 夜雨聆风
夜雨聆风





AI 写 PRD,别把整个 Wiki 喂给它
前两天我写了一篇,把 Obsidian 里的 Wiki 接进 Codex。那套东西适合个人用:材料放在本地,AI 能读,写东西时不用每次从零交代背景。
但如果把场景从“我自己的工作台”换成“公司里的 PRD 生成”,问题马上变了。
公司里不只一个产品经理。Wiki 也不是一堆干净资料。里面有当前规则,有历史页面,有被否掉的方案,也有不同业务线留下的旧口径。
这时候你真的敢让 AI 一口气读完整个 Wiki,然后吐出一份 PRD 吗?
或者换个更具体的问题:我们建一个 PRD Skill,塞进去两千字 System Prompt,再每次贴五千字背景资料,看起来能跑。但哪些资料该给模型,谁来筛?如果每次都要人先筛一遍,那 AI 到底是在帮我写 PRD,还是在逼我先做一遍上下文整理?
已经有了一份 PRD 生成提示词,也有一篇公司 Wiki 里的 PRD 写作规范,那能不能把它做成一个 Skill。
看起来很简单。把提示词塞进去,补个模板,最后让 AI 按格式输出。
但聊着聊着,问题变了。
真正难的不是 PRD 模板。模板反而是最容易的部分。真正难的是,AI 在写 PRD 的时候,到底相信谁。
它相信你临时粘贴的一段会议纪要,还是相信公司 Wiki 里的历史页面。它相信一个产品经理自己的 Obsidian,还是相信团队都能看到的业务事实源。它遇到两个页面说法不一致时,是自己拍脑袋合并,还是停下来标一个待确认。
这个问题一旦摊开,就不是提示词工程了。
它是上下文工程。

很多团队第一次做 AI 生成 PRD,很容易掉进一个坑,觉得只要系统提示词足够长,AI 就会足够懂业务。
所以提示词越写越厚。
角色定义,思考流程,输出格式,反问规则,质量要求,甚至要求 AI 每次都把完整内心思考写出来。
但这条路很快会遇到天花板。
因为提示词解决的是写作方式,不解决事实来源。
你可以规定 AI 必须写清楚权限、兼容、上线计划、埋点、历史数据处理。可如果它不知道公司的系统边界,不知道订单状态怎么流转,不知道结算规则以哪个页面为准,它写得越完整,风险反而越大。
看起来像 PRD。
实际上可能是一份很漂亮的幻觉。
所以这次方案里,第一个判断是,PRD Skill 不应该装进公司全量业务知识。
Skill 应该只负责方法。
比如 PRD 的章节结构,输入材料怎么读,什么时候反问,什么时候标待确认,Mermaid 流程图怎么画,质检清单怎么跑。
公司业务知识应该放在另一个地方。
这个地方,最适合的是公司 Wiki。
原因也简单。Wiki 本来就是团队共享的事实源。产品经理、研发、运营、测试都能围绕它协作。它有权限体系,有页面历史,也更适合沉淀系统规则、业务流程和历史 PRD。
