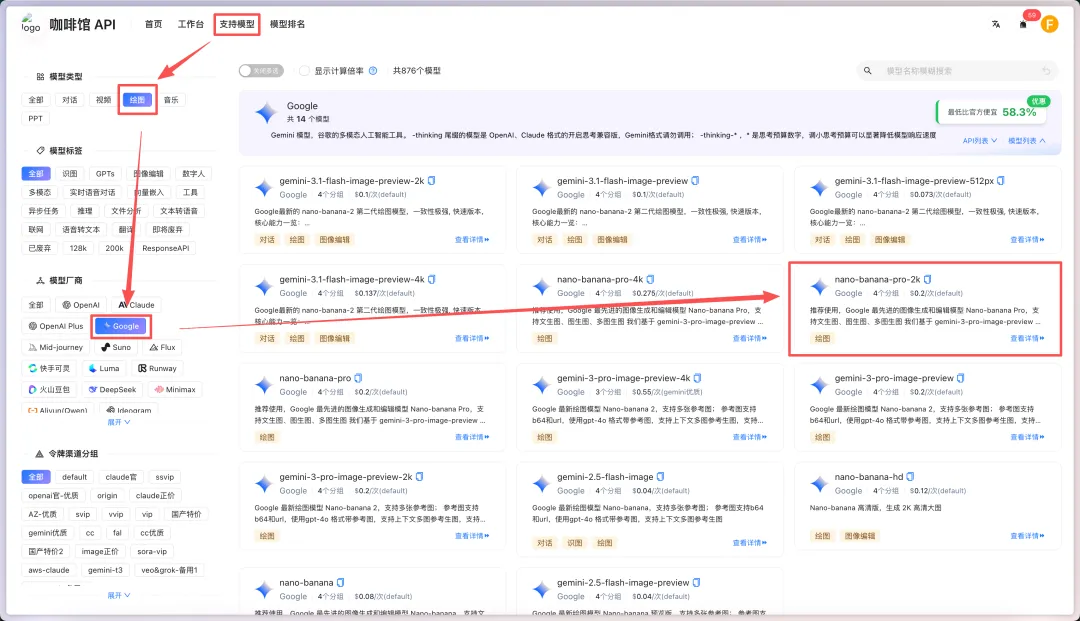
点击「查看详情」,就能看到一个调用的文档地址
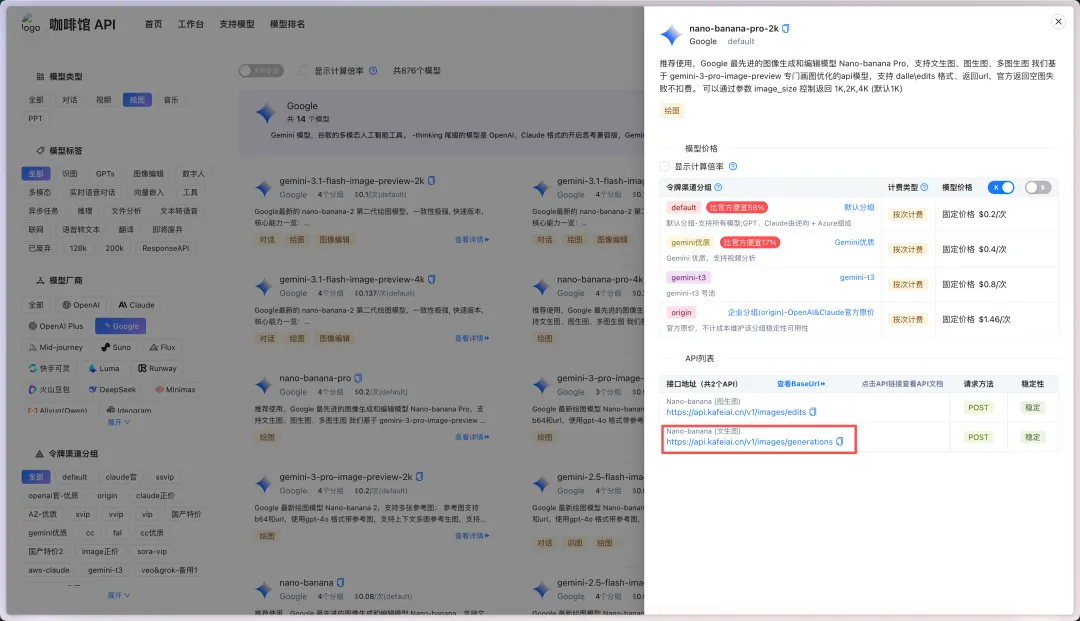
接口的文档信息内容比较复杂,如果不是专业做开发出身的小伙伴,可能看着会非常难受。但是整个内容呢,不需要我们自己真的去一次的去看。
只需要点击页面的右上角的复制页面,将整个页面的文字信息复制给我们的AI去查看即可
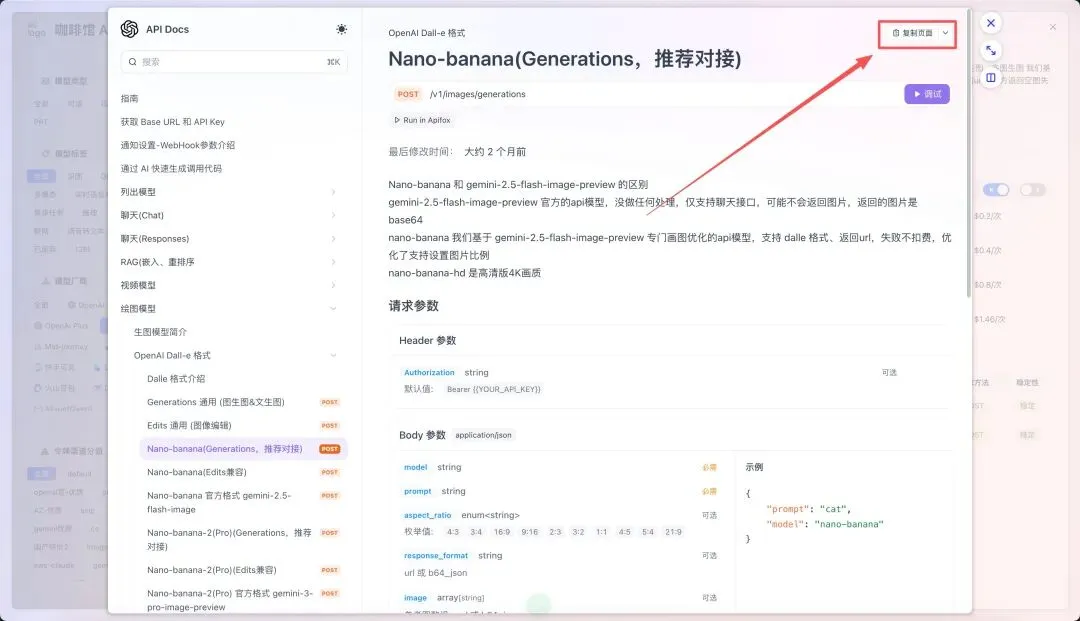
除了复制这些接口的网页,还要加上一些我们的要求和需求,然后让最终再让它一并生成。
具体的大大家可以看下面的这段内容“前面是我提供给他的一些要求和需求,下半部分是复制的他的请求(接口)文档”
请求接口为:https://api.kafeiai.cn/v1/images/edits我要用的模型为:nano-banana-pro-2k其他注意事项:图片要9:16的,你需要根据我提供的一张原图和一张服装图进行参考,生成一张新图,图片要2K请你基于上面的情况帮我去创建一个skill,skill的名称你自己定义。我想要实现的效果就是当我提供原图和服装图的时候,你需要帮我生成新图。同时,新图呢,你需要帮我保存在本地的文件里面去。下面是请求文档:# Nano-banana(Edits兼容) ## OpenAPI Specification```yamlopenapi:3.0.1info:title:''description:''version:1.0.0paths:/v1/images/edits:post:summary:'Nano-banana(Edits兼容) 'deprecated:falsedescription:>- Nano-banana 和 gemini-2.5-flash-image-preview 的区别gemini-2.5-flash-image-preview官方的api模型,没做任何处理,仅支持聊天接口,可能不会返回图片,返回的图片是base64nano-banana我们基于gemini-2.5-flash-image-preview专门画图优化的api模型,支持dalle格式、返回url,失败不扣费,优化了支持设置图片比例nano-banana-hd是高清版4K画质tags:-绘图模型/OpenAIDall-e格式parameters:-name:Authorizationin:headerdescription:''required:falseexample:Bearer {{YOUR_API_KEY}}schema:type:stringdefault:Bearer {{YOUR_API_KEY}}requestBody:content:multipart/form-data:schema:type:objectproperties:model:example:nano-bananatype:stringprompt:example:一只猫type:stringimage:description:支持多图或不带参考图example:-file://E:\Downloads\1745936044575403500.png-file://E:\Downloads\微信图片_20250826114255_1785.jpgtype:stringformat:binaryresponse_format:description:url或b64_jsonexample:urltype:stringaspect_ratio:type:stringenum:-'1:1'-'2:3'-'3:2'-'3:4'-'4:3'-'4:5'-'5:4'-'9:16'-'16:9'-'21:9'x-apifox-enum:-value:'1:1'name:''description:''-value:'2:3'name:''description:''-value:'3:2'name:''description:''-value:'3:4'name:''description:''-value:'4:3'name:''description:''-value:'4:5'name:''description:''-value:'5:4'name:''description:''-value:'9:16'name:''description:''-value:'16:9'name:''description:''-value:'21:9'name:''description:''example:''required:-model-prompt-imageexample:model:stringprompt:stringsize:stringresponses:'200':description:''content:application/json:schema:type:objectproperties: {}x-apifox-orders: []headers: {}x-apifox-name:成功security: []x-apifox-folder:绘图模型/OpenAIDall-e格式x-apifox-status:releasedx-run-in-apifox:https://app.apifox.com/web/project/3868318/apis/api-341817449-runcomponents:schemas: {}securitySchemes: {}servers: []security: []```所以各位小伙伴也可以将上面这段内容直接复制给你的AI Agent
AI Agent的选项有很多,可以去使用claude code或者open claw。甚至可以像我一样直接去使用work buddy
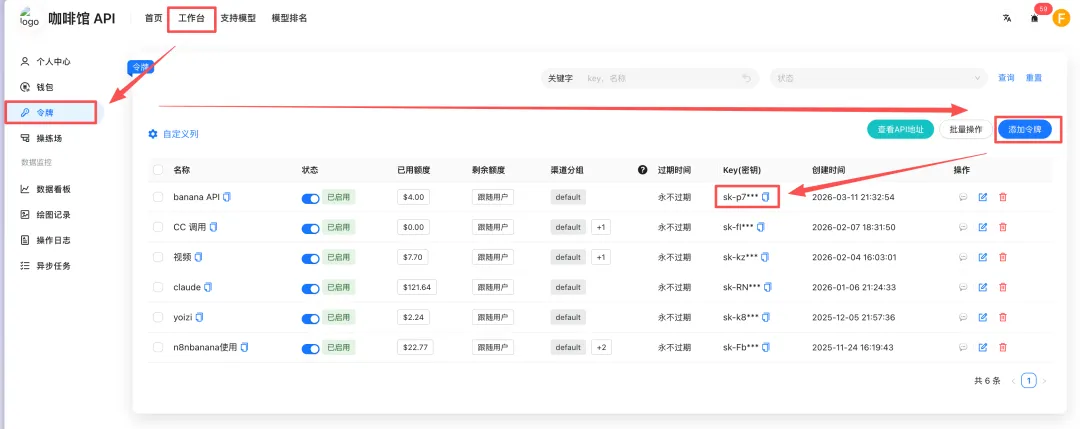
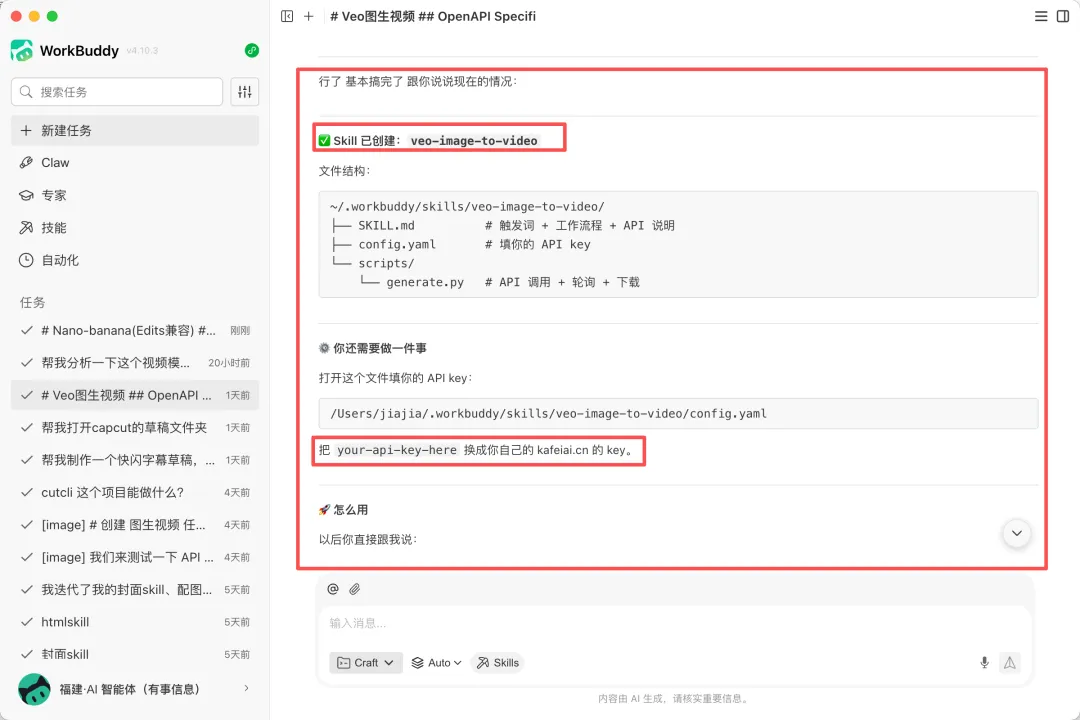
下面这张截图就是生成好后他给我的回复,自动的会帮我们创建好技能的名称,并且告诉我们怎么去使用,那在这张图中,大家有看到最后的一个红色框中的一个API密钥
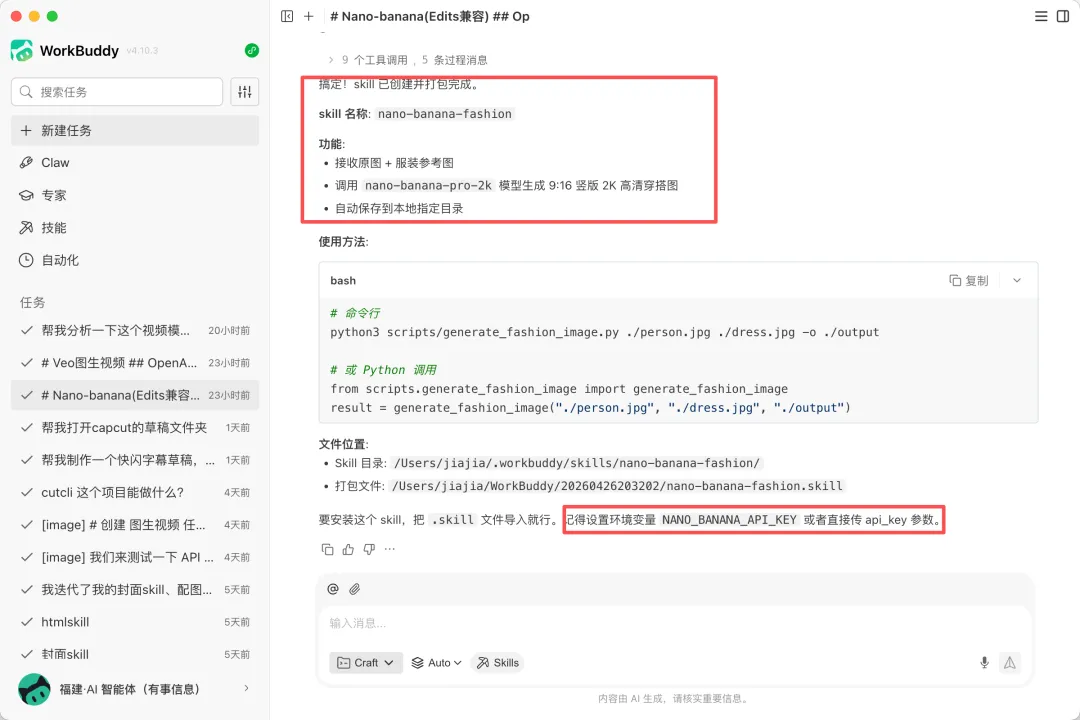
这个密钥是需要我们在咖啡馆的这个网站里面去获取的。也就相当于是一个门户的密码,有了这个密码,我们就可以使用这个skill去生成相对应的图片
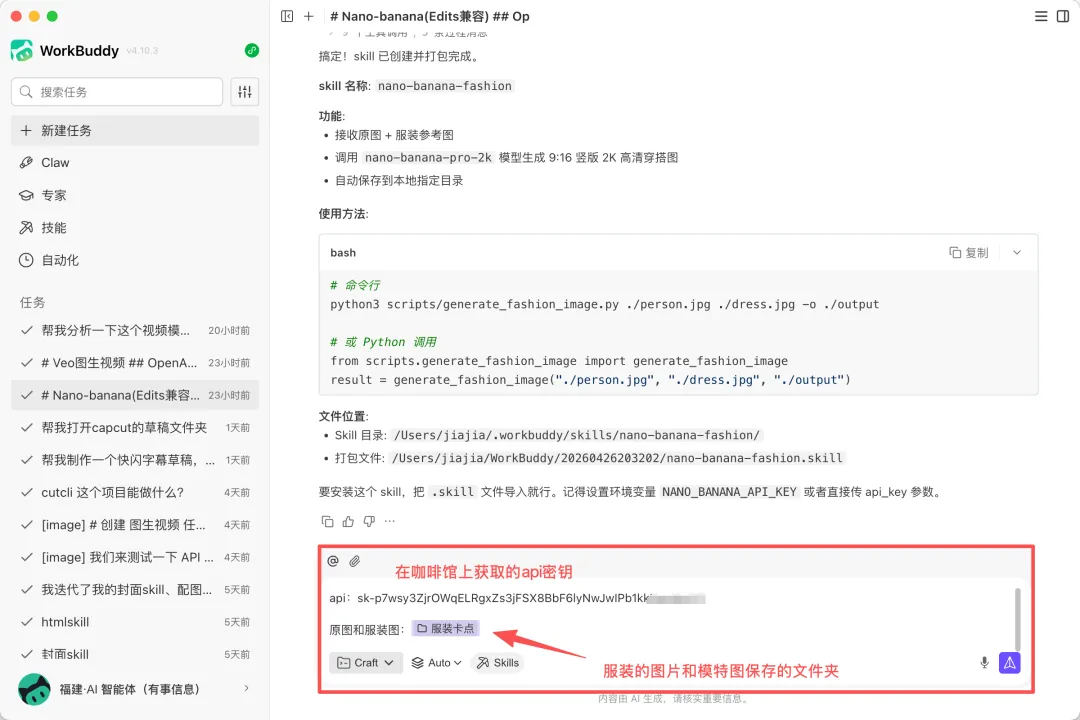
Skill生成好了之后呢,就要优先的去体验一下啊,测试一下这个skill的功能能不能正常的运行:
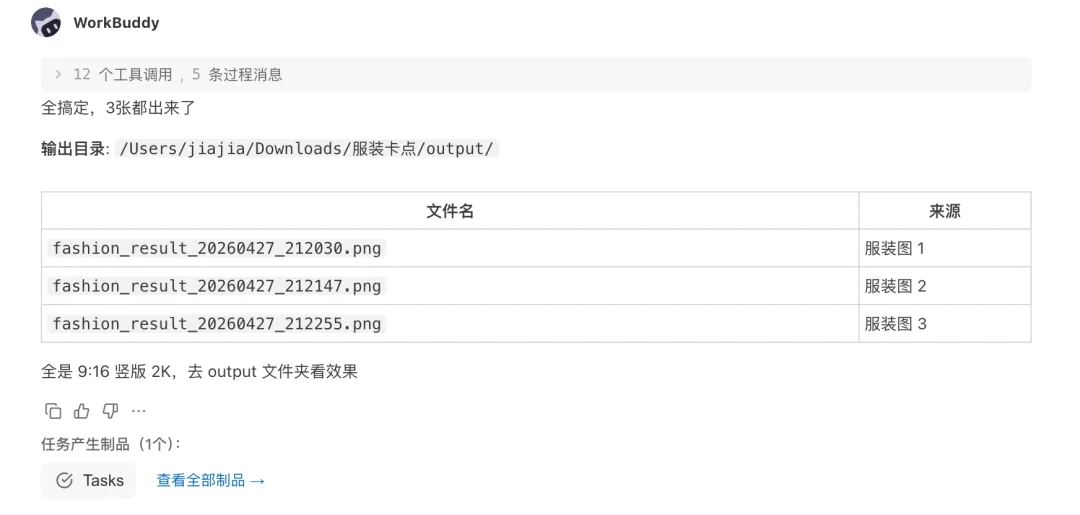
运行结果:说明skill创建很好,没有什么问题后续可以继续使用
如果在测试中遇到任何问题,都可以重复的和AI进行沟通,不需要我们自己手动的去修改skill或者说自己去调整skill。如果有问题的话,AI也会根据情况再去解决skill的一些特殊情况
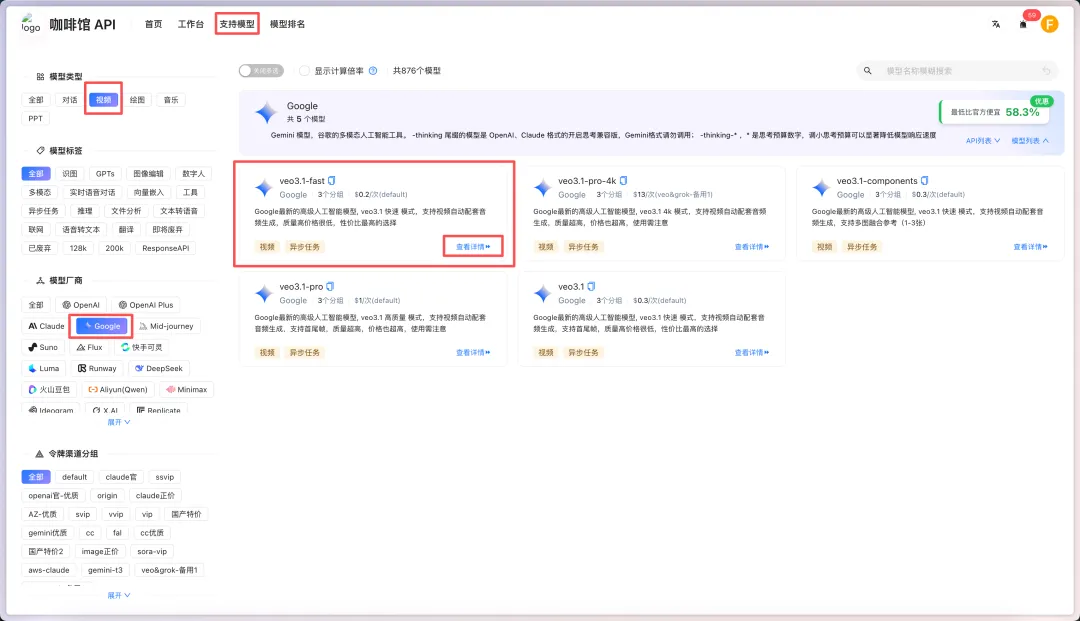
视频skill的制作
下面在来做视频的skill,逻辑一样,也是使用咖啡馆的视频模型接口去做成skill,推荐模型veo3.1-fast
