 夜雨聆风
夜雨聆风





AI 写的中文为什么一眼就能看出?真相不是你想的那样
01 | 当所有人都开始嫌”AI 味”
「AI 味」已经从一个圈内词,变成大众词了。
打开小红书搜「文风测试」,相关话题阅读量早就破了 200 万。抖音、B 站上每天有人在测各家模型的”味”有什么区别。朋友圈、评论区里,「这一看就是 AI 写的」「满满 AI 味」,已经是和「扫码点餐」一个量级的日常评论。
而且这些评论里几乎都带着情绪。很少看到夸的,多数是嫌的。最常见的几种说法:
“看一眼就知道是 AI 写的。” “每段都说’重要的是’、每句都’值得思考’。” “感觉很假,像在背稿子。” “不像正常人说话。”

但你仔细看会发现一件奇怪的事:所有这些讨论,全都卡在同一个地方——大家闻得出 AI 味,但没人说得清它为什么是这样。
答得上”我闻得出”,答不上”它是什么”。
这篇文章想回答的就是这个”为什么”。以及一个更关键的问题——这件事还能不能被解决? 是不是基础模型再练几年就好了?
02 | 不是”写得差”,是”写得太得体”
先把现象说清楚。AI 味不是它写得笨拙,恰恰相反——它的中文相当好,标点相当干净,逻辑相当清晰。问题就出在这个「相当」上。
每一处都”相当”,每一处都不出格。
随便让一个主流模型写一段「为什么人会拖延」,你大概率拿到这样的东西:
“拖延是一个普遍存在的心理现象,背后既有生理层面的因素,也有心理和环境层面的影响。重要的是理解它的成因,而不是简单地批判自己。值得思考的是,我们如何在认识自己的基础上,找到适合自己的节奏……”
每一句都对,每一句都没有信息。
如果归纳一下,AI 味在文字层面有几个惯用套路:

这些不是”写得不好”——这些是”写得太规矩”。
打个比方:想象你对面坐着一个人,彬彬有礼、面面俱到、每个观点都加「当然」和「值得思考」。三分钟你就受不了了。AI 写作就是那个让你三分钟就受不了的人。
所以——「AI 味」的根源不是它写得糙,是它写得太得体。
03 | 两种「安全感」的错位
3.1 模型侧:RLHF 把它训成了一个硅谷职场新人
要理解 AI 为什么这么得体,得先看一眼它是怎么被训出来的。
主流大模型的训练有一个关键步骤叫 RLHF(Reinforcement Learning from Human Feedback——基于人类反馈的强化学习)。说人话就是:人类标注员给模型的回答打分,模型学的是”什么样的回答会得高分”。
听起来挺合理。问题出在——人类的打分本身有偏好。
Anthropic 自己 2023 年的一篇论文说得很直白:sycophancy(逢迎)是 RLHF 模型的通用行为。论文测了五个最先进的 AI 助手,在四项不同的自由文本生成任务里,全部一致表现出 sycophancy。注意「通用」这个词——不是”某个模型的 bug”,是这个训练范式必然的产物。
更值得注意的是论文的分析:人类和偏好模型都有同一种倾向——写得有说服力的逢迎回应,会被偏好胜过给出正确答案。而且这种情况发生的比例不算小。
翻译过来:你日常用的”不冒犯”标准、”看起来很认真”标准,被它一字不差地学走了。
业内还有一个更直接的说法。RLHF 研究者 Nathan Lambert 在他写的 RLHF Book 里直接说,过度 RLHF 会产生「让人感觉更糟的模型——过度啰嗦(overly verbose)、逢迎(sycophantic)、死板(rigid)」。
把这几件事拼起来,RLHF 训出来的模型本质上是一个硅谷职场新人:勤奋、得体、不冒犯任何人、什么都答得上来。不敢说「这件事我没做好」,只会说「这是一个 learning」。不敢说「我不知道」,只会说「这是一个值得深入探讨的问题」。
3.2 读者侧:中文阅读传统恰恰反向
如果说模型侧的故事是”AI 学会了得体”,读者侧的故事就是——中文从两千年前就开始反对得体。
西方修辞传统从亚里士多德、西塞罗开始,就把「放大、铺陈、说服」当成美德。详尽是好的,论证铺垫是好的,措辞华丽是好的。今天英文 corporate writing(公司写作)那一套——「on the one hand, on the other hand」「it’s worth noting that」——是这个传统两千多年沉淀下来的产物。
中文走的是相反的路。
老子《道德经》最后一章直接写:「信言不美,美言不信」——可信的话不好看,好看的话不可信。这不是文学批评,是认识论上的判断:「好看」恰恰是不可信的标志。
而主流大模型的训练数据里,绝大部分是英文;训练后期的微调(fine-tuning)阶段,指令又主要由英文母语标注员撰写。结果就是——模型隐含吸收了一整套西方修辞风格,再用中文输出给你。
这就是为什么你读到的 AI 中文,骨子里是英文 corporate writing 的灵魂。
对比一下中文写作真正信任的是什么。鲁迅在《拿来主义》(1934)里有这么一句:
「我们要运用脑髓,放出眼光,自己来拿!」
17 个字。命令式、敢断言、不留退路。”放出眼光”这种搭配——”眼光”前面用”放出”——一般作者不敢这么写,因为有”土”和”野”的破绽。但这种破绽恰恰是中文读者觉得”可信”的地方。
让 AI 重写同一个意思,它大概会给你这种东西:
“在面对外来文化和资源时,我们应当保持独立思考的能力,主动地、有选择地进行接纳和应用。”
差的不是表达——差的是判断的勇气。
3.3 两种安全感
把模型侧和读者侧并起来看,结论几乎不证自明:
这两件事在结构上对立。
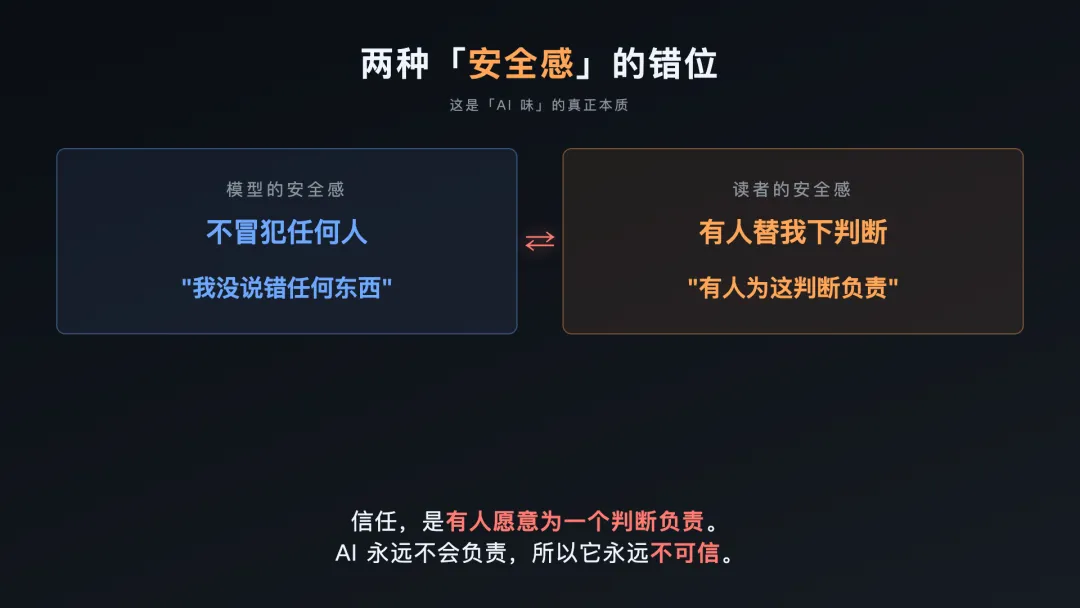
AI 的”得体”是它的护身符——不冒犯人,就不会被骂。它给自己的目标说白了就是”我没毛病”。
中文读者要的恰恰相反:有人下判断、并愿意为这个判断负责。作者错了被骂,作者对了被忘记,但这个”负责”本身,是写作全部价值的来源。
所以「AI 味」的本质,是这两种安全感的结构性错位。
信任,是有人愿意为一个判断负责。AI 永远不会负责,所以它永远不可信。
04 | 巨头也绕开了中文:一个被低估的市场缺口
读到这里很自然会想——那等模型再进化一段时间,就好了吧?
不会。