个人 Obsidian 当然有价值。它适合放个人理解、会议碎片、未确认判断、灵感和草稿。
但它不适合成为团队级 AI 上下文。
因为别人看不到,也无法共同维护,更无法对业务口径负责。
到这里,好像答案已经出来了,让 AI 读公司 Wiki 不就行了吗。
问题是,不能这么粗暴。
如果让 AI 直接读完整个 Wiki,马上会出现三个问题。
第一,token 浪费。一个需求可能只涉及订单取消,你没必要让它把结算、财务、司机端、运营后台全读一遍。
第二,噪音太多。Wiki 里一定有历史页面、重复页面、废弃页面、只适用于某个旧版本的页面。AI 不知道哪个该信,就可能把旧规则写进新 PRD。
第三,权限风险。不是所有页面都应该被摘要到一个更大范围可见的地方。索引本身也可能泄露业务信息。
所以关键不是让 AI 读更多。
而是让 AI 先知道该读什么。
这就是索引页的意义。
索引页不是普通目录,而是一张 AI 可读的业务地图。它告诉 AI,一个需求如果涉及订单取消,要先看哪些页面。如果涉及费用结算,要先看哪些规则。如果涉及状态变更,要检查哪些上下游系统。
换成系统视角,它就是一个低成本的 RAG 路由层。
用户给出需求之后,AI 不直接扑向全量 Wiki,而是先读索引。
索引告诉它,这个需求大概率涉及哪些系统、角色、流程、规则和高风险点。
然后它只读命中的少量页面。
这样上下文变小了,噪音也少了,生成 PRD 的依据也清楚了。
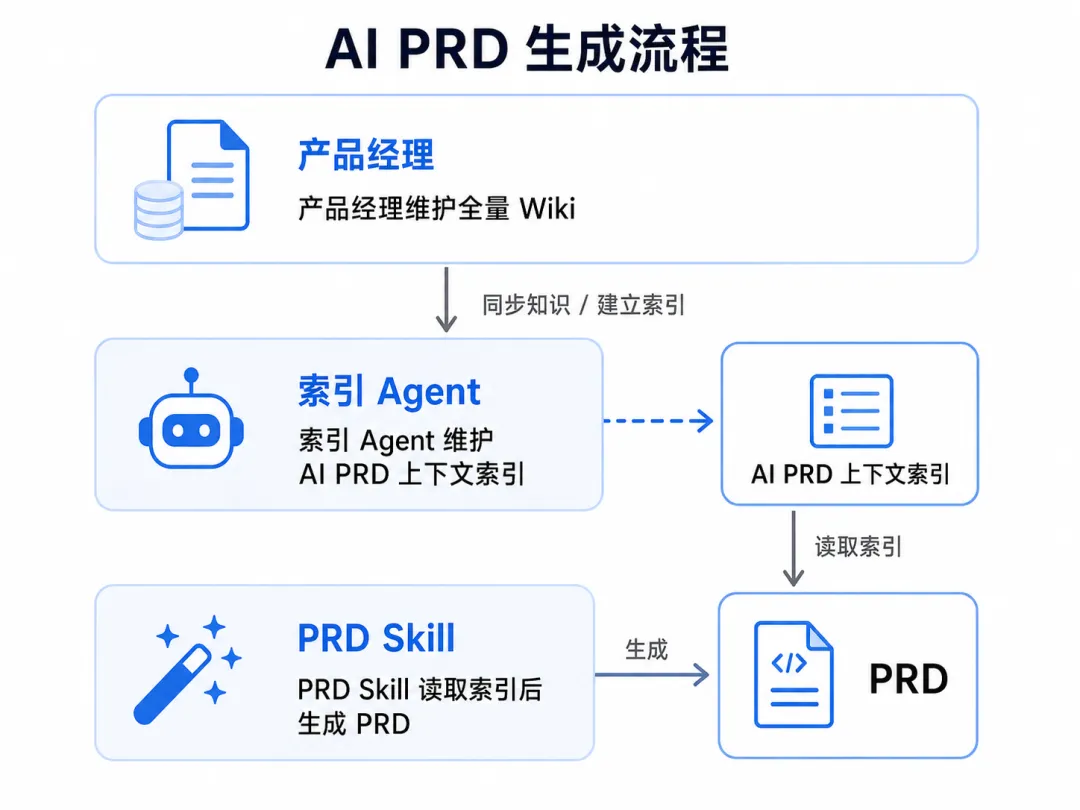
产品经理继续维护全量 Wiki。
独立 Agent 维护 AI PRD 上下文索引。
PRD Skill 读取索引,再按需生成 PRD。
这三个角色不能混在一起。
产品经理维护的是业务真相。这个页面到底是不是最新口径,取消订单后要不要重新计费,某个状态到底能不能回退,这些都必须由业务 Owner 决定。
索引 Agent 维护的不是业务真相。
它维护的是,怎么找到业务真相。
它可以扫描页面,提取标题、摘要、系统、流程、角色、关键词和更新时间。它可以发现两个页面互相矛盾。它可以提醒某个规则页面很久没有确认了。它可以生成一个更新建议。
但它不能直接改写原始业务规则。
这一刀要切清楚。
否则 Agent 很容易从信息治理工具,变成一个偷偷改业务口径的人。那就危险了。
所以更稳的做法是,索引 Agent 每次输出 diff。
比如新增一个索引条目,更新一段摘要,标记一个疑似过期页面,发现两个页面对同一条费用规则说法不一致。
然后由产品经理或页面 Owner 审核。
这听起来慢一点,但它把责任边界保住了。
AI 可以提高信息治理效率,但不能替组织承担业务责任。
接下来要做的,也不是一上来接 Wiki API。
API 是效率问题,不是质量问题。