这里跟制作生图skills的一样滴,这是接口信息:
建议大家直接复制我下面的这些文本,发给你的AI Agent, 去给你生成相对应的skill 。因为在我们生成视频的时候,它的很多模型是使用的异步任务,所以大家还需要去理解所谓的请求接口、查询接口等内容
直接复制下面的内容给到可以生成skill的AI应用即可:
你的请求接口是:https://api.kafeiai.cn/v2/videos/generations你的模型是:veo3.1-fast其他要求,你需要帮我生成视频,视频呢,是根据我提供的参考图案去生成视频,然后提示词呢,为固定提示词,内容为:一只手轻搭在身侧,另一只手自然地整理衣服,重心微微后移,展现衣服的版型与衣服的内容,姿态优雅,眼神温柔地看向镜头,发丝随动作轻微飘动。最后向前走两步,或者转一圈。请求文档:# Veo图生视频 ## OpenAPI Specification```yamlopenapi:3.0.1info:title:''description:''version:1.0.0paths:/v2/videos/generations:post:summary:'Veo图生视频 'deprecated:falsedescription:|- 当模型是带 veo2-fast-frames 最多支持两个,分别是首尾帧 当模型是 veo3-pro-frames 最多支持一个首帧 当模型是 veo2-fast-components 最多支持 3 个,此时图片为视频中的元素不传aspect_ratio参数时,会根据参考图自动匹配比例,如果无法判断默认生成横屏tags:-视频模型/统一格式接口/Google-Veoparameters:-name:Content-Typein:headerdescription:''required:trueexample:application/jsonschema:type:string-name:Authorizationin:headerdescription:''required:falseexample:Bearer {{YOUR_API_KEY}}schema:type:stringdefault:Bearer {{YOUR_API_KEY}}requestBody:content:application/json:schema:type:objectproperties:prompt:type:stringmodel:type:stringenum:-veo3-pro-frames-veo3-fast-frames-veo2-fast-frames-veo2-fast-components-veo3.1-veo3.1-pro-veo3.1-componentsx-apifox-enum:-value:veo3-pro-framesname:''description:支持图生视频-value:veo3-fast-framesname:''description:''-value:veo2-fast-framesname:''description:''-value:veo2-fast-componentsname:''description:''-value:veo3.1name:''description:>- 支持首尾帧,Google最新的高级人工智能模型, veo3 快速 模式,支持视频自动配套音频生成,质量高价格很低,性价比最高的选择, 自适应首帧和文生视频-value:veo3.1-proname:''description:>- 支持首尾帧,Google最新的高级人工智能模型, veo3 高质量 模式,支持视频自动配套音频生成,质量超高,价格也超高,使用需注意, 自适应首帧和文生视频-value:veo3.1-componentsname:''description:多图参考(1-3)张图enhance_prompt:type:booleandescription:| 是否优化提示词,一般是false;由于 veo 只支持英文提示词,所以如果需要中文自动转成英文提示词,可以开启此开关images:type:arrayitems:type:stringdescription:>- url or base64;当模型是带 veo2-fast-frames 最多支持两个,分别是首尾帧,当模型是 veo3-pro-frames 最多支持一个首帧,当模型是 veo2-fast-components 最多支持 3 