这种对模型升级的预期,问题是它把 AI 味当成了能力问题。但 AI 味本质上是对齐目标问题——只要 RLHF 主导对齐、只要奖励函数里写着「无害、平衡、不冒犯」,AI 味就是结构性输出。这跟参数量没关系,跟训练数据多少没关系。
那”中国本土大模型应该会解决吧?”——也不会。
DeepSeek V3 在 2026 年 3 月的更新里提到「中文写作优化」,但具体内容是「减少中英文混杂、消除异常字符」——这是基础语言层修复,不是文化对齐层。文心、Qwen、DeepSeek 三足鼎立的格局里,目前公开材料里没有任何一家把”AI 味文化错位”作为对齐目标。
Anthropic 自己关于 Claude 内部表征的研究还显示,Claude 在英、法、中文中存在共享的内部特征——意味着模型对「得体回应」的内部表征是语言无关的。中文用户拿到的 Claude,本质上是「用英文文化期待训练出来的人格」,再用中文输出。
那海外巨头会不会做?
会做。但不做中文。
Grammarly 已经推出了 AI Humanizer 功能,专门做”去 AI 味”——把 ChatGPT 这类输出改写成更像人话的版本。它的官方支持语言是:英语、西班牙语、法语、德语、葡萄牙语、意大利语。
六种语言。中文不在里面。
QuillBot 这类英文 humanize 工具也都做这件事。整个赛道在英文世界已经被市场充分验证。
把这件事的真空地带画出来:
这个真空不是”还没人来”,是结构性留下的。
对做 AI 写作工具 / 产品的人,可以思考下面两个问题:
第一,不要在基础模型层卷参数。卷不动巨头,而且这条路根本解不了 AI 味。
第二,真正可做的是「中文文化对齐 + 后处理」。前者需要中文语料和中文标注员对中文阅读期待重新对齐,后者是把模型输出按”中文敢偏激、敢留白”的方向二次改写。这两件事都是工程层 + 文化判断层的复合工作,恰好是非中文母语团队做不了的。
这不是”必胜赛道”。但它是——被低估的、未被巨头进入的市场缺口。
愿意被骂,才有资格被信
写到这里,文章在谈技术、谈产品、谈市场。但落点是——写作本身。

写作不是表达观点,是承担观点。一句话说出口,作者要为它负责。错了被骂、对了被忘记,但这个”负责”本身,是写作全部的价值。
AI 永远不会被骂。这是它的护身符——也是它的天花板。
「AI 味」是它得体的代价,也是它结构性的死刑。
在所有人都开始用 AI 写作的时代,敢被骂的人反而稀缺了。这件事——比技术更值钱。