如果索引结构没想清楚,页面状态没人维护,Owner 不明确,冲突页面没人裁决,那接了 API 也只是更快地把混乱搬进 AI。
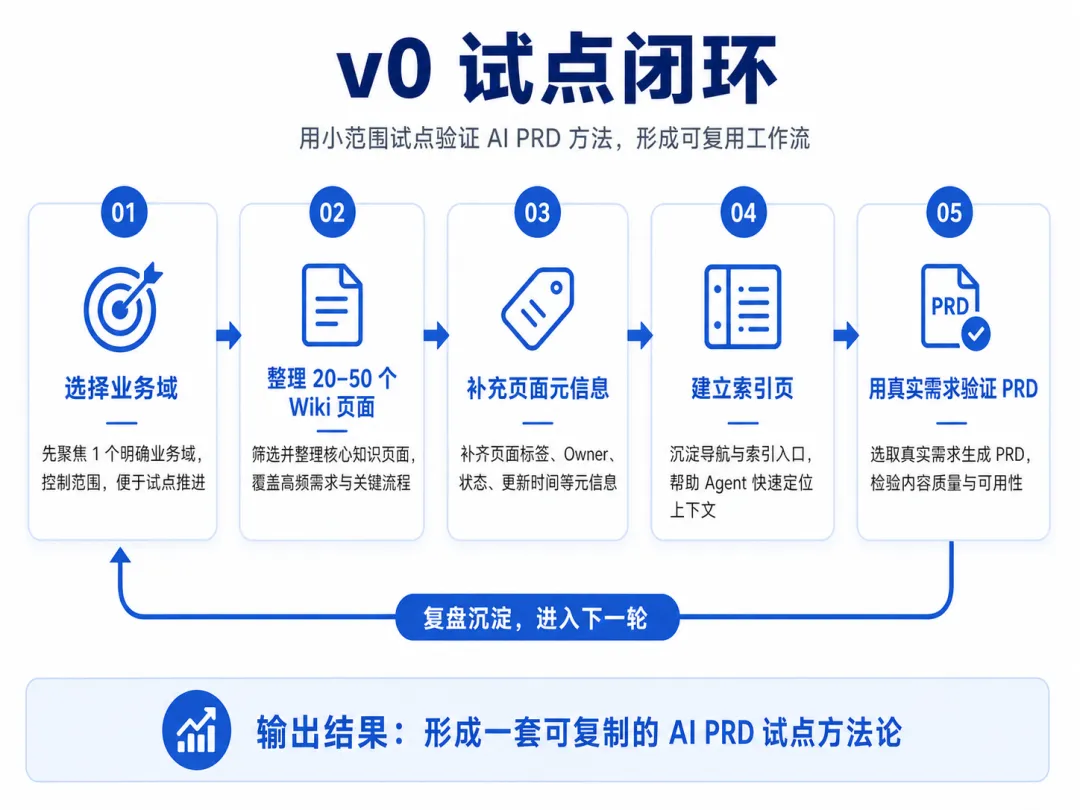
现阶段最值得做的是一个小闭环。
选一个业务域。
比如订单、调度、履约、结算,先别贪多。
整理 20 到 50 个核心 Wiki 页面,判断哪些还有效,哪些需要废弃,哪些只是历史参考。
然后给这些页面补几个最低限度的元信息,Owner,页面状态,最后确认时间。
再建一个 AI PRD 上下文索引页,按系统、业务流程、需求类型、术语、高风险规则来组织。
最后拿一两个真实需求验证。
不是验证 AI 写得漂不漂亮。
而是验证它有没有读对页面,有没有误用过期信息,有没有把系统边界写清楚,有没有把不确定的地方标出来。
这套流程跑通之后,再考虑半自动。
比如每周让索引 Agent 扫描最近更新页面,生成索引更新建议。产品经理审核后,再更新索引。
等到这个机制稳定了,再讨论 API、增量扫描、页面 hash、自动生成索引 diff。
顺序不能反。
很多 AI 项目失败,不是因为模型不够强,而是因为一开始就把自动化放在了治理前面。
这件事放到 PRD 生成上尤其明显。
PRD 不是一篇普通文章。它会进入研发、测试、上线、培训、运营。它里面的一句话,可能会变成一段代码、一个数据库字段、一条埋点、一个灰度开关。
所以 AI 写 PRD,不能只追求顺滑。
它要可追溯。
每个关键规则最好能回到某个 Wiki 页面。每个不确定点最好能找到确认人。每个冲突最好能被暴露出来,而不是被模型悄悄抹平。
这也是为什么,那些要求 AI 输出完整内心思考的提示词,反而没那么重要。
我们真正需要的不是看见 AI 想了什么。
而是知道它依据了什么。
依据比思考表演更重要。
如果未来要把这件事正式做起来,我觉得第一阶段只需要四个交付物。
一个 PRD Writer Skill,负责模板、写作规则、质检和待确认项。
一个 Wiki Index Maintainer Agent,负责扫描授权页面、维护索引建议、发现过期和冲突。
一个 AI PRD 上下文索引页,负责给 AI 路由。
一个试点验证流程,负责判断这套东西到底有没有提高 PRD 质量。
先这样就够了。
别一开始就想做全公司知识库,别一开始就接全量 API,别一开始就让 AI 写回 Wiki。
先让它在一个小业务域里,读对材料,写对 PRD,暴露不确定。
这件事跑通之后,规模化才有意义。
最后回头看,我们讨论的其实不是一个 PRD 生成工具。
它更像是在回答一个更底层的问题。
当 AI 开始进入产品工作流时,公司知识要怎么组织,才配得上被 AI 使用。
不是把知识堆给它。
是给它一张地图。