个,此时图片为视频中的元素aspect_ratio:type:stringenum:-'9:16'-'16:9'x-apifox-enum:-value:'9:16'name:''description:''-value:'16:9'name:''description:''required:-prompt-model-imagesx-apifox-orders:-prompt-model-enhance_prompt-images-aspect_ratioexamples: {}responses:'200':description:''content:application/json:schema:type:objectproperties: {}x-apifox-orders: []headers: {}x-apifox-name:成功security: []x-apifox-folder:视频模型/统一格式接口/Google-Veox-apifox-status:releasedx-run-in-apifox:https://app.apifox.com/web/project/3868318/apis/api-343632235-runcomponents:schemas: {}securitySchemes: {}servers: []security: []```查询接口:# Veo查询任务## OpenAPI Specification```yamlopenapi:3.0.1info:title:''description:''version:1.0.0paths:/v2/videos/generations/{task_id}:get:summary:Veo查询任务deprecated:falsedescription:|- 统一接口格式 status 枚举: NOT_START : 未开始 IN_PROGRESS : 正在执行 SUCCESS : 执行完成 FAILURE : 失败tags:-视频模型/统一格式接口/Google-Veoparameters:-name:task_idin:pathdescription:''required:trueschema:type:string-name:Authorizationin:headerdescription:''required:falseexample:Bearer {{YOUR_API_KEY}}schema:type:stringdefault:Bearer {{YOUR_API_KEY}}responses:'200':description:''content:application/json:schema:type:objectproperties: {}example:task_id:veo3:1756693796-YQVHH4A3Lgplatform:googleaction:google-videosstatus:SUCCESSfail_reason:''submit_time:1756693797start_time:1756693808finish_time:1756693898progress:100%data:output:>- https://filesystem.site/cdn/20250901/018eg2SgUpHMT6EEuQbfeRLWeUhE75.mp4search_item:''headers: {}x-apifox-name:成功security: []x-apifox-folder:视频模型/统一格式接口/Google-Veox-apifox-status:releasedx-run-in-apifox:https://app.apifox.com/web/project/3868318/apis/api-343593236-runcomponents:schemas: {}securitySchemes: {}servers: []security: []```请求接口为:https://api.kafeiai.cn/v2/videos/generations/{task_id}请你帮我做成一个skill啊,我要实现的效果就是我给你提供一张图片,你需要帮我生成视频。视频生成的提示词呢,在上面我已经给你提供了。生成好之后呢,你需要使用异步的接口去帮我查询视频,直到视频全部完成之后,并且再保存到我的本地Skill技能创建完成之后,他也会告诉你,这个技能当中呢,我们并没有提供任何的API. Key那这些内容就是和我们上面图片skill其实是一样的,我们也需要在咖啡馆里面获取一个API,当然这个API和图片API是共用的,一个api就够用。
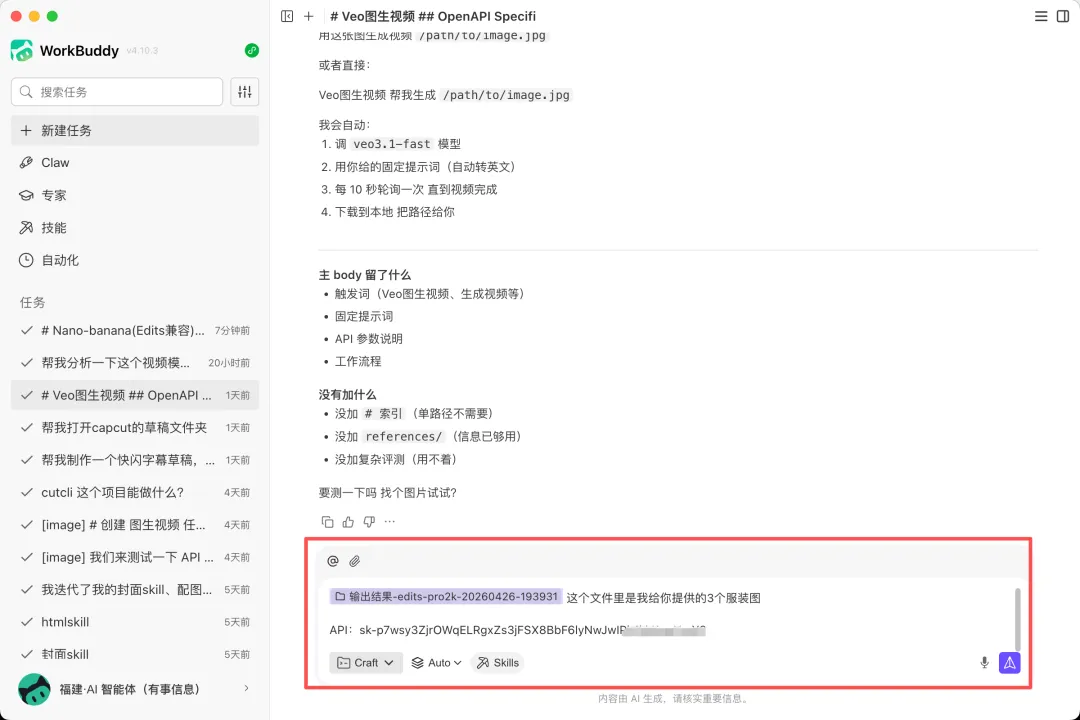
同样也要测试一下效果:
合成视频skill
这个合成视频的skill,也是本次分享中的一个重点,这个skill的制作,也非常有趣
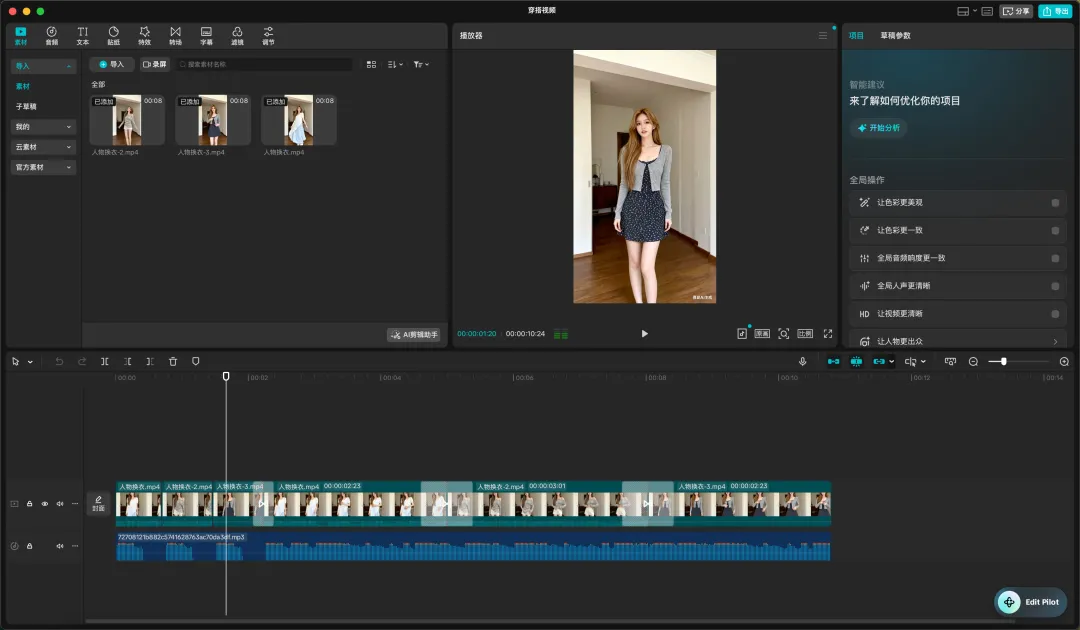
给大家看一张图:

这张图中写了哪些内容呢?
不就是通过文字信息,将我们这个剪辑软件(国际剪映)里的视频效果描述了出来
既然AI能识别我们的视频的草稿,那我们只需要让他先识别,然后再制作成skill,这个skill呢,相当于就是一个视频模板了
AI就可以后续参考这个skill制作出类似的视频草稿出来,这样这个链路都清晰了吧!
核心就是生成好三个AI视频(服装展示)的片段,然后自动剪辑,配置服装出现时间、卡点、音频
既然视频模板中的结构它能分析出来,那只需要让它下一步生成skill即可:
提示词:帮我制作成一个skill,当我后续我每次想要生成类似视频的时候,我只需要提供3个视频片段,就能生成同样素材音频、同样转场、同样时间卡点的这种素材出来。
当做好了之后,我们所有的skill都准备好了
虽然说拆开去生成skill的方式呢,会将结构变得更清晰啊,我们的梳理、输出、生成会更方便;但是这样的方式不利于去自动生成
还记得我们的目的吗?就是传递模特图和服装图即可得到这样的视频。所以还需要进行一步skill的合并:
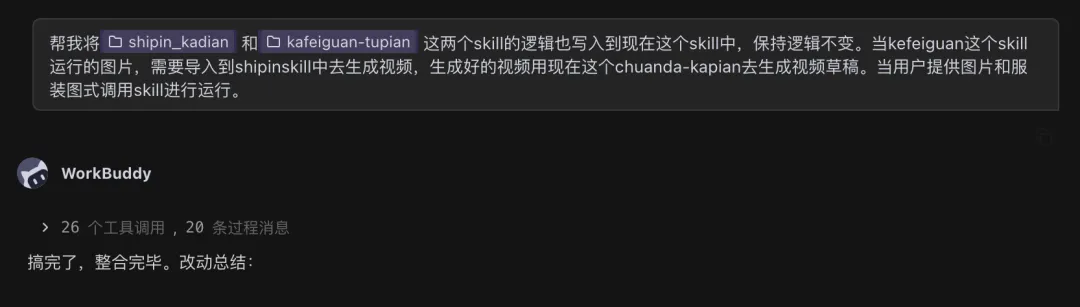
实现也很简单,就是将生成的图片skill和视频的skill全部发给我们的AI
然后告诉他整个的流程的串行的一个逻辑,比如我们第一个skill生成的图片,需要导入到第二个视频skill中去生成视频;生成好的AI视频片段,再去调用这个合成草稿模板的这个skill,进行最终的视频合成
这样我们的3个skill的功能都合并起来了,每当我们传递一张原图(模型图)+ 3张服装图的情况下,就能自动的调用这一个大的skill完成图片、视频、合成视频全流程的制作
写在最后
以上的内容就是我分享的全部信息
在最后呢,我再去回答大家一些疑惑,比如说为什么我的所有截图都是work buddy;其实很多小伙伴的上手门槛,会被限制在我们每个人电脑的一些环境上。
但是work buddy是腾讯旗下的一个app,直接下载到电脑中就可以用;你要说他的能力的话,其实并没有我们想象的那么强,也会有很多的BUG和一些难用的地方
所以在用的时候,可以把文字信息框下面的模型从自动(auto)改成MiniMax的模型或者GLM的模型,能稍微提高一些使用的效率。
在文章中提到的 skill 完整模板,可以分享给大家,只需要在文章下面评论“0429”并添加下方进行领取
关注公众号并添加舰长,领取智能体学习资料,并参与智能体技术直播讲解

另外非常欢迎大家加入[唐舰长AI落地智能体交流群],主要交流群每周都会进行公益直播教大家搭建AI智能体工作